linux学习
很多关于linux的书籍在前面章节中写了一大堆东西来介绍linux,可惜读者看了好久也没有正式开始进入linux的世界,这样反而导致了他们对linux失去了一些兴趣,而把厚厚的一本书丢掉。
Linux的历史确实有必要让读者了解的,但是不了解也并不会影响你将来的linux技术水平。哈哈,本人其实就不怎么了解linux的历史,所以对于linux的历史在本教程中不会涉及到。如果你感兴趣的话,那你去网上搜一下吧,一大堆呢足够让你看一天的。虽然我不太想啰嗦太多,但是关于linux最基本的认识,我还是想简单介绍一下的。也算是我对linux的创始人Linus Torvalds先生的尊重。
在介绍linux的历史前,我想先针对大家如何对linux的发音说一下。我发现我身边的朋友对linux的发音大致有这么几种:“里那克斯”与“里你克斯”“里扭克斯”等。其实官方的标准发音为['li:nэks],因为这个发音是创始人Linus的发音。如果你不认识这个音标,那么就读成“里那克斯”。而笔者习惯发音成“里你克斯”,当然你发音成什么,并没有人会说你,完全是一个人的习惯而已。
也许有的读者已经了解到,linux和unix是非常像的。没错,linux就是根据unix演变过来的。当年linus就是因为接触到了unix而后才自己想开发一个简易的系统内核的,他开发的简易系统内核其实就是linux。当时linus把开发的这个系统内核丢到网上提供大家下载,由于它的精致小巧,越来越多的爱好者去研究它。人们对这个内核添枝加叶,而后成为了一个系统。也许你听说过吧,linux是免费的。其实这里的免费只是说linux的内核免费。在linux内核的基础上而产生了众多linux的版本。
Linux的发行版说简单点就是将Linux内核与应用软件做一个打包。较知名的发行版有:Ubuntu、RedHat、CentOS、Debain、Fedora、SuSE、OpenSUSE、TurboLinux、BluePoint、RedFlag、Xterm、SlackWare等
对于linux的应用,我想大多数都是用在服务器领域,对于服务器来讲真的没有必要跑一个图形界面。所以我们平时安装linux操作系统时往往是不安装图形界面的。说到这里也许你会有疑问,图形界面还能选择装或者不装?
是的,虽然linux和微软的windows一样同位操作系统,但是它们有一个很大的区别就是windows操作系统的图形界面是和内核一体的,俗称微内核,而linux操作系统图形界面就像一个软件一样,和内核并不是一体的。所以linux你可以选择不安装图形界面,这样不仅不影响服务器的正常使用还可以节省系统资源的开销,何乐而不为呢?
如果你对linux超级感兴趣,想使用linux就像使用windows一样,那你可以安装图形界面,可以像windows一样来体验linux也是蛮不错的。但是如果你想成为一个专业的linux系统工程师,那我建议你从第一天开始就不要去安装图形界面,从命令窗口开始熟悉它。
另外一点值得说的是,日常应用中,我们都是远程管理服务器的,不可能开着图形界面来让你去操作,虽然目前也有相应的工具支持远程图形连接服务器,可是那样太消耗网络带宽资源,所以从这方面来考虑还是建议你不要使用图形界面。
因为笔者一直都是使用CentOS,所以这次安装系统也是基于CentOS的安装。把光盘插入光驱,设置bios光驱启动。进入光盘的欢迎界面。
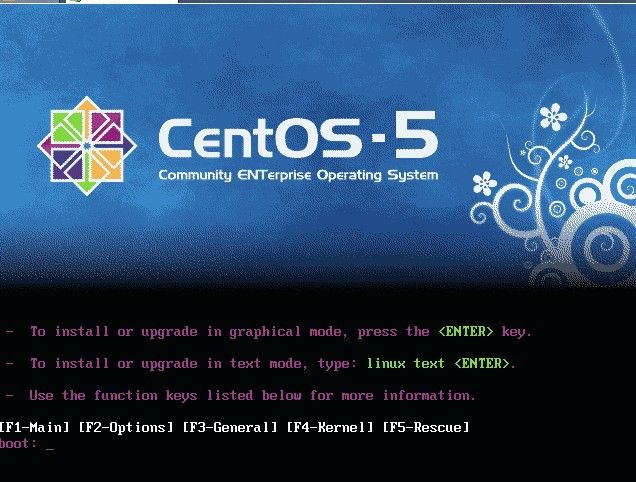
其中有两个选项,可以直接按回车,也可以在当前界面下输入 linux text 按回车。前者是图形下安装,可以动鼠标的,后者是纯文字形式的。建议初学者用前者安装。直接回车后,出现一下界面:
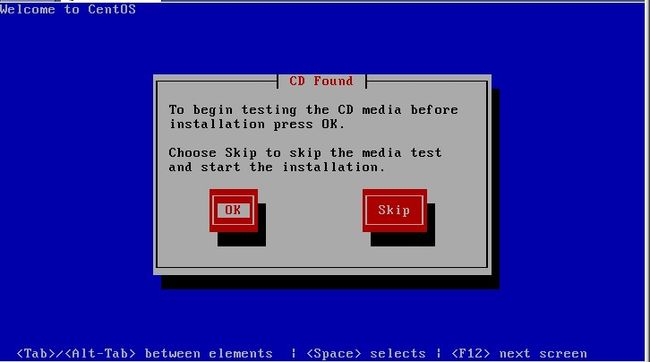
这一步是要提示你是否要校验光盘,目的是看看光盘中的安装包是否完整或者是否被人改动过,一般情况下,如果是正规的光盘不需要做这一步操作,因为太费时间。接下来是:

这一步没有什么可说明的,直接点“Next”
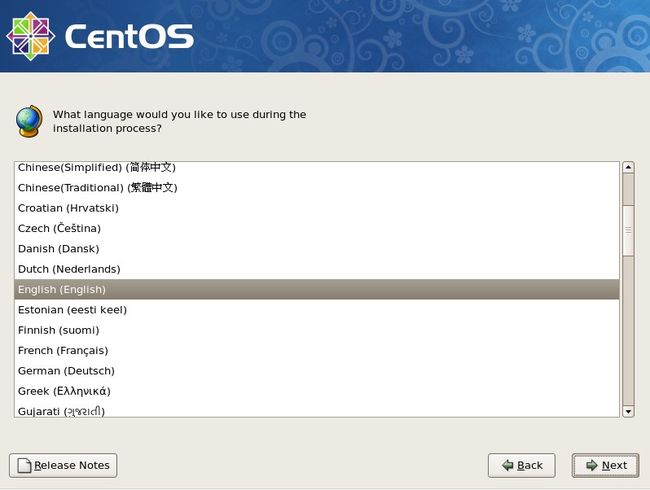
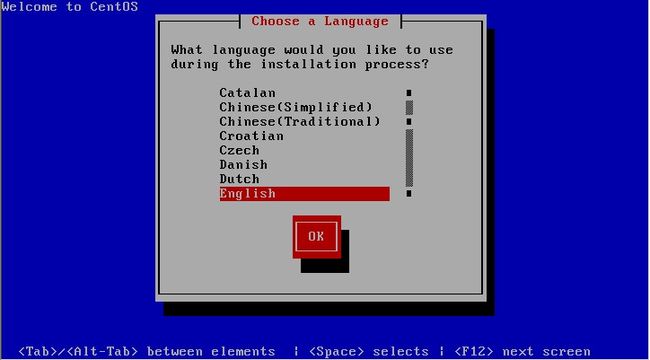
这里是选择安装系统时所用语言,笔者习惯用English,当然你也可以选择Chinese(Simplified)(简体中文),选择好后点“Next”

这里是选择合适的键盘,我们平时使用的都是英文键盘,所以这里不用动,默认即可,直接“Next”
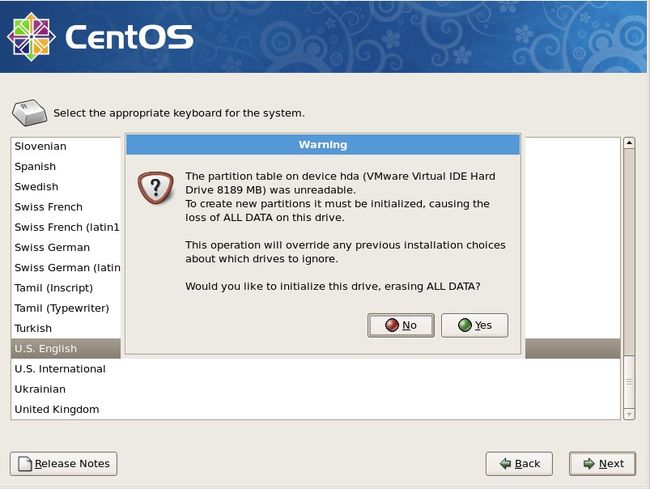
到这里就会提示你,下面会分区,会初始化磁盘,磁盘上的数据会丢失,问你是否要初始化设备并清除磁盘上的数据。因为是空盘,所以选择“Yes”

