深入理解Lustre文件系统-第10篇 LNET:Lustre网络
LNET是一个消息传递API,源自Sandia Portals。虽然它们俩有一些共同点,但是它们俩是不同的东西。我们将探讨LustreLNET,但是不会深入研究这两者的不同。
10.1核心概念
首先,我们需要澄清一些在本节接下来的部分使用的一些术语,特别是进程ID、匹配项、匹配位和内存描述符。
LNET进程ID
LNET使用LNET进程ID来区分它的peer们,定义如下:
typedef struct {
lnet_nid_t nid;
lnet_pid pid;
}lnet_process_id_t;
nid标识节点ID,而pid标识了节点上的进程。例如,对于套接字LND(和对于所有现有的LNETLNDs),在内核空间只运行了一个LNET实例,所以进程id使用一个预留的ID(12345)来标识自己。
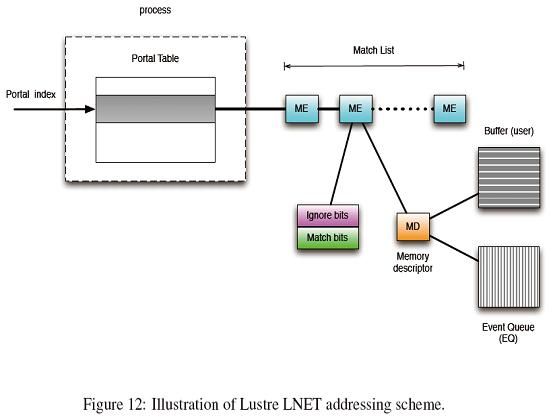
ME:匹配项(Matching Entry)
portal由一个匹配项(ME)的列表组成。每个ME和一个缓冲相联系,缓冲由内存描述符(memory descriptor,MD)描述。ME本身定义了匹配位和忽略位,它们是64比特的标识符,用来确定达到的消息是否可以使用对应的缓冲空间。Figure9.1画出了Lustre LNET的寻址方案。
typedef structlnet_me {
struct list_head me_list;
lnet_libhandle_t me_lh;
lnet_process_id_t me_match_id;
unsigned int me_portal;
__u64 me_match_bits;
__u64 me_ignore_bits;
lnet_unlink_t me_unlink;
struct lnet_libmd *me_md;
} lnet_me_t;
与portal相关联的所有ME都由me_list链接起来。me_match_id定义了哪个远程LNETpeer允许访问这个ME,而这可以用来作为允许开放访问的通配符(wildcard?外卡?)。
MD:内存描述符
在上层创建一个MD之后,LENT层使用结构体lnet_md_t来引用MD。而在LNET内部,则是通过structlnet_libmd_t来表示的。根据我们的理解,这样做的目的是使得lnet_libmd_t对客户端不透明,从而使得它们不能干扰LNET的内部状态。它俩共有一些字段,但是LNET为内部管理(housekeeping)维护了更多状态。
typedef struct {
void *start;
unsigned int length;
int threshold;
int max_size;
unsigned int options;
void *user_ptr;
lnet_handle_eq_t eq_handle;
} lnet_md_t;
如果由MD描述的内存缓冲是连续的,那么start地址指向内存的开始,否则它指向一些I/O向量的开端。I/O向量有两种:如果内存已经映射到实虚拟内存中,它由struct iovec;否则,它由lnet_kiov_t描述,这有可能也有可能不被映射到虚拟内存中,而从定义上看,它只是一个内存页。MD选项(options)描述了I/O向量的类型。它要么是LNET_MD_IOVEC要么是LNET_MD_KIOV。同样,如果MD是一个非连续的内存空间,length就描述了数组中的项数。
如上所述,struct lnet_libmd_t被LNET内部用来描述MD,其中加入了其他一些记录字段:
typedef structlnet_libmd {
struct list_head md_list;
lnet_libhandle_t md_lh;
lnet_me_t *md_me;
unsigned int md_length;
unsigned int md_offset;
unsigned int md_niov;
union {
struct iovec iov[LNET_MAX_IOV];
lnet_kiov_t kiov[LNET_MAX_IOV];
} md_iov;
...
