Kettle-Spoon使用文档
Spoon使用文档
-- General Availability Release 5.4.0.1-130 中文版
一.概念
a) kjb文件称为‘作业’。完成ETL前期准备工作,如测试数据库连接,下载文件,获取配置等等。
b) ktr文件称为‘转换’。完成ETL数据转换工作,如数据转换,数据校验,Insert/Update数据库等等。
c) 通常的用法是一个kjb,运行多个ktr。
二.作业
a) 新建作业后,在‘主对象树’中有4个文件夹:DB连接,作业项目,Hadoop Clusters,子服务器。
i. DB连接:配置数据库连接。可通过配置文件,${crawler.db.host}的方式传递数值。如何加载配置文件,请看‘通用-设置变量’。
ii. 作业项目:主要业务流程在这里实现。当在‘核心对象’中任意拖出一个对象到设计面板后,该对象会出现在‘作业项目’中。
iii. Hadoop Clusters:集群配置。
iv. 子服务器:子服务器配置。
b) 作业属性
i. 点击右边的‘设计面板’空白处弹出。
c) 核心对象
i. 通用
1. START:作业调度器,可设置定时执行功能。(一般作为作业的第一个执行对象)。
2. DUMMY:空操作。
3. 作业:可调用另一个作业。
4. 设置变量:属性文件名中,可通过ctrl+alt+space,获取系统参数,如${Internal.Job.Filename.Directory},然后加载配置文件,如:config.properties。变量范围表示,可选择‘在根作业中有效’,那么在 被执行的ktr中也能使用加载的配置文件了。默认选项应该也是可以。
5. 转换:也就是ktr文件
ii. 邮件
1. 发送邮件:配置‘邮件服务器’,‘验证’,‘收件人’,‘发件人’即可发送邮件。
iii. 文件管理
1. HTTP方式上传下载文件。
2. 文件的增删查改,比较,移动,压缩
iv. 应用
1. 中止作业:结束作业。一般放在作业的最后。
v. 资源库
1. 检查是否连接到资源库:配置‘主对象树’中的DB连接。用于测试数据库连接。
vi. 文件传输
1. SFTP 上传:在‘一般’中配置基本信息。在‘文件’中配置‘源’和‘目标’信息。
三.转换
a) 新建作业后,在‘主对象树’中有4个文件夹:DB连接,Steps(步骤),Hops(节点连接),数据库分区schemas,子服务器,Kettle集群schemas,Hadoop clusters。
i. DB连接:同上。
vii. Steps(步骤):主要业务流程在这里实现。当在‘核心对象’中任意拖出一个对象到设计面板后,该对象会出现在‘步骤’中。
ii. Hops(节点连接):对象之间的连接线。
b) 转换属性
i. 点击右边的‘设计面板’空白处弹出。
c) 核心对象
i. 输入
1. 文本文件输入:
a) 文件:‘选中的文件’中配置文件路径。如:${Internal.Job.Filename.Directory}/tmp.txt。
b) 内容:选择文件类型,过滤头尾的数据,数据的分割符等一些条件。
c) 字段:将每行的内容,根据分隔符处理后,每项数据表示什么,在这里配置。String,Integer,Timestamp类型可以不填写长度等信息,但要注意“格式”。
d) 其他输出字段:可配置额外的字段。
2. CSV Input:基本同‘文本文件输入’。
3. GZIP CSV Input:可直接处理gz压缩的文件。
4. 获取文件名:在‘已经选择的文件名称’中,配置你想获取文件的路径,以及通过通配符的方式获取你想要的文件。
5. 获取文件行数:在‘选中的文件’中填写文件名,在‘内容’—》‘行数字段’中配置变量名,如:rowscount。那么在下一个步骤中可以通过rowscount获取了。
6. 获取系统信息:‘名称’:变量名。‘类型’:数据获取方式。该变量可全局使用。
7. 表输入:选择‘数据库连接’(需要在‘主对象树’的DB连接中配置),填写SQL语句,那么下一步骤就能使用该数据。
ii. 输出
1. 文本文件输出
a) 文件:‘文件名称’配置文件名。
b) 内容:配置封闭符,分隔符,头尾,压缩等。
c) 字段:同之前提到的‘字段’。
2. 插入/更新
a) 配置数据库连接,目标表,提交记录数据(批量处理每次提交数)
b) 不执行任何更新:当插入数据重复时,不做更新。
c) 用来查询的关键字:如表字段id,比较符=,流里的字段id。
