hadoop经典系列(十一)性能分析实验初步
【试验目的】
本试验目的是为了总结hadoop相关参数优化对性能的影响。
【试验环境】
硬件环境
本次试验用机4台,配置一致:
CPU: Intel(R) Xeon(R) CPU E5620 @ 2.40GHz * 16
内存: MemTotal: 32867608 kB 64bit
linux版本 CentOS release 6.2 (Final)
内核版本 2.6.32-220.el6.x86_64
硬盘 Model: IBM ServeRAID M5015 (scsi)
Disk /dev/sda: 2997GB
Sector size (logical/physical): 512B/512B
软件环境:
JDK: jdk1.6.0_45
Hadoop: hadoop-1.2.1
【试验数据和程序】
试验所用程序为WordCount计数程序(统计每个字母出现的次数),数据源是“ABCDEABC…”的循环
【试验结果统计和总结】
总结相同的配置,此次试验hadoop中备份数均为1份
导入hdfs的数据分析
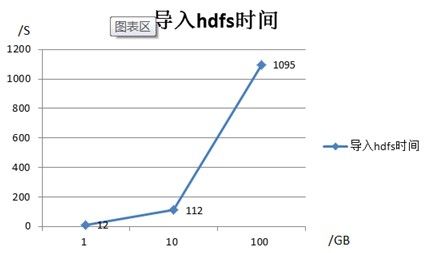
可以看出在数据导入环节,系能基本呈现线性。
参数优化结果(所使用数据均为10G)
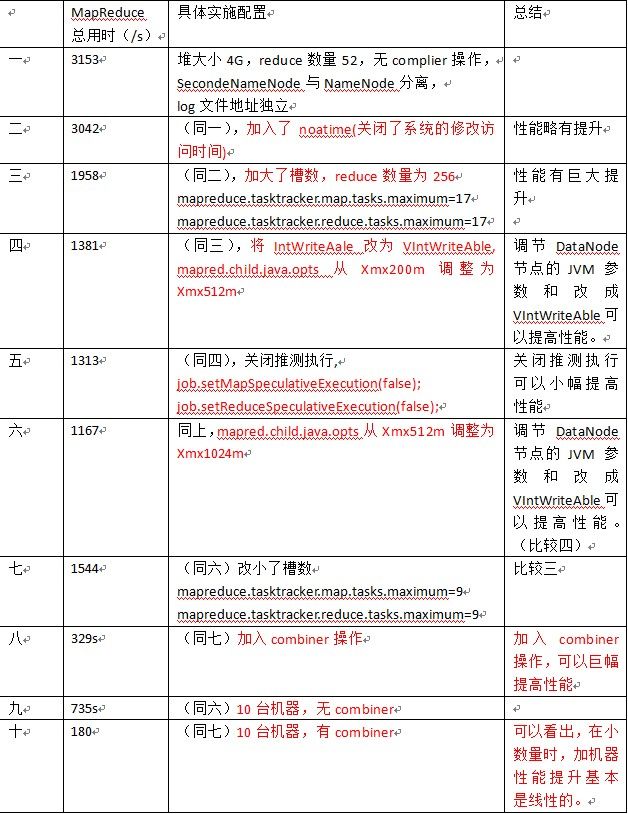
遗留的问题和今后研究的方向
1.本次试验由于机器有限,所以在大量加入机器后性能提升是否线性有待验证。
2.本次试验的数据混乱度不高,有待加入真实数据进行验证
3.本次试验实在hadoop1.0的环境中做的,有待在2.0中试验。
试验结果总结
对hadoop性能优化性能提高的因素排列如下(按照优化幅度从高到低):
1.加入combiner
2.增大map和reduce的槽数
3.加大dateNode上jvm参数
4.加机器
5.改变堆的大小
6.IntWriteAble改成VIntWriteAble
7.SecondeNameNode与NameNode分离
8.关闭noatime
作者简介
昵称:澳洲鸟,猫头哥
姓名:朴海林
QQ:85977328
MSN:[email protected]
本文的研究,离不开《至高天》朋友们的支持
猫头哥:http://phl.iteye.com/
根根:http://blog.csdn.net/suileisl
芝麻的奋斗:http://sesame84.iteye.com/
wan560:http://blog.csdn.net/wan560/
terrily:http://terrily.iteye.com/
本试验目的是为了总结hadoop相关参数优化对性能的影响。
【试验环境】
硬件环境
本次试验用机4台,配置一致:
CPU: Intel(R) Xeon(R) CPU E5620 @ 2.40GHz * 16
内存: MemTotal: 32867608 kB 64bit
linux版本 CentOS release 6.2 (Final)
内核版本 2.6.32-220.el6.x86_64
硬盘 Model: IBM ServeRAID M5015 (scsi)
Disk /dev/sda: 2997GB
Sector size (logical/physical): 512B/512B
软件环境:
JDK: jdk1.6.0_45
Hadoop: hadoop-1.2.1
【试验数据和程序】
试验所用程序为WordCount计数程序(统计每个字母出现的次数),数据源是“ABCDEABC…”的循环
【试验结果统计和总结】
总结相同的配置,此次试验hadoop中备份数均为1份
导入hdfs的数据分析
可以看出在数据导入环节,系能基本呈现线性。
参数优化结果(所使用数据均为10G)
遗留的问题和今后研究的方向
1.本次试验由于机器有限,所以在大量加入机器后性能提升是否线性有待验证。
2.本次试验的数据混乱度不高,有待加入真实数据进行验证
3.本次试验实在hadoop1.0的环境中做的,有待在2.0中试验。
试验结果总结
对hadoop性能优化性能提高的因素排列如下(按照优化幅度从高到低):
1.加入combiner
2.增大map和reduce的槽数
3.加大dateNode上jvm参数
4.加机器
5.改变堆的大小
6.IntWriteAble改成VIntWriteAble
7.SecondeNameNode与NameNode分离
8.关闭noatime
作者简介
昵称:澳洲鸟,猫头哥
姓名:朴海林
QQ:85977328
MSN:[email protected]
本文的研究,离不开《至高天》朋友们的支持
猫头哥:http://phl.iteye.com/
根根:http://blog.csdn.net/suileisl
芝麻的奋斗:http://sesame84.iteye.com/
wan560:http://blog.csdn.net/wan560/
terrily:http://terrily.iteye.com/