}
显而易见的是,md_me是与当前MD相关联的的ME项的地址,而它可以是NULL。md_length是MD描述的所有部分的总字节数,而md_offset是跳过的字节数。对于一个非连续的内存,假想它们都组合到一个虚拟的连续数组,而你有一个用以进入其中的逻辑偏移量。而md_niov是I/O向量的有效项数,I/O向量由union结构体中的iov或者kiov描述。md_list是一个以句柄(md_ld)作为关键字用来定位MD的哈希表。
偏移量的使用实例
在初始化时,服务器将发布请求缓冲(为请求portal),缓冲是用来容纳接收到的客户端请求的。我们进一步假设请求缓冲大小是4KB,而每个请求最多是1KB。当第一个消息到达时,偏移量增加到1KB,而当第二个消息到达时,偏移量设置为2KB,如此继续。所以,本质上说,偏移量是为避免覆盖写而用来追踪写位置的,而这就是默认的情况。在另外一种情况下,偏移量有不同的用法,我们将在讨论完MD选项之后对之进行描述。
MD选项
如果MD的设置了LNET_MD_MANAGE_REMOTE标志,那么客户端可以为了执行GET或者PUT操作,而向MD指定偏移量。在接下来的API讨论中,我们将描述GET和PUT API的偏移量选项,我们现在描述两种使用情形:
- 路由器发布一个包含nid的缓冲,以给感兴趣的客户端读,该缓冲设置了LNET_MD_MANAGE_REMOTE和LNET_MD_OP_GET标志。所有的客户端将会得到偏移量为零的这个缓冲,因为他们得到了路由器上nid的完整列表。
- 在使用自适应的超时机制时,对于提早的服务器回复的情况,客户端在发出请求之前,发布一个回复缓冲。服务器首先以偏移量为零,发送一个提早的回复。其含义是:“我收到你的请求啦,现在耐心等待吧”。然后,服务器端以一个合适的偏移量,向同一的缓冲发送实际的回复。
与MD相关的另外一个属性类型定义了在MD上允许的操作。例如,如果MD只设置了取得标志LNET_MD_OP_GET,那么就不允许向MD写入。这与只读模式等价。而LNET_MD_OP_PUT则意味着MD允许PUT操作,但是如果没有GET标志,那么就变成只写了。
当出现到达的消息比当前MD缓冲大的情况下,有两个标志用来处理这种情况。LNET_MD_TRUNCATE标志允许存储这个消息,但是要截短。当客户端不关心回复的内容时,这个标识是有用的。举个例子,让给我们假设一个客户端ping路由器来来查看它是否还活着。路由器回复了一个它的nid的列表。客户端不关需其内容,也不解释这些nid,所以一个设置了截短标志的小缓存就足够了。第二个标志是LNET_MD_MAX_SIZE,它告知LNET丢掉那些接收到的超出允许大小的消息。
事件队列
每个MD都有一个事件队列,事件都向事件队列传送。每个事件队列可以用回调函数,或者可以被调查。
10.2 Portal RPC:LNET的客户端
Portal RPC设计为对每个定义的服务有多个portal,它们是请求、回复和块portal。我们使用一个例子来解释着一点。假设客户端想要向服务器读十块数据。它首先向服务器发送一个RPC请求,表明它想读取十个块,而它已经准备好了块传输(即已经准备好了块缓冲)。这时,服务器初始化块传输。当服务器完成传输后,它通过发送一个请求来告知客户端。通过这个数据流,我们清楚了客户端需要准备两个缓冲:一个是为块RPC提供的与bulkPortal相关联的缓冲,一个是与恢复Portal相关联的缓冲。
这就是Lustre怎样使用Portal RPC的。在上述情形中,它使用两个portal,因为Portal RPC对两个portal使用同样的ME匹配位。然而,只要两个缓冲的匹配位不同,使用同一个portal来发布两个缓冲就不会有问题。
Get和Put混淆
- 大多数情况下,客户端调用LNetPut来向服务器请求一些东西,或者请求向服务器发送一给些东西。然后服务器将使用LnetPut来向客户端发送一个回复,或者像块传输里一样,使用LnetGet来从客户端读取一些东西。