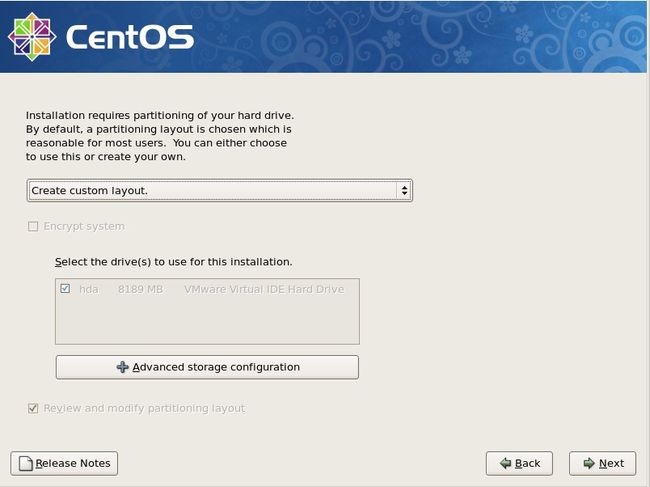
到这一步,就该分区了。其中一共有四种方式可以供你选择

第一种,在所选磁盘上把所有分区移除,然后按照默认的方式分区;
第二种,在所选磁盘上把所有linux分区移除(如果磁盘上有windows格式的分区,并不会移除),然后按照默认方式分区;
第三种,在所选磁盘上只使用空闲部分,并且按照默认方式分区;
第四种,用户自定义。
这里我们选第四种。然后“Next”
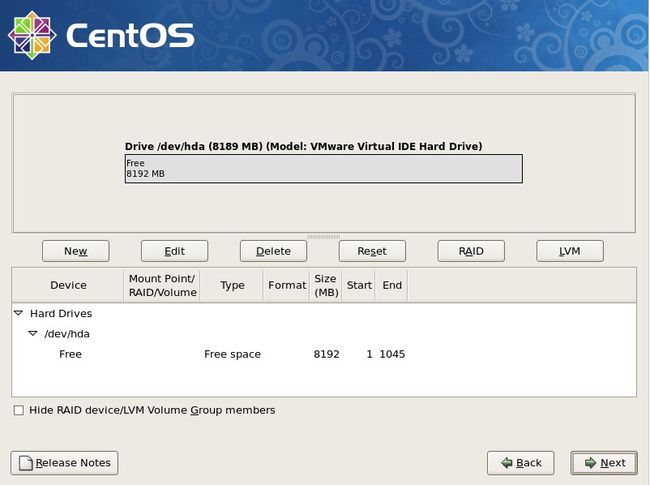
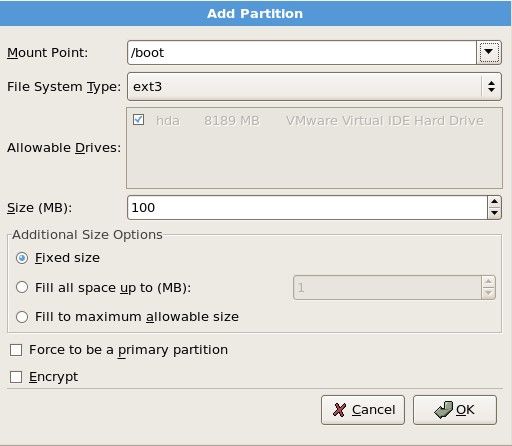
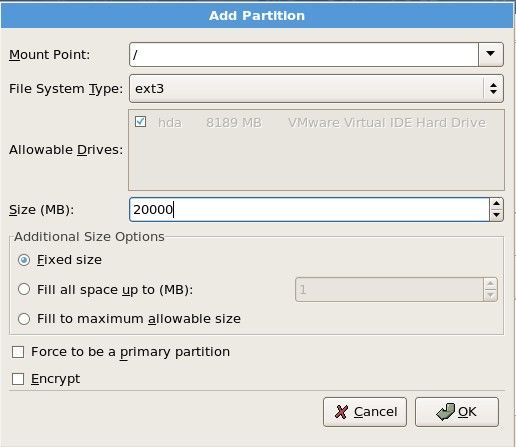
接下来该分区了,分区的很灵活,但大体上按照这个规则来(这是服务器上这样分,如果你是虚拟机,请看后边部分):
-
/boot 分区 100M
-
Swap 分区 内存的2倍,如果大于等于4G,则只需给4G即可

