MySQL 查询优化器(四)
2.5 LEFT JOIN查询
该测试主要用于测试LEFT JOIN与JOIN的处理逻辑上的差异,具体查询处理逻辑如下所示:
JOIN:prepare阶段
setup_tables():同2.1测试。
setup_fields():同2.1测试。
setup_conds():同2.4测试。
JOIN:optimize阶段
simplify_joins():类似2.4测试。不同之处在于由于LEFT JOIN 使用的数据表不能为 NULL表,这是由是否有where条件过滤决定的。所以该过程会将LEFT JOIN外链接查询转化为多表联合查询操作,从而忽略LEFT JOIN的链接操作。
optimize_cond():同2.1测试。
make_join_statistics():同2.4测试。
choose_plan():同2.1测试。
greedy_search():同2.1测试。
best_extension_by_limited_search():同2.4测试。
get_best_combination():同2.4测试。
JOIN:exec阶段
以下同2.4测试。
Left join嵌套(join)查询,执行SQL:
SELECT student.std_id, std_name, std_spec, std_***, std_age, cur_name, cur_credit, cur_hours, score FROM student LEFT JOIN(course JOIN std_cur ON std_cur.cur_id=course.cur_id) ON (student.std_id=std_cur.std_id) WHERE course.cur_name = 'C';
对应的查询计划如下所示:

通过以上测试发现,除了在simplify_joins()处有略微的不同之外,其他处理逻辑和查询计划与测试2.4都是一样的。而LEFT JOIN从理论来说,会将左边的表的进行全表扫描,而右边的表中如果没有匹配的记录时,会用NULL值填充。然后从查询结果来看,查询的记录并非student表的所有记录。并且从查询计划来看,student表的查询类型不是ALL。
通过查看simplify_joins()函数的注释和源码实现发现,OUTER JOIN可以转化为INNER JOIN,转化的条件与used_tables和not_null_tables的值有关。而not_null_tables的值是根据where条件决定的。如果有where条件过滤,那么LEFT JOIN会被转化为INNER JOIN查询。更进一步的研究,将作为单独的问题进行详细的研究和测试。
2.6 Natural JOIN查询
Natural JOIN的查询处理逻辑如下所示:
JOIN:prepare阶段
setup_tables():类似2.1测试,不同之处在于调用setup_natural_join_row_types()函数将Natural JOIN查询转化为JOIN ON查询。转化过程为:找到共同的字段名,作为ON的条件进行链接查询。
setup_fields():同2.1测试。
setup_conds():同2.3测试。
JOIN:optimize阶段
simplify_joins():同2.3测试。
optimize_cond():同2.1测试。
make_join_statistics():同2.3测试。
choose_plan():同2.1测试。
greedy_search():同2.1测试。
best_extension_by_limited_search():同2.3测试。
get_best_combination():同2.3测试。
JOIN:exec阶段
以下同2.3测试。
Natural join查询,执行SQL:
SELECT student.std_id, std_name, std_spec, std_***, std_age, cur_name, cur_credit, cur_hours, score FROM student NATURAL JOIN std_cur NATURAL JOIN course WHERE course.cur_id = 101;
对应的查询计划如下所示:

由以上查询处理逻辑和查询计划可以看出,Natural JOIN查询处理与JOIN ON的处理方式类似。唯一不同之处在set_tables()处理阶段,调用setup_natural_join_row_types()函数将Natural JOIN查询转化为JOIN ON查询。从官方文档中可以知道,Natural JOIN也说明了该查询的处理逻辑[1]。应用中,Natural JOIN查询有其局限性,必须有相同的字段名,才能使用。因此,在查询处理中,应避免使用不明确的字段进行联合查询,使用用明确的字段进行链接,不但能够获取到正确的查询结果,而且可以避免MySQL额外的查询处理逻辑。
