webx2.0-RundataService学习总结
概述
作为一个新人,在学习webx框架的一些体会,总结一些经验,也籍此希望对后来的同学有一点细微的帮助。
预备知识需要了解service框架
简单解析一下Webx框架中RunDataService组件。下面是本文着力解决的几个问题:
下面将基于这几个问题展开论述。
RundataService在框架中的地位
RundataService为什么需要存在
RundataService为框架带来了哪些便利,它实现了哪些功能
生成的Rundata结构是怎样的
Rundata工作原理
Rundata是如何设计的,设计理念又是什么
最终生成的Rundata是啥样的
RundataService作为Webx框架的核心服务之一,框架的核心就是包装用户的请求数据,然后根据请求信息,再找到用户的所需要的资源,再包装这些资源,将这些包装的资源最后解析成 http协议格式返回给用户。而RundataService在这当中就起到了从接收用户的请求信息到最终返回给用户这个过程中所做的信息传递者的角色,你可以看出他在Webx中地位。
RundataService存在的必要性
Webx框架提供了两个服务,控制着整个http请求的走向,两个服务各司其职。
Request Contexts服务
该服务负责访问和修改request和response,但不负责改变应用执行的流程。
Pipeline服务
提供应用执行的流程,但不关心request和response。
RundataService用途
buffered服务
缓存response中的内容
lazy-commit服务
延迟提交response
parser服务
解析参数,支持multipart/form-data
rewriter服务
重写请求的URL和参数
session服务
一套可扩展的session框架,重新实现了HttpSession接口
set-local服务
设置locale区域和charset字符集编码
buffered服务
对Response进行包装,把写入Response中的数据先缓存起来,提供了缓存功能。具体应用在生成嵌套的页面部件和保存cookie这两个方面
lazy-commit服务
对Response进行包装,延迟提交数据,在所有请求完结束后提交。response.sendError(),response.sendRedirect(),response.flushBuffer(),response.setContentLength() 或者response.setHeader("Content-Length", length),response输出流被写入并达到内部buffer的最大值(例如:8KB)会导致报文的提交,当response被提交以后,一切headers都不可再改变。这对于某些应用(例如cookie-based session)的实现是一个大问题。
parse服务
对Request进行包装,特别是扩展了mutil-request的功能,如文件上传等。具体的用途有:
直接取得指定类型的参数
如果参数值未提供,或者值为空,则返回指定默认值
取得上传文件的FileItem对象
黄埔实训的时候用到了上传文件的功能,就拿这来举个例子:
由于multipart/form-data 是新增的编码类型, 而非标准的HTTP协议, 所以添加了这些属性之后, 需要做一些特殊处理. 原因在于, HTTP上传功能是把请求以一个HTTP流的方式发送到服务器上,而HTTP头和form其 他字段也都是在同一个流中, 所以需要把文件信息从HTTP流中分离出来。
Content-Type multipart/form-data; boundary=---------------------------7008609411307065658643635354
服务器端获得了HTTP流信息, 并且知道其格式之后, 就可以进行处理, 把文件信息分离出来. 处理的流程应该如下:
1.按照分隔符的分隔规则, 解析出各个字段的信息;
2.对各个字段进行判断, 如果是普通的input的类型, 则回填到表单中; 如果是file类型, 则读出file的内容并回填到相应的表单项中.
按照以上的步骤进行处理时, 遇到了问题, 使用下面的代码不能获得FileItem数组, items为null:
FileItem[] items = uploadHtml.parseRequest(rundata.getRequest());
程序抛出了stream ended unexpectedly异常,其实框架已经完成了上面所说的HTTP流的处理, 并且把分离后的数据重新回填到rundata中了. HTTP流已经解析过一次, 所以不能再次被解析. webx已经把解析工作完成, 所以接下来直接拿到file的内容回填就可以了.
FileItem item = rundata.getParameters().getFileItem("poNewContentUploadFile");String htmlBuffer = item.getString();this.getGroup(rundata,"contentForm").getField("htmlContent").setValue(htmlBuffer);
还提供了比较方便的访问cookie值的方法
参数名称大小写转换
过滤参数
rewrite服务
感觉框架没怎么用,但是确实功能很强大,我们平时编程都是在程序里控制~~
排序
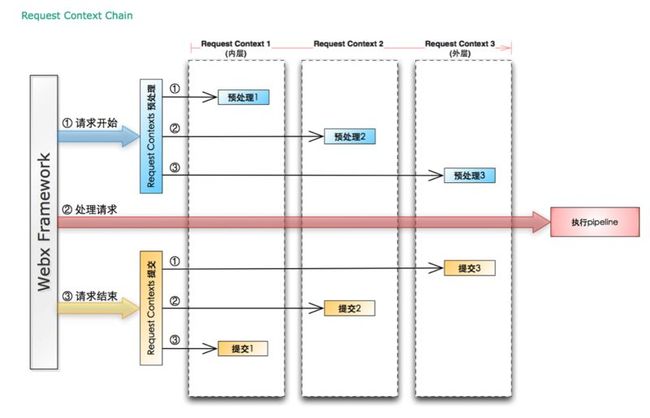
Request Contexts之间,有时会有依赖关系,所以Request Contexts出现的先后顺序是非常重要的。例如:
<session>提供了基于cookie的session支持。然而cookie属于response header。一旦response被提交,header就无法再修改了。因此<session>依赖于<lazy-commit>,以阻止response过早提交。也就是说,<lazy-commit>必须排在<session>之前。
<rewrite>需要访问参数,而参数是能过<parser>解析的,所以<parser>要排在<rewrite>之前。
不过貌似框架有自动排序功能,我也没仔细看到这一点。
Rundata结构图

