Unpivot 和 Apply的应用比较
在SQL中, UNPIVOT 和 APPLY 能取得相同数据效果。
看一个例子:
IF OBJECT_ID('tempdb..#QSales','U') is not null
drop table #QSales
GO
create table #QSales(
[Year] int,
Q1Sales int,
Q2Sales int,
Q3Sales int,
Q4Sales int)
GO
insert #QSales select 2009, 7, 29, 71, 8
union all select 2010, 2, 8, NULL, 4
union all select 2011, 6, 5,3,null
select *from #QSalesunpivot (Sales for Descript in (Q1Sales,Q2Sales,Q3Sales,Q4Sales)) P
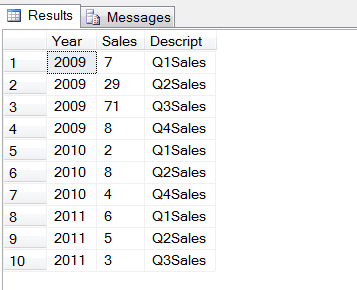
同样的结果,可以取得,使用APPLY
select [Year],Sales,Descript
from #QSales
CROSS apply (values (N'Q1Sales',Q1Sales)
,(N'Q2Sales',Q2Sales)
,(N'Q3Sales',Q3Sales)
,(N'Q4Sales',Q4Sales)) P(Descript,Sales)
where Sales is not null
那一个好呢? 我们来比较以下执行计划:
UNPIVOT:

APPLY:
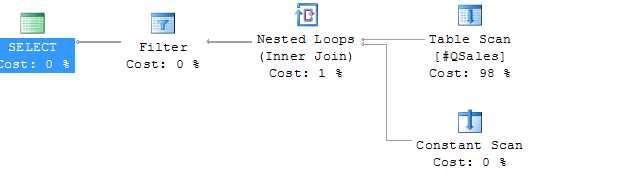
显然, 后者要好。而且完全可以用OUTER 代替 CROSS.
对于多列数据, APPLY 就更有优势。
select PatientID,TestDate,Cholesterol,Sodium,Glucosefrom #BloodTestsunpivot (TestDate for DateDesc in (TestDate1,TestDate2,TestDate3)) U1unpivot (Cholesterol for CholDesc in (Chol1,Chol2,Chol3)) U2unpivot (Sodium for SodDesc in (Sod1,Sod2,Sod3)) U3unpivot (Glucose for GlucDesc in (Gluc1,Gluc2,Gluc3)) U4where right(DateDesc,1)=right(CholDesc,1) and right(CholDesc,1)=right(SodDesc,1) and right(SodDesc,1)=right(GlucDesc,1)
select PatientID,TestDate,Cholesterol,Sodium,Glucosefrom #BloodTestscross apply (select TestDate1,Chol1,Sod1,Gluc1 union all select TestDate2,Chol2,Sod2,Gluc2 union all select TestDate3,Chol3,Sod3,Gluc3) X(TestDate,Cholesterol,Sodium,Glucose)
上面这个, 清晰显示,APPLY更加简洁,高效。
那么, UNPIVOT没有用处么?
也不是。现在看这样一个表。
StudentID Test1 Test2 Test3 Test4 Test5 Test6 Test7 Test8 Test9 Test10 Test11 Test12
--------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ------ ------ ------
1 96 87 NULL 100 99 91 73 90 90 91 93 92
2 83 84 89 79 88 NULL 93 82 85 86 88 82
3 100 100 98 91 100 95 96 96 99 100 98 100
select StudentID ,AverageScore=avg(TestScore*1.0) ,MinScore=min(TestScore) ,MaxScore=max(TestScore) ,StdDev=stdev(TestScore)from #Scoresunpivot (TestScore for Descript in (Test1,Test2,Test3,Test4,Test5,Test6 ,Test7,Test8,Test9,Test10,Test11,Test12)) Pgroup by StudentID
上述查询,可以得到:
StudentID AverageScore MinScore MaxScore StdDev
--------- ------------ -------- -------- ----------------
1 91.090909 73 100 7.18963900977711
2 85.363636 79 93 3.95658254741963
3 97.750000 91 100 2.80016233295663
下面查询
;with UnpivotedScores as( select StudentColumn='Student'+convert(varchar(10),StudentID) ,TestScore ,TestID=convert(int,substring(TestColumnName,5,len(TestColumnName))) from #Scores unpivot (TestScore for TestColumnName in (Test1,Test2,Test3,Test4,Test5,Test6 ,Test7,Test8,Test9,Test10,Test11,Test12)) U)select * from UnpivotedScorespivot (max(TestScore) for StudentColumn in (Student1,Student2,Student3)) P
可以得到
TestID Student1 Student2 Student3
------ -------- -------- --------
1 96 83 100
2 87 84 100
3 NULL 89 98
4 100 79 91
5 99 88 100
6 91 NULL 95
7 73 93 96
8 90 82 96
9 90 85 99
10 91 86 100
11 93 88 98
12 92 82 100
注意,这里使用了CTE, 而且一个是PIVOT,另一个是UNPIVOT,
是否很美丽呢?
select StudentID ,AverageScore=avg(TestScore*1.0) ,MinScore=min(TestScore) ,MaxScore=max(TestScore) ,StdDev=stdev(TestScore)from #Scoresunpivot (TestScore for Descript in (Test1,Test2,Test3,Test4,Test5,Test6 ,Test7,Test8,Test9,Test10,Test11,Test12)) Pgroup by StudentID