- 客户端调用LNetGet的一个情况是路由pinger;客户端将从一个广为人知的服务器portal取得一个NID列表,以此作为确定路由还活着的方法。
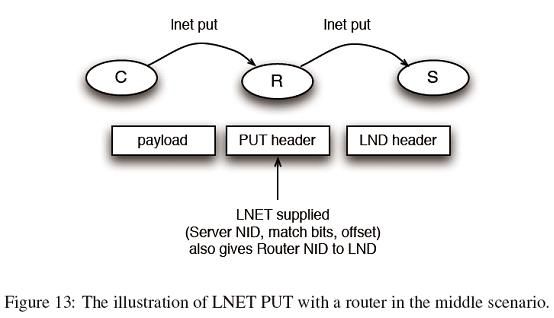
处在中心的路由
我使用LNET PUT作为例子来解释这个情景。让我们假设客户端C有一些需要发往最终目的服务器S的有效载荷,而R则是发送所需要经过的处于中心的路由器,如Figure 13所示。LNET取得有效载荷,并填以PUT头,PUT头中包含诸如最终服务器NID、匹配位、偏移量等信息。现在这是一个完整的LNET消息。当LNET将该消息和路由NID一起传给LND层。LND将这些消息放在传输线上,消息传往R。
路由LND层接收到这个消息,并将之传到路由LNET层。需要从消息的PUT头中取得两部分信息。一个是消息的大小,这样路由才能分配(或者预分配)空间来存储接收到的消息,注意这里的空间和我们之前谈及的MD不同,它只是一块缓冲。第二个信息是目的NID。在消息完全接受完后,路由LNET将把这个消息和NID一起传送给合适的LND(可能是另外一个LND,如果这个一个混杂的路由环境中)来将之传送到传输线上。
10.2.1第一轮:客户端服务器端的合作
假设服务器端想要向它的客户端发布一个缓冲,如下对是在两者中出现的步骤的简要描述:
1. 服务器连接ME和MD,使它们成为某个已知portal的一部分。
2. 服务器确保MD选项设置是正确的:对于这种情况下的远程管理,只允许取(get-only)。现在服务器准备好了。
3. 如果客户端准备本地ME和本地MD,为回复请求做准备。
4. 客户端按照peer地址、portal、匹配位来调用LNET GET。
5. 服务器收到GET消息,检查它是否有效(正确的portal、正确的匹配位,对MD的正确操作)。
6. 服务器调用MD上注册的回调函数来告知高层。在我们早前提及的路由ping情况下,一旦发布了缓冲,上层服务器就可能不再对客户端请求感兴趣了,所以这个回调函数可能就是NULL。
7. 服务器向客户端发送一个回复消息。注意这个回复不是一个LNET PUT。
10.2.2第二轮:更多细节
1. 服务器通过ptlrpc_register_rqbd()发布了一个请求缓冲。_rqbd是对请求缓冲描述符(request buffer descriptor)的缩写,由structptlrpc_request_buffer_desc定义。它为创建ME和MD提供了足够的信息。由于这是一个用来服务请求的服务缓冲,其匹配ID及所有重要的ME、MD创建方法如下所示:
structptlrpc_service *service = rqbd->rqbd->rqbd_service;
staticlnet_process_id_t match_id = {LNET_NID_ANY, LNET_PID_ANY};
rc =LNetMEAttach(service->srv_req_portal, match_id, 0, ?0,
LNET_UNLINK,LNET_INS_AFTER,&me_h);
rc =LNetMDAttach(me_h, md, LNET_UNLINK, &rqbd->rqbd_md_h);
LNET_UNLINK标示当ME对应的MD删除(unlink)的时候,这个ME应该被删除。而LNET_INS_AFTER意味这个新的ME应当添加到已存在的ME链表里。me_h和md分别定义为handle_me_t和lnet_md_t。
2. 客户端通过ptl_send_rpc()发送RPC,这个函数将struct ptlrpc_request *request作为一个输入参数,可能进行如下操作:
- 客户端通过ptlrpc_register_bulk()发布一个块缓冲。这个是在请求的块缓冲不为NULL时执行的:
if(request->rq_bulk != NULL) {
rc =ptlrpc_register_bulk(request);
...
