InnoDB引擎Myslq数据库数据恢复
首先祝愿看到这片文章的你永远不要有机会用到它...
本文指针对用InnoDB引擎的Mysql数据库的数据恢复,如果是其它引擎的Mysql或其它数据库请自行google...
如果有一天你手挫不小心删掉了正式数据库中的数据,甚至把整个库给drop掉了,瞬间感觉眼前一黑有木有,感觉就像世界末日到了有木有,如果你有数据库备份还好,回复备份中的数据即可,或者你开了Mysql的二进制日志记录好像也可以从里面恢复,可是如果木有备份又木有开二进制日志记录是不是感觉苦逼了无从下手,下面的内容就针对这种情况给出一些解决方法...
1.首先你要尽快停掉mysql服务,把mysql数据库data文件夹下的内容全部拷出来,防止之后的操作覆盖删掉的数据。
2.准备一个Linux系统我用的是Ubuntu 12.04。
3.准备数据库恢复工具percona-data-recovery-tool-for-innodb,关于percona-data-recovery-tool-for-innodb:
3.1.这个工具只能对InnoDB/XtraDB表有效,而无法恢复MyISAM表。
3.2.这个工具是以保存的MySQL数据文件进行恢复的,而不用MySQL Server运行。
3.3.不能保证数据总一定可被恢复。例如,被重写的数据不能被恢复。
3.4.使用这个工具需要手动做一些工作,并不是全自动完成的。
3.5.恢复过程依赖于你对丢失数据的了解程度,在恢复过程中可能需要在不同版本的数据之间做出选择。那么如果你越了解自己的数据,恢复的可能性就越大。
4.下载percona-data-recovery-tool-for-innodb并解压,打开终端,输入以下命令:
wget https://launchpad.net/percona-data-recovery-tool-for-innodb/trunk/release-0.5/+download/percona-data-recovery-tool-for-innodb-0.5.tar.gz tar -zxvf percona-data-recovery-tool-for-innodb-0.5.tar.gz
4.1.转到解压后的目录的mysql-source子目录,运行配置命令:
cd percona-data-recovery-tool-for-innodb-0.5/mysql-source ./configure
4.2.完成配置步骤后,回到解压后的根目录,运行make命令,编译生成page_parser和constraints_parser工具(如果编译过程中出现问题,诸如包依赖之类的,请根据错误提示自行补全):
cd ..
make
5.提取数据
InnoDB页的默认大小是16K,每个页属于一个特定表中的一个特定的index。page_parser工具通过读取数据文件,根据页头中的index ID,拷贝每个页到一个单独的文件中。
如果你的MySQL server被配置为innodb_file_per_table=1,那么系统已经帮你实现上述过程。所有需要的页都在.ibd文件,而且通常你不需要再切分它。然而,如果.ibd文件中可能包含多个index,那么将页单独切分开还是有必要的。如果MySQL server没有配置innodb_file_per_table,那么数据会被保存在一个全局的表命名空间(通常是一个名为ibdata1的文件,本文属于这种情况),这时候就需要按页对文件进行切分。
5.1.切分页--在解压后的根目录下新建dbfile文件夹并把你拷的data目录下的ibdata1文件复制到该文件夹。
5.1.1.如果MySQL是5.0之前的版本,InnoDB采取的是REDUNDANT格式,在终端运行以下命令:
./page_parser -4 -f ./dbfile/ibdata1
5.1.2.如果MySQL是5.0及以上版本,InnoDB采取的是COMPACT格式,在终端运行以下命令:
./page_parser -5 -f ./dbfile/ibdata1
5.2.运行后,page_parser工具会创建一个pages-<TIMESTAMP>的目录,其中TIMESTAMP是UNIX系统时间戳。在这个目录下,为每个index ID,以页的index ID创建一个子目录。如图:
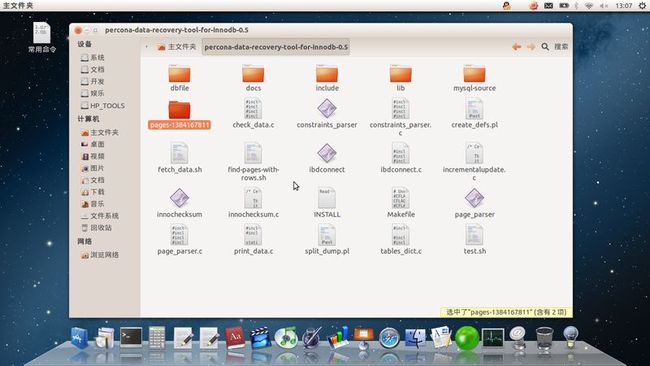
5.3.选择需要的Index ID
5.3.1.如果你只是删除了表中的数据而没有删除表,那么可以启动InnoDB Tablespace Monitor,输出所有表和indexes,index IDs到MySQL server的错误日志文件。创建innodb_table_monitor表用于收集innodb存储引擎表及其索引的存储方式:
mysql> CREATE TABLE innodb_table_monitor (id int) ENGINE=InnoDB;
如果innodb_table_monitor已经存在,drop表然后重新create表。等MySQL错误日志输出后,可以drop掉这张表以停止打印输出更多的监控。一个输出的例子如下:
TABLE: name sakila/customer, id 0 142, columns 13, indexes 4, appr.rows 0 COLUMNS: customer_id: DATA_INT len 2 prec 0; store_id: DATA_INT len 1 prec 0; first_name: type 12 len 135 prec 0; last_name: type 12 len 135 prec 0; email: type 12 len 150 prec 0; address_id: DATA_INT len 2 prec 0; active: DATA_INT len 1 prec 0; create_date: DATA_INT len 8 prec 0; last_update: DATA_INT len 4 pr ec 0; DB_ROW_ID: DATA_SYS prtype 256 len 6 prec 0; DB_TRX_ID: DATA_SYS prtype 257 len 6 prec 0; DB_ROLL_PTR: DATA_SYS prtype 258 len 7 prec 0; INDEX: name PRIMARY, id 0 286, fields 1/11, type 3 root page 50, appr.key vals 0, leaf pages 1, size pages 1 FIELDS: customer_id DB_TRX_ID DB_ROLL_PTR store_id first_name last_name email address_id active create_date last_update INDEX: name idx_fk_store_id, id 0 287, fields 1/2, type 0 root page 56, appr.key vals 0, leaf pages 1, size pages 1 FIELDS: store_id customer_id INDEX: name idx_fk_address_id, id 0 288, fields 1/2, type 0 root page 63, appr.key vals 0, leaf pages 1, size pages 1 FIELDS: address_id customer_id INDEX: name idx_last_name, id 0 289, fields 1/2, type 0 root page 1493, appr.key vals 0, leaf pages 1, size pages 1 FIELDS: last_name customer_id
这里,我们恢复的是sakila库下的customer表,从上面可以获取其主键信息:
INDEX: name PRIMARY, id 0 286, fields 1/11, type 3
5.3.2如果你把整个数据库都drop掉了,那是没办法按照上面的方法找到需要的Index ID的,那么你可以用一下的方法来获取需要的Index ID:
A:如果你能确定需要的表中有一些字段会有特殊值只在这个表中有记录,那么可以用以下命令搜索全部切分后的页:
grep -r "CP201310090001" pages-1384167811
搜索后的结果如图(可以看到0-968就是需要的Index ID):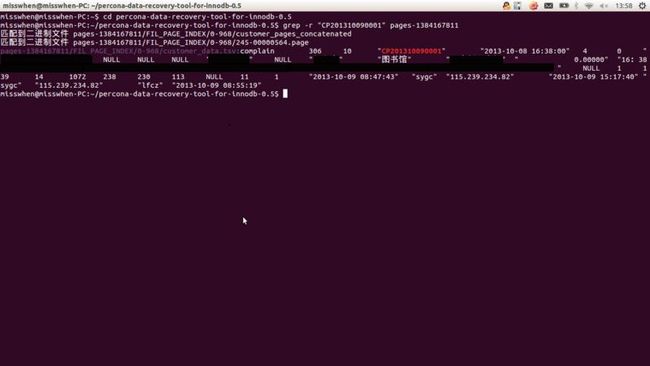
B:如果找不出特殊值,官方教程好像说可以通过表字段名称搜索全部切分后的页,可是由于上面说的很笼统,我测试半天没有成功,有需要可以参考链接:http://www.percona.com/docs/wiki/innodb-data-recovery-tool:mysql-data-recovery:advanced_techniques#finding_index_ids
C:最后方法,暴力破解,由于我要回复的表除A方法里面的之外其它的没有特殊值,B方法也没研究出来,只能通过脚本循环所有文件来比对了,首先需要执行5.4,5.5步骤,生成好要查找的表定义并编译constraints_parser工具,然后在解压根目录新建一个shell脚本,我命名的是test.sh,脚本内容:
#!/bin/bash function ergodic(){ for file in ` ls $1` do if [ -d $1"/"$file ] then ergodic $1"/"$file else echo $1"/"$file #输出文件的完整的路径 ./constraints_parser -5 -f $1"/"$file #提取数据 echo $1"/"$file #输出文件的完整的路径 sleep 1 #暂停一秒 fi done } INIT_PATH="pages-1384167811/FIL_PAGE_INDEX" #这里是分页后页面文件所在的文件夹 ergodic $INIT_PATH
然后在终端输入./test.sh执行脚本,盯着终端直到终端输出有数据,且不是乱码的时候,那么当前提取的文件所在的文件夹名就是你要找的Index ID,然后执行5.6,5.7的过程即可,截图如下: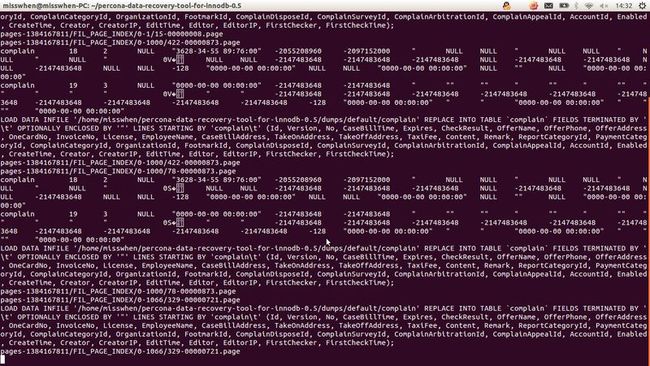
5.4.生成表定义,这需要你知道要恢复表的结构,最简单的方法在测试服务器上新建一个与要恢复数据库一样的数据库,然后在终端输入(如果不知道表结构,也有可能通过表定义文件.frm回复,详细请参考:http://www.percona.com/docs/wiki/innodb-data-recovery-tool:mysql-data-recovery:advanced_techniques#getting_create_table_from_frm_files):
./create_defs.pl --host=服务器地址 --user=用户名 --password=密码 --db=数据库名 --table=表名 > include/table_defs.h
然后转到解压根目录下的include子目录打开table_defs.h文件,检查一下生成的是否正确,防止你在上面的数据库或表名写错而生成定义为空的文件,如图: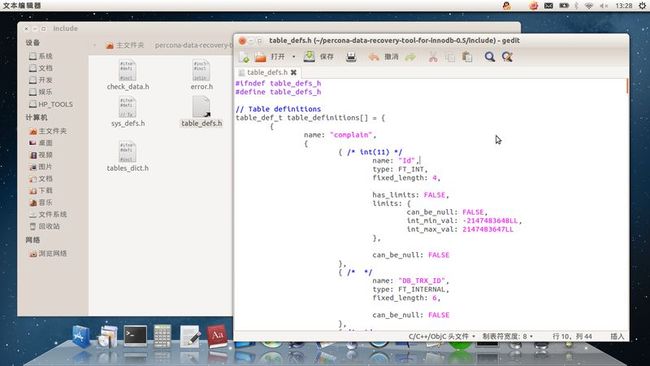
5.5.编译constraints_parser工具(每次生成表定义后都要重新编译):
make gcc -DHAVE_OFFSET64_T -D_FILE_OFFSET_BITS=64 -D_LARGEFILE64_SOURCE=1 -D_LARGEFILE_SOURCE=1 -g -I include -I mysql-source/include -I mysql-source/innobase/include -c tables_dict.c -o lib/tables_dict.o gcc -DHAVE_OFFSET64_T -D_FILE_OFFSET_BITS=64 -D_LARGEFILE64_SOURCE=1 -D_LARGEFILE_SOURCE=1 -g -I include -I mysql-source/include -I mysql-source/innobase/include -o constraints_parser constraints_parser.c lib/tables_dict.o lib/print_data.o lib/check_data.o lib/libut.a lib/libmystrings.a gcc -DHAVE_OFFSET64_T -D_FILE_OFFSET_BITS=64 -D_LARGEFILE64_SOURCE=1 -D_LARGEFILE_SOURCE=1 -g -I include -I mysql-source/include -I mysql-source/innobase/include -o page_parser page_parser.c lib/tables_dict.o lib/libut.a
5.6.合并页,切分页后生成的Index号码的文件夹下面会有好多文件,提取记录前需要先把这些文件合并成一个文件:
find pages-1384167811/FIL_PAGE_INDEX/0-968/ -type f -name '*.page' | sort -n | xargs cat > pages-1384167811/FIL_PAGE_INDEX/0-968/customer_pages_concatenated
合并后如图:
5.7.提取合并后的数据:
./constraints_parser -5 -f pages-1384167811/FIL_PAGE_INDEX/0-968/customer_pages_concatenated > pages-1384167811/FIL_PAGE_INDEX/0-968/customer_data.tsv
提取后的文件如图:
文件中的内容就是表中的记录,你可以直接把tsv文件中的内容导入到数据库,也可以打开tsv文件把内容复制到excel表格中,用你习惯的方式导入。