网络舆情分析系统的研究与设计
Quanlong Guan1, Saizhi Ye2, Guoxiang Yao2, Huanming Zhang1, Linfeng Wei2, Gazi Song2, Kejing He3
1中国广州 暨南大学 网络与教育科技中心
2中国广州 暨南大学 信息科学技术学院
3中国广州 华南理工大学 计算机科学与工程学院
摘要— 网络正在成为公众舆论的一个传播平台。及时地掌握网络舆情和恰当地了解他们的看法趋向是很重要的。文本分类在大量的信息管理和检索任务扮演一个根本角色。但是网页分类比纯文本分类困难在于网页中存在着大量的嘈杂信息。在本文,我们提出一种网络舆情(IPO)分析系统的方案。我们通过在摘要中应用网页分类法来提取网页中最为相关的内容,然后再将他们传递到标准文本分类算法(NB或SVM)中。我们全面地利用文本分类和文本聚类算法,证明了它们在单独使用时是高效率且有效的。根据实验结果,我们证明了系统结构在系统设计中的重要性。
关键词— 网络舆情;网页摘要;文本分类;向量空间模型;
Ⅰ. 介绍
现如今,人们越来越多地使用互联网与他人进行沟通,发表他/她们的关于某些话题的看法和表达他/她们的关于某些事的怨言(我们把所有这些相关的话题和人们的观点叫做网络舆情,简称IPO)。互联网可能会被攻击者或敌人用作破坏互联网稳定和威胁网络社会安全的工具[1]。然而,网络舆情可能会对真实世界的社会安全产生巨大的冲击[2]。当前对网络舆情的研究主要是研究它对真实世界的社会或政府的影响,并且从心理学或社会学的角度分析它的活动方式[3]。文本分类在大量的信息管理和检索任务扮演一个根本角色。但是网页分类比纯文本分类困难在于网页中存在着大量的嘈杂信息。网页是不同于一般的的文本文档集合。文本文档可以被认为是一个词语的汇集,而网页则含有附加的结构信息。
在本文,我们设法显示我们的网络舆情分析系统(IPOAS)的模型。 我们的主要工作如下:
1)参考各种各样的相关技术,我们提出一种改进的网络语请分析模型,它可以更加有效地处理和探求网络舆情的特征。
2)在这个系统中,有二个重要的核心模块:信息预处理模块和网络舆情语义分析模块。 我们分析了他们的实现方法。
3) 我们通过在摘要中应用网页分类法来提取网页中最为相关的内容,然后再将他们传递到标准文本分类算法(NB或SVM)中。根据实验结果,我们证明了系统结构在系统设计中的重要性。
本文的其他部分结构如下。在第2部分,我们将回顾有关网络舆情最新的工作成果和有关传统网络舆情分析方法的研究,然后将提出我们的IPOAS模型。我们的方法将在第3部分和第4部分详述。在第5部分,实验结果和一些相关的讨论将会被列出。最后,在第6部分,我们将总结我们的工作。
Ⅱ. 相关著作
网络舆情是一个宽泛的题目。从网络中获取情感倾向是一个困难的语义问题。与文本文档比较,网页有一些额外特点,例如HTML标签,URL,超链接和锚文本,他们都被证明在获取情感倾向时是有用的。最近许多有关利用这些特性进行情感倾向提取的网页摘要研究[4,5]都完成了。 Dou[4]指出用于在网页分类中预处理的网络摘要技术是一个可行的且有效的技术。证据显示考虑到上下文信息的摘要比仅仅从目标文档提取的内容相关性更强。同样,我们在摘要过程中利用网页分类去从网页中提取最相关的内容。我们系统的网络舆情信息预处理模块也使用了这些特点。 这个模块由二个方法构成:数学算法或神经网络和文本分类/聚类。
有许多根据数学算法中的方法构建的模块。网络公共会话的的增长使得网络通信成为了一个潜在的富有的数据来源。P.D. Turney[6]介绍了一种从庞大的语料库中对语义倾向进行无监督学习的简单算法。这种方法涉及了向搜索引擎进行请求和利用逐点交互信息来分析结果。 类似地,Peter Jorgensen[7]探索了竞争(IAC)的相互作用和人工神经网络(ANN)的使用来找到存在于电子邮件文本中的关系。最终,Pjianping Zeng[8]提出了隐马尔可夫模型(HMM)来描述网络舆情的活动。所有他们的研究最终形成了有关网络舆情活动过程的数学模型的整合,这一整合可以利用一定的数据进行自动的分析。
其他的研究使用了文本分类或聚类的方法。文本分类当前是信息搜索和数据挖掘领域研究的一个热门主题[9,10]。其在近年来有着迅速的发展,并在信息过滤,自然语言处理和信息的组织和管理方面有着广泛的应用。Pyanjun Li和Soon M.Chung [11]提出了二种新的文本聚类算法,名为根据频繁词序的聚类(CFWS)和根据频繁词意序列的聚类(CFWMS)。
Ⅲ. IPOAS模型概览