-
/ 分区给20G
-
剩余空间给/data
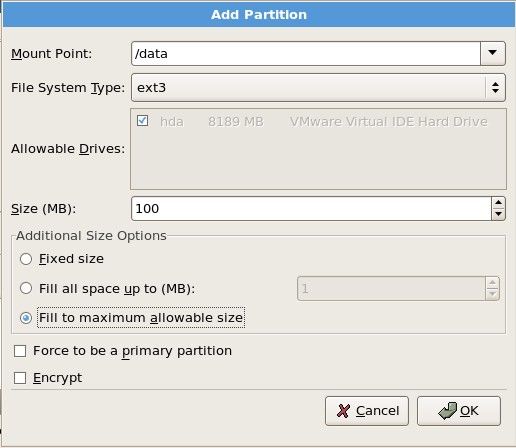
说明:/boot 分区是系统启动所需要的文件,就跟windows的C盘中的windows 目录类似,这个分区中的文件并不大,只需要100M足够。Swap分区是交换分区,当内存不够时,系统会把这部分空间当内存使用。/ 分区,其实就是一个根目录,在以后的章节中会介绍到。现在不懂并没有关系,只要知道有这么一个东西即可。/data 这个分区是我们自定义的,就是专门放数据的分区。
如果你安装的是虚拟机,并且你只有8G的磁盘空间,那么我建议你这样分区:
1 /boot 100M
2 swap 内存的2倍
3 / 全部剩余空间
分区完后,点“Next”

可以在Use a boot loader password 前面打勾,这个选项的作用是,给boot loader 加一个密码,为了防止有人通过光盘进入单用户模式修改root密码。
下面的选项同样可以打勾,笔者从来没有用过该功能,如果你有兴趣,可以研究一下。然后下一步
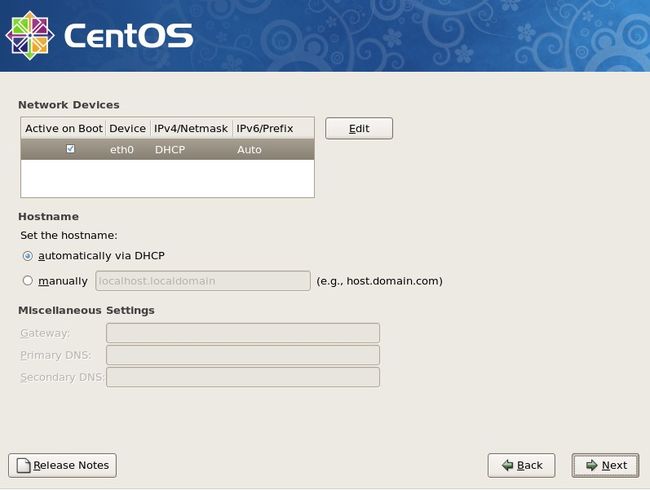
这一步是配置网卡信息,可以现在自定义网卡的IP,和配置主机名,默认是通过DHCP获得,你也可以点manually 自定义一个主机名,如 mail.example.com 。如果这两种方式都没有配置,那么linux会给你配置一个万能的主机名,即localhost.localdomain 剩下的几个就不用配置了,默认留空。
接着下一步,选择时区,在这里当然要选择我们所处的时区Asia/Chongqing 如果没有Chongqing那就选择Asia/Shanghai。
继续下一步

在这里自己定义一个root的密码,继续下一步
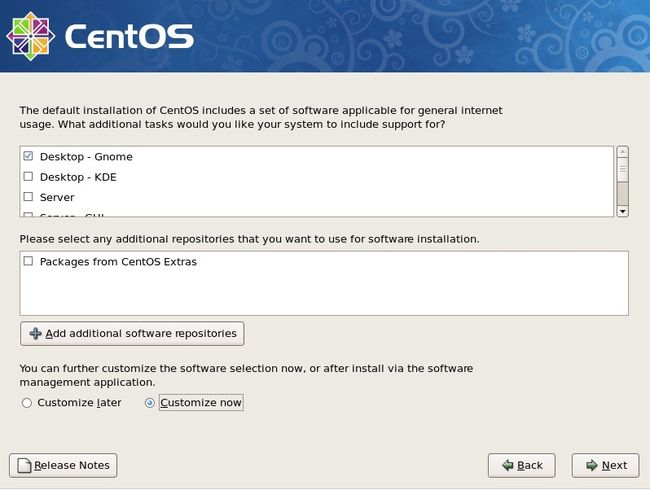
这里要我们选择要安装的包,笔者习惯自定义安装,需要点下面的“customize now”然后下一步
“Desktop Environments” 看右侧,把GNOME 前面的勾去掉,这个其实就是图形界面的安装包,如果不去掉这个勾,就会安装图形界面。

