大数据中的SMAQ技术
本文另一地址请见 大数据中的SMAQ技术
本文译自 The SMAQ stack for big data
所谓海量数据,是指数据的规模大到已经难以使用传统的方式来处理。最早面临这个问题的是网络搜索引擎,而如今,社会化网络,移动电话、各种传感器和科学计算每天增长数以PB计的数据。 围绕Google关于这方面的工作和Yahoo的Haoop中对MapReduce的实现,兴起了一个海量数据处理工具的生态系统。 随着MapReduce越来越广为人知,更多的海量数据系统开始涌现,包括了存储、MapReduce和查询等不同领域。所有的SMAQ都以开源、分布式以及运行在普通硬件上为特征。
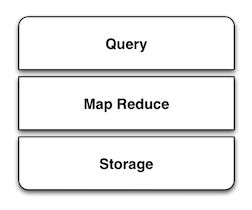
就像LAMP给web应用开发带来的影响,SMAQ使得海量数据处理越来越容易。LAMP推动了Web2.0,SMAQ正以同样的方式开创一个数据驱动的产品和服务创新的新时代。 在SMAQ中占据着主导地位的是基于Hadoop的架构,除此之外还包含了主要的NoSQL数据库。这篇文章描述了SMAQ体系并且将如今的一些海量数据工具归类在SMAQ体系中的合适位置。
MapReduce
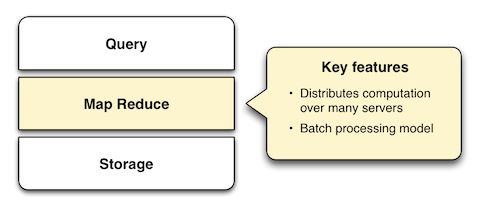
由Google发明,为了处理网络搜索的索引问题,MapReduce 框架在如今的大多数海量数据处理中扮演着重要作用。它最关键的发明是把一个数据查询分解在多个节点上并行进行。这种分布解决了数据量太大超出单台机器的计算能力的问题。
为了理解MapReduce是如何工作的的,让我们来看看这两个阶段。在map阶段,输入数据被逐条处理,然后形成一个中间数据。在reduce阶段,中间数据被处理形成最终需要的结果。
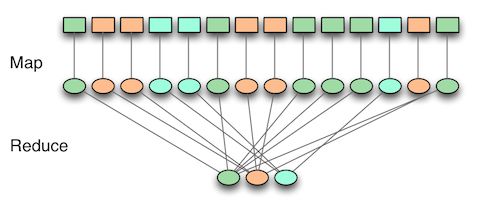
MapReduce的一个简单例子是统计一篇文档中的单词频率。在map阶段,每个词被计数1,在reduce阶段,同一个词的计数被加和起来。 如果这个例子看上去很难理解,那是因为它确实如此。为了使用MapReduce完成这个功能,map和reduce阶段都必须遵守特定的约束,这样任务才能并行执行。把一个查询转换为一个或多个MapReduce任务不是一个直观的过程,应该有一个高层次的抽象来简化这一步骤,而把复杂性掩盖在查询之下。 基于MapReduce的系统不同于传统数据库的一点是对于数据的处理都是批量进行的,任务在队列里排队执行,每个任务可能要花去数分钟乃至数小时。 用MapReduce处理数据的三步必需操作:
- 加载数据 –这个操作在数据仓库术语中通常称之为抽取、转换和加载(ETL)。数据被从原始源中抽取出来,结构化以备处理,然后加载进供MapReduce使用的存储设施。
- MapReduce – 这一阶段从存储设施中获得数据,处理,然后把结果再写入存储设施。
- 提取结果 – 一旦处理完成,就可以从存储中获得结果呈现为适宜阅读的样式。
许多SMAQ系统都为简化这些过程而做了专门设计。
Hadoop MapReduce
Yahoo支持的Hadoop是最知名的开源MapReduce实现。它由Doug Cutting在2006年创立,并在2008年初的时候具备了网络级服务的能力。 Hadoop现在由Apache托管,目前已经发展为一个包含有多个子项目的SMAQ软件体系。 建立MapReduce任务需要写代码来封装Map和Reduce阶段。而且数据必须先放置在Hadoop文件系统中。 仍然以上面的单词统计来作为例子,map函数应该像下面这么写:(取自Hadoop MapReduce文档,关键操作以黑体标记)
public static class Map extends Mapper (LongWritable, Text, Text, IntWritable) {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken()); context.write(word, one);
}
}
}
同样在Reduce中对每个单词的计数加和.
