上次搭建hadoop1.2.1分布式集群,这次搭建hadoop2.4分布式集群,由于是在自己的笔记本上搭建集群,所以必须在虚拟机下安装多linux系统来模拟真实的分布式集群环境,我们用的虚拟机是VmWare10,选择的是linux发行版CentOs6.0,虚拟了三个CentOs系统(安装CentOs的步骤省略,这里不是我们这次学习的重点),一台master 两台slave,用户名全部为hadoop,具体如下(除了第一步使用root用户操作,其他均使用hadoop用户):
master 192.168.1.106
slave1 192.168.1.107
slave2 192.168.1.108
下面说明hadoop的详细安装过程:
1、给hadoop用户增加sudo权限以及修改host
1)切换到root用户,su 输入密码
2)给sudoers增加写权限:chmod u+w /etc/sudoers
3)编译sudoers文件:vi /etc/sudoers
在root ALL=(ALL) ALL下方增加hadoop ALL=(ALL)NOPASSWD:ALL
4)去掉sudoers文件的写权限:chmod u-w /etc/sudoers
5)修改host,vi /etc/hosts
192.168.1.106节点修改为master
192.168.1.107节点修改为slave1
192.168.1.107节点修改为slave2
2、首先安装jdk,我选择的是jdk-6u31-linux-amd64.rpm,使用命令sudo yum install jdk-6u31-linux-amd64.rpm --nogpgcheck;安装。安装后java路径为:/usr/java/jdk1.6.0_31
3、解压hadoop-2.4.0.tar.gz文件:tar -xzvf hadoop-2.4.0.tar.gz
4、设置java环境变量以及hadoop环境变量
sudo vim /ect/profile,
在最后增加
export JAVA_HOME=/usr/java/jdk1.6.0_31
export HADOOP_PREFIX=/home/hadoop/hadoop-2.4.0
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后使用sudo source /ect/profile使之生效
5、做SSH免密码登录
分别在三个系统中(hadoop用户)的终端执行:ssh-keygen -t rsa,一路回车
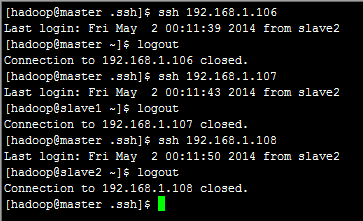
会在当前用户下.ssh目录中生成两个文件一个是私钥文件,一个是公钥文件,我们复制公钥文件到当前目录并重命名为authorized_keys,分别把其他两个系统的公钥文件内容复制到authorized_keys文件中,其他两个系统也做此操作,最后每个系统的authorized_keys文件包含本系统的公钥内容以及其他两个系统公钥的内容,使用SSH命令进行测试,如下图:
6、进入/home/hadoop/hadoop-2.4.0/etc/hadoop目录中,编辑hadoop-env.sh文件,使用vim hadoop-env.sh,修改内容如下:
export JAVA_HOME=/usr/java/jdk1.6.0_31
7、编辑yarn-env.sh vim yarn-env.sh,修改内容如下:
JAVA_HOME=/usr/java/jdk1.6.0_31
8、编辑core-site.xml,修改内容如下:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.0/tmp</value>
</property>
9、编辑hdfs-site.xml,编辑内容如下:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.4.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.4.0/dfs/data</value>
</property>
10、编辑mapred-site.xml(需要复制mapred-site.xml.template,并命名为mapred-site.xml),编辑内容如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
11、编辑yarn-site.xml文件,修改内容如下:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
12、编辑slaves文件,修改内容如下:
slave1
slave2
13、复制hadoop2.4到另外两个节点,使用的命令是:
scp -r ./hadoop-2.4.0 [email protected]:/home/hadoop
scp -r ./hadoop-2.4.0 [email protected]:/home/hadoop
14、在master节点格式化hdfs文件
[hadoop@master hadoop-2.4.0]$ ./bin/hdfs namenode -format
成功格式化后,如下图:![]()
15、启动hadoop
[hadoop@master hadoop-2.4.0]$ ./sbin/start-all.sh
使用jps查看运行的进程,表示master和slave节点成功运行的进程如下:
master:
slave1:
slave2:
至此hadoop2.4集群搭建完成。