关于ejabberd里面设计gen_iq_handler的理解
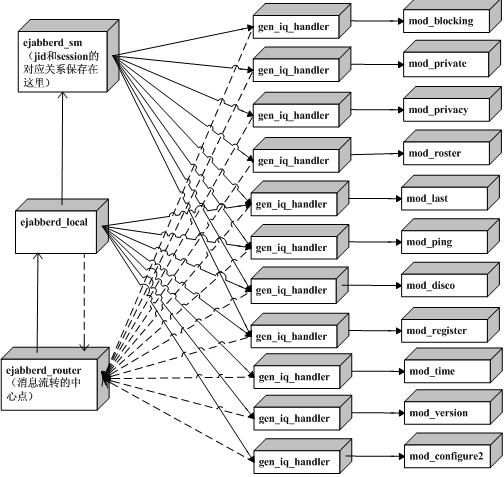
上图是我之前给同事做ejabberd代码走读的时候画的一个消息流图,当时一个同事问我“ejabberd为什么要设计gen_iq_handler这个模块?”我当时没回答出来,让另外一个同事简单回答了一下。事后我又研究了一下代码,觉得设计gen_iq_handler的原因有以下几个?
1:模块配置里面有{iqdisc, Value}这一项配置,value的值可以是no_queue, one_queue, {quques, N}和parallel。gen_iq_handler里面对不同的配置有不同的处理代码,如下:
add_iq_handler(Component, Host, NS, Module, Function, Type) ->
case Type of
no_queue ->
Component:register_iq_handler(Host, NS, Module, Function, no_queue);
one_queue ->
{ok, Pid} = supervisor:start_child(ejabberd_iq_sup,
[Host, Module, Function]),
Component:register_iq_handler(Host, NS, Module, Function,
{one_queue, Pid});
{queues, N} ->
Pids =
lists:map(
fun(_) ->
{ok, Pid} = supervisor:start_child(
ejabberd_iq_sup,
[Host, Module, Function]),
Pid
end, lists:seq(1, N)),
Component:register_iq_handler(Host, NS, Module, Function,
{queues, Pids});
parallel ->
Component:register_iq_handler(Host, NS, Module, Function, parallel)
end.
2:有些IQ结的业务处理很耗时,而有些IQ结的业务处理很快。
3:对于耗时的IQ结处理,不能把模块的iqdisc配置成no_queue,因为如果这样做的话,由下面面的代码可知,这条session连接就会被阻塞,直到这个IQ结处理完才能继续处理下一个数据包。
handle(Host, Module, Function, Opts, From, To, IQ) ->
case Opts of
no_queue ->
process_iq(Host, Module, Function, From, To, IQ);
{one_queue, Pid} ->
Pid ! {process_iq, From, To, IQ};
{queues, Pids} ->
Pid = lists:nth(erlang:phash(now(), length(Pids)), Pids),
Pid ! {process_iq, From, To, IQ};
parallel ->
spawn(?MODULE, process_iq, [Host, Module, Function, From, To, IQ]);
_ ->
todo
end.
4:设计gen_iq_handler以后,主业务逻辑不需要直接访问相应的mod_功能模块,也就不需要关心这些模块的配置。主业务逻辑只需要调用gen_iq_handler提供的简单接口,所有这些功能模块的配置细节,以及如何根据这些配置细节来调用相应的功能模块,由gen_iq_handler来处理。gen_iq_handler屏蔽了各模块的调用差异。
5:配置成one_queue, {quques, N}和parallel的这些功能模块,也不需要重复实现gen_server行为模式,由gen_iq_handler来帮他们实现。这样做还有一个好处,就是使模块可以自由的在no_queue和one_queue, {quques, N}和parallel自由切换,而不需要增加或减少任何代码,只需要修改配置。
6:模块的增减,不需要修改主业务逻辑代码,只需要增加/减少mod_功能模块以及修改配置。