public static class Reduce extends Reducer (Text, IntWritable, Text, IntWritable) {
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum));
}
}
运行一个Hadoop MapReduce任务包括以下几步:
- 写Java代码来定义map和reduce阶段该做的事情
- 从文件系统中加载数据
- 提交任务执行
- 从文件系统中获取结果
仅通过Java API来使用Hadoop MapReduce是比较复杂的,必需由专门的程序猿来写代码。不过围绕着Hadoop已经诞生了一个巨大的生态系统,使得数据的加载和处理更加简单。 其他实现 MapReduce也有一些替他编程语言的实现,在Wikipedia’上的MapReduce词条有一个列表,有兴趣的同学可以看一下。特别要提及的是一些NoSQL数据库系统也整合了MapReduce,这个会在本文的后面提及。
存储
需要合适的存储来获取数据和放置计算结果。传统的关系数据库不是个好主意。数据被分块存储在多个节点上并以键值对的形式提供给Map。这些数据是非结构化的,不需要遵循固定的数据结构规范。但是对每个MapReduce节点数据都必须是可用的。

存储层的设计和结构非常重要,不仅针对MapReduce接口,还因为其影响到数据加载和计算结果提取和查找的易用性。
Hadoop 分布式文件系统
Hadoop 使用Hadoop 分布式文件系统,(HDFS)作为基本存储机制,这是Hadoop的核心组件。 HDFS 具有西面一些特点, 想了解更详细的可以去看 HDFS 设计文档.
- 故障容错 – HDFS运行在廉价硬件上并假设硬件故障经常发生.
- 流式数据访问 – HDFS 按照批量处理的思想来设计, 强调数据的高吞吐而非随机访问。
- 极端可伸缩 – HDFS 可以达到PB规模级数据的处理能力; 这样的应用场景已在FaceBook成为现实.
- 可移植性 – HDFS 可以安装在不同操作系统上.
- 一次写 – HDFS 假设一个文件一旦写入之后就不再改变,从而简化了数据复制并且加速了数据吞吐.
- 在不同位置计算 – 移动程序到数据所在的地方通常要比移动数据更快,HDFS体现了这一特点。
HDFS提供了一个和通用文件系统很相似的接口。不像数据库,HDFS只能存取数据,而不能对数据做索引。 对数据的随机访问是不支持的。 不过,像HBase这样的工具在更高层次提供了更加丰富的功能。
HBase, the Hadoop Database
HBase使得Hadoop更加易用。 HBase 模仿 Google 的 BigTable 设计,是一个基于列的适合存储海量数据的数据库。 它属于NoSQL数据库领域,Cassandra 和 Hypertable 是它的同类.
