Field types for structured nontext fields
In general, Solr provides a number of built-in field types for structured data, such as numbers, dates, and geo location fields.
String fields
Solr provides the string field type for fields that contain structured values that shouldn’t be altered in any way. For example, the lang field contains a standard ISO-639-1 language code used to identify the language of the tweet, such as en.
<fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
Date fields
A common approach to searching on date fields is to allow users to specify a date range.
<field name="timestamp" type="tdate" indexed="true" stored="true" /> <fieldType name="tdate" class="solr.TrieDateField" omitNorms="true" precisionStep="6" positionIncrementGap="0"/>
In general, Solr expects your dates to be in the ISO-8601 Date/Time format (yyyy-MM-ddTHH:mm:ssZ);
Z is UTC Timezone.
DATE GRANULARITY <field name="timestamp">2012-05-22T09:30:22Z/HOUR</field>
Numeric fields
<field name="favorites_count" type="int" indexed="true" stored="true" /> <fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
Because we don’t need to support range queries on this field, we chose precisionStep="0", which works best for sorting without incurring the additional storage costs associated with a higher precision step used for faster range queries. Also, note that you shouldn’t index a numeric field that you need to sort as a string field because Solr will do a lexical sort instead of a numeric sort if the underlying type is stringbased.
Advanced field type attributes
Solr supports optional attributes for field types to enable advanced behavior.

-------------------------------------------------------------------------------------------------------------------------------------
Sending documents to Solr for indexing


Importing documents into Solr
- HTTP POST
- Data Import Handler (DIH)
- ExtractingRequestHandler, aka Solr Cell
- Nutch
-------------------------------------------------------------------------------------------------------------------------------------
Update handler
In general, the update handler processes all updates to your index as well as commit and optimize requests. Table 5.7 provides an overview of common request types supported by the update handler.



Committing documents to the index
- NORMAL/HARD COMMIT A normal or hard commit is one in which Solr flushes all uncommitted documents to disk and refreshes an internal component called a searcher so that the newly committed documents can be searched.
- SOFT COMMIT A soft commit is a new feature in Solr 4 to support near real-time (NRT) searching. For now, you can think of a soft commit as a mechanism to make documents searchable in near real-time by skipping the costly aspects of hard commits, such as flushing to durable storage. As soft commits are less expensive, you can issue a soft commit every second to make newly indexed documents searchable within about a second of adding them to Solr. But keep in mind that you still need to do a hard commit at some point to ensure that documents are eventually flushed to durable storage.
AUTOCOMMIT
For either normal or soft commits, you can configure Solr to automatically commit documents using one of three strategies:
- Commit each document within a specified time.
- Commit all documents once a user-specified threshold of uncommitted documents is reached.
- Commit all documents on a regular time interval, such as every ten minutes.
When performing an autocommit, the normal behavior is to open a new searcher.But Solr lets you disable this behavior by specifying <openSearcher>false</openSearcher>. In this case, the documents will be flushed to disk, but won’t be visible in search results. Solr provides this option to help minimize the size of its transaction log of uncommitted updates (see the next section) and to avoid opening too many searchers during a large indexing process.


Transaction log
olr uses a transaction log to ensure that updates accepted by Solr are saved on durable storage until they’re committed to the index. Imagine the scenario in which your client application sends a commit every 10,000 documents. If Solr crashes after the client sends documents to be indexed but before your client sends the commit, then without a transaction log, these uncommitted documents will be lost. Specifically, the transaction log serves three key purposes:
- It is used to support real-time gets and atomic updates.
- It decouples write durability from the commit process.
- It supports synchronizing replicas with shard leaders in SolrCloud
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
Every update request is logged to the transaction log. The transaction log continues to grow until you issue a commit. During a commit, the active transaction log is processed and then a new transaction log file is opened.
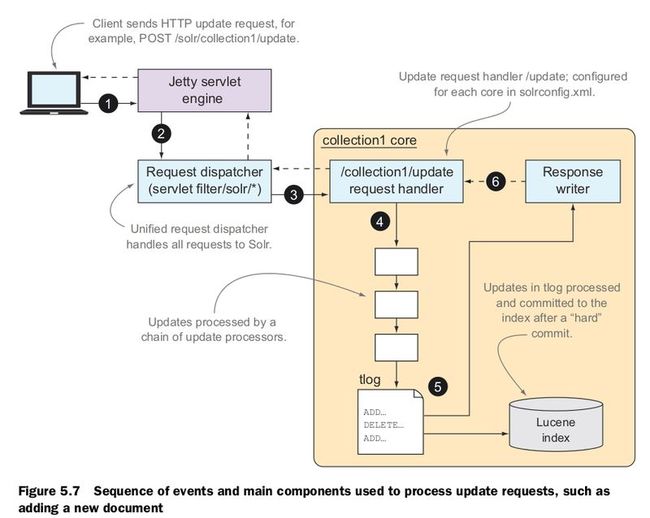
With the transaction log, your main concern is balancing the trade-off between the length of your transaction log—that is, how many uncommitted updates—and how frequently you want to issue a hard commit. If your transaction log grows large, a restart may take a long time to process the updates, delaying your recovery process.
Atomic updates
You can update existing documents in Solr by sending a new version of the document. But unlike a database in which you can update a specific column in a row, with Solr you must update the entire document. Behind the scenes, Solr deletes the existing document and creates a new one; this occurs whether you change one field or all fields.
Atomic updates are a new feature in Solr that allows you to send updates to only the fields you want to change.

