Unicode和UTF-8
很老的话题了,网上一堆一堆的。所以再堆一篇也无所了,来澄清一些原来模糊模糊的了解。
Unicode是啥不多说,人类为了克服巴别塔的悲剧而创造的标准化道路的一个产物。
以下是大段的维基百科[1]的内容:
“Unicode 的编码方式与 ISO 10646 的通用字符集(Universal Character Set,UCS)概念相对应,目前实际应用的 Unicode 版本对应于 UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示 2^16 即 65536 个字符。基本满足各种语言的使用。实际上目前版本的 Unicode 尚未填充满这16位编码,保留了大量空间作为特殊使用或将来扩展。16位 Unicode 字符构成基本多文种平面(Basic Multilingual Plane,简称 BMP
……
Unicode 的实现方式不同于编码方式。一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。Unicode 的实现方式称为Unicode转换格式(Unicode Translation Format,简称为 UTF
例如,如果一个仅包含基本7位ASCII字符的 Unicode 文件,如果每个字符都使用2字节的原 Unicode 编码传输,其第一字节的8位始终为0。这就造成了比较大的浪费。对于这种情况,可以使用 UTF-8 编码。
”
所以二者的关系是UTF-8是Unicode的具体实现方式(表现形式、使用方式),而Unicode是编码的值。(UTF-8 is the way in which Unicode is used under Unix, Linux, and similar systems. )。需要注意的是UTF-8是专门针对Unicode的,因此如果想从GBK转到UTF-8需要先转到Unicode。
而与UTF-8的UTF-16也是Unicode的一种实现方式(表现形式、使用方式)。在BMP内的符号UTF-16使用2 个字节表示,辅助平面是使用4个字节表示。UTF-16的缺点有:1.无法相容于ASCII编码。2.大尾和小尾的混乱(从Mac到Win时的麻烦)。优点是它的固定字节。其具体的编码方式可以Google.
Unicode 的实现方式还包括 UTF-7、Punycode、CESU-8、SCSU、UTF-32等。不太常用,就没去细究了。
UTF-8的编码方式去调查了一下。其两个特点是:1.兼容ASCII 2.变长,1-4字节。具体编码方式如下:
每个字节都分为4种类型,按打头的1的个数(紧接着0)来区分。比如11110XXX就是类型4,1110XXXX是类型3,类推,不同的是类型1并非10XXXXXX而是0XXXXXXX。为啥?兼容ASCII!!
对多字节的UTF-8码并非每个字节可以使这4个类型的任一种。因为如果一个3字节的UTF-8码的第三个字节是1型的,那就会被解释成1个2字节码和一个1字节码(当然2字节那部分也需要按要求)。所以不能是1型的,而如果2,3,4型则会是码的表示范围变小,所以对多字节的码除最高字节外都是10开头的(就是那个“按道理”推的类型1)。
说的可能比较含糊,下面的表格就很清楚了。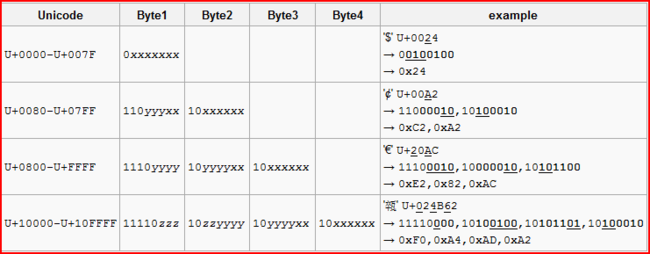
[2]
因此UTF-8的分布是:开始的128个字元是ASCII码,接下来双字节编码的1920个字符,包括带附加符号的拉丁字母,希腊字母等,希伯来文字母和阿拉伯字母的字元。基本多文种平面中其余的字元使用三个字节,剩余字符使用四个字节。
不过疑惑的是为什么在U+10FFFF截止了,因为按上述表格理论上是可以表示到U+1FFFFF。查了一下大概是因为RFC 3629的限制,UTF-8只能表示正式的Unicode的定义,即U+0000到 U+10FFFF。
所以,从另一个角度UTF-8的特定数值范围的字节是只能出现在多字节序列的某个位置或者有其他限制(比如非法)。
具体的如下:
[2]
更多限制参见[2]。
总体来说,UTF-8的编码方式保证了一个字符的位元组序列不会包含在另一个字符的位元组序列中。这确保了以位元组为基础的子串匹配(sub-string match)方法可以适用于在文字中搜寻字或词。虽然UTF-8编码的字串也存在信息冗余,但是利多于弊。更何况压缩并非Unicode 的目的,所以不可混为一谈。
关于UTF-8的缺点,有一个有意思的是在正则表达式这块。
“
正则表达式可以进行很多英文高级的模糊检索。例如,[a-h]表示a到h间所有字母。同样GBK编码的中文也可以这样利用正则表达式,比如在只知道一个字的读音而不知道怎么写的情况下,也可用正则表达式检索,因为GBK编码是按读音排序的。只是UTF-8不是按读音排序的,所以会对正则表达式检索造成不利影响。但是这种使用方式并未考虑中文中的破音字,因此影响不大。Unicode是按部首排序的,因此在只知道一个字的部首而不知道如何发音的情况下,UTF-8 可用正则表达式检索而GBK不行
”
[3]
这样对Unicode,主要是UTF-8大概有了个初步的了解,更多的可以看看http://www.cl.cam.ac.uk/~mgk25/unicode.html
[1] http://zh.wikipedia.org/zh-cn/Unicode
[2] http://en.wikipedia.org/wiki/UTF-8
[3] http://zh.wikipedia.org/zh-hans/UTF-8