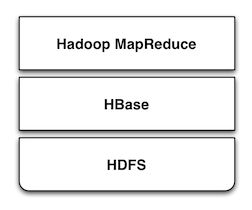
HBase 使用 HDFS 作为存储, 能够在可容错的多个节点上存储大量数据。像其它相似的列存储数据库一样, HBase 提供了 REST 和 Thrift 访问接口. 因为有索引,HBase可以用一些简单的查询语句进行快速的随机访问。对于更复杂的操作,HBase既可以作为 Hadoop MapReduce 的数据源也可以作为计算结果数据的目的地。HBase提供了接口使得Hadoop可以将其作为数据存储装置,而不是使用更底层的HDFS。
Hive
数据仓库是SMAQ系统的一个重要应用领域。此种数据存储方式使得报表生成和分析更加容易。Facebook 开发的 Hive 是构建在Hadoop之上的一个数据仓库框架。与 HBase 相同, Hive 也在Hadoop 之上提供了一个基于表的抽象 ,这简化了结构化数据的加载。 与 HBase 相比, Hive 只能运行 MapReduce jobs并且只适合于批量分析。Hive 提供了类SQL查询语言来执行 MapReduce 任务,这会在下面的Query一章详述。
Cassandra and Hypertable
Cassandra 和 Hypertable 也是与 HBase 类似的 BigTable 模式的可扩展的列存储数据库。 Cassandra 作为一个Apache 项目最初由Facebook 创立,现在已经在许多网站得到了应用, 包括 Twitter, Facebook, Reddit 和 Digg. Hypertable 由 Zvents 创立,刚刚开源不久。

这两种数据库都提供了针对 Hadoop 的接口,Hadoop可以使用它们作为数据源或者储存计算结果数据。 在更高的层次, Cassandra 提供了 与 Pig 查询语言的整合 (详见下面的 Query 章节), Hypertable 已经 与Hive整合。
NoSQL 数据库实现的 MapReduce
上面提到的几个存储全都依赖于Hadoop 的 MapReduce。还有一些 NoSQL 数据库内建了 MapReduce 功能, 这样就可以对存储的数据进行并行计算。与基于Hadoop 的混合 SMAQ 架构相比,他们提供了一体化的存储、MapReduce 和查询功能。 基于Hadoop 的系统通常用于批量分析,而NoSQL通常用于支持实时应用,这些 NoSQL 数据库提供的 MapReduce 往往是一个为了加强查询的次要功能。例如 Riak,对 MapReduce 任务的默认延迟时间是60秒, 而 Hadoop 的处理过程通常都要耗时数分钟乃至数小时。 这些 NoSQL databases 提供了 MapReduce 功能:
- CouchDB 是一个分布式数据库, 提供半结构化的基于文档的存储。它的主要功能包括强大的复制支持和分布式更新。 CouchDB 的查询使用 JavaScript 定义的 map和 reduce 来实现。
- MongoDB 本质上与 CouchDB 非常相似, 不过更强调性能, 弱化了分布式更新 , 数据副本和版本供呢个。 MongoDB MapReduce operations 也使用 JavaScript 定义.
- Riak 另一个类似于 CouchDB和 MongoDB 的数据库, 但是它更看重高可用性。 MapReduce operations in Riak 可以使用 JavaScript 或者 Erlang 定义.
与 SQL 数据库的整合
在许多应用场景下,数据的主要来源是像 MySQL 或者 Oracle 这样的传统关系数据库,MapReduce 有两种典型的方式来使用这种数据:
- 用关系数据库作为数据来源(例如社会网络中的朋友列表)。
- 将 MapReduce 的运算结果写入关系数据库 (例如基于朋友兴趣的产品推荐).
因此,理解 MapReduce 和 关系数据库之间是怎么交互的就很重要。最简单的做法是使用固定分隔的文本文件,使用 SQL 命令结合 Hadoop 操作来完成导入导出。不过,还有一些更加复杂的工具能实现这个目的。 Sqoop 就是一个吧关系数据库中的工具导入到 Hadoop 的工具。 由 Cloudera 开发,他们维护了一个企业级Hadoop 平台。 Sqoop 使用了JDBC API ,因此与具体数据库无关。可以全部导入整张表的数据,也可以使用条件来有选择的加载想要的数据 Sqoop 也可以把 MapReduce 的结果从 HDFS 导回到数据库。 因为 HDFS是一个文件系统, Sqoop 需要有明显标识分隔的文本文件来吧需要的数据转换成 SQL 语句插入到 数据库。 在 Hadoop 体系下有 Cascading API , (详见下面的 Query 章节) cascading.jdbc 和 cascading-dbmigrate 工具可以做与 Sqoop 相似的事情。