IPOAS模型采用了三层结构,分别是I/O层、服务处理层和数据层。图1显示了系统的具体结构。每层都可以被细分。每层的具体分解见图1。

图1. IPOAS模型
A. I/O层
1) 数据集:数据集与用户要求要收集的数据有关。它主要包括内部数据、网络数据和媒体数据。 互联网在日常生活中逐渐成为了公众交换信息的一个重要平台。例如BBS、博客、门户网站和政府网站等等信息平台可以作为对舆情进行监视和疏导的一个来源。
2) 前端应用模块:前端应用模块是网络舆情分析系统的输出程序。在大多数情况下,它提供适应用户需要的功能,包括有——热点查寻,关键词检索,自动摘要,主题词自动推荐,辅助收集功能等等。
B. 服务加工层数
1) 网络舆情信息收集模块:网络舆情信息收集模块用来定位网页资源和获取它的源代码。 当前基于网页链接的信息收集技术可以自动地获取基于的网页资源和源代码。因而收集覆盖面便可以通过链接遍及整个互联网。网络舆情监控系统可以根据用户提供的网络舆情关注点制定主体目标,然后利用手工干预和信息自动收集的联合方法完成信息收集的任务。对于那些被定位的网页资源,系统会判断这些资源是否被保存进了历史数据库。如果是并且两者相同,系统将忽略这样的资源并继续收集其他资源。相反,如果资源未被保存入数据库或保存过后被改变了,系统将使用网络爬虫技术收集这些信息然后保存这些数据到数据库中以便之后进行信息预处理工作。
2) 信息预处理模块:信息预处理模块的主要作用是通过使用诸如去杂、分词和分类等方法将从网页上收集的数据处理成格式化数据,然后将他们保存到数据库中。这个模块是网络舆情分析系统中的数据准备和技术准备阶段。预处理收集到的信息意味着转换网页格式并且过滤出网络舆情信息。对于新闻评论,这个模块需要过滤掉无关的信息并保留诸如新闻标题、来源、日期、内容、点击量、评论者、评论内容、评论数量等等信息。类似地,对于BBS,模块需要记录帖子的标题、发帖人、发帖日期和时间、内容、回复、回复的数量的标题,最后要产生格式化过的信息。
收集模块和信息预处理模块的数据交互是通过文件完成的。所以信息预处理模块可以直接将处理后的数据结果存放到数据库中。
3) 网络舆情语义分析模块:网络舆情语义分析模块进一步地从信息预处理模块生成的数据中挖掘数据。所运用的关键技术有热点发现的和跟踪,新事件发现,关联分析和趋势分析。 这一模块是整体系统的核心模块。它有着像网络舆情监视,热点跟踪和事件发现等等功能。
在系统实现过程中,网页信息分析方法基于向量空间模型,并且采用了成熟的的数据挖掘算法和技术,例如文本分类和文本聚类。与其他研究相比,这个系统的好处是它采用了灵活的方法对数据挖掘算法进行了整合应用,并且这些算法可以根据文本分析和数据挖掘的需要进行定制。可以确信,整体系统可以执行策略调整和优化以适应用户和应用的需要,因此系统可以在使用中达到它的设计水平。
4) 趋势分析模块:趋势分析模块用来分析公众对一个主题在不同的时期的关心程度。因而它可以提供网络舆情趋势的预测和预警服务来帮助决策者了解网络舆情的趋势和事先发现热点问题。
C.数据层
数据层主要负责保存物理数据到数据库中,这其中会用到有关算法、网络舆情收集、网络舆情特征向量、语义分析等方面的知识。
Ⅳ. 网络舆情信息预处理技术
网络舆情信息预处理模块是网络舆情分析系统中最重要信息处理的模块之一。这个模块将进一步处理从网络舆情信息收集模块传来的网页源代码。现今有许多信息预处理技术,例如网页摘要,网络文本组织法,网页净化,网页去重,文本分割,停用词和功能词删除和词频统计。在这个部分,我们考虑如何分析嵌在网页中的复杂隐晦的结构和如何使用这些信息进行网页摘要。我们的方法是从网页提取最相关的内容然后传递他们到一种标准文本分类算法中。
尤其是,我们将用页面布局分析法识别出的内容主体指导网页的摘要工作。
网页中结构化的字符使网页摘要与纯文本摘要不同。这项任务的难点在于在网页中数量众多的“嘈杂”成分,例如导航条、广告和版权信息。为了运用网页的结构信息,我们使用了如[12]所描述的基于功能的对象模型(FOM)的一个简化版本。
简言之,FOM试图通过辨认对象的作用和类别来了解作者的意图。在FOM中,对象被分类成一个作为最小的信息体并不可进一步被划分的基本的对象(BO),或者是一个组合对象(CO)。组合对象是对象(BO或CO)的集合,而这些对象可以同时发挥某些作用。BO的一个例子是jpeg文件。在HTML内容中,BO是一个在两个标签或一个内嵌对象中的不可分的元素。在BO的内容的里面没有其他标记。根据这个标准,我们可以容易地在网页里找出所有的BO。同样,CO可以被网页布局分析所查出。基本思想是在同一个类别的对象通常有一致的视觉样式,以便他们可以从其他类别对象中由明显的可见边界分离,例如表格边界。在查出网页中的所有的BO和CO后,我们可以根据一些启发式规则辨认每个对象类别。 这些规则的详细例子在[15]中被展示;这里我们仅提供概要。首先,对象类别包括:
1)信息对象:这个对象表示内容信息。
2)导航对象:这个对象提供导航指南。
3)互动对象:这个对象提供用户端互动。
4)装饰对象:这个对象起装饰作用。
5)特殊功能对象:这个对象执行特殊功能例如广告、商标、联系方式、版权、参考等等。
为了利用这些对象,从上述的对象类型中,我们定义了一个网页中包含与该页主题有关的主要对象的内容体(CB);这些是表达关于网页重要信息的对象。找出CB的算法如下:
1. 把每个被选择的对象当作一个单一文档并且为对象建立的TF*IDF索引。
2. 利用余弦相似度算法计算任意两个对象的相似度,如果相似度大于某个阈值,就增加一个这两个对象间的链接。阈值需要根据经验进行选择。在处理完所有对象对之后,我们将得到一张连接不同的对象的关联图。
3. 在图表中,拥有最多边缘的对象被定义为核心对象。
4. 提取CB作为与核心对象相连接的所有对象的组合。
最后,我们将分配CB值S到每个句子。如果句子包括在“内容体”中,则Scb= 1.0;否则, Scb= 0.0。最后,所有Scb等于1.0的句子将用来进行我们所谈到的的网页摘要。
Ⅴ. 网络舆情信息的语义分析(IPOISA)
IPOISA是系统的核心技术,主要用来检测和追踪热点。由它来确定网络舆情(IPO)信息的准确性。系统运用文本分类和文本聚类的算法来实施语义分析和处理被预处理过的内容,以便建立由索引信息组成的分析数据库。
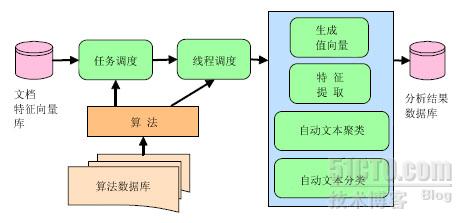
图2. 网络舆情信息的语义分析
图2显示的是IPOISA的结构。 IPOISA包括文档特征据库、算法库和分析结果数据库。 文档特征数据库是在预处理网络舆情(IPO)信息以后生成的知识数据库。分析结果数据库保存IPOISA的结果。 IPOISA的主要功能是算法库,算法调度和线程操作:
A. 算法库
算法库包括一些可以动态地被扩展和增加的配置文件。算法库可以为每一种类型的执行线程生成特定的算法,并被算法调度程序所使用。系统根据系统管理员的需求保存关于算法策略的配置信息到算法库中。
B. 算法调度
算法调度负责分配多线程的执行和管理任务,即IPOISA的引擎。算法调度用来调度不同的算法和处理次序来分类或聚类本文的特征向量,并且控制线程的运行。系统掌管和控制每个用户的不同进程,这意味着他可以在同一时间处理一个用户的不同进程。例如,由系统提供的基本的处理方法是热点事件的探测和用户感兴趣的事件的追逐,然后系统可以同时为用户A创造两个进程—热点探测进程“A_Detection”和事件跟踪进程的“A_Tracking”,用这两个进程来分析和处理来自多方面的信息。
C. 线程处理
每个处理线程都是文本分类或聚类之一的过程,包含值向量的生成、特征选择或者特征提取、文本分类或聚类。算法库确定每个线程的每个部分的算法。线程根据预编程序时间频率和处理策略从文档特征向量库中读取需要的内容,并且进行进一步的分析和处理,其结果将被保存入结果数据库。最后,用户可以在结果数据库中进行查询,所需要的结果将以适当的形式呈现给用户。
Ⅵ. 实验
为了确定对网络分类和IPOAS的摘要效果,我们进行了几次实验。
A. 数据集
实验数据集由我们自己的语科库和北京大学中文网页训练集CCT2006组成。它包含8个类别和6000个句子,其中有4000个被用作训练集合而其他的则用作测试。共有四个类别,包括教育、商业、计算机和互联网、新闻和媒体,被选中用来分析结果。
B. 分类器
因为本文的焦点是确定对网络分类和IPOAS的摘要效果,在实验中我们选择了两个流行的分类器。 一个是原生贝叶斯分类器,另一个是支持向量机。
1) 原生贝叶斯分类器(NB)
原生贝叶斯分类器(NB)是在实践中被证明很好使用的一种简单但有效的文本分类算法。NB的基本思想是使用词汇和分类的联合概率来估算一篇给定文档所在分类的概率。多数研究者通过运用贝叶斯规则使用NB方法:

当P(Cj|θ)可以通过计数在训练数据出现的每个类别Cj的频率来计算;|C| 是类别的数量;p(wi|cj)代表词wi可能在分类cj出现的概率在可能小在训练数据,这种概率在训练数据中可能会较小,因此拉普拉斯过滤被用来估算它;N(wk,di)是单词wk出现在di中的次数;n是单词在训练数据中的数量。
2) 支持向量机(SVM)
