Oracle之Group By
前几天把《Oracle SQL高级编程》看完了,受益匪浅。近期抽空写些总结
以下内容这里另一位作者写的很简练http://www.2cto.com/database/201204/126721.html
准备实验数据
create table sales_log(
category varchar2(10),
year varchar2(4),
month varchar2(2),
sales number
);
declare
type categorys_varray is varray(3) of varchar2(10);
v_categorys categorys_varray := categorys_varray('Apple', 'Orange', 'Banana');
type years_varray is varray(3) of varchar2(4);
v_years years_varray := years_varray('2011', '2012', '2013');
type months_varray is varray(12) of varchar2(2);
v_months months_varray := months_varray('1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12');
v_sales number;
begin
for i in 1..v_categorys.count loop
for j in 1..v_years.count loop
for k in 1..v_months.count loop
SELECT TRUNC(100+900*dbms_random.value) into v_sales FROM dual;
insert into sales_log(category, year, month, sales) values(v_categorys(i), v_years(j), v_months(k), v_sales);
end loop;
end loop;
end loop;
commit;
end;
一、group by基本用法:
1)计算每年的总销售额
select year, sum(sales) from sales_log group by year;

2)各类水果在各年的销售额
select year, category, sum(sales) from sales_log group by year, category;
在select 列表中指定的列要么是group by 子句中指定的列,要么包含聚组函数
如果想对分组结果进行排序,必须手动指定order by

二、having
1)查出2013年销售额在1w以上的水果
select category, sum(sales) from sales_log where year = '2013' group by category having sum(sales) > 7000;
where是针对原数据进行筛选,而having子句只是针对汇总后的结果进行筛选
![]()
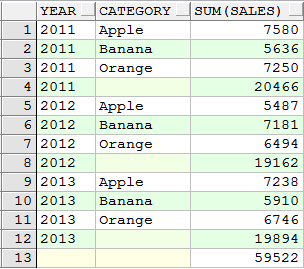
三、cube
1)统计每种水果每年的销售额、每种水果所有销售额、每年销售额、全部销售额
select category, year, sum(sales)
from sales_log
group by cube(category, year)
order by category, year nulls last;
categroy,year分组合计
category分组合计
year分组合计
总计
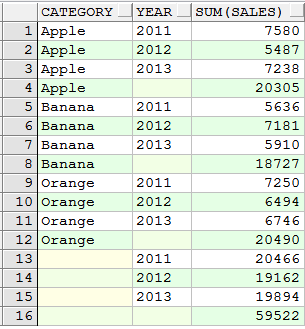
四、grouping (只用于rollup和cube)
1)对上面结果的空值进行处理,以'ALL YEAR'代替NULL表示所有年份,以'ALL CATEGORY'代表所有种类
select decode(grouping(category), 1, 'ALL CATEGORY', category), decode(grouping(year), 1, 'ALL YEAR', year), sum(sales) from sales_log group by cube(category, year) order by category, year;
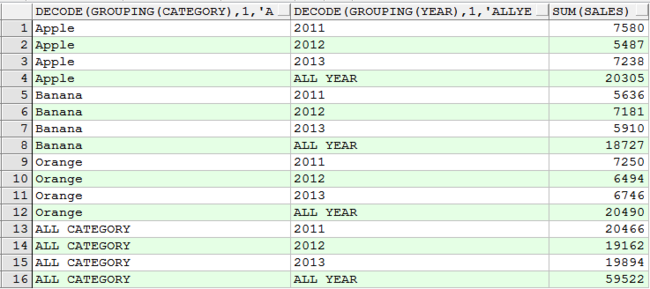
2) 统计每种水果每年的销售额、每种水果所有销售额、每年销售额、全部销售额
select decode(grouping(category), 1, 'ALL CATEGORY', category), year, sum(sales) from sales_log group by cube(category, year) having grouping(year) != 1 order by category, year;
使记录含义更清晰,而不是单纯的一个null值。
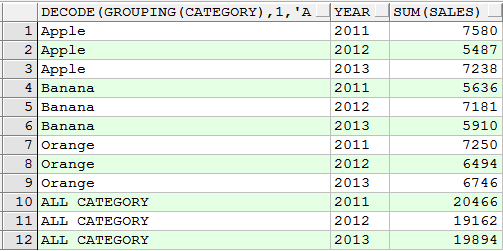
五、grouping_id (since 9i)
1)分别对"每种水果每年的销售额"、"每种水果所有销售额"、"每年销售额"、"全部销售额"进行分类标识
select grouping_id(category, year), decode(grouping(category), 1, 'ALL CATEGORY', category), decode(grouping(year), 1, 'ALL YEAR', year), sum(sales) from sales_log group by cube(category, year) order by category, year;
是grouping()的扩展,相当于grouping_id(category,year)=(grouping(category) || grouping(year)表示的二进制)的值
结果分为三类

六、group_id() 刚认识这个函数,待进一步测试
select group_id(), grouping_id(category, year), decode(grouping(category), 1, 'ALL CATEGORY', category), decode(grouping(year), 1, 'ALL YEAR', year), sum(sales) from sales_log group by cube(category, year) order by category, year;
group_id()函数,无参数,可以表示此分组记录是否重复,0表示第一次,1表示重复。
七、grouping sets
1)统计每种水果每年的销售额、每种水果所有销售额、每年销售额、全部销售额
select category, year, sum(sales) from sales_log group by grouping sets((category, year), (category), (year), ())
分别以按(category,year)和(category)以及(year)的作为group by的条件分组
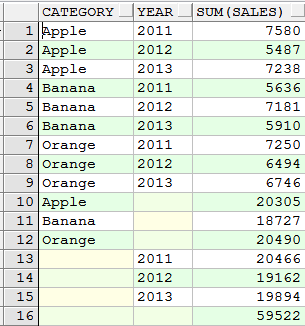
八、rollup ( 可以和cube对比一下)
1)统计全年销售额、每种水果每年销售额
select year, category, sum(sales) from sales_log group by rollup(year, category);
category,year分组合计
category分组合计
总计