与流式数据源的整合
除了来自关系数据库的数据,像网站服务器日志以及传感器输出这样的流式数据, 构成了很多海量数据系统的数据来源。Cloudera 的 Flume 项目为 Hadoop 和 流式数据源之间的整合提供了一个方案。Flume 通过网络从遍布集群的机器和文件中 收集数据 ,然后持续不断的写入到 HDFS。 FaceBook 开发的 Scribe 也提供了同样的功能。
商用 SMAQ 解决方案
一些大规模并行处理 (MPP) 数据库产品已经内建了 MapReduce 功能。 MPP 数据库通常有一个各节点并行运行的分布式架构。他们主要应用于数据仓库和分析,通常通过 SQL 来使用。
- Greenplum 数据库基于开源的 PostreSQL 数据库, 运行在一个分布式集群上。Greenplum给常规的 SQL 接口增加加了MapReduce 功能,这样就可以更快的分析更大规模的数据,消耗的时间可以降低好几个数量级。Greenplum MapReduce 可以将外部数据与数据库内部数据混合处理。可以用Python 或者 Perl 来执行 MapReduce 操作。
- Aster Data’s nCluster 数据仓库系统也提供了 MapReduce 功能。用 Aster Data’s SQL-MapReduce 技术来调用。 SQL-MapReduce 可以混合 SQL 语句与 编程语言定义的 MapReduce 任务,支持 C#, C++, Java, R 和 Python 语言。
还有一些数据仓库产品选择连接 Hadoop 的 MapReduce 而不是自己实现。
- Vertica, Farmville 的运营公司 Zynga 所使用的,一个 大规模并行处理(MPP) 基于列的数据库, 提供了 Hadoop 接口。
- Netezza 是一整套的包含硬件的数据仓库和分析设备。 最近刚刚被 IBM 收购。 Netezza 与 Cloudera 合作 增强了其产品与 Hadoop 之间的互操作性。 虽然解决的是一样的问题, 但是Netezza 并不太符合我们的 SMAQ 定义。 它既不是开源的也不是运行在廉价的通用硬件上。
尽管可以使用开源软件组建一个基于Hadoop的系统,但是仍然需要做许多工作来整合各个组件。Cloudera 致力于使 Hadoop 成为企业级应用,它在 Cloudera Distribution for Hadoop (CDH) 中提供了一个统一的 Hadoop 体系。就像Ubuntu 和 Red Hat 提供了 整合版本 Linux 的意义。CDH 提供一个免费版和功能更多的 企业版本。CDH 是一个包含了面向用户查询和操作接口的完整的 SMAQ 环境。 这些意义重大的工作对 Hadoop 生态圈贡献颇大。
Query
使用像上面的Java 代码 那样的编程语言定义 map 和 reduce 函数并组装 MapReducre 任务是直观但是不便的。为了解决这个问题,SMAQ 包含了一个更高层面上的查询层来简化 MapReduce 定义和获取结果数据。
许多使用 Hadoop 的机构已经。在 MapReduce API 之上开发了自己的查询层来简化操作,其中有一些已经开源或者是商业化了 查询层一般不只提供计算过程的制定,还要负责加载数据、保存结果以及在集群中分配 MapReduce 任务。典型的搜索技术通常被用来实现计算的最后一步也即返回结果给用户。
Pig
由 Yahoo 开发,现在已经成为 Hadoop 项目的一部分。 Pig 提出了一种用于定义和运行 Hadoop MapReduce 任务的高层次语言, Pig Latin。 这实际上提供了一个Java API之间的接口,使那些熟悉 SQL 的开发人员可以以他们擅长的方式来使用 Hadoop。Pig 也可以用于 Cassandra 和 HBase 。 下面演示了使用 Pig 做词频统计的例子。包含了数据的加载和结果存储。 (符号 $0 表示每条记录的第一个字段 )。
input = LOAD 'input/sentences.txt' USING TextLoader(); words = FOREACH input GENERATE FLATTEN(TOKENIZE($0));
grouped = GROUP words BY $0; counts = FOREACH grouped GENERATE group, COUNT(words); ordered = ORDER counts BY $0; STORE ordered INTO 'output/wordCount' USING PigStorage();
