Heartbeat(v1、v2、pacemaker)集群组件概述
一、什么是Heartbeat
Heartbeat 是一个基于Linux开源的高可用集群系统。主要包括心跳服务和资源接管两个高可用集群组件。心跳监测服务可以通过网络链路和串口进行,而且支持冗余链路, 它们之间相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运行在对方主机上的资源或者服务。
二、HeartBeat版本
Heartbeat 是一个基于Linux开源的高可用集群系统。主要包括心跳服务和资源接管两个高可用集群组件,其重大的版本变更主要分为三个阶段。
1、Heartbeat v1.x
heartbeat v1版时就有了资源管理的概念,而v1版的资源就是heartbeat自带的,叫haresources,这个文件是个配置文件;而这个配置文件接口就叫haresources;
Heartbeat1.x允许集群节点和资源通过/etc/ha.d目录下面的两个文件来配置
ha.cf:定义集群节点,失效检测和切换时间间隔,集群时间日志机制和节点Fence方法
haresources: 定义集群资源组,每一行定义可以一起进行失效切换的一个默认的节点和一组资源,资源包括IP地址,文件系统,服务或者应用
2、Heartbeat v2.x
Heartbeat v2第二版的时候,heartbeat被做了很大的改进,自己可以做为一个独立进程来运行,并而可以通过它接收用户请求,它就叫crm,在运行时它需要在各节点上运行一个叫crmd的进程,这个进程通常要监听在一个套接字上,端口就是5560,所以服务器端叫crmd,而客户端叫crm(可以称为crm shell),是个命令行接口,通过这个命令行接口就可以跟服务器端的crm通信了,heartbeat也有它的图形化界面工具,就叫heartbeat-GUI工具,通过这个界面就可以配置进行。
Heartbeat 2.0 在基于Heartbeat1.x 基础上配置引入了模块结构的配置方法,集群资源管理器(Cluster Rescource Manager-CRM).
CRM模型可以支持最多16个节点,这个模型使用基于XML的集群信息(Cluster Information Base-CIB)配置。
Heartbeat 2.x官方最后一个STABLE release 2.x 版本是2.1.4。
CIB文件(/var/lib/heartbeat/crm/cib.xml)会在各个节点间自动复制,它定义了下面的对象和动作:
集群节点
集群资源,包括属性,优先级,组和依赖性
日志,监控,仲裁和fence标准
当服务失败或者其中设定的标准满足时,需要执行的动作
3、Heartbeat v3.x
在v3版本后,整个heartbeat项目进行了功能拆分,分为不同的子项目来分别进行开发。但是HA实现原理与Heartbeat2.x基本相同,配置也基本一致。在v3版本后,被拆分为heartbeat、pacemaker(心脏起博器)、cluster-glue(集群的贴合器),架构分离开来了,可以结合其它的组件工作。
Heartbeat:将原来的消息通信层独立为heartbeat项目,新的heartbeat只负责维护集群各节点的信息以及它们之前通信;
Cluster Glue:相当于一个中间层,它用来将heartbeat和pacemaker关联起来,主要包含2个部分,即为LRM和STONITH。
Resource Agent:用来控制服务启停,监控服务状态的脚本集合,这些脚本将被LRM调用从而实现各种资源启动、停止、监控等等。
Pacemaker: 也就是Cluster Resource Manager (简称CRM),用来管理整个HA的控制中心,客户端通过pacemaker来配置管理监控整个集群。
Heartbeat 3官方正式发布的首个版本是3.0.2。原来之前的CRM管理由pacemaker来替代,底层message layer依旧可以使用heartbeat v3也可以使用corosync等。 其具体细节本文不做介绍,可单独参考clusterlabs.org。