“Applications” 除了Editors 前面的勾去掉外,其他均不要

“Development”全部都要勾上
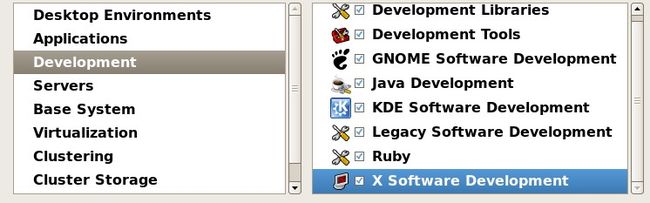
“Servers”以及以下所有项都不要勾任何,然后下一步

点Next 后,系统就开始安装了。

等过会后,会出现
至此,linux系统已经安装完成了。接下来点“Reboot”重启一下
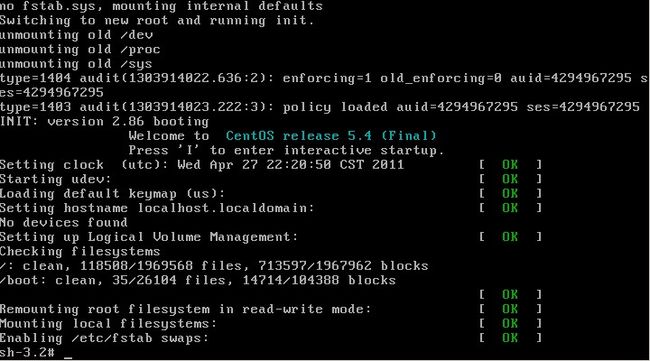
【Linux 系统启动过程】
Linux的启动其实和windows的启动过程很类似,不过windows我们是无法看到启动信息的,而linux启动时我们会看到许多启动信息,例如某个服务是否启动。
Linux系统的启动过程大体上可分为五部分:内核的引导;运行init;系统初始化;建立终端 ;用户登录系统。
A 内核引导
当计算机打开电源后,首先是BIOS开机自检,按照BIOS中设置的启动设备(通常是硬盘)来启动。紧接着由启动设备上的grub程序开始引导linux,Tips: 如果你看不懂这个文件,没有关系,随着你对linux的深入了解,你再回过头看这个文件你就会豁然开朗的。但是你现在必须要明白runlevel的各个级别的含义。
C 系统初始化
E 用户登录系统
【图形模式与文字模式的切换方式】
Linux预设提供了六个命令窗口终端机让我们来登录。默认我们登录的就是第一个窗口,也就是tty1,这个六个窗口分别为tty1,tty2 … tty6,你可以按下Ctrl + Alt + F1 ~ F6 来切换它们。如果你安装了图形界面,默认情况下是进入图形界面的,此时你就可以按Ctrl + Alt + F1 ~ F6来进入其中一个命令窗口界面。当你进入命令窗口界面后再返回图形界面只要按下Ctrl + Alt + F7 就回来了。如果你用的vmware 虚拟机,命令窗口切换的快捷键为 Alt + Space + F1~F6. 如果你在图形界面下请按Alt + Shift + Ctrl + F1~F6 切换至命令窗口。
【学会使用快捷键】
Ctrl + C:这个是用来终止当前命令的快捷键,当然你也可以输入一大串字符,不想让它运行直接Ctrl + C,光标就会跳入下一行。
Tab: 这个键是最有用的键了,也是笔者敲击概率最高的一个键。因为当你打一个命令打一半时,它会帮你补全的。不光是命令,当你打一个目录时,同样可以补全,不信你试试。
Ctrl + D: 退出当前终端,同样你也可以输入exit。
Ctrl + Z: 暂停当前进程,比如你正运行一个命令,突然觉得有点问题想暂停一下,就可以使用这个快捷键。暂停后,可以使用fg 恢复它。
Ctrl + L: 清屏,使光标移动到第一行。
【学会查询帮助文档 — man】
这个man 通常是用来看一个命令的帮助文档的。例如:
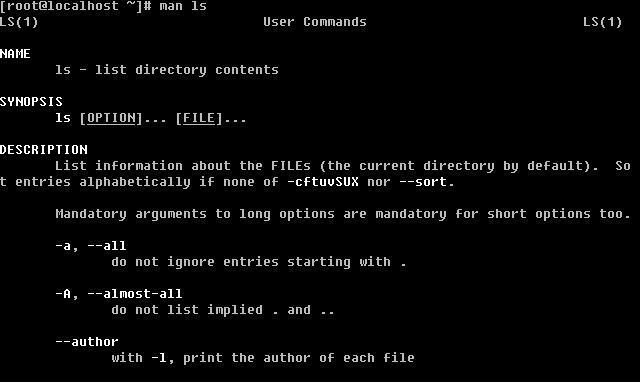
输入 man ls 其实格式为 man + 命令
你就会看到相关的帮助文档了。从命令的介绍到命令的参数以及用法介绍的都非常详细的。不错吧。
【Linux系统目录结构】
登录系统后,在当前命令窗口下输入 ls / 你会看到
![[image]](http://img.e-com-net.com/image/info2/ddf5cdc4bd6e402b81d6733b368f3dbc.jpg)
以下是对这些目录的解释:
/bin bin是Binary的缩写。这个目录存放着最经常使用的命令。
/boot这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev dev是Device(设备)的缩写。该目录下存放的是Linux的外部设备,在Linux中访问设备的方式和访问文件的方式是相同的。
/etc这个目录用来存放所有的系统管理所需要的配置文件和子目录。
/home用户的主目录,在Linux中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。
/lib这个目录里存放着系统最基本的动态连接共享库,其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
/lost+found这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。
/media linux系统会自动识别一些设备,例如U盘、光驱等等,当识别后,linux会把识别的设备挂载到这个目录下。
/mnt系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
/opt 这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
/proc这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all。