- 客户端通过LNetMEAttach()和LNetMDAttach()发布回复缓冲,这个操作是在期望得到回复的时候执行的(输入参数noreply设置为0)。
- 客户端发送请求:
rc =ptl_send_buf(&request->rq_req_md_h,
request->rq_reqmsg,request->rq_reqlen,
LNET_NOACK_REQ,&request->rq_req_cbid,
connection,
request->rq_request_portal,
request->rq_xid,0);
3. 服务器通过evernts.c中定义的request_in_callback()来处理接收到的RPC、这可能进一步引发两个动作:
- 块传输:ptlrpc_start_bulk_transfer(),
- 发送回复:ptlrpc_reply()。
4. 一旦块传输被写入、读取或者回复了,可能引发等多的回调,例如client_bulk_callback()和reply_in_callback()。
10.3 LNET API
命名习惯
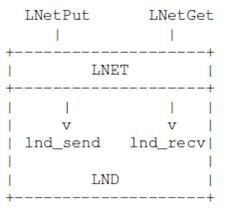
以LNet开始的函数名是为高层提供的外部API。所有其他使用小写的函数是LNET内部使用的函数。在LNET里,LND有两个API集合。如果以lnd开头,则是是为LNET向下调用而准备的API;而如果以lnet开头,则是为LND向上调用LNET而准备的;如下图所示。注意,使用LNET来同时表述整个网络子系统和一个LND之上的一个特殊层是很让人容易迷惑的,但是好像实际就是这么用的。
LNET在内核空间和用户空间都编译了。如果文件以liblnet开头,那么意味着它是为用户空间准备的;否则这是为内核准备的。在lnet/lnet下的文件编译了两次,在lnet/klnds和lnet/ulnds只被编译了一次。
初始化和拆除
intLNetInit(void)和intLNetFini(void)是用来建立和拆除LNET连接的API。
面向内存的通信语义
如下的API已经由注释注解了:
int LNetGet(
lnet_nid_t self,
lnet_handle_md_t md_in, /* local MD to hold requested data */
lnet_process_id_t target_in, /* target process id */
unsigned int portal_in, /* target portal index */
__u64 match_bits_in, /* match bits used on targetprocess */
unsigned int offset_in); /* offset into remote MD */
这个函数初始化了远程读操作。注意offset_in只有在目标内存描述符中设置了LNET_MD_MANAGE_REMOTE时才被使用。对PUT操作,也是如此。
int LNetPut(
lnet_nid_t self,
lnet_handle_md_t md_in, /* local MD holding data to be sent */
lnet_ack_req_t ack_req_in, /* flag to request Ack event */
lnet_process_id_t target_in, /* target process id */
unsigned int portal_in, /* target portal index */
__u64 match_bits_in, /* match bits for target process*/
unsigned int offset_in, /* offset into remote MD */
__u64 hdr_data_in); /* 64-bit user data */
这个函数异步地发送数据。self设定了使用的源NID和输出的NI(网络接口,network interface)。如果给定了LNET_NID_ANY,LNet将根据目的NID和路由表自行选择源NID和NI。注意,acknowledgments只有在它们被初始化进程中的进程请求,并且本地MD有事件队列,且远程MD允许时,才被发出。
匹配项管理
int
LNetMEAttach(unsignedint portal,
lnet_process_id_t match_id,
__u64 match_bits, __u64 ignore_bits,
lnet_unlink_t unlink, lnet_ins_pos_t pos,
lnet_handle_me_t *handle)
