Kubernetes v1.0特性解析
kubernetes1.0发布,开源社区400多位贡献者一年的努力,多达14000多次的代码提交,最终达到了之前预计的milestone, 并意味着这个开源容器编排系统可以正式在生产环境使用,必将推动容器生态及周边产业的进步发展。本次分享主要介绍kubernetes1.0较新的功能特性,包括服务发现方式及较新版本对应的设置变化,如何用dns方式构建内网服务发现,存储支持,如何解决集群存储及如何使用rbd的方式将ceph存储块附加到Pod,监控,如何在集群模式下搭建监控系统等话题。以及介绍Kuberentes官方发布时官方提到的功能理念及未来部分的功能扩展,包括k8s产品经理Craig McLuckie所提及的kubernetes的整体愿景等。
下文是本次的分享整理:
首先介绍 k8s v1.0的部分较新的特征,包括dns负载均衡,k8s监控和k8s ha高可用性的方式等
1. DNS,负载均衡
k8s服务发现通用两种方式, kube-proxy和DNS, 在v1之前,Service含有字段portalip 和publicIPs, 分别指定了服务的虚拟ip和服务的出口机ip,publicIPs可任意指定成集群中任意包含kube-proxy的节点,可多个。portalIp 通过NAT的方式跳转到container的内网地址。在v1版本中,publicIPS被约定废除,标记为deprecatedPublicIPs,仅用作向后兼容,portalIp也改为ClusterIp, 而在service port 定义列表里,增加了nodePort项,即对应node上映射的服务端口。
这样portlist里仅仅是一个容器端口到服务端口的maping,这种方式和marathon里的方式相似。loadbalancer项里是提供给外部clouder provider使用的,云提供商可以通过获取loadbanancer指定的入口ip和对应的虚拟服务入口,来建立自定义的服务连接通道,或者通过获取endpoint或pod直接将访问导入containter。当然,如果loadbanancer在集群外部,需要自行解决连入集群内网的问题。
dns服务发现,就是在k8s内网建立一套pod组合,对外提供dns服务。dns服务组本身是放在k8s平台里的,同时又给k8s平台提供服务。这个和监控的服务组合类似,当然也可以单独拿出来,以standalone的方式在k8s平台之外运行提供服务。
dns服务以addon的方式,需要安装skydns和kube2dns。kube2dns会通过读取kubernetes API获取服务的clusterIP和port信息,同时以watch的方式检查service的变动,及时收集变动信息,并将对于的ip信息提交给etcd存档,而skydns通过etcd内的dns记录信息,开启53端口对外提供服务。大概的dns的域名记录是 servicename.namespace.tenx.domain, "tenx.domain"是提前设置的主域名。
举例来说,如果在K8s中创建了一个服务“mysql-service", namespace是"tenxcloud", 这时会在skydns中形成记录 mysql-service.tenxcloud.tenx.domain。在后续创建的pod中,如果仍然以namespace 为tenxcloud创建,那么在pod内可以直接用 mysql-service 来访问上述服务,但如果在其他的namespace内访问,就需要加上命名空间名称,如mysql-service.tenxcloud。实际上最终的url是要加上端口号,需要在servcie定义中给端口命名,比如mysql-service 的访问端口是 {"name": "mysqlport" , "targetport": 3306, "protocol": "tcp"}, 那么对于的3306,对于的 DNS SRV记录是 _mysqlport._tcp.mysql-service.tenxcloud
kubernetes 支持以 "link"方式连接跨机容器服务,但link的方式依赖于服务的启动顺序,容错性能较差,官方更加推荐以dns的方式来构建。
2. kubernetes监控
比较老的版本 kubernetes需要外接cadvisor,主要功能是将node主机的container metrics抓取出来。在较新的版本里,cadvior功能被集成到了kubelet组件中,kubelet在与docker交互的同时,对外提供监控服务。
kubernetes集群范围内的监控主要由kubelet, heapster和storage backend(如influxdb)构建。Heapster可以在集群范围获取metrics和事件数据。它可以以pod的方式运行在k8s平台里,也可以单独运行以standalone的方式。
当以pod及服务方式运行时,heapster通过虚拟网访问kube-apiserver, 获取所有node的信息,主要是ip地址,然后通过node节点(ip地址)上Kubelet对外提供的服务获取对应pod的metrics。
Kubelet则通过内部集成cadvisor的组件或者最终的数据。最后,heapster会将获取的数据存储到后端, 现阶段后端存储支持Influxdb 和GCM等。
