数据库性能优化方案
不论MSYQL过程如何,最后都要到磁盘上去读这个“文件”(记录存储区等效),所以当然这一切的前提是只读 内容,无关任何排序或查找操作。所以,读写任何类型的数据都没有直接操作文件来的快。
判断方法:
1、如果信息的及时性要求不高 可以加入缓存来减少频繁读写数据库。
2、一次读取的内容越大,直接读文件的优势会越明显
3、写文件和INSERT几乎不用测试就可以推测出,数据库效率只会更差。
4、很小的配置文件如果不需要使用到数据库特性,更加适合放到独立文件里存取,无需单独创建数据表或记录,很大的文件比如图片、音乐等采用文件存储更为方便,只把路径或缩略图等索引信息放到数据库里更合理一些。
1、读写分离
随着业务的发展,我们的数据量和访问量都在增长。对于大型网站来说,有不少业务是读多写少的,这个状况也会直接反应到数据库上。那么对于这样的情况,我们可以考虑使用读写分离的方式。
这个结构的变化会带来两个问题:
1、数据复制问题。
2、应用对于数据源的选择问题。
我们希望通过读库来分担主库上读的压力,那么首先就需要解决数据怎么复制到读库的问题。数据库系统一般都提供了数据复制的功能,我们可以直接使用数据库系统的自身机制。但对于数据复制,我们还需要考虑数据复制时延问题,以及复制过程中数据的源和目标之间的映射关系及过滤条件的支持问题。数据复制延迟带来的就是短期的数据不一致。例如我们修改了用户信息,在这个信息还没有复制到读库时(因为延迟),我们从读库上读出来的信息就不是最新的,如果把这个信息给进行修改的人看,就会让他觉得没有修改成功。
对于应用来说,增加一个读库对结构变化有一个影响,即我们的应用需要根据不同情况来选择不同的数据库源。写操作要走主库,事务中的读也要走主库,而我们也要考虑到备库数据相对于主库数据的延迟。就是说即便是不在事务中的读,考虑到备库的数据延迟,不同业务下的选择也会有差异。
提到读写分离,我们更多地是想到数据库层面。事实上,广义的读写分离可以扩展到更多的场景。我们看一下读写分离的特点。简单来说就是在原有读写设施的基础上增加了读“库”,更合适的说法应该是增加了读“源”,因为它不一定是数据库,而只是提供读服务的,分担原来的读写库中读的压力。因为我们增加的是一个读“源”,所以需要解决向这个“源”复制数据的问题。
在这儿顺便说一下搜索引擎。
以我们所举的交易网站为例,商品存储在数据库中,我们需要实现让用户查找商品的功能,尤其是根据商品的标题来查找的功能。对于这样的情况,可能有读者会想到数据库中的like功能,这确实是一种实现方式,不过这种方式的代价也很大。还可以使用搜索引擎的倒排表方式,它能够大大提升检索速度。不论是通过数据库还是搜索引擎,根据输入的内容找到符合条件的记录之后,如何对记录进行排序都是很重要的。
搜索引擎要工作,首要的一点是需要根据被搜索的数据来构建索引。随着被搜索数据的变化,索引也要进行改变。这里所说的索引可以理解为前面例子中读库的数据,只不过索引的是真实的数据而不是镜像关系。而引入了搜索引擎之后,我们的应用也需要知道什么数据应该走搜索,什么数据应该走数据库。构建搜索用的索引的过程就是一个数据复制的过程,只不过不是简单复制对应的数据。
搜索集群(Search Cluster)的使用方式和读库的使用方式是一样的。只是构建索引的过程基本都是需要我们自己来实现的。
总体来说,搜索引擎的技术解决了站内搜索时某些场景下读的问题,提供了更好的查询效率。并且我们看到的站内搜索的结构和使用读库是非常类似的,我们可以把搜索引擎当成一个读库。
2、擅用缓存