pacemaker是个资源管理器,不是提供心跳信息的,因为它似乎是一个普遍的误解,也是值得的。pacemaker是一个延续的CRM(亦称Heartbeat V2资源管理器),最初是为心跳,但已经成为独立的项目。
Pacemaker核心组件说明:
ccm组件(Cluster Consensus Menbership Service):作用,承上启下,监听底层接受的心跳信息,当监听不到心跳信息的时候就重新计算整个集群的票数和收敛状态信息,并将结果转递给上层,让上层做出决定采取怎样的措施,ccm还能够生成一个各节点状态的拓扑结构概览图,以本节点做为视角,保证该节点在特殊情况下能够采取对应的动作。
crmd组件(Cluster Resource Manager,集群资源管理器,也就是pacemaker):实现资源的分配,资源分配的每个动作都要通过crm来实现,是核心组建,每个节点上的crm都维护一个cib用来定义资源特定的属性,哪些资源定义在同一个节点上。
cib组件(集群信息基库,Cluster Infonation Base):是XML格式的配置文件,在内存中的一个XML格式的集群资源的配置文件,主要保存在文件中,工作的时候常驻在内存中并且需要通知给其它节点,只有DC上的cib才能进行修改,其他节点上的cib都是拷贝DC上。配置cib文件的方法有,基于命令行配置和基于前台的图形界面配置。
lrmd组件(Local Resource Manager,本地资源管理器):用来获取本地某个资源的状态,并且实现本地资源的管理,如当检测到对方没有心跳信息时,来启动本地的服务进程等。
pengine组件
PE(Policy Engine):策略引擎,来定义资源转移的一整套转移方式,但只是做策略者,并不亲自来参加资源转移的过程,而是让TE来执行自己的策略。
TE(Transition Engine): 就是来执行PE做出的策略的并且只有DC上才运行PE和TE。
stonithd组件
STONITH(Shoot The Other Node in the Head,”爆头“), 这种方式直接操作电源开关,当一个节点发生故障时,另 一个节点如果能侦测到,就会通过网络发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动, 这种方式需要硬件支持。
STONITH应用案例(主从服务器),主服务器在某一端时间由于服务繁忙,没时间响应心跳信息,如果这个时候备用服务器一下子把服务资源抢过去,但是这个时候主服务器还没有宕掉,这样就会导致资源抢占,就这样用户在主从服务器上都能访问,如果仅仅是读操作还没事,要是有写的操作,那就会导致文件系统崩溃,这样一切都玩了,所以在资源抢占的时候,可以采用一定的隔离方法来实现,就是备用服务器抢占资源的时候,直接把主服务器给STONITH,就是我们常说的”爆头 ”。
资源脚本(resource scripts)即Heartbeat控制下的脚本。这些脚本可以添加或移除IP别名(IP alias)或从属IP地址(secondary IP address),或者包含了可以启动/停止服务能力之外数据包的处理功能等。通常,Heartbeat会到/etc/init.d/或/etc/ha.d/resource.d/目录中读取脚本文件。Heartbeat需要一直明确了解"资源"归哪个节点拥有或由哪个节点提供。在编写一个脚本来启动或停止某个资源时,一定在要脚本中明确判断出相关服务是否由当前系统所提供。
三、Pacemaker特点
主机和应用程序级别的故障检测和恢复
几乎支持任何冗余配置
同时支持多种集群配置模式
配置策略处理法定人数损失(多台机器失败时)
支持应用启动/关机顺序
支持,必须/必须在同一台机器上运行的应用程序
支持多种模式的应用程序(如主/从)
可以测试任何故障或群集的群集状态
四、Pacemaker集群的分类
1.双机热备(Active/Passive)
官方说明:许多高可用性的情况下,使用Pacemaker和DRBD的双节点主/从集群是一个符合成本效益的解决方案。

