【Windows编程】系列第四篇:使用Unicode编程

上一篇我们学习了Windows编程的文本及字体输出,在以上几篇的实例中也出现了一些带有“TEXT”的Windows宏定义,有朋友留言想了解一些ANSI和Unicode编程方面的内容,本章就来了解和学习一些Windows下关于ANSI和Unicode方面的编程基础。
计算机最早在美国诞生,所以最开始都是以英语为作为交互语言,由于只有26个字母,用一个字节(范围-128 ~ 127)表示,这个范围足够表示26个因为字符和一些常用的控制字符,这个就是ASCII编码。因此最早的各种程序设计语言以及使用的字符串都用字节数组表示,也确实满足了编程的各种需求。但是随着计算机的普及,范围上逐渐超出了英语使用的国家,这样一来,字符编码就成了问题,因为很多国家的语言字符数目根本不能用一个字节来表示,比如我们国家的中文,常用的就有四千多个,如果再加上一些不常用的字符,更是远远不止这些,因此一个字节的字符串编码就行不通了,那么自然而然就出现了两个字节甚至跟多字节的编码方式了。
除了基本的ASCII编码外,目前常用的字符编码有MBCS、BG2312、GBK、UTF-8、UTF-16、 UTF-32、BIG5、Base64、Unicode等等,其实Unicode就是使用UTF-16编码。现在的所有系统都支持多字节编码,Windows98以前的对Unicode支持不好,很多内核函数都需要将字符串转换之后才能处理,从Windows NT系统后几乎都采用了Unicode编码重新系统内核,非Unicode的编码会经过转换之后在传入内核处理。
在C语言诞生的时候,同样还没有遇到多字节字符串问题,当然也没有Unicode等这些编码,标准的C语言库函数处理字符串时都是ASCII编码,因此用标C函数处理多字节字符编码就存在问题,所以不同系统都在内部进行这种字符编码的处理。那么问题来了,既然标C不支持Unicode,我们又如何编程使用Unicode呢?我们如何指定程序中的字符串采用ASCII还是Unicode或者两种同时出现在一个程序里面呢? 更好的情况,我们如何编写程序,根据自己的需求编译ASCII和Unicode(以下称宽字符)版本?本文我们就来谈谈这个问题。在微软公司提供的C/C++编译器中提供了一个wchar_t的变量类型,这个类型实际上是通过typedef定义的一个无符号16位整型数。我们使用这个来定义宽字符版本的字符和字符串,而普通的ANSI还是标准C语言的char来定义。
宽字符串的使用
下面我们对比一下ASCII和Unicode字符(串)的定义及常量的定义方式。
ASCII版本:
Char c = ‘A’; Char str[] = “hello, world”;
宽字符版本:
wchar_t wch = L’A’; wchar_t wstr[] = L“hello, world”;
微软的编译器通过这个大写字母“L”开头来识别后面的字符串将编译为一个Unicode的字符或字符串,注意这里的L后面不能有空格。
看下面的实例:
#include <windows.h>
#include <stdio.h>
int main(void)
{
char c = 'A';
char str[] = "hello, ANSI";
wchar_t wch = L'A';
wchar_t wstr[] = L"hello, Unicode";
printf("1 --> %c\n", c);
printf("2 --> %s\n", str);
printf("3 --> %c\n", wch);
printf("4 --> %s\n", wstr);
printf("5 --> %C\n", c);
printf("6 --> %S\n", wstr);
wprintf(L"7 --> %c\n", wch);
wprintf(L"8 --> %s\n\n", wstr);
system("pause");
return 0;
}
这个小程序的输出如下:
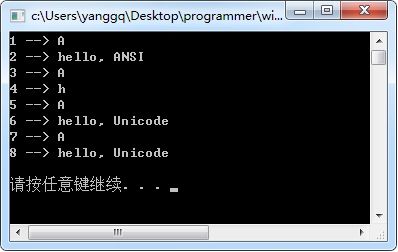
可以看出:
用printf可以输出ANSI的字符和字符串(废话)
用wprintf可以输出Unicode字符和字符串
printf可以用大写的字母C、S,即“%C”“%S”来输出宽字符和字符串
可以看出第3和第4用printf可以输出宽字符,但宽字符串仅仅输出了字符串的第一个字符,实际上这个就是问题了,不能这样输出,第3的字符A实际上完全是运气好,因为Unicode是双字节,所以宽字符”A”实际在是十六进制的“00 41”,而Windows系统是一个小端系统,所以在内存中的排版为“41 00 ……”,所以第一个刚好输出A。而第4只能输出一个“h”,也是因为这个原因。字符串wstr在内存的存在形式如下如:
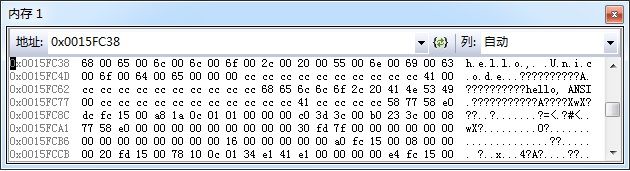