Pig 的功能很强大,开发者可以使用 User Defined Functions (UDFs) 来定义自己的操作,就像许多SQL 数据库也支持自定义函数 。在 Pig 里可以用Java 语言来定义 UDF。 虽然要比 MapReduce API 更容易理解和易于使用,但 使用 Pig 仍然要去学习一种新的语言。所谓类SQL语言毕竟与 SQL 还是有所不同,这使得那些熟悉 SQL 的开发人员并不能够完全重用他们的技能。
Hive
像上面介绍过的,Hive 是一个 Facebook 开发的,建筑在 Hadoop 之上的开源数据仓库方案。它提供了一种跟 SQL 很相像的查询语言和一个网络界面,可以在这个网络界面上来构建简单查询。因此,那些对 SQL了解不是很深的人也可以使用它。 与Pig 和 Cascading 这样需要编译的工具相比,Hive 最强的地方是提供了数据的即时查询。如果把成为一个功能更全面的商业智能系统作为目的, 对非技术人员友好的 Hive 是一个非常好的起点。 CDH 整合了 Hive,,并且通过 HUE 提供了一个更高层次的接口,通过这个接口用户可以提交查询并且监控Hadoop 任务的执行。
Cascading, the API Approach
Cascading 项目对 Hadoop MapReduce API 做了包装以使其在 Java 应用中使用更方便。这是很薄的一层,它的目的只是为了降低在一个比较大的系统里整合 MapReduce 的复杂性。Cascading 包含以下功能:
- 一个简化 MapReduce 定义的数据处理 API。
- 一个控制 Hadoop 集群中 MapReduce 任务执行的 API。
- 支持基于 JVM 的脚本语言访问,如 Jython, Groovy, or JRuby。
- 整合了 HDFS 之外的数据源, 包括 Amazon S3 和 web servers。
- 测试 MapReduce 过程的验证机制。
Cascading’s key feature is that it lets developers assemble MapReduce operations as a flow,joining together a selection of “pipes”. Cascading 的核心功能是允许开发者将MapReduce 操作组合成一个流,一起加入一个管道的选择。这非常适合于需要将 Hadoop 整合进一个大系统的场景。 Cascading 自身没有提供高级查询语言,由一个叫做 Cascalog 的项目来提供这个功能。 Cascalog使用 基于JVM的 Clojure 语言实现了一个与 Datalog 相似的查询语言。尽管这种语言表现强大,但它的实际地位很尴尬, 因为它既不像Hive 的类 SQL 语言那样可以利用已有的知识,又不像Pig 那样提供一个过程化的表达。下面的代码是用 Cascalog 写的词频统计的例子 : 看上去很简洁,但是不太好理解
(defmapcatop split [sentence] (seq (.split sentence "\\s+"))) (?<- (stdout) [?word ?count] (sentence ?s) (split ?s :> ?word) (c/count ?count))
Search with Solr
海量数据开发中的一个重要组成部分是数据检索和汇总。像 HBase 这样的数据库附加层简化了数据访问,但是并不能够提供复杂的搜索。 为解决这个问题,通常使用开源搜索和索引平台 Solr 来作为 NoSQL 数据库的辅助。Solr 使用 开源搜索引擎 Lucene 提供搜索功能。 例如,假设有一个社会网络数据库,MapReduce 依据某种算法计算每个人的影响力,并发计算好的评分结果插入数据库。用 Solr 对数据做索引,然后就可以找到影响最大的且在个人信息里面留了手机的 那些人。 Solr 最早由 CNET 开发,现在已经成为了一个 Apache 项目,它已经由一个文本搜索引擎进化成了支持多面导航和结果聚类的工具。 此外, Solr 可以管理分布在多个服务器上的大数据。这使它非常适合于大型数据集上的结果检索,从而成为构建商业智能系统的重要组件。
总结
MapReduce, 特别是 Hadoop 提供了一种在多台普通服务器上进行分布式计算的有效方法, 再结合分布式存储和对用户友好的查询机制,就形成了所谓 SMAQ 架构,这种架构使小开发团队也可以进行海量数据处理。 这些技术降低了大范围内的数据调查和建立在复杂算法上的数据产品的成本, 这是爆炸性的进步,永远改变了多维分析和数据仓库,降低了新产品开发的门槛,Mike Loukides在 “What is Data Science?“提及的趋势会愈发欲烈。
Linux 的出现给了那些有创新想法的开发者们巨大的支持,他们可以将自己的工作电脑配置成Linux服务器。SMAQ 对于创建数据中心具有相同的意义,它降低了创建数据驱动型业务的成本。