drools名词术语总结
1 规则引擎在j2se和j2ee的不同
使用Java规则引擎API
Java规则引擎API把和规则引擎的交互分为两类:管理活动和运行时活动。管理活动包括实例化规则引擎和装载规则。而运行时活动包括操作Working Memory和执行规则。如果你在J2SE环境中使用Java规则引擎,你可能需要在代码中执行以上所有的活动。相反,在J2EE环境中,Java规则引擎的管理活动是应用服务器的一部分
2 理解规则引擎
1) 规则引擎可以被看做具有推理能力的计算机程序,推理是基于事实和规则的,因此需要两个要件:事实的集合(事实可被看成由类的实例封装成),规则的集合。
2) 规则:在规则引擎中,一条规则由条件和结论两部分组成,可以理解为 if(条件1){结论1} 这样的代码。
3) 规则集:规则的集合。
4) 事实与规则的匹配以及冲突集,当一个事实满足某条规则的条件部分,就说这个事实与这条规则匹配。如某条规则是:如果有个人数学成绩60分以上的话,就给他奖学金;某个事实是:我。
现在看“我”是如何跟这个规则匹配的,因为“我”的数学成绩是75分,所以满足条件部分。“我”就满足“获得奖学金”这条规则。剩下就等发给我奖学金这个操作了,由于获得奖学金的实体不只我一个,成绩好的要先发,因此操作有个先后顺序,因此要把这个匹配项先存入冲突集中,判断先给谁发奖学金(也就是执行的先后顺序)。
5) 规则引擎运作原理:
S1 使用匹配算法如Rete算法从事实集中取出事实与规则匹配,如果发生匹配,则把这个匹配项存入冲突集。
S2 重复S1直到没有匹配项。否则停止匹配。
S3 执行冲突集。
3 开发过程常用的类
Drools最外层的类(接口)至少有KnowledgeBuilder,KnowledgeBuilderFactory, KnowledgeBase,KnowledgeBaseFactory, KnowledgeBuilderErrors(错误类先不管),KnowledgeRuntimeLogger,StatefulKnowledgeSession等。
大部分的外层的类(比如KnowledgeBuilder, KnowledgeBase)的实例的创建都是使用工厂模式来创建。
1 ) KnowledgeBuilder对象:
通过KnowledgeBuilderFactory 的newKnowledgeBuilder()创建.
KnowledgeBuilder 的作用就是用来在业务代码当中收集已经编写好的规则, 然后对这些规则文件进行编译, 最终产生一批编译好的规则包(KnowledgePackage)给其它的应用程序使用
KnowledgeBuilder kbuilder=KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl",
Test.class),ResourceType.DRL);
Collection<KnowledgePackage>
kpackage=kbuilder.getKnowledgePackages();//产生规则包的集合
在添加规则文件时,需要通过使用 ResourceType 的枚举值来指定规则文件的类型;同时在指定规则文件的时候drools 还提供了一个名为ResourceFactory 的对象,通过该对象可以实现从Classpath、URL、File、ByteArray、Reader 或诸如XLS 的二进制文件里添加载规则。
2 ) KnowledgeBase对象:
通过KnowledgeBaseFactory 对象提供的newKnowledgeBase()创建
KnowledgeBase 是 Drools 提供的用来收集应用当中知识(knowledge)定义的知识库对象,在一个KnowledgeBase 当中可以包含普通的规则(rule)、规则流(rule flow)、函数定义(function)、用户自定义对象(type model)等
KnowledgeBase 创建完成之后,接下来就可以将我们前面使用KnowledgeBuilder 生成的KnowledgePackage 的集合添加到KnowledgeBase 当中,以备使用:
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl",Test.class), ResourceType.DRL);
Collection<KnowledgePackage> kpackage =kbuilder.getKnowledgePackages();
KnowledgeBase kbase =KnowledgeBaseFactory.newKnowledgeBase();
kbase.addKnowledgePackages(kpackage);//将KnowledgePackage集合添加到KnowledgeBase当中
3 ) StatefulKnowledgeSessions对象:
通过KnowledgeBase 对象的newStatefulKnowledgeSession()方法创建
StatefulKnowledgeSession statefulKSession=kbase.newStatefulKnowledgeSession();
statefulKSession.setGlobal("globalTest", new Object());//设置一个global对象
statefulKSession.insert(new Object());//插入一个fact对象
statefulKSession.fireAllRules();
statefulKSession.dispose();
StatefulKnowledgeSession 对象是一种最常用的与规则引擎进行交互的方式,它可以与规则引擎建立一个持续的交互通道,在推理计算的过程当中可能会多次触发同一数据集。在用户的代码当中,最后使用完StatefulKnowledgeSession 对象之后,一定要调用其dispose()方法以释放相关内存资源。