2.7 Straight_JOIN查询
STRAIGHT_JOIN查询是是 MySQL 对标准 SQL 的扩展,用于在多表查询时指定表载入的顺序。具体的查询处理逻辑如下所示:
JOIN:prepare阶段
setup_tables():同2.1测试,
setup_fields():同2.1测试。
setup_conds():同2.3测试。
JOIN:optimize阶段
simplify_joins():类似2.3测试,不同之处在于根据STRAIGHT_JOIN的条件,为数据表建立依赖关系,也就是说右部的表依赖于左部的表。同样,转化为JOIN的查询处理。
optimize_cond():同2.1测试。
make_join_statistics():同2.3测试。
choose_plan():同2.1测试。
greedy_search():同2.1测试。
best_extension_by_limited_search():类似2.3测试,不同之处在于根据表的依赖关系,查找最优的查询计划。由于右部的表依赖于左部的表,因此在组合查找最优路径时,右部的表必须始终在左部的表的后面。
get_best_combination():同2.3测试。
JOIN:exec阶段
以下同2.3测试。
由于STRAIGHT_JOIN的查询与表的顺序有关系,为了体现这一特点,测试两条不同表顺序的SQL语句进行比较查询计划的不同。
Straight_join查询,执行SQL:
SELECT student.std_id, std_name, std_spec, std_***, std_age, cur_name, cur_credit, cur_hours, score FROM student STRAIGHT_JOIN(course STRAIGHT_JOIN std_cur ON std_cur.cur_id=course.cur_id) ON (student.std_id=std_cur.std_id) WHERE course.cur_name = 'C';
第一条SQL查询对应的查询计划如下所示:
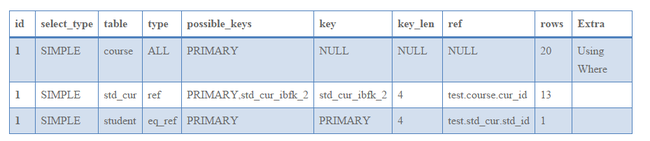
执行SQL:
SELECT student.std_id, std_name, std_spec, std_***, std_age, cur_name, cur_credit, cur_hours, score FROM student STRAIGHT_JOIN(std_cur STRAIGHT_JOIN course ON std_cur.cur_id=course.cur_id) ON (student.std_id=std_cur.std_id) WHERE course.cur_name = 'C';
第二条SQL查询对应的查询计划如下所示:
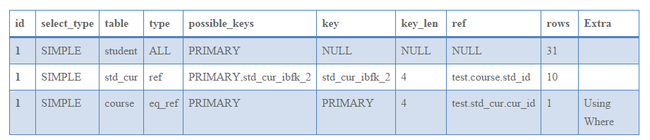
通过以上查询处理逻辑来看,STRAIGHT_JOIN与JOIN查询类似,不同之处在于将STRAIGHT_JOIN转化为表的依赖关系,从而限制查找最优查询计划过程中表的组合方式,而没有直接调用函数optimize_straight_join() (sql\sql_select.cc:5108)来取代greedy_search()函数的优化。
此外,从查询计划来看,第一个SQL查询没有按照指定的表的顺序执行,这是因为指定的student表和course表没有关联关系,转化为JOIN查询处理,通过查询优化器计算的代价来决定student加载的顺序。而course表与std_cur表存在关联关系,所以会按照course表首先加载,std_cur表后加载。而从第二个SQL查询来看,完全按照指定表的顺序进行加载。
2.8 子查询
在SQL查询中有子查询时,查询处理逻辑就远远不是以上处理逻辑了,查询处理过程的入口函数为execute_sqlcom_select()(sql\sql_parse.cc:4530)。因为从该函数开始,就已经对子查询进行处理。当然之前的查询处理也都从该函数入口,但是之前的查询在该过程中并没有特殊的处理,并且主要分析查询优化器的处理逻辑,因此没有就该部分做过多的分析。
具体的查询处理逻辑如下所示:
execute_sqlcom_select():查询入口函数。由于子查询中的表tmp不是实际的表,因此,会首先对子查询进行处理。首先调用open_and_lock_tables()函数打开查询中的所有表并添加锁。其次调用handle_select()函数处理查询处理。