/root该目录为系统管理员,也称作超级权限者的用户主目录。
/sbin s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。
/selinux 这个目录是Redhat/CentOS所特有的目录,Selinux是一个安全机制,类似于windows的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。
/srv 该目录存放一些服务启动之后需要提取的数据。
/sys 这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs ,sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统种被创建。
/tmp这个目录是用来存放一些临时文件的。
/usr 这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似与windows下的program files目录。
/usr/bin:系统用户使用的应用程序。
/usr/sbin:超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src:内核源代码默认的放置目录。
/var这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
在linux系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。/etc: 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。/bin, /sbin, /usr/bin, /usr/sbin: 这是系统预设的执行文件的放置目录,比如 ls 就是在/bin/ls 目录下的。值得提出的是,/bin, /usr/bin 是给系统用户使用的指令(除root外的通用户),而/sbin, /usr/sbin 则是给root使用的指令。 /var: 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在/var/log 目录下,另外mail的预设放置也是在这里。
【如何正确关机】
其实,在linux领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
linux和windows不同,在 Linux 底下,由于每个程序(或者说是服务)都是在在背景下执行的,因此,在你看不到的屏幕背后其实可能有相当多人同时在你的主机上面工作,例如浏览网页啦、传送信件啦以 FTP 传送档案啦等等的,如果你直接按下电源开关来关机时,则其它人的数据可能就此中断!那可就伤脑筋了!此外,最大的问题是,若不正常关机,则可能造成文件系统的毁损(因为来不及将数据回写到档案中,所以有些服务的档案会有问题!)。
如果你要关机,必须要保证当前系统中没有其他用户在线。可以下达 who 这个指令,而如果要看网络的联机状态,可以下达 netstat -a 这个指令,而要看背景执行的程序可以执行 ps -aux 这个指令。使用这些指令可以让你稍微了解主机目前的使用状态!(这些命令在以后的章节中会提及,现在只要了解即可!)
正确的关机流程为:sysnc ? shutdown ? reboot ? halt
sync 将数据由内存同步到硬盘中。
shutdown 关机指令,你可以man shutdown 来看一下帮助文档。例如你可以运行如下命令关机:
shutdown –h 10 ‘This server will shutdown after 10 mins’ 这个命令告诉大家,计算机将在10分钟后关机,并且会显示在登陆用户的当前屏幕中。
Shutdown –h now 立马关机
Shutdown –h 20:25 系统会在今天20:25关机
Shutdown –h +10 十分钟后关机
Shutdown –r now 系统立马重启
Shutdown –r +10 系统十分钟后重启
reboot 就是重启,等同于 shutdown –r now
halt 关闭系统,等同于shutdown –h now 和 poweroff
最后总结一下,不管是重启系统还是关闭系统,首先要运行sync命令,把内存中的数据写到磁盘中。关机的命令有 shutdown –h now halt poweroff 和 init 0 , 重启系统的命令有 shutdown –r now reboot init 6.
【忘记root密码如何做】
以前笔者忘记windows的管理员密码,由于不会用光盘清除密码最后只能重新安装系统。现在想想那是多么愚笨的一件事情。同样linux系统你也会遇到忘记root密码的情况,如果遇到这样的情况怎么办呢?重新安装系统吗?当然不用!进入单用户模式更改一下root密码即可。如何进入呢。
1 重启linux系统