这个函数创建了一个新的ME。第一个参数表明ME需要和哪个本地portal联系,而下一个参数表明了允许访问这个ME的运程进程id(或远程peer)。接下来的是匹配位和忽略位。每个portal RPC都有一个独有的事务id,所以portal RPC使用这个事务id来作为回复的匹配位。事务id将被发送给远程peer,而远程peer将使用这个事务id来作为它的回复缓冲的匹配位。最后一个参数是ME指针,如果调用成功,它返回一个句柄。
int LNetMDAttach(
lnet_handle_me_t meh, /* ME to beassociated with */
lnet_md_t umd, /* user-visible part of theMD */
lnet_unlink_t unlink, /* if MD is unlinkedwhen it is not active */
lnet_handle_md_t *handle)
这个函数用来创建MD,并将它连到一个ME上。如果ME已经与一个MD相关联,则出错返回。umd是从LNET客户端(现在为止,是Portal RPC或者LNET自测)来的,它指定了将创建的MD对象的参数,函数将以lnet_handl_md_t *handle参数返回一个该对象的句柄。
int LNetMDBind(
lnet_md_t umd,
lnet_unlink_t unlink,
lnet_handle_md_t *handle)
这个函数创建一个独立的内存描述符,即一个未与ME相关联的MD。
10.4 LNET/LND语义和API
LNET是无连接的、异步的和不可靠的。然而,大部分LND是可靠的、面向连接的,所以在同它们的peer交流之前,它们需要建立一个连接。LNET消息的有效载荷限制是1MB,且最大的段数量不超过256。另外,LNET既不分段也不组合段。LNET假定了上层绝不会传给LNET大于1MB的有效载荷。这个限制的理由有几个——例如,提前设置的限制使得缓冲管理变简单,一些低层驱动的零散缓冲数是有限制的,例如是256个。另外,如果缓冲室以页的方式发布,诸如Portal RPC等高层可以更容易地对数据进行分段。这个限制的缺点是一旦有一个支持多于1MB的MTU的网络技术出现,LNET可能不能充分地使用其带宽。
LND可以有多个实例——例如,在你有多个IB接口的时候。每个接口都由一个网络接口类型表示,该类型由lnet_ni_t定义。在该结构体中定义的其中一个字段是lnd_t——一个对该特定LND类型可用的方法表。
10.4.1API总结
LND API是在LNET和它的基础网络驱动之间的接口。正如之前提到的,有两组LND API。第一组是LNET期望LND实现的。例如:LNET期望调用LND方法来发送和传输消息。
- lnd_startup()、lnd_shutup():这些函数对每个接口调用,只要当LNET想要打开或者删除这些接口。
- lnd_notify():这是可选的。
- lnd_accept():这是可选的。
- lnd_send()、lnd_recv()、lnd_eager_recv():发送正在送出的消息和接收正在来到的消息。
- lnd_ctl():这个调用是可选的。它将用户空间的ioctl命令传送到LND。LNET通过一个特殊的设备文件,支持许多ioctl;一些是由LNET直接处理(例如,增加路由),另外一些必须传递到LND处理。
另外一组API是提供给LND用的LNET函数:
- lnet_register_lnd()和lnet_unregister_lnd():每个LND驱动都调用这个函数来注册一个新的LND类型。
- lnet_notify():一个peer挂了,调用这个函数告知LNET。
- lnet_parse():对每个接收到的新消息,LND调用这个函数来让LNET知道接收到了一个消息,这样LNET可以分析并调查它。
- lnet_finalize():这个函数在消息进入和传出时都被LND调用。当发送消息时,它被LND调用,用来允许LNET创建一个事件,以告知消息已被发送了。对消息到达,这个调用表明已经完全接收了正在到来的消息的有效载荷。
10.5 LNET开启和数据传输
对于LNET源码组织的简单评注:
lnet/ulnds /*LND in user space, */
lnet/klnds /*LND in kernel space */
lnet/lnet /*LNET layer */
显然,在内核LND和用户空间LND的源码并没有多少相同。因此,只有Portal网络和TCP网络有用户空间LND。在内核空间,ptllnd、o2iblnd和socklnd可能是需要知道的最重要的几个。
10.5.1开启
当LNET初始化后,调用lnet_startup_lndnis()。
1. 调用lnet_parse_networks()来分析用户提供的模块参数。之后,LNET得到一个需要启动的网络接口列表。
2. Iterate(?)上面得到的每个接口。首先它尝试定位由lnd_t表示的lnd实例。当找到时,调用lnd_startup()。我们将看看每个步骤的细节。