open_and_lock_tables():该函数用于打开SQL查询中的表,并添加锁。此外,还会处理驱动表。调用open_tables()函数打开所有的表,lock_tables()函数为所有表添加锁,调用mysql_handle_derived()函数处理驱动表。而对子查询来说,特殊的处理逻辑为调用mysql_handle_derived()处理驱动表的过程。(sql\sql_base.cc:5494)
mysql_handle_derived():用于处理驱动表,实际处理过程根据给定的函数指针,执行对应的处理阶段。首先调用mysql_derived_prepare()函数中的处理逻辑,准备子查询的处理逻辑;其次调用mysql_derived_filling()函数处理子查询中的优化和执行的处理逻辑;最后调用mysql_derived_cleanup()函数清理子查询使用的资源。(sql\sql_derived.cc:46)
mysql_derived_prepare():用于准备子查询的处理逻辑过程。从查询处理过程来看,MySQL将子查询作为一个查询子单元(unit)来看,共用了union的查询逻辑处理过程。调用st_select_lex_unit::prepare()函数(sql\sql_union.cc:172),执行JOIN::prepare阶段,查询处理逻辑类似2.1测试,不同之处是group条件的处理过程,类似测试1.9。调用select_union::create_result_table()函数(sql\sql_union.cc:117)创建临时表,调用create_tmp_table()函数执行具体的创建过程。(sql\sql_derived.cc:135)
mysql_derived_filling():处理子查询优化和执行的处理逻辑。调用mysql_select()函数实际进行查询的处理逻辑,由于已经执行了prepare过程。因此,该过程主要处理JOIN::optimize阶段,优化过程的处理逻辑类似2.1测试,对group条件的处理过程(需要创建临时表,存储临时结果),类似测试1.9。处理JOIN::exec阶段,执行过程的处理逻辑类似2.1测试,不同之处在于查询结果存储到prepare阶段创建的临时表中。(sql\sql_derived.cc:264)
mysql_derived_cleanup():清理子查询使用的资源。调用st_select_lex_unit::cleanup()函数进行具体的清理工作。(sql\sql_derived.cc:321)
handle_select():主查询过程的实际处理逻辑,查询处理过程类似2.1测试多表联合查询处理方式,不同之处是联合查询四个表,其中tmp为子查询处理过程中得到的临时表。
子查询,执行SQL:
SELECT student.std_id, std_name, student.std_spec, std_***, std_age, SUM(cur_credit) total FROM student, course, std_cur, (SELECT std_spec, AVG(score) savg FROM student LEFT JOIN std_cur ON (student.std_id = std_cur.std_id) GROUP BY std_spec) tmp WHERE student.std_id = std_cur.std_id AND course.cur_id = std_cur.cur_id AND student.std_spec = tmp.std_spec AND score > tmp.savg GROUP BY std_id ORDER BY total;
对应的查询计划如下所示:
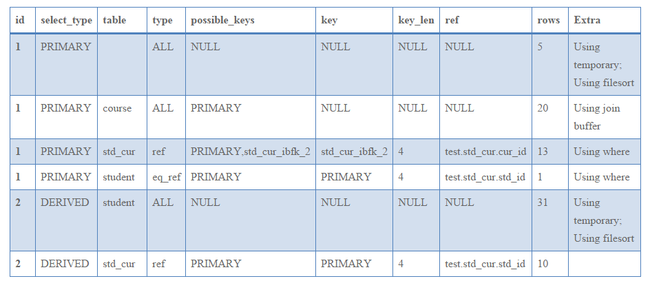
从以上查询处理逻辑来看,子查询的处理逻辑与之前的处理有所不同,其入口函数的层次有所提升,并且处理的流程也发生了变化。对子查询来说,首先根据查询条件和查询的表获得子查询语句中的结果集,该过程的查询处理作为union中的一个单元来处理。处理逻辑与单独的查询处理过程类似,最后将查询的结果集存储到临时表中。然后执行多表联合查询,获得最终的查询结果。
从查询计划来看,特别之处是select_type的值为PRIMARY和DERIVED,其中PRIMARY表示为最外的查询;DERIVED表示驱动表查询,依赖于外部的查询。因此,select_type为DERIVED的是查询获取驱动表的查询计划,select_type为PRIMARY的是主查询的查询计划。