StatefulKnowledgeSession 可以接受外部插入(insert)的业务数据——也叫fact,一个fact 对象通常是一个普通的Java 的POJO,一般它们会有若干个属性,每一个属性都会对应getter 和setter 方法,用来对外提供数据的设置与访问。一般来说,在Drools 规则引擎当中,fact 所承担的作用就是将规则当中要用到的业务数据从应用当中传入进来,对于规则当中产生的数据及状态的变化通常不用fact 传出。如果在规则当中需要有数据传出,那么可以通过在StatefulKnowledgeSession 当中设置global 对象来实现,一个global 对象也是一个普通的Java 对象,在向StatefulKnowledgeSession 当中设置global 对象时不用insert 方法而用setGlobal 方法实现。
4 Drools是如何工作
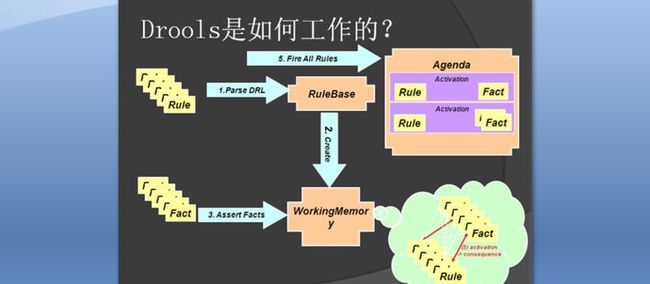
5 FACT对象
Fact 是指在Drools 规则应用当中,将一个普通的JavaBean 插入到规则的WorkingMemory当中后的对象。规则可以对Fact 对象进行任意的读写操作,当一个JavaBean 插入到WorkingMemory 当中变成Fact 之后,Fact 对象不是对原来的JavaBean 对象进行Clon,而是原来JavaBean 对象的引用。规则在进行计算的时候需要用到应用系统当中的数据,这些数据设置在Fact 对象当中,然后将其插入到规则的WorkingMemory 当中,这样在规则当中就可以通过对Fact 对象数据的读写,从而实现对应用数据的读写操作。一个Fact 对象通常是一个具有getter 和setter 方法的POJO 对象,通过这些getter 和setter 方法可以方便的实现对Fact 对象的读写操作,所以我们可以简单的把Fact 对象理解为规则与应用系统数据交互的桥梁或通道。
6 Rule
When
<conditions>
Then
<actions>
一个Rule由conditions和actions组成,当所有的conditions匹配,rule可以”fire”
Rule操纵应用程序里的Fact(数据)
7 典型actions
l 插入新的fact
l 修改已经存在的fact
l 撤销fact
l 为fact的字段赋值
l 为global赋值
l 进行GC
警告:使用java的时候。不要使用if/else,for/while loops或者其他类似的java逻辑
8 package
对一个规则文件而言,package是必须定义的,必须放在规则文件第一行。特别的是,package的名字是随意的,不必必须对应物理路径,跟java的package的概念不同,这里只是逻辑上的一种区分。同样的package下定义的function和query等可以直接使用。
9 import
导入规则文件需要使用到的外部变量,这里的使用方法跟java相同,但是不同于java的是,这里的import导入的不仅仅可以是一个类,也可以是这个类中的某一个可访问的静态方法。
10 rule
定义一个规则。rule "ruleName"。一个规则可以包含三个部分: 1)属性部分:定义当前规则执行的一些属性等,比如是否可被重复执行、过期时间、生效时间等。 2)条件部分,即LHS,定义当前规则的条件,如 when Message(); 判断当前workingMemory中是否存在Message对象。 3)结果部分,即RHS,这里可以写普通java代码,即当前规则条件满足后执行的操作,可以直接调用Fact对象的方法来操作应用。RHS部分除了调用Drools提供的api和Fact对象的方法,也可以调用规则文件中定义的方法,方法的定义使用 function 关键字。
11规则流ruleflow-group
在使用规则流的时候要用到ruleflow-group 属性,该属性的值为一个字符串,作用是用来将规则划分为一个个的组,然后在规则流当中通过使用ruleflow-group 属性的值,从而使用对应的规则。

注意:
[1]Split结点类型为OR,约束选择always strue.表示选择其规则组中所有符合事实的规则进行并发执行;
[2] Join结点类型为AND,表示当且进当上述规则组均执行完毕后,才执行后面的规则或进程。
Drools5.0 RuleFlow常见问题汇总:
1 编译drools rf文件时总是报异常,
kbuilder.add(ResourceFactory.newClassPathResource("salary.rf"), ResourceType.DRF);
…………………
…………………
Caused by: java.lang.IllegalArgumentException: Unable to instantiate 'org.jbpm.process.builder.ProcessBuilderFactoryServiceImpl'
…………………
…………………
少了两个jar包
jbpm-flow-5.4.0.Final.jar
jbpm-flow-builder-5.4.0.Final.jar
2 编辑rf文件 添加rule task节点 文件显示叉号 (未解决)
执行会抛java.lang.IllegalArgumentException:Unknown process ID :xxx
3 设计规则流
在properties视图里设置节点属性
通过select按钮可以修改节点的名称
12开发流程
运用DROOLS开发应用系统的流程:
1、整理系统的商业逻辑
2、从逻辑中抽象出规则依赖的事实(FACTS)
3、根据商业逻辑和事实编写(定制)规则
4、加载事实到事实库(Workingmemory)
5、加载规则到规则库(rulebase)
6、激活规则引擎匹配规则(fire)
1 ) 商业逻辑
DROOLS是用来处理系统中的商业逻辑的,在决定一个项目使用DROOLS开发后,就要着手整理这个系统中所包含的商业逻辑,可以借助excel建立系统商业逻辑的决策表,决策表包括系统逻辑中所有条件,及满足特定逻辑规则时采取的动作集合。
决策表的左边是逻辑的条件(可以有多个),决策表的最右边是当全部的左边条件成立时执行的动作(可以有多个)。决策表的每一行都是一条逻辑规则。
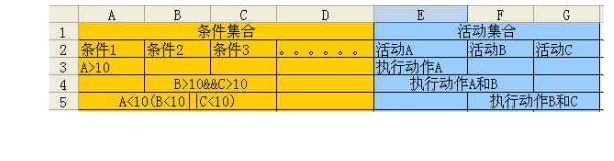
2 ) 第 2 节 抽象事实
从第一节中整理的商业逻辑的条件中抽象出DROOLS的事实类,所谓的事实类就是以条件中的变量为属性的标准的javabean类(每个属性都有get和set方法),事实必须包括全部的条件中的变量。可以根据需要抽象出一个或多个事实。