3. 在循环中,首先通过网络类型查找驱动。
lnd =lnet_find_lnd_by_type(lnd_type);
如果没有找到驱动,可能是驱动还没有加载,所以将尝试加载模块,然后重试定位驱动:
rc =request_module(libcfs_lnd2modname(lnd_type));
在驱动加载后,在它初始化过程中,它向LNET注册,使得驱动能在稍后被定位到。
4. 在定位了网络接口的驱动之后,我们可以将驱动绑定到该接口,然后调用驱动的开启方法:
ni->ni_lnd =lnd;
rc =(lnd->lnd_startup)(ni);
现在,我们开始解释一个特定的LND模块,套接字LND。特别地,我们看看ksocknal_startup()。
1. 如果函数第一次被调用,那么它将调用ksocknal_base_startup()来做一些单次初始化,例如创建所有接口共用的数据结构。
2. 找到使用这个网络的以太网接口。它可能是用户指定的,也可能是找到的系统第一个非循环接口。一旦找到,它将为这个接口初始化数据结构。nid按如下方法创建:
ni->ni_nid =LNET_MKNID(LNET_NIDNET(ni->ni->nid),
net->ksnn_interfaces[0].ksni_ipaddr);
在LNET创建后,用户可以通过这个接口发送或接受数据。
10.5.2LNET发送
我们从LNetPut开始一直下到LND层,描述发送过程的一般流程。
1. 首先,分配LNET消息描述符msg,由struct lnet_msg_t描述。这个消息描述符将传递给LND。特别地,里面定义了一个lnet_hdr_t msg_hdr(消息头),它将最终成为传输线上的消息的一部分。
msg =lnet_msg_alloc();
2. LNET MD句柄被从输入参数转换到实际MD结构,里面存储了有效负载。
md =lnet_handle2md(&mdh);
3. 将MD与消息相关联:
lnet_commit_md(md,msg);
4. 填入消息细节。如果存在的话,这些细节可能是消息的类型(PUT或者GET)、匹配位、portal索引、偏移量和用户提供的数据。
lnet_prep_send(msg,LNET_MSG_PUT, target, 0, md->md_length);
msg->msg_hdr.msg.put.match_bits= cpu_to_le64(match_bits);
msg->msg_hdr.msg.put.ptl_index= cpu_to_le32(portal);
...
5. 如下所示,填入事件信息:
msg->msg_ev.type= LNET_EVENT_SEND;
msg->msg_ev.initiator.nid= LNET_NID_ANY;
msg->msg.ev.initiator.pid= the_lnet.ln_pid;
...
6. 最后如下所示,调用lnet发送函数(不是LND发送)。
rc =lnet_send(self, msg);
7. 这个发送函数需要定位使用的接口。如果目标是本地的,则解析到直连接口。如果目的地是远程的,则解析到路由表中的一个路由。这个搜索的结果是lp,由structlnet_peer_t定义,定义了peer的最佳选择。这个peer要么是路由的接口,要么是最终目的地的接口,如下所示。
msg->msg_txpeer= lp;
8. 然后,调用lnet_post_send_locked()来检查credit(?)。假设你只允许向peer发送x个并行消息。如果你超过了这个credit阈值,这个消息将排队,直到了更多的credit。
9. 如果通过了credit检查,那么:
if (rc==0)
lnet_ni_send(src_ni, msg);
这个发送函数调用LND发送,进行下一步发送:
rc =(ni->ni_lnd->lnd_send)(ni, priv, msg);
在以后的某一时间点,在LND发送消息结束后,将调用lnet_finalize()来告知LNET层,消息已经发送完毕。然而,让我们继续深入发送消息的过程。让我们假设这是一个IP网络;那么发送的就是套接字LND,更确切地说,将调用ksocknal_send()。
10. 记住,套接字LND是基于连接的,所以当你想要发送某些东西的时候,首先你需要定位peer,然后你需要检查是否建立了连接。如果有,你只需将tx加入到连接队列中。
if (peer!=NULL){
if(ksocknal_find_connectable_route_locked(peer) == NULL) {
conn =ksocknal_find_conn_locked(tx->tx_lnetmsg->msg_len, peer);
if (conn != NULL) {
ksocknal_queue_tx_locked(tx,conn);
...