支持向量机(SVM)是V.Vapnik最近介绍的一个强有力的学习方法。它是建立在计算型学习理论之上的,而且已被成功地用于文本分类。
SVM通过在可能的输入空间内发现超曲面来运作。超曲面试图通过最大化最近的距离的正负面例子来从负面例子中分裂正面例子到超曲面。直观地,这使为那些与训练数据很近但又不相同测验数据分类正确。有各种各样的方式训练SVM。一个特别简单和快速的方法是由J.Platt开发的序列最小最优化(SMO)。他的序列最小最优化算法将二次规划(QP)问题分解为一系列小的QP问题来进行分析解决。因而SMO算法有效地适用于大型的特征和训练集。
3) 评估指标
我们使用标准指标来评估网页分类的效果,即精确度、召回率和F1-measure指标。要确定这些,我们必须首先来了解一篇文档的分类是否是真阳性(TP),假阳性(FP)或假阴性(FN) (参见表1)
表Ⅰ
一篇文档的分类
| TP |
决定于一篇文档是否根据其相关的分类被正确地分类。 |
| FP |
决定于一篇文档是否被说明错误地与分类关联。 |
| FN |
决定于一篇文档是否本应关联到一个分类却没有关联上。 |
精确度(P)是在系统返回的所有被预言的正面类成员之中的系统返回的实际正面类成员的比例。P=TP/(TP+FP)。召回率(R)是被预言的正面成员在数据中所有实际正面类成员之中所占的比例。R= TP/(TP+FN)。F1是精确度和召回率的调和平均数,如下所示:
F1 = 2* P *R/ (P + R)
C. 实验结果和分析
表Ⅱ
有关P、R和F1实验结果
|
|
|
Education |
News and Media |
Computer and Internet |
Business |
| P |
NB |
95.51 |
97.36 |
94.37 |
92.24 |
| SVM |
93.29 |
97.06 |
95.03 |
91.85 |
|
| R |
NB |
90.33 |
96.93 |
91.34 |
93.71 |
| SVM |
90.87 |
96.25 |
91.08 |
93.65 |
|
| F1 |
NB |
92.85 |
97.14 |
92.83 |
92.96 |
| SVM |
92.06 |
96.65 |
93.01 |
92.74 |
实验结果显示两种类型的成熟文本分类算法在被大量训练集训练后再次被聚类处理,精确率和召回率以及F1值大致相同。例如,两种算法的结果在新闻和媒体方面令人满意,然而NB在教育和商业类别中表现得要比SVM更好,而SVM比NB更擅长计算机和互联网类别。可见一个适用不同的种类的文本分类算法的通用平台由IPOAS建立。根据实际需要和用户需求,IPOAS可以通过满足不同算法的处理需求来运用更多更为有效的的算法。因此,这再次证明了IPOAS有良好的扩展性和多算法兼容性。
Ⅶ. 总结
以前,网络舆情分析系统只不过是舆情信息处理的其中一环,只是文本分类或文本聚类而已。这种应用在某种状况下经常被认为是差强人意的,例如,在用户想要在某个时期把新闻归类为教育、经济、文化、科学技术等等,并且想要查看每个类别中的热点事件时。很明显地,这些要求的实现需要首先对文本进行分类,再从前一阶段的结果中针对每个类别的文本进行聚类操作。
本文提出了一份网络舆情分析的系统计划。这个建模方法是可行且有效的。我们将文本分类和聚类算法巧妙地结合了起来,并证明了这种结合比仅使用它们其中的一个要更有效率、更有效果。我们通过应用网页摘要技术可以从网页中提取最相关的内容,然后把它们传递给一个标准的文本分类算法。通过实验的结果,我们证明了这一系统在系统结构和设计上的优越性。
致谢
这一成果是在CEEUSRO工程(No.2008B090500201)和广东省高校科学技术成果转化重点工程(No.cgzhzd0807)的支持下完成的。
参考文献
[1] M.W. David, K. Sakurai. Combating cyber terrorism: countering cyber terrorist advantages of surprise and anonymity. International Conference on Advanced Information Networking and Applications.pp.716-721,2003.
[2] N. Thanthry, M. S. Ali, R. Pendse. Security, Internet connectivity and aircraft data networks. International Carnahan Conference on Security Technology. pp.251-255, 2005.
