接上一篇:
http://caoyaojun1988-163-com.iteye.com/blog/1302936
5 性能
虽然除了互斥锁,同步框架也支持其他许多风格的同步;但是锁的性能是最容易比较和衡量的,即便如此,还有很多不同的测量方法。这里的实验旨在揭示开销和吞吐量。在每项测试中,每个线程多次更新一个伪随机数,计算使用函数:nextRandom(INT种子):
int t = (seed % 127773) * 16807 –(seed / 127773) * 2836; return (t > 0)? t : t + 0x7fffffff;
其中一组线程每次迭代更新的概率为S,他们共享一个互斥锁下的生产器,另外一组线程使用无锁的本地生产器;并且在线程竞争的时候短时间的锁定区域,以减少其他因素的影响,使用随机数函数有两个方面的考虑,一是用于检测是否被锁定(它是一个很好生产器),二是让循环内的代码不会让JVM优化掉。
我们比较了4种锁:使用synchronized关键字的内建锁(Builtin)、在第4节演示的简单的互斥(Mutex)类、使用ReentrantLock的重入锁(Reentrant)、使用“公平”的模式的ReentrantLock的公平锁。所有的测试使用Sun J2SE1.5 JDK 的第46个build版本,选择服务器模式;在正式搜集数据之前,跑20组数据,以消除“预热”的影响;测试的时候,除了公平模式只迭代运行一百万次,其他每个线程迭代运行1000万次,
测试机器使用四个基于x86的机器和四个基于UltraSPARC的机器。所有x86机器上运行Linux RedHat2.4 NPTL的基代内核和库;所有的UltraSparc机器运行Solaris9。所有的测试都是在系统最轻负载时进行;测试机的其他方面没有要求,因为完全处于闲置状态;“4P”的名称,其实表示是两个超线程(hyperthreaded HT)Xeon的处理器,所以跟接近4核而不是2核。没有任何人为的缩小分歧。如下所示,相对应成本的同步器与处理器的个数、类型,速度并没有一个简单的关系。

5.1、负载
无竞争时的开销,可以通过仅仅运行一个线程,每次迭代用S=1的版本减去S=0的版本(不会去访问共享变量)的时间;表2显示了不同同步器的运行情况,单位是纳秒;Mutex类最接近测试框架的基本成本开销。重入锁(Reentrant )的额外开销,表示记录当前所有者的线程和错误检查的开销,公平锁的额外开销表示首先检查队列是否为空的开销。
表2还显示tryAcquire与使用“快速通道”--内置锁的成本。这里的差异主要反映了使用不同的原子操作和跨锁、机器的内存壁垒的成本。在多处理器时这些指标往往完全高于其他的。内置锁与同步器的主要的区别显然是由于Hotspot 的锁在获取锁和解锁都使用compareAndSet,而同步器的类只有在获取使用compareAndSet,释放的时候使用volatile 的写(即,屏蔽多处理器的内存屏障,和所有的处理器上的指令重排约束);
表3的场景是S=1、运行256个并发线程,制造大量的锁竞争,在完全饱和竞争的情况下,FIFO锁比内建锁有更小的开销(等价更大的吞吐量),并且比公平锁少两个数量级。这表明:高并发的情况下,允许闯入的FIFO的策略有更好的效率。


表3还显示,即使有较低的内部开销,但是由于上下文切换的时间导致了公平锁的较差的性能。上面的时间可以粗略的看到在各个不同平台上阻塞、唤醒线程的比例;此外,一个后续的实验(只使用机器4P)显示,公平性的设置对这些锁的总体方差影响不大。可以作为一个较粗粒度的变化维度,就线程结束时间而言,在4P的机器上公平锁(Fair)的标准差为0.7%,Reentrant的标准差为6.0%;作为对比,如果模拟长期持有锁,一个方案是,每个线程获取每个锁的时候计算16K的随机数
总运行时间几乎相同(公平锁9.79s,Reentrant9.72s);公平模式获取更小的标准差大约0.1%,而Reentrant 上升到29.5%。
5.2 吞吐
大多数的同步器使用时处于无争和饱和竞争的极端之间。这可以沿着两个维度去做实验和研究,一个是固定线程集合中线程的数量,改变发生竞争的概率,另一个是固定竞争的概率,增加线程集合中线程的数量。我们通过使用可重入锁(Reentrant),在不同的竞争概率和线程数量的场景中运行来说明这些因素的影响,下面是slowdown的计算方法:

t表示总共执行的时间, b是一个线程没有竞争或者同步时的执行时间,n是线程的数据,p是处理器的数量,s任然表示访问共享变量的概率;slowdown的值等于总时间除以最小的串行执行的时间加上并行执行的时间(这是理想情况);这是理想的时间模型,没有任何同步开销,因为没有任何线程与其他线程冲突而被阻塞。即便如此,在非常低的竞争下,一些测试结果可能比这个理想模型稍微好一些,,大概是由于jvm的优化,流水线等引起细微的差别;
图中所有的数字取2为低的对数,例如:1.0表示测试的时间是理想模型的2倍;4.0表示16倍;使用对数是为了解除对基本时间的依赖,所以与使用基础计算结果具有相同的趋势;这些测试使用的竞争的概率从1/128(0.008)到1;间隔2的幂,线程数是从1到1024,间隔是2的幂的一半;
在单处理器(1P和1U)的情况在,随着竞争的增加新能下降,但是跟线程的数量没有关系。多处理器一般会看到更糟糕的下降速度。多处理器的图形显示,在很少线程的时候会出现一个峰值,然后迅速下降;这反映了性能的过渡区,这个时候闯入的线程和被唤醒的线程同样可能获得锁,产生竞争因此经常迫使对方阻塞。在大多数情况下,在接下去就是平滑的区域,这个时候锁几乎永远不可用,导致跟单处理器的顺序的模式类似;无论有多少个处理器的机器,都必然出现。 同样还可以看到其他的信息;例如,全部有竞争的时候(概率为“1.000”)较少处理器的机器上slowdowns相对较差。


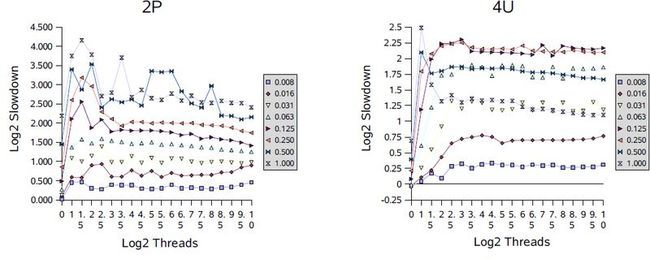

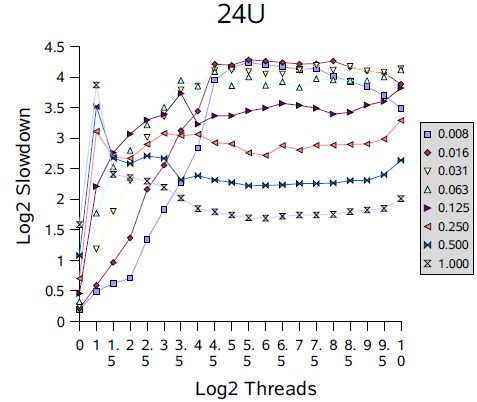
这些结果,可以发现如果调解阻塞(阻塞和唤醒)的支持方式去减少上下文切换和相关开销的可以提供很小但是对此框架有明显改善的性能。此外,可以使用其他形式的自适应的自旋、针对多个处理器的高并发的锁,可以避免这里看到的震动。而自适应自旋在不同的环境下工作往往是非常困难的,针对具体的应用程序可以使用配置文件去配置使用基于这个框架的自定义的锁。
6、总结:
截止写这篇文章的时候,java.util.concurrent中的同步框架还是很新的功能,还需要在实践中去评估,在j2se 1.5 发布之前,它的设计、实现、性能都是不可预知的;无论如何,框架的出现成功的满足可以基础它高效创建新的同步器的目标。