}
所以,最终,排队的消息将通过内核套接字API,来在套接字连接上发送。
11. 如果还没有连接,那么我们先将消息排队到peer,这样当建立了新连接后,我们可以从peer的队列中将消息移至连接的队列里,将它们发生出去。
在传输线上传输的消息的简要布局如下:

从一个套接字LND中发送消息有两种方式(API):如果消息较小,正常发送将会把消息送入一个内核套接字缓冲中(每个套接字都有一个发送缓冲)。这不是一个零复制(zero-copy)传输。另外,你可以先不复制(零复制),而将缓冲直接发送到网络中去。然而,零复制也有它的开销,所以Lustre只使用这种流程发送大消息。
10.5.3 LNET接收
在接受端,假设我们使用套接字LND,ksocknal_process_receive()是接收的入口函数。这里给出了一般步骤。
1. LND开始接受新消息。开始时,它只接受截止到LNET消息头的部分,因为它现在还不知道将有效负载放在哪个地方,只有LNET层知道目标MD的信息。
由于这个原因,LND将LNET头传给lnet_parse()。这个函数中,LNET层将查看头,并且确定portal、偏移量、匹配位、源NID、源PID等。LNET可能拒绝消息(例如畸形消息),也可能接受它。
2. 如果定位了合适的MD,LNET(从lnet_parse())调用另外一个LND API,lnd_recv()。现在套接字内核缓冲中的有效载荷被复制到目的MD。在套接字LND情况下,这是一个内核中内存到内存的复制。
3. 如果LNET在以后某个时间点要调用lnd_recv(),则会立即调用lnd_eager_recv()。
4. 在LNET调用lnd_recv()后,LND开始接收锁有效载荷(要么是通过内存到内存的复制,要么是通过RDMA),而LND应当在有限的时间内调用lnet_finalize()。此时,如果RDMA可用,LND可以使用它来传输数据。
同时注意TCP可能会进行分段,但是当lnd_recv()结束时,在对消息组段(de-fragmenting)之后,它传输了整个消息。
10.5.4 对于RDMA的情况
我们提到,在套接字LND中有一个内存到内存的复制。对于任一支持RDMA的网络,例如o2ib LND,它可以使用RMDA将数据之间传输到目的MD,从而避免了内存到内存的拷贝。更完整的配合过程如下:
1. LNET PUT将消息传送到o2ib LND。现在o2ib LND又两部分信息:一个LNET信息头,里面保存了诸如源NID、目的NID和一个指向实际有效载荷的MD。
2. 与套接字LND不同,o2ib LND只通过网络向peer发送(使用OFED API)了LNET头。消息包含了一个o2ib LND头,其中表明这是一个o2ib PUT请求。
3. 在接收端,o2ib LND仍然调用lnet_parse(),因为它有LNET头信息,由此它确定了MD。然后调用lnd_recv()来接收数据。o2ib的lnd_recv()将首先向OFED注册MD缓冲。在注册内存后,它取得了一个OFED内存ID,它与注册好的内存等价。
4. 现在o2ib向发起人发回另外一个消息(PUT ACK),其中携带了远程内存ID。发起人向它的保有有效载荷的本地MD注册了这个消息,并且取得了一个本地内存ID。最后,它调用RDMAwrite,将控制传给OFED作进一步处理。
10.6 LNET路由
一般概念
Lustre路由有两个基本特征。第一个是Lustre网络内的所有节点可以直接相互通信,而不需要路由层的参与。第二个是,Lustre路由是静态路由,它的网络拓扑是静态配置的,在系统初始化时就已分析好了。在运行时,可以更新配置,系统会对之响应,然而,根据我们的了解,这种动态更新和基于距离向量或者链接状态的路由非常不同。
对于Lustre网络的一个粗陋定义是:一组可以相互之间直接通信而不需路由参与的节点群。每个Lustre网络都有一个唯一的类型和号码,例如tcp0、ib0、ib1等等,每个端节点(end node)都有一个NID(网络标识符,NetworkIdentifier)。Figure 9.6画出了一个路由层的栈的实例。这个定义有一些artifact(?):(1) 它与IP子网和IP路由毫无关系。如果你有两个网络和一个两者之间的IP路由器,它仍然可以看作是一个Lustre网络。(2) 如果你有一个TCP接口的端节点,和另一个有IB接口的端节点,那么你在两者之间需要有一个LNET路由,这将被看做两个Lustre网络。(3) Lustre网络中的地址必须是唯一的。
上述定义的另外一个暗示是,端节点的路由表将把LNET路由而不是IP路由作为下一跳。为了确定一个Lustre网络,你通常会使用networks和ip2nets这两个指令中的一个:
# router
options lnetnetworks = tcp0(eth0), tcp1(eth1)
# client
options lnetnetworks = tcp0
# singleuniversal modprobe.conf
options lnetip2nets="tcp0(eth0,eth1) 192.168.0.[2,4]; tcp0 192.168.0.*; \
elan0 132.6.[1-3].[2-8/2]"

10.6.1非均匀路由的失败之处
这个题目强调了我们在当前的LNET(production)源码的不足之处。它和对LNET的一般性讨论时有关的,而我们相信和更多的读者分享我们的观察是有益的。这里的问题是,路由很难可靠地确定一个接口是否挂掉了。当前,LNET甚至都不会尝试去确定这个事。所以对于一个有两个接口的路由,比如说tcp0和ib0,如果ib0接口挂了,而与tcp0连接的接口仍然在发送数据,这将导致一个间歇性的通信失败。
解决这个问题的一种思想是LNET路由可以尝试监测传输问题,然后暂时性地关闭所有接口。路由可能有能力更加智能地处理这个问题:如果它了解整个拓扑和客户端使用的输入路径的信息,那么它可以只关闭一些接口。在那之前,相比于因间歇性失败而遭受超时,关闭所有的接口似乎要好些。
10.6.2路径缓冲管理和流控制
在初始化时,LNET路由预分配了一个确定数量的路由缓冲。端节点的LNET层不需要这样做(除非在初始化它的路由表时)。分配和管理路由缓冲,是端节点和路由的执行逻辑之间的主要区别,如果不是唯一的区别。
由于路由缓冲是受限资源,为了防止单一端节点淹没路由,每个节点都给定了一个限额。缓冲只有在转寄(forwarded)之后,才能够重新使用。对每个端节点的限额也被称为缓冲credit。它只对路由有意义,和“传输中的RPC”credit不同,后者称为peer到peer credit。一个RPC可以牵涉到多个LNET消息(最多十个),这些可能是一个请求LNET消息,一个回复LNET消息,而在块传输的情况下,可能有四个LNET消息发往一个方向,而四个LNET消息发往相反的方向。这也暗示了块传输LNET消息是块RPC事务的一部分,但是它们不被算作一个RPC。所以它们(这四个块传输消息)不被算作是正在传输中的RPC。
有三种路由缓冲:1MB(一个LNET消息可以携带的最大有效载荷量),为小消息准备的4KB,和为诸如ACK等极小消息准备的有效载荷为零的缓冲。
从一个端节点发来的请求遵循先来先服务的原则。如果从一个特定端节点的请求超过了它的限额,那么它的下一个请求将不会被处理,直到路由缓冲被释放,这就是LNET层进行流控制的本质方法(流控是点到点的)。点到点的流控制是由更上层来实现的,例如,通过正在传输的RPC数(RPCs inflight)。在下层LND调用了lnet_finalize()之后,缓冲就可以释放了。调用lnet_finalize(),标志着LND将运送看作结束了,但并不意味这消息已经放在传输线上了。根据消息大小,LND和内核有处理它的不同逻辑。对于LNET的唯一要求是,一旦lnet_finalize()调用了,LNET就可以自由地回收利用缓冲了。
逻辑上,LNET只有一个队列,从所有端口到达的消息都入队列,并按序做进一步处理。每个接口都有它自己的接口队列,然而这不是LNET关心的事,因为这是中断驱动的。所以,每个到达消息都按其到达的顺序接受处理是有保证的。
10.6.3细粒度路由
这个特性是最近开发出来的(Lustre bug #15332)for Jaguar/Spider deployment at ORNL。其驱动是LNET不向路由指定负载。所以如果你有多个连接同一个目的的路由,LNET将会执行一个roundrobin算法来分配负载,对端节点和路由都是这样的。细粒度路由加入的是,简单地,对不同的路由,指定由系统管理员预先配置的负载。其目的是让更好的路由负责更多的流量。这里的更好是由site(?)系统管理员定义的。
dest network 1:
w1 (router 1, router 3)
w2 (router 4, router 5)
w3 (router 2)
例如,你可以指定不同的负载级别,然后指定路一个级别,以表示你的偏好。如果w1<w2,那么w1是两者之中偏好的负载级别。在给定的负载级别里,路由器是相等的。
对我们这个情况里,更明确的是,这个机制提供了一个可能性:客户端可以选取一个离他更近的路由器作为它偏好的路由。
本文章欢迎转载,请保留原始博客链接http://blog.csdn.net/fsdev/article