简单介绍下Influxdb, 它是时序数据库,即所有记录都带有时间戳属性。主要用于实时数据采集,事件跟踪记录,存储时间图表原始数据等。它的查询语言与SQL类似,又略有不同;对外提供RESTAPI接口。自带的操作面板可以直接把数据粗略转成曲线图表。支持定时自动运行的统计命令,比如,定时执行求取平均值并存到另外的表格,对于带有时间坐标的数据分析有很高的价值。目前在过时数据清理上略有瑕疵,不能定时自动清除过往数据,需要外接类似crontab等定时工具来处理。
Inflxudb可与Grafana结合,Grafana可将influxdb数据内容更好的呈现成图表曲线的形式,如果不需要提供对外产品的话,Grafana是很好的数据图形工具。
通过设置heapster --source 来设置数据来源,--sink 参数可以设定后端存储为influxdb。 heapster 抓取数据后,将分类存储到多个influxdb 表格中,包括cpu, memory, network, eventlog 等,另外可以设置定时统计命令来处理这些raw数据。
heapster目前未到1.0版本,对于小规模的集群监控比较方便。但对于较大规模的集群,heapster目前的cache方式会吃掉大量内存。因为要定时获取整个集群的容器信息,信息在内存的临时存储成为问题,再加上heaspter要支持api获取临时metrics,如果将heapster以pod方式运行,很容易出现OOM。所以目前建议关掉cache,并以standalone的方式独立出k8s平台,比如单独运行在一个VM上。而influxdb也要做好数据清理工作,日志及监控信息增长会给系统带来很大烦恼,外接crontab运行清除命令即可。但作为GoogleCloudPlatform的工具,heapster也有望以容器工具集项目的方式加入CNCF,所以建议k8s监控还是用heapster方式来做。
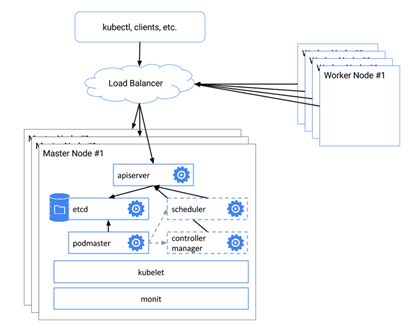
3. 官方Kubernetes HA的方式
利用etcd实现master 选举,从多个Master中得到一个kube-apiserver, 保证至少有一个master可用,实现high availability。对外以loadbalancer的方式提供入口。这种方式可以用作ha,但仍未成熟,据了解,未来会更新升级ha的功能。这里用到了kubelet的启动方式,--config参数,设置路径添加kubelet启动时刻需要做的动作。 --config=/etc/kubernetes/manifests,可以利用其创建pod。
有以下几点:
Process watcher,保证 master运行失败后自动重启,这个是必要条件。monit的方式,或者自行解决守护问题。
可靠的冗余存储, 使用etcd集群模式。 etcd是key value的存储方式,它的角色类似于zookeeper。etcd搭建集群节点至少3个,因为选举投票最终要确定leader和follower,初始投票会假定自身都是leader, 同时又都reject对方,无法形成多数的票数。3个可以形成多数对少数的情况,并且建议把投票timeout的设置成不同的时间。而5个以上较为稳定。
多个kube-apiserver, 用负载均衡的方式统一起来。node节点访问时,通过haproxy的入口,分发到不同的apiserver, 而apiserver背后是相同的etcd集群。
用组件podmaster 模拟选举。它利用etcd实现一个选举算法。类似zookeeper的方式,选举出来的kube-apiserver被启动并作为主出口,其他的kube-apiserver处于standby的状态被停止。
安装部署 kube-sheduller和kube-controller-manager,这里在每台master机器上同时存在一套 kube-apiserver, kube-scheduller 和kube-controller-manager,并且以localhost的方式连接。这样当kube-apiserver被选中时,同机的kube-scheduller和kube-controoler-manager起作用,当standby时,同机的3个组件都会不可用。
也就是说,etcd集群背景下,存在多个kube-apiserver,并用pod-master保证仅是主master可用。同时kube-sheduller和kube-controller-manager也存在多个,但伴随着kube-apiserver,同一时间只能有一套运行。
QA节选:
问题1:有几个问题:1.容器 net方式 网络性能损失多少,2 .k8s是怎么做到的容器自动迁移?
杨乐:容器是建在pod里,实际上最终用的是docker 的 网络参数,同pod里不用转发,是docker本身的功能,在虚拟网络里,是以NAT的方式。
问题2:K8s是不是定义的一个pod的容器集群是只部署在同一个主机上?
杨乐:到目前是,同一个pod里的containerS 是部署在同一台主机的。
问题3:这个图里的loadbalancer是安装在哪里的?所有的客户端以及kubelete会连接这个嘛?
杨乐:loadbanlancer可以任意地方,只要能访问到集群,会作为api的出口。
问题4:K8s中的etcd放在容器里的吗?
杨乐:不用放在里面,可以放进去,也可以在外面。