d) 更新字段:表字段value,流字段value,更新Y
iii. 转换
1. 排序记录:‘字段名称’中填写要排序字段。如:filename,根据前一步提供的文件名来排序。
iv. 流程
1. Switch / Case:根据不同的case值,指定不同的下一步。
2. 阻塞数据直到步骤都完成:选择步骤select,复制次数0,那么本步骤会阻塞知道select完成执行。
v. 脚本
1. Java代码:可用于数据转换,‘字段’中配置输出字段名。‘Processor’中编写java代码。如:
a) String start = get(Fields.In, "start").getString(r);//获取数据
b) Long start1 = IPStringToLong(start);//转换数据,IPStringToLong是自定义的
c) get(Fields.Out, "start1").setValue(r, start1);//输出数据
2. JavaScript代码:可将前步传入的数据通过spoon自带的function,进行转换。如:var todayStr = date2str(today, "yyyyMMdd");,前步传入today,本步转换后,输出todayStr,date2str是转换方法。
vi. BA Server
1. Set session variables:字段名称(上步提供的临时变量),变量名(环境变量名),变量活动类型(Valid in the root job)。那么之后的对象就能用这个‘变量名’来获取数值了。
四.用法
a) kjb作业流程:START —》 获取参数 —》 测试数据库连接 —》 转换(ktr) —》 成功,除去头和尾,中间任意出错的 —》 发送邮件 —》 中止作业。
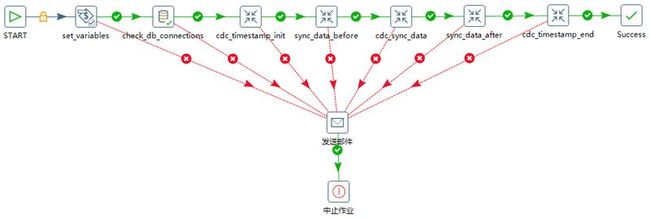
b) 部署spoon脚本:Linux下Bash脚本调用 kitchen.sh -file=sync.kjb XXX(参数) -param:env=${env} -norep -level=Detailed -logfile=logs/X.log
c) 快速连接两个对象:左击对象1,按住shift,拖动鼠标到对象2。

d) 临时变量,只能在下一个‘对象’中使用。所以可以考虑分发的方式:
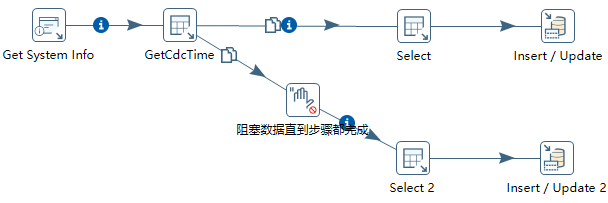
Select和Select2中需要用到GetCdcTime中获取的临时数据。而Select2等待Select的Insert/Update执行完才会执行。
e) 通过文件导入数据:获取文件名—》排序文件数据—》获取数据—》导入数据库。

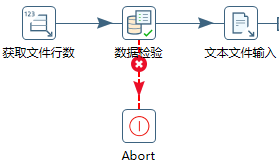
f) 数据检验:‘要检验的字段名’,可在‘下拉’中找到上一步骤中传递过来的变量。根据检验条件来控制执行流程。
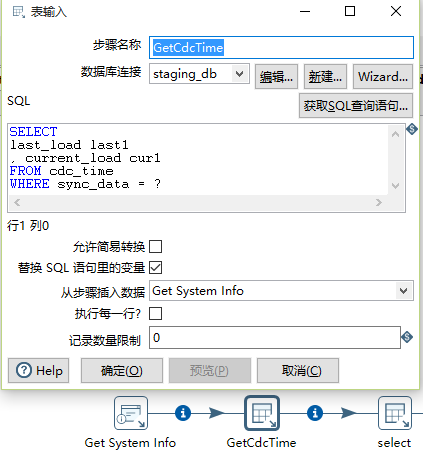
g) 如何获取前步参数:‘从步骤插入数据’,选择前部名称,勾选‘替换SQL语句里的变量’,在SQL用‘?’来表示前步骤的参数。注意点:如前步骤提供3个参数,后步骤用了3个‘?’,则分别对应前步骤的3个参数,顺序一致。如步骤‘select’就能使用GetCdcTime中查寻出来的last1和cur1。
五.注意点
a) 输出到文件时,需要注意是否使用‘强制在字段周围加封闭符’:如封闭符是双引号,Spoon对于输出数据是String类型的,默认是不添加双引号的,那么当数据中有换行符的话,那么就导致使用这份数据导入时,Spoon解析时会出问题,如果勾选了该功能,数据就能被正确解析。建议默认勾选。
b) kettle默认情况下把空字符串当作NULL处理。导致sql中出现问题。解决办法:在.kettle/kettle.properties添加KETTLE_EMPTY_STRING_DIFFERS_FROM_NULL=Y
c) Mysql数据库语句的注意点:
i. sha1要判空,if(reg_num="","",sha1(reg_num)) AS reg_num
ii. timestamp要格式转换,if(enrol_date="",NULL,str_to_date(enrol_date,'%Y-%m-%d %H:%i:%s')) AS enrol_date