3 秒之内要按一下回车,出现如下界面

然后输入e
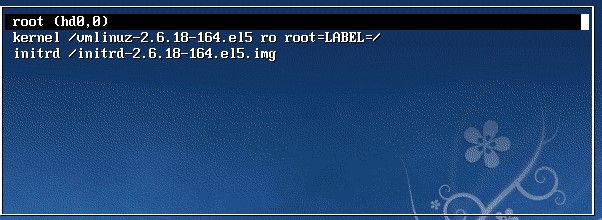
在 第二行最后边输入 single,有一个空格。具体方法为按向下尖头移动到第二行,按“e”进入编辑模式
 在后边加上single 回车
在后边加上single 回车
![[image]](http://img.e-com-net.com/image/info2/6efed1a65b2745d0b852971534272279.jpg)
最后按“b”启动,启动后就进入了单用户模式了
此时已经进入到单用户模式了,你可以更改root密码了。更密码的命令为 passwd
![[image]](http://img.e-com-net.com/image/info2/3ea9a93acc304aba97ec9a038aae2bfa.jpg)
【使用系统安装光盘的救援模式】
救援模式即rescue ,这个模式主要是应用于,系统无法进入的情况。如,grub损坏或者某一个配置文件修改出错。如何使用rescue模式呢?
光盘启动,按F5 进入rescue模式

输入linux rescue 回车
![[image]](http://img.e-com-net.com/image/info2/380fd15c2f304ccabd8bcd3f2380d212.jpg)
选择语言,笔者建议你选择英语
选择us 键盘

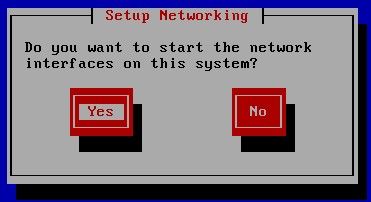
这里问你是否启动网络,有时候可能会联网调试。我们选no

这里告诉我们,接下来会把系统挂载在/mnt/sysimage 中。其中有三个选项,Continue 就是挂载后继续下一步; Read-Only 挂载成只读,这样更安全,有时文件系统损坏时,只读模式会防止文件系统近一步损坏;Skip就是不挂载,进入一个命令窗口模式。这里我们选择Continue。
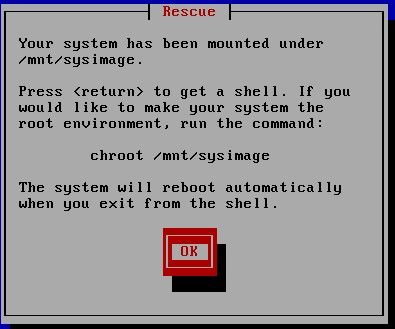
至此,系统已经挂载到了/mnt/sysimage中。接下来回车,输入chroot /mnt/sysimage 进入管理员环境。
![[image]](http://img.e-com-net.com/image/info2/6ded9c32e63b465e92913e81847a2898.jpg)
Tips: 其实也可以到rescue模式下更改root的密码的。这个rescue模式和windows PE系统很相近。当运行了chroot /mnt/sysimage/ 后,再ls 看到目录结构和原来系统中的目录结构是一样的。没错!现在的环境和原来系统的环境是一模一样的。你可以输入exit 或者按Ctrl + D退出这个环境。然后你再ls 看一下
![[image]](http://img.e-com-net.com/image/info2/44e1782db814436c95495bb31cd4e906.jpg)
这个目录其实就是rescue模式下的目录结构,而我们的系统文件全部在 /mnt/sysimage目录下
Linux大多应用于服务器,而服务器不可能像PC一样放在办公室,它们是放在IDC机房的,所以我平时登录linux系统都是通过远程登录的。Linux系统中是通过ssh服务实现的远程登录功能。默认ssh服务开启了22端口,而且当我们安装完系统时,这个服务已经安装,并且是开机启动的。所以不需要我们额外配置什么就能直接远程登录linux系统。ssh服务的配置文件为 /etc/ssh/sshd_config,你可以修改这个配置文件来实现你想要的ssh服务。比如你可以更改启动端口为36000.
如果你是windows的操作系统,则Linux远程登录需要在我们的机器上额外安装一个终端软件。目前比较常见的终端登录软件有SecureCRT, Putty, SSH Secure Shell等,很多朋友喜欢用SecureCRT因为它的功能是很强大的,而笔者喜欢用Putty,只是因为它的小巧以及非常漂亮的颜色显示。不管你使用哪一个客户端软件,最终的目的只有一个,就是远程登录到linux服务器上。这些软件网上有很多免费版的,你可以下载一个试着玩玩。下面笔者介绍如何使用Putty登录远程linux服务器。
如果你下载了putty,请双击putty.exe 然后弹出如下的窗口。笔者所用putty为英文版的,如果你觉得英文的用着别扭,可以下载一个中文版的。
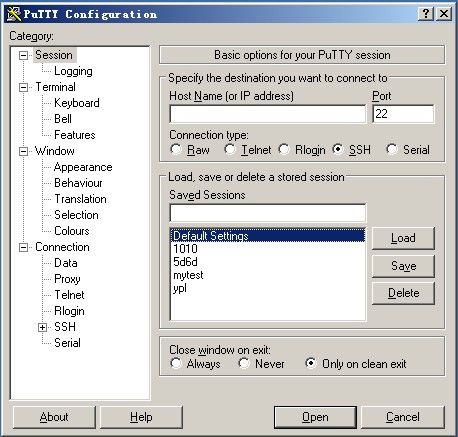
因为是远程登录,所以你要登录的服务器一定会有一个IP或者主机名。请在Host Name( or IP address) 下面的框中输入你要登录的远程服务器IP(如果你的linux还没有IP,那么请自行设置一个IP,如何设置请到后续章节查找),然后回车。