缓存(Cache Memory)位于与内存之间的临时存储器,它的容量比内存小但交换速度快。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内即将访问的,当调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。由此可见,在中加入缓存是一种高效的解决方案,这样整个内存储器(缓存+内存)就变成了既有缓存的高速度,又有内存的大容量的存储系统了。缓存对的性能影响很大,主要是因为CPU的数据交换顺序和CPU与缓存间的带宽引起的。 缓存是为了解决CPU速度和内存速度的速度差异问题。内存中被CPU访问最频繁的数据和指令被复制入CPU中的缓存,这样CPU就可以不经常到象“蜗牛”一样慢的内存中去取数据了,CPU只要到缓存中去取就行了,而缓存的速度要比内存快很多。 这里要特别指出的是: 1.因为缓存只是内存中少部分数据的复制品,所以CPU到缓存中寻找数据时,也会出现找不到的情况(因为这些数据没有从内存复制到缓存中去),这时CPU还是会到内存中去找数据,这样系统的速度就慢下来了,不过CPU会把这些数据复制到缓存中去,以便下一次不要再到内存中去取。 2..因为随着时间的变化,被访问得最频繁的数据不是一成不变的,也就是说,刚才还不频繁的数据,此时已经需要被频繁的访问,刚才还是最频繁的数据,现在又不频繁了,所以说缓存中的数据要经常按照一定的算法来更换,这样才能保证缓存中的数据是被访问最频繁的。
3、专库专用,数据垂直拆分
读写分离后,数据库又遇到瓶颈
垂直拆分的意思是把数据库中不同的业务数据拆分到不同的数据库中。结合现在的例子,就是把交易、商品、用户的数据分开,如图2-20所示。
这样的变化给我们带来的影响是什么呢?应用需要配置多个数据源,这就增加了所需的配置,不过带来的是每个数据库连接池的隔离。不同业务的数据从原来的一个数据库中拆分到了多个数据库中,那么就需要考虑如何处理原来单机中跨业务的事务。一种办法是使用分布式事务,其性能要明显低于之前的单机事务;而另一种办法就是去掉事务或者不去追求强事务支持,则原来在单库中可以使用的表关联的查询也就需要改变实现了。
对数据进行垂直拆分之后,解决了把所有业务数据放在一个数据库中的压力问题。并且也可以根据不同业务的特点进行更多优化。
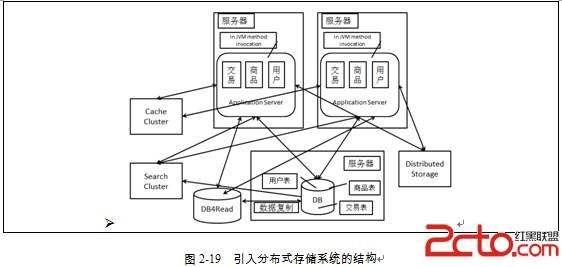
4、分布式存贮
常见的分布式存储系统有分布式文件系统、分布式Key-Value系统和分布式数据库。
4、1 文件系统是大家所熟知的,分布式文件系统就是在分布式环境中由多个节点组成的功能与单机文件系统 一样的文件系统,它是弱格式的,内容的格式需要使用者自己来组织;
4、2 而分布式Key-Value系统相对分布式文件系统会更加格式化一些;
4、3 分布式数据库则是最格式化的方式了。
分布式存储系统自身起到了存储的作用,也就是提供数据的读写支持。相对于读写分离中的读“源”,分布式存储系统更多的是直接代替了主库。是否引入分布式系统则需要根据具体场景来选择。分布式存储系统通过集群提供了一个高容量、高并发访问、数据冗余容灾的支持。具体到前文提到的三个常见类,则是
一、通过分布式文件系统来解决小文件和大文件的存储问题,
二、通过分布式Key-Value系统提供高性能的半结构化的支持,
三、通过分布式数据库提供一个支持大数据、高并发的数据库系统。
分布式存储系统可以帮助我们较好地解决大型网站中的大数据量和高并发访问的问题。引入分布式存储系统后,我们的系统大概会是图2-19的样子。