利用HTK工具包快速建立一个语音命令识别系统
摘要
体验过百度语音产品的你一定能感受到语音交互的魅力。在这里,我们以一个常用命令(打开、关闭、开始、停止)的语音识别任务为例,介绍一下如何利用HTK快速地建立这样一个语音命令识别系统,让电脑识别出你所说的简单命令。当然,如果要想识别任何其它的词,原理及过程也完全相同。
工具包介绍
HTK的全称是”Hidden Markov Model Toolkit”,是英国剑桥大学工程学院开发的隐马尔可夫模型(后面简称为隐马模型)工具包,可以方便有效的建立及操作隐马模型。隐马模型在许多人工智能领域都有着成功的应用,比如语音识别,当前国际上主流的语音识别系统仍是基于隐马模型建立的。HTK的开发也主要是针对语音识别的应用及研究。
HTK是一个开源工具包,可以在http://htk.eng.cam.ac.uk/进行免费下载,工具包中包含许许多多的模块及工具,都是用纯C代码写成的,基本都以H开头。其中也有非常详细的文档可供参考。
建立语音训练数据
首先我们需要录音以采集足够的语音数据,对于“打开、关闭、开始、停止”这四个命令都需要录一些相应的语音样本,同时也需要对录下的语音做一些简单的标注。录音和标注可以采用HTK工具包中的HSLab来完成。
比如在命令行下运行“HSLab打开.sig”,然后点击“Rec”健开始录音,点击“Stop”键录音结束。这时就会在当前目录下生成一个名为“打开_0.sig”文件,再进行一次录音则生成“打开_1.sig”,以此类推。默认的录音采样率为16kHz,我们采用默认的设置就可以了。
录音后需要对语音进行简单的标注,标注也是用HSLab工具,运行后按“Mark”键,选择需要标注的区域,按“Labelas”,输入标注的符号,然后回车确定即可。在本问的例子中,每个语音样本都是孤立的命令词,我们只需要标注出3个部分:起始静音部分(标记为sil),命令词语音部分(标记为命令词,如“打开”),结束静音部分(标记为sil)。标注完成,点击“Save”键保存,会生成一个后缀为“lab”的文件。
特征提取
语音识别系统并不直接在语音信号上进行识别,而是先要进行特征提取,包括分帧,加窗,求取频谱及倒谱,这样确保提取出的特征更加紧凑并尽可能多的保留语音内容的信息。
HTK中负责提取特征的是HCopy工具,它将wav格式的语音文件转化为包含若干特征
矢量的特征文件。具体命令如下:
HCopy –A –D –C hcopy.conf -S hcopy.scp
其中hcopy.conf是一个配置文件,用于对特征提取过程中的参数进行配置,如下所示:
hcopy.scp为待处理语音源文件与特征目标文件对的列表,格式如下:

隐马模型结构定义
在本文的例子中,有五个需要建模的声音单元:“打开”,“关闭”,“开始”,“停止”,“sil”。对于每一个声音单元都将采用一个对应的隐马模型来建模。需要确定的隐马模型结构参数包括:
1.状态个数
2.每个状态的输出函数形式
3.状态间的跳转关系
在本例中我们采用最常用的结构配置,如下所示:
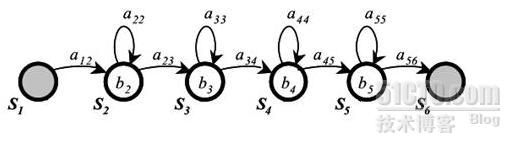
模型包括4个有输出的状态{S2,S3,S4,S5},第一个和最后一个状态{S1,S6}不产生输出,只是为了操作方便。每个状态的输出函数b采 用对角方差阵的混合高斯分布函数来描述。
隐马模型训练
 1. 模型初始化
1. 模型初始化
在训练开始必须对模型参数进行初始化,初始化是会影响训练的收敛速度与准确性。HTK提供了两种初始化工具:HInit和HCompv.
(1) 采用HInit初始化
HInit -A -D -T 1 -S trainlist.txt -M model/hmm0 \
-H model/proto/hmmfile -l label -L label_dir nameofhmm
其中,nameofhmm是隐马模型的名称,如“开始”、“关闭”;hmmfile是一个描述隐马模型原型的文件,如拓扑结构,转移关系,特征维数等;model/hmm0为初始化生成的初始模型文件。
(2) 采用HCompv初始化
HCompv -A -D -T 1 -S trainlist.txt -M model/hmm0flat \
-H model/proto/hmmfile -f 0.01 nameofhmm
2. 参数重估
模型参数的估计采用HRest工具,调用该工具完成一轮参数的重新估计,具体命令行如下:
HRest -A -D -T 1 -S trainlist.txt -M model/hmmi -H vFloors \
-H model/hmmi-1/hmmfile -l label -L label.dir nameofhmm
其中,trainlist.txt文件包含所有用于训练的mfcc特征文件列表,label_dir是存放标注文件(.lab)的目录,vFloors是由HCompv生成的最小方差值的文件。
整个训练过程需要迭代多次,通常5-10轮次,每次迭代时,HRest程序可输出数据的似然值。
识别任务语法及词典定义
对于任意一个识别任务我们要定义该识别任务的语法,并生成待识别的网络,识别网络即包括所有可能识别的词或句子。在HTK中,支持用户写一个类似EBNF语法范式的文本文件,HParse工具可以自动对该文本文件进行解析,生成相应的识别网络文件。
对于本文中的例子,描述其语法的文本文件“gram.txt”如下:

其中,花括号表示允许0至多次出现,方括号表示0或1次出现。
然后可通过HParse生成识别网络文件“net.slf”
HParse -A -D -T 1 gram.txt net.slf
生成的识别网络如下图所示:
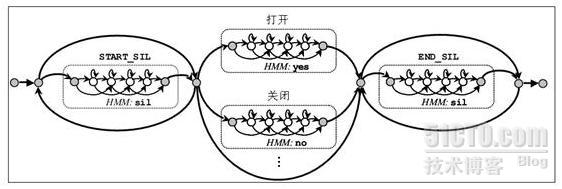
除了建立识别语法文件,还需要建立词典,词典是为了将最终识别的结果与隐马模型描述的单元名称建立对应关系,由于在本例中我们是直接以词为单元来建立模型,所以这里的词典就非常简单,词典“dict.txt”如下所示:

识别及测试
模型训练完成后就可以进行识别和测试了:
1. 首先录入待识别的语音,如“input.sig”,利用HCopy将其转换为MFCC特征矢量文件input.mfcc(与训练时提取特征过程相同)。
2. 识别是通过Viterbi算法在特征矢量上进行计算,与各个单词的隐马模型进行匹配。这一步是通过工具HVite进行的,具体命令行如下:
HVite -A -D -T 1 -H hmmdef.mmf -i reco.mlf -w net.slf \
dict.txt hmmlist.txt input.mfcc
其中“reco.mlf”为输出识别结果的文件,其识别结果形式如下所示:
识别及测试
模型训练完成后就可以进行识别和测试了:
1. 首先录入待识别的语音,如“input.sig”,利用HCopy将其转换为MFCC特征矢量文件input.mfcc(与训练时提取特征过程相同)。
2. 识别是通过Viterbi算法在特征矢量上进行计算,与各个单词的隐马模型进行匹配。这一步是通过工具HVite进行的,具体命令行如下:
HVite -A -D -T 1 -H hmmdef.mmf -i reco.mlf -w net.slf \
dict.txt hmmlist.txt input.mfcc
其中“reco.mlf”为输出识别结果的文件,其识别结果形式如下所示:

3. 当然HTK也支持采用一种更自然的方式进行识别测试,即直接录音进行识别,具体命令行如下:
HVite -A -D -T 1 -C directin.conf -g -H hmmsdef.mmf \
-w net.slf dict.txt hmmlist.txt
运行该命令后,命令行会出现“READY[1]>”,此时便可进行声音录入,按任意键结束录音,程序会进行识别并将结果显示在屏幕上, 然后出现“READY[2]>”进行下一次录音及识别。
由于在这种识别方式里由程序自动进行特征提取,配置文件direction.conf中需包含录音音频格式及特征提取过程所需的各类参数,一个具体示例如下:

本文出自 “百度技术博客” 博客,谢绝转载!