第一个字符是“h”,它的宽字符在内存排布(小端系统)为”68 00 …”,根据C语言规则,字符串以空字符0x00为结束符,因此使用printf和%s来输出时,系统并不知道这个h是一个宽字符,而是以此向后一直到空字符,这里刚好第二个就碰上了,因此只能输出一个“h”。
同样,scanf函数也是如此:
scanf("%s", str); //这个是C语言的正常用法
scanf("%s", wstr); //这个是可以工作的,但是接收结果是ANSI格式的字符串
scanf("%S", wstr); //这个可以正确接收宽字符格式的字符串
wscanf(L"%s", wstr); //这个是标准的接收宽字符格式字符串
以上的printf和scanf用%S来处理宽字符的方式是微软扩展的,不一定其他编译系统也能这样处理。
Unicode字符串支持函数
从上面我们看出,微软的编译器对宽字符及宽字符串常量用一个大写的“L”作为前缀来高手编译,后面的字符串作为Unicode版本而不是ANSI版本。另外printf和scanf也有对于的宽字符版本函数wprintf和wscanf来处理,从MSDN我们知道,所有关于字符/字符串都有两个版本,比如_wfopen、_getws、wcslen、wcscpy、wcscat等就是标准C函数fopen、gets、strlen、strcpy、strcat的宽字符版本。除了这些标C的宽字符函数外,Windows的API同样有ANSI和Unicode版本,比如创建窗体和空间的CreateWindowA、CreateProcessA等就是ANSI版本,而对应的CreateWindowW、CreateProcessW就是Unicode版本,他们处理的字符串类型都必须是wchar_t的字符串。
在一个程序里面,我们可以使用ANSI版本的函数来处理对应的字符串,同时也可以使用Unicode版本的函数来处理wchar_t的字符串,正如上面的实例一样,但必须对应,否则可能出现编译错误,更麻烦的是有可能编译通过但是结果却不是我们想要的,如上面的第4一条输出。
当然如果不是需要,最好不要在程序里面一会儿使用ANSI,一会使用Unicode,这样对将来的移植性兼容性很差,也不利于多语种和国际化。强烈建议使用Unicode版本来编写程序,这个是一个大趋势,如果你要把PC平台的Windows程序移植到微软的嵌入式平台Win CE上的话,就必须是Unicode。微软为了简化和通用性,在Win CE平台上只支持Unicode。而且使用Unicode编码时运行效率更高,因为现在的Windows操作系统内核全部都是用Unicode版本,如果上面传入一个ANSI的,它必须先转换成Unicode字符串,再传入内部的函数处理。
同时支持两种编码
当然理想情况是如果编写统一的应用程序,在编译时想编译成ANSI就编译成ANSI版本,想编译成Unicode版本就编译成Unicode版本是最好的,这样我们写出来的程序不管是移植性还是通用性都最好,其实这个微软早就想到了。
微软针对标准C函数构造了一套平台相关的字符串处理宏定义,所谓平台相关就是说这些宏是微软自己定义的,只是在Windows平台下使用,不是标准里面的东西。这些定义在不同的情况下会变成不同的版本。如果定义了“_UNICODE”这个宏定义,Windows将在处理C/C++函数是采用Unicode版本,否则就是ANSI版本。下面我们以strlen这个函数来看一下Windows是怎么定义的:
#ifdef _UNICODE #define _tcslen wcslen #else #define _tcslen strlen #endif
这里的_tcslen就是那个平台相关的求字符串的字符长度的宏定义,当然我们在使用的时候把他看成函数就行了,可以看到如果定义了_UNICODE,那么_tcslen在编译时实际是链接的wcslen,否则链接strlen。现在我们打开VS下面的头文件“tchar.h”,就可以看到很多以下划线开头的宏定义,这些都是平台相关的通用字符串处理库函数:
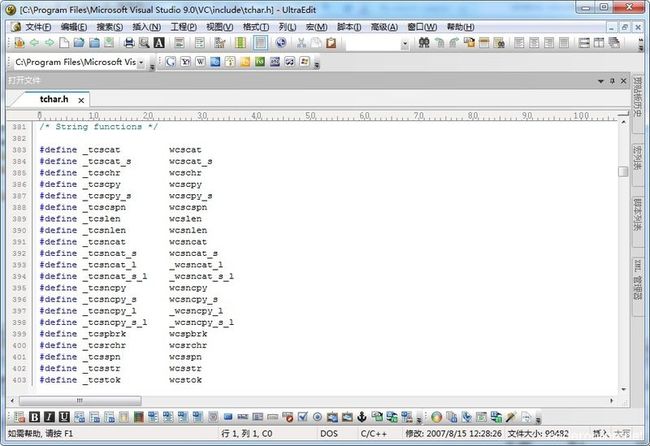
所以使用这些函数的时候要包含这个头文件。
另外,如果定义了“UNCODE”这个宏,Windows的API也会采用Unicode版本,否则采用ANSI版本。比如CreateWindow这个函数定义如下:
#ifdef UNICODE #define CreateWindow CreateWindowW #else #define CreateWindow CreateWindowA #endif // !UNICODE
所以实际上CreateWindow是一个宏定义而已,但是这不影响我们把它当做函数来使用,同样其他含有字符串作为参数的Windows API也同样做了定义。
默认情况下,我们使用VS来建立工程,_UNICODE和UNICODE这两个宏都是打开的,所以我们用向导创建的工程都是Unicode版本的,我们也可以从配置选项里面删除这两个定义来编译ANSI版本的程序。