Rundata工作原理
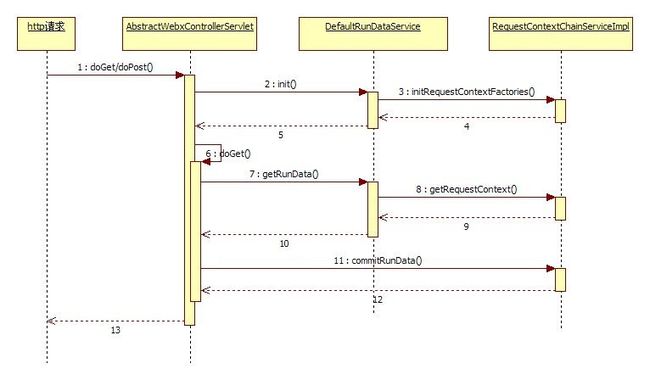
Rundata生命周期的时序图
Rundata中的设计模式
在实现RundataContext的过程中涉及到了两种设计模式:装饰模式和工厂模式
装饰模式

//为了便于说明,代码和源码有出入,但是原理是一样的: Request request = new BufferedRequestContextImpl(request); Request request = new LazyCommitRequestContext(request); Request request = new RewriterRequestContext(request); Request request = new ParserRequestContext(request);
public class BufferedRequestContextImpl extends AbstractRequestContextWrapper
implements BufferedRequestContext {
/**
* 包装一个<code>RequestContext</code>对象。
*
* @param wrappedContext 被包装的<code>RequestContext</code>
*/
public BufferedRequestContextImpl(RequestContext wrappedContext) {
//保存对象的引用,装饰模式因此而闪亮
super(wrappedContext);
//这个service具体干的事,即对response作处理
setResponse(new BufferedResponseImpl(this, wrappedContext.getResponse()));
}
//doGet中开始提交 commitRunData(rundata)
//从这个方法可以看到是由外而内提交的
public void commitRequestContext(RequestContext requestContext)
throws RequestContextException {
while (requestContext != null) {
String message = "Committing request context: "
+ ClassUtil.getShortClassNameForObject(requestContext) + "("
+ ObjectUtil.identityHashCode(requestContext) + ")";
getLogger().debug(message);
Profiler.enter(message);
try {
requestContext.commit();
} finally {
Profiler.release();
}
requestContext = requestContext.getWrappedRequestContext();
}
}
}
工厂模式

每个factory的生命周期由serviceManager来管理,默认的操作由抽象类来完成,比如初始化和销毁等操作;但是每个工厂只生产一种实例,为什么还要整个工厂模式呢?看下面代码:
public class BufferedRequestContextFactory extends AbstractRequestContextFactory {
/**
* 包装一个request context。
*
* @param wrappedContext 被包装的<code>RequestContext</code>对象
*
* @return request context
*/
public RequestContext getRequestContextWrapper(RequestContext wrappedContext) {
return new BufferedRequestContextImpl(wrappedContext);
}
}
public class ParserRequestContextFactory extends AbstractRequestContextFactory {
.......
public RequestContext getRequestContextWrapper(RequestContext wrappedContext) {
ParserRequestContextImpl requestContext = new ParserRequestContextImpl(wrappedContext);
requestContext.setAutoUpload(autoUpload);
requestContext.setCaseFolding(folding);
requestContext.setUnescapeParameters(unescapeParameters);
if (autoUpload) {
UploadService upload = null;
try {
upload = (UploadService) getRequestContextChainService().getServiceConfig().getService(
UploadService.SERVICE_NAME);
} catch (ServiceInstantiationException e) {
log.error("Unable to load UploadService", e);
}
requestContext.setUploadService(upload);
}
if (filter != null) {
requestContext.setParameterParserFilter(filter);
}
requestContext.setHtmlFieldSuffix(htmlFieldSuffix);
return requestContext;
}
}
}
因为每个service产生的方法各不相同,但是具体获取途经又要对用户透明,因此采用了工厂模式,用户之需要从工厂中get就可以了!
Rundata里面究竟有什么
linux下截图比较麻烦,给他贴图,内容都是一样的:
重点关注下最下面的class,这不正体现了装饰模式,同时通过观察这个顺序你可以试下框架会不会自动排序!~