YARN到底是怎么一回事?
文章思路:
首先提出第一代MRv1的局限性,然后解释YARN是怎么克服这些局限性的,接着说了YARN的编程模型,说了YARN的组成,YARN的通信协议和YARN的运行过程。通过这样的描述来认识YARN的。
MRv1的局限性
YARN是在MRv1的基础上演化而来,它克服了MRv1的各种局限性:
1:扩展性差
MRv1中,Jobracker同事兼备了资源管理和作业控制两个功能。
2:可靠性差
MRv1才用了master/slave结构,master存在单点故障的问题。
3:资源利用率低
MRv1采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源划分单位,通常一个
任务不会用完槽位对应的资源,且其他任务无法使用这些空闲的资源。
4:无法支持多种计算框架。
不能支持新的计算框架:包括内存计算框架,流式计算框架和迭代式计算框架。
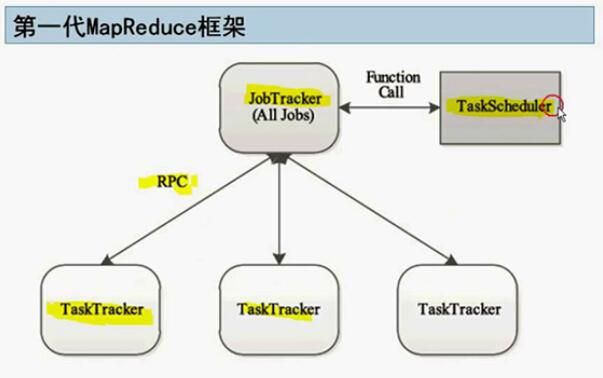
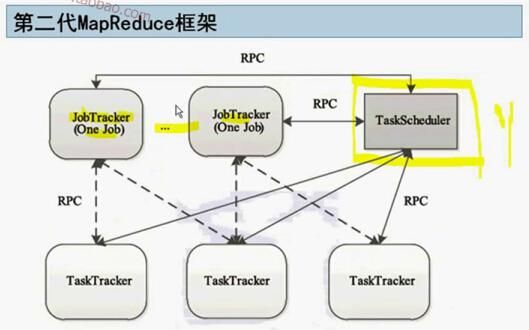
第二代的mapreduce框架的TaskScheduler就是yarn
YARN的编程模型
1:保证编程模型的向下兼容性,MRv2重用了MRv1的编程模型和数据处理引擎,但运行环境被重写。
2:编程模型与数据处理引擎
mapreduce应用程序编程接口有两套:新的API(mapred)和旧的API(mapreduce)
采用MRv1旧的API编写的程序可直接运行在MRv2上
采用MRv1新的API编写的程序需要使用MRv2编程库重新编译并修改不兼容的参数 和返回值
3:运行时环境
MRv1:Jobracker和Tasktracker
MRv2:YARN和ApplicationMaster
YARN的组成
yarn主要由ResourceManager,NodeManager,ApplicationMaster和Container等几个组件组成。
ResourceManager(RM)
RM是全局资源管理器,负责整个系统的资源管理和分配。
主要由两个组件组成:调度器和应用 程序管理器(ASM)
调度器
调度器根据容量,队列等限制条件,将系统中的资源分配给各个正在运行的应用程序
不负责具体应用程序的相关工作,比如监控或跟踪状态
不负责重新启动失败任务
资源分配单位用“资源容器”resource Container表示
Container是一个动态资源分配单位,它将内存,CPU,磁盘,网络等资源封装在一起,从而限定每个任务的资源量
调度器是一个可插拔的组件,用户可以自行设计
YARN提供了多种直接可用的调度器,比如fair Scheduler和Capacity Scheduler等。
应用程序管理器
负责管理整个系统中所有应用程序
ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM
AM的主要功能
与RM调度器协商以获取资源(用Container表示)
将得到的任务进一步分配给内部的任务
与NM通信以自动/停止任务
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
当前YARN自带了两个AM实现
一个用于演示AM编写方法的实例程序distributedshell
一个用于Mapreduce程序---MRAppMaster
其他的计算框架对应的AM正在开发中,比如spark等。
Nodemanager(NM)和Container
NM是每个节点上的资源和任务管理器
定时向RM汇报本节点上的资源使用情况和各个Container的运行状态
接收并处理来自AM的Container启动/停止等各种要求
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源
YARN会为每个任务分配一个Container,且改任务只能使用该Container中描述的资源
Container不同于MRv1的slot,它是一个动态资源划分单位,是根据应用程序的需求动态产生的
yarn的通信协议
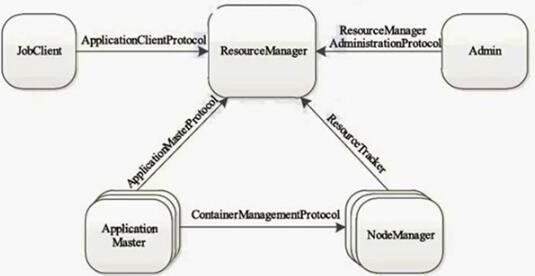
YARN主要由以下几个协议组成
ApplicationClientProtocol
Jobclient通过该RPC协议提交应用才程序,查询应用程序状态等
ResourceManagerAdministrationProtocol
Admin通过该协议更新系统配置文件,比如节点黑名单,用户队列权限等。
ApplicationMasterProtocol
AM通过该RPC协议想RM注册和撤销自己,并为各个任务申请资源
ContainerManagementProtocol
AM通过要求NM启动或者停止Container,获取各个Container的使用状态等信息
ResourceTracker
NM通过该RPC协议向RM注册,并定时发送心跳信息汇报当前节点的资源使用情况和Container运行状况
YARN的工作流程
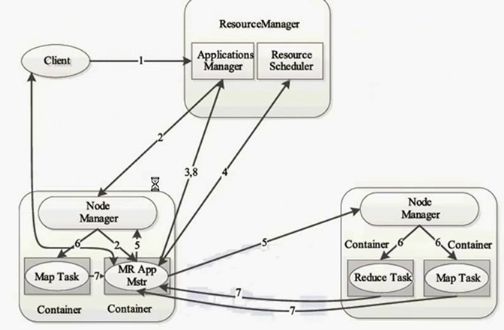
文字描述一下这个过程:
1:由客户端提交一个应用,由RM的ASM接受应用请求
提交过来的应用程序包括哪些内容:
a:ApplicationMaster
b:启动Applicationmaster的命令
c:本身应用程序的内容
2:提交了三部分内容给RM,然后RM找NodeManager,然后
Nodemanager就启用Applicationmaster,并分配Container
接下来我们就要执行这个任务了,
3:但是执行任务需要资源,所以我们得向RM的ASM申请执行任务的资源(它会在RM这儿注册一下,说我已经启动了,注册了以后就可以通过RM的来管理,我们用户也可以通过RM的web客户端来监控任务的状态)ASM只是负责APplicationMaster的启用
4::我们注册好了后,得申请资源,申请资源是通过第四步,向ResourceScheduler申请的
5:申请并领取资源后,它会找Nodemanager,告诉他我应经申请到了,然后Nodemanager判断一下,
6:知道他申请到了以后就会启动任务,当前启动之前会准备好环境,
7:任务启动以后会跟APplicationmaster进行通信,不断的心跳进行任务的汇报。
8:完成以后会给RM进行汇报,让RSM撤销注册。然后RSM就会回收资源。当然了,我们是分布式的,所以我们不会只跟自己的Nodemanager通信。也会跟其他的节点通信。