Behind the scenes, Solr locates the existing document with id=1, retrieves all stored fields from the index, deletes the existing document, and creates a new document from all existing fields plus the new retweet_count_ti field. It follows that all fields must be stored for this to work because the client application is only sending the id field and the new field. All other fields must be pulled from the existing document.
-----------------------------------------------------------------------------------------------------------------------------------
Index management
The most of the index-related settings in Solr are for expert use only. What this means is that you should take caution when you make changes and that the default settings are appropriate for most Solr installations.
Index storage
When documents are committed to the index, they’re written to durable storage using a component called a directory. The directory component provides the following key benefits to Solr:
- Hides details of reading from and writing to durable storage, such as writing to a file on disk or using JDBC to store documents in a database.
- Implements a storage-specific locking mechanism to prevent index corruption,such as OS-level locking for filesystem-based storage.
- Insulates Solr from JVM and OS peculiarities.
- Enables extending the behavior of a base directory implementation to support specific use cases like NRT search.
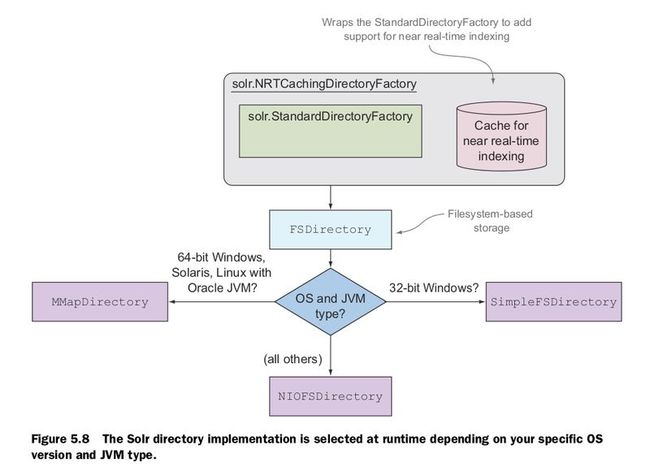
By default, Solr uses a directory implementation that stores data to the local filesystem in the data directory for a core.
The location of the data directory is controlled by the <dataDir> element in solrconfig.xml:
<dataDir>${solr.data.dir:}</dataDir>
The solr.data.dir property defaults to data but can be overridden in solr.xml for each core, such as
<core loadOnStartup="true" instanceDir="collection1/" transient="false" name="collection1" dataDir="/usr/local/solr-data/collection1"/>
Here are some basic pointers to keep in mind:
- Each core shouldn’t have to compete for the disk with other processes. If you have multiple cores on the same server, it’s a good idea to use separate physical disks for each index.
- Use high-quality, fast disks or, even better, consider using solid state drives (SSDs) if your budget allows.
- Spend quality time with your system administrators to discuss RAID options for your servers.
- The amount of memory (RAM) you leave available to your OS for filesystem caching can also have a sizable impact on your disk I/O needs.
The default directory implementation used by Solr is solr.NRTCachingDirectoryFactory, which is configured with the <directoryFactory> element in solrconfig.xml:
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"/>
Segment merging
A segment is a self-contained, read-only subset of a full Lucene index; once a segment is flushed to durable storage, it’s never altered. When new documents are added to your index, they’re written to a new segment. Consequently, there can be many active segments in your index. Each query must read data from all segments to get a complete result set. At some point, having too many small segments can negatively impact query performance. Combining many smaller segments into fewer larger segments is
commonly known as segment merging.