[3] G.X. Zhang.Analysis on the inclination of group polarization from subject of public opinion in the cyber space. Journal of China Qingdao University of Science and Technology.21(4), pp.104-107, 2005.
[4] PDou Shen, PQiang Yang, PZheng Chen. Noise reduction through summarization for Web-page classification. Proceedings of Information Processing and Management: an International Journal v43 i 6.2007.
[5] D. Shen, Z. Chen, Q. Yang, H. J. Zeng, B. Zhang, Y. Lu, and W. Y. Ma, "Web-page classification through summarization", Proceedings of the 27th Annual International Conference on Research and Development in Information Retrieval (SIGIR'04), Sheffield, United Kingdom, July 25-29, 2004, pp. 242-249.
[6] P.D.Turney,M.L.Littman.Unsupervised learning of semantic orientation from a hundred-billion-word corpus.Technical Report ERB-1094,National Research Council Canada,Institute for Information Technology,2002.
[7] Peter Jorgensen. Incorporating context in text analysis by interactive activation with competition artificial neural networks.ACM,pp. 1081-1099,2005.
[8] Jianping Zeng,Shiyong Zhang,Chengrong Wu,Jianfeng Xie. Predictive Model for Internet Public Opinion. IEEE Vol.3,pp.7-11,2007.
[9] Guo-Xiang Yao ,Quan-Long Guan,Liang-Chao Lin, et al. “Research and implementation of next generration network intrusion detection system based on protocol analysis”..Proceedings-ISECS,CCCM 2008,vol 2, ,pp 353-357b,2008
[10] Shen. Y, Jiang. J. Improving the performance of Naive Bayes for text classification, CS224N spring. Technical report, Stanford University.2003.
[11] PYanjun Li,Soon M. Chung,John D. Holt. Text document clustering based on frequent word meaning sequences.ACM,pp.381-404,2008.
[12] Chen, J., Zhou, B., Shi, J., Zhang, H., and Wu, Q., Function-Based Object Model Towards Website Adaptation, In Proceedings of the 10th International World Wide Web Conference, 2001.