2.多节点热备(N+1)
官方说明:支持多少节点,Pacemaker可以显着降低硬件成本通过允许几个主/从群集要结合和共享一个公用备份节点。

3.多节点共享存储(N-TO-N)
官方说明:有共享存储时,每个节点可能被用于故障转移。Pacemaker甚至可以运行多个服务。

4.共享存储热备 (Split Site)
官方说明:Pacemaker 1.2 将包括增强简化设立分站点集群

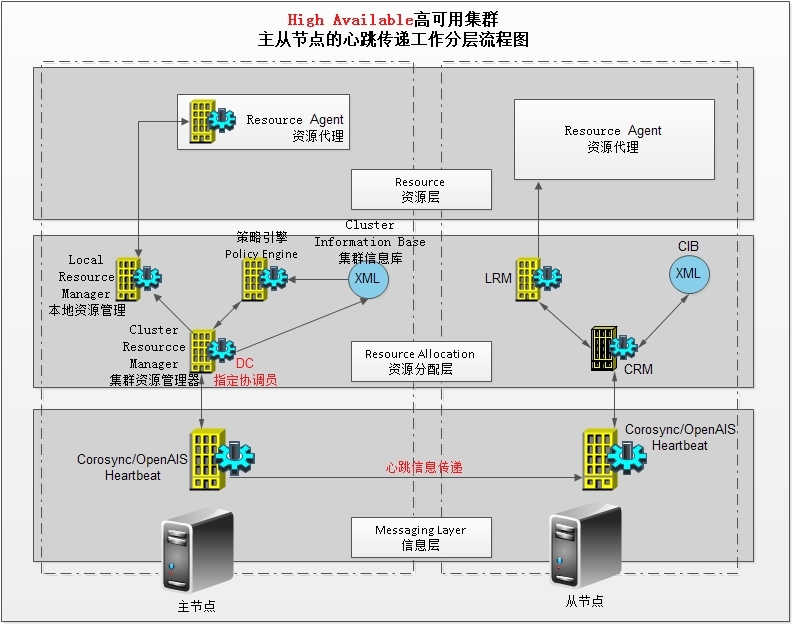
五、Pacemaker内部结构

群集组件说明:
stonithd:心跳系统。
lrmd:本地资源管理守护进程。它提供了一个通用的接口支持的资源类型。直接调用资源代理(脚本)。
pengine:政策引擎。根据当前状态和配置集群计算的下一个状态。产生一个过渡图,包含行动和依赖关系的列表。
CIB:群集信息库。包含所有群集选项,节点,资源,他们彼此之间的关系和现状的定义。同步更新到所有群集节点。
CRMD:集群资源管理守护进程。主要是消息代理的PEngine和LRM,还选举一个领导者(DC)统筹活动(包括启动/停止资源)的集群。
OpenAIS:OpenAIS的消息和成员层。
Heartbeat:心跳消息层,OpenAIS的一种替代。
CCM:共识群集成员,心跳成员层。

功能概述
CIB使用XML表示集群的集群中的所有资源的配置和当前状态。CIB的内容会被自动在整个集群中同步,使用PEngine计算集群的理想状态,生成指令列表,然后输送到DC(指定协调员)。Pacemaker 集群中所有节点选举的DC节点作为主决策节点。如果当选DC节点宕机,它会在所有的节点上, 迅速建立一个新的DC。DC将PEngine生成的策略,传递给其他节点上的LRMd(本地资源管理守护程序)或CRMD通过集群消息传递基础结构。当集群中有节点宕机,PEngine重新计算的理想策略。在某些情况下,可能有必要关闭节点,以保护共享数据或完整的资源回收。为此,Pacemaker配备了stonithd设备。STONITH可以将其它节点“爆头”,通常是实现与远程电源开关。Pacemaker会将STONITH设备,配置为资源保存在CIB中,使他们可以更容易地监测资源失败或宕机。
六、heartbeat心跳传递
HeartBeat运行于备用主机上的Heartbeat可以通过以太网连接检测主服务器的运行状态,一旦其无法检测到主服务器的"心跳"则自动接管主服务器的资源。通常情况下,主、备服务器间的心跳连接是一个独立的物理连接,这个连接可以是串行线缆、一个由"交叉线"实现的以太网连接。Heartbeat甚至可同时通过多个物理连接检测主服务器的工作状态,而其只要能通过其中一个连接收到主服务器处于活动状态的信息,就会认为主服务器处于正常状态。从实践经验的角度来说,建议为Heartbeat配置多条独立的物理连接,以避免Heartbeat通信线路本身存在单点故障。
串行电缆:被认为是比以太网连接安全性稍好些的连接方式,因为hacker无法通过串行连接运行诸如telnet、ssh或rsh类的程序,从而可以降低其通过已劫持的服务器再次侵入备份服务器的几率。但串行线缆受限于可用长度,因此主、备服务器的距离必须非常短。
以太网连接:使用此方式可以消除串行线缆的在长度方面限制,并且可以通过此连接在主备服务器间同步文件系统,从而减少了从正常通信连接带宽的占用。
基于冗余的角度考虑,应该在主、备服务器使用两个物理连接传输heartbeat的控制信息;这样可以避免在一个网络或线缆故障时导致两个节点同时认为自已是唯一处于活动状态的服务器从而出现争用资源的情况,这种争用资源的场景即是所谓的"脑裂"(split-brain)或"partitioned cluster"。在两个节点共享同一个物理设备资源的情况下,脑裂会产生相当可怕的后果。
七、Heartbeat控制信息
"心跳"信息: (也称为状态信息)仅150 bytes大小的广播、组播或多播数据包。可为以每个节点配置其向其它节点通报"心跳"信息的频率,以及其它节点上的heartbeat进程为了确认主节点出节点出现了运行等错误之前的等待时间。
集群变动事务(transition)信息:ip-request和ip-request-rest是相对较常见的两种集群变动信息,它们在节点间需要进行资源迁移时为不同节点上heartbeat进程间会话传递信息。比如,当修复了主节点并且使其重新"上线"后,主节点会使用ip-request要求备用节点释放其此前从因主节点故障而从主节点那里接管的资源。此时,备用节点则关闭服务并使用ip-request-resp通知主节点其已经不再占用此前接管的资源。主接点收到ip-request-resp后就会重新启动服务。
重传请求:在某集群节点发现其从其它节点接收到的heartbeat控制信息"失序"(heartbeat进程使用序列号来确保数据包在传输过程中没有被丢弃或出现错误)时,会要求对方重新传送此控制信息。 Heartbeat一般每一秒发送一次重传请求,以避免洪泛。
上面三种控制信息均基于UDP协议进行传送,可以在/etc/ha.d/ha.cf中指定其使用的UDP端口或者多播地址(使用以太网连接的情况下)。
此外,除了使用"序列号/确认"机制来确保控制信息的可靠传输外,Heartbeat还会使用MD5或SHA1为每个数据包进行签名以确保传输中的控制信息的安全性。