Hadoop集群上使用Lzo压缩
转自:http://www.tech126.com/hadoop-lzo/
自从Hadoop集群搭建以来,我们一直使用的是Gzip进行压缩
当时,我对gzip压缩过的文件和原始的log文件分别跑MapReduce测试,最终执行速度基本差不多
而且Hadoop原生支持Gzip解压,所以,当时就直接采用了Gzip压缩的方式
关于Lzo压缩,twitter有一篇文章,介绍的比较详细,见这里:
Lzo压缩相比Gzip压缩,有如下特点:
- 压缩解压的速度很快
- Lzo压缩是基于Block分块的,这样,一个大的文件(在Hadoop上可能会占用多个Block块),就可以由多个MapReduce并行来进行处理
虽然Lzo的压缩比没有Gzip高,不过由于其前2个特性,在Hadoop上使用Lzo还是能整体提升集群的性能的
我测试了12个log文件,总大小为8.4G,以下是Gzip和Lzo压缩的结果:
- Gzip压缩,耗时480s,Gunzip解压,耗时180s,压缩后大小为2.5G
- Lzo压缩,耗时160s,Lzop解压,耗时110s,压缩后大小为4G
以下为在Hadoop集群上使用Lzo的步骤:
1. 在集群的所有节点上安装Lzo库,可从这里下载
cd /opt/ysz/src/lzo-2.04
./configure –enable-shared
make
make install
#编辑/etc/ld.so.conf,加入/usr/local/lib/后,执行/sbin/ldconfig
或者cp /usr/local/lib/liblzo2.* /usr/lib64/
#如果没有这一步,最终会导致以下错误:
lzo.LzoCompressor: java.lang.UnsatisfiedLinkError: Cannot load liblzo2.so.2 (liblzo2.so.2: cannot open shared object file: No such file or directory)!
2. 编译安装Hadoop Lzo本地库以及Jar包,从这里下载
export CFLAGS=-m64
export CXXFLAGS=-m64
ant compile-native tar
#将本地库以及Jar包拷贝到hadoop对应的目录下,并分发到各节点上
cp lib/native/Linux-amd64-64/* /opt/sohuhadoop/hadoop/lib/native/Linux-amd64-64/
cp hadoop-lzo-0.4.10.jar /opt/sohuhadoop/hadoop/lib/
3. 设置Hadoop,启用Lzo压缩
vi core-site.xml
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
vi mapred-site.xml
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
4. 安装lzop,从这里下载
下面就是使用lzop压缩log文件,并上传到Hadoop上,执行MapReduce操作,测试的Hadoop是由3个节点组成集群
lzop -v 2011041309.log
hadoop fs -put *.lzo /user/pvlog
#给Lzo文件建立Index
hadoop jar /opt/sohuhadoop/hadoop/lib/hadoop-lzo-0.4.10.jar com.hadoop.compression.lzo.LzoIndexer /user/pvlog/
写一个简单的MapReduce来测试,需要指定InputForamt为Lzo格式,否则对单个Lzo文件仍不能进行Map的并行处理
job.setInputFormatClass(com.hadoop.mapreduce.LzoTextInputFormat.class);
可以通过下面的代码来设置Reduce的数目:
job.setNumReduceTasks(8);
最终,12个文件被切分成了36个Map任务来并行处理,执行时间为52s,如下图:
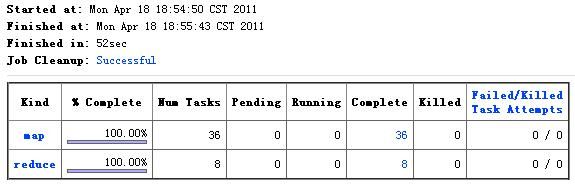
我们配置Hadoop默认的Block大小是128M,如果我们想切分成更多的Map任务,可以通过设置其最大的SplitSize来完成:
FileInputFormat.setMaxInputSplitSize(job, 64 *1024 * 1024);
最终,12个文件被切分成了72个Map来处理,但处理时间反而长了,为59s,如下图:
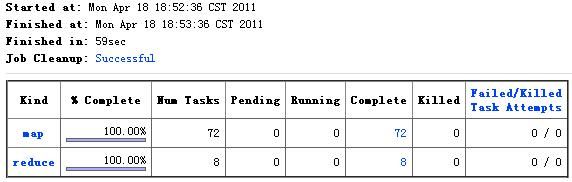
而对于Gzip压缩的文件,即使我们设置了setMaxInputSplitSize,最终的Map数仍然是输入文件的数目12,执行时间为78s,如下图:
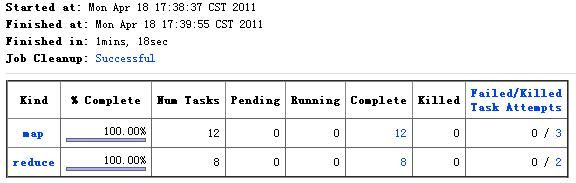
从以上的简单测试可以看出,使用Lzo压缩,性能确实比Gzip压缩要好不少