现在函数的使用解决了,那么如何来定义字符以及字符串的变量类型已经常量,使得_UNICODE和UNICODE定义也能影响类型和常量呢?微软同样使用了一系列的定义来解决这个问题。TCHAR是作为字符、字符串的变量类型,等价于char和wchar_t,如果定义了UNICDOE,TCHAR实际上是wchar_t,否则就是char,这个在winnt.h中能找到。
对字符串常量,VS定义了TEXT、__TEXT,在tchar.h中,还定义了_T等好几种方式,只要定义了UNICODE,则这些宏定义就是Unicode,否则就是ANSI版本。因此我们以后在编写程序时,应该充分用这些宏来定义字符串类型变量,常量以及处理函数。下面是一个推荐的简单实例:
#include <windows.h>
#include <tchar.h>
int _tmain(void)
{
TCHAR c = TEXT('A');
TCHAR buf[16];
TCHAR *str = TEXT("hello, world!");
_tprintf(TEXT("1 --> %c\n"), c);
_tprintf(TEXT("2 --> %s\n"), str);
_tscanf(_T("%s"), buf);
_tprintf(_T("%s\n"), buf);
_tsystem(TEXT("pause"));
return 0;
}
在这个实例中,所有可能用到字符串的函数都采用通用的函数,能正确的编译Unicode版本和ANSI版本。
Unicode和ANSI字符串转换
有时候我们可能还是会出现不同编码之间的转换,这是我们可以采用Windows提供的API来完成。
MultiByteToWideChar函数和WideCharToMultiByte函数,这两个函数可以在ANSI和Unicode字符串之间来回转换。他们的参数有很多相似之处,原型为:
int MultiByteToWideChar(UINT CodePage, DWORD dwFlags, LPCSTR lpMultiByteStr, int cbMultiByte, LPWSTR lpWideCharStr, int cchWideChar); int WideCharToMultiByte(UINT CodePage, DWORD dwFlags, LPCWSTR lpWideCharStr, int cchWideChar, LPSTR lpMultiByteStr, int cbMultiByte, LPCSTR lpDefaultChar, LPBOOL lpUsedDefaultChar);
具体用法可以参考MSDN,网上也能找到大量的使用说明和实例,这里就不再叙述。
下面给一个实例来演示ANSI和Unicode之间的转换:
#include <windows.h>
#include <tchar.h>
#include <stdio.h>
int _tmain(void)
{
int nwCh;
char AnsiStr[] = "hello, world!";
wchar_t wszBuf[20] = {0};
//获得转换后产生多少Unicode字符,可以作为后面实际转换时传入容纳转换结果的Unicode字符数buffer大小
nwCh = MultiByteToWideChar(CP_ACP, 0, AnsiStr, -1, NULL, 0);
//转换并接收结果
MultiByteToWideChar(CP_ACP, 0, AnsiStr, -1, wszBuf, nwCh);
wprintf(L"nwCh = %d, %s\n", nwCh, wszBuf);
int nCh;
char AnsiBuf[20] = {0};
//获得转换后产生多少ANSI字符,可以作为后面实际转换时传入容纳转换结果的ANSI字符数buffer大小
nCh = WideCharToMultiByte(CP_ACP, 0, wszBuf, -1, NULL, 0, NULL, NULL);
//转换并接收结果
WideCharToMultiByte(CP_ACP, 0, wszBuf, -1, AnsiBuf, nCh, NULL, NULL);
printf("nCh = %d, %s\n", nCh, AnsiBuf);
_tsystem(TEXT("pause"));
return 0;
}
请注意注释部分,该函数及可以转换,也能获取转后所需输出的存储字符个数空间的大小。运行后的输出结果:
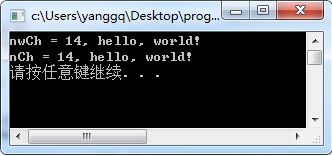
到这里本文就结束了,下一篇将继续我们的Windows编程系列之旅。敬请关注!
更多经验交流可以加入Windows编程讨论QQ群:454398517。
关注微信公众平台:程序员互动联盟(coder_online),你可以第一时间获取原创技术文章,和(java/C/C++/Android/Windows/Linux)技术大牛做朋友,在线交流编程经验,获取编程基础知识,解决编程问题。程序员互动联盟,开发人员自己的家。

转载请注明出处,谢谢合作!