此时,提示我们输入要登录的用户名。
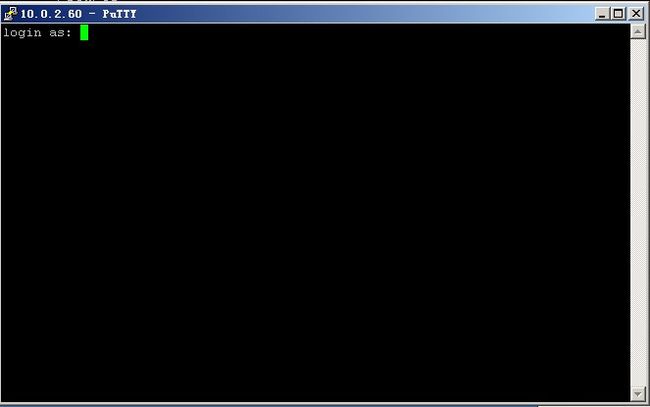
输入root 然后回车,再输入密码,就能登录到远程的linux系统了。

【使用密钥认证机制远程登录linux】
SSH服务支持一种安全认证机制,即密钥认证。所谓的密钥认证,实际上是使用一对加密字符串,一个称为公钥(public key), 任何人都可以看到其内容,用于加密;另一个称为密钥(private key),只有拥有者才能看到,用于解密。 通过公钥加密过的密文使用密钥可以轻松解密,但根据公钥来猜测密钥却十分困难。 ssh 的密钥认证就是使用了这一特性。服务器和客户端都各自拥有自己的公钥和密钥。 如何使用密钥认证登录linux服务器呢?
首先使用工具 PUTTYGEN.EXE 生成密钥对。打开工具PUTTYGEN.EXE后如下图所示:

该工具可以生成三种格式的key :SSH-1(RSA) SSH-2(RSA) SSH-2(DSA) ,我们采用默认的格式即SSH-2(RSA)。Number of bits in a generated key 这个是指生成的key的大小,这个数值越大,生成的key就越复杂,安全性就越高。这里我们写2048.
![[image]](http://img.e-com-net.com/image/info2/87c6355fb432448093d7e2b586adf846.jpg)
然后单击Generate 开始生成密钥对:
![[image]](http://img.e-com-net.com/image/info2/dd4d3cea961b44a3b39fe75bf9ff14f3.jpg)
注意的是,在这个过程中鼠标要来回的动,否则这个进度条是不会动的。

到这里,密钥对已经生成了。你可以给你的密钥输入一个密码,(在Key Passphrase那里)也可以留空。然后点 Save public key 保存公钥,点 Save private Key 保存私钥。笔者建议你放到一个比较安全的地方,一来防止别人偷窥,二来防止误删除。接下来就该到远程linux主机上设置了。
1)创建目录 /root/.ssh 并设置权限
[root@localhost ~]
[root@localhost ~]
2)创建文件 / root/.ssh/authorized_keys
[root@localhost ~]
3)打开刚才生成的public key 文件,建议使用写字板打开,这样看着舒服一些,复制从AAAA开头至 “---- END SSH2 PUBLIC KEY ----“ 该行上的所有内容,粘贴到/root/.ssh/authorized_keys 文件中,要保证所有字符在一行。(可以先把复制的内容拷贝至记事本,然后编辑成一行载粘贴到该文件中)。在这里要简单介绍一下,如何粘贴,用vim打开那个文件后,该文件不存在,所以vim会自动创建。按一下字母”i”然后同时按shift + Insert 进行粘贴(或者单击鼠标邮件即可),前提是已经复制到剪切板中了。粘贴好后,然后把光标移动到该行最前面输入ssh-ras ,然后按空格。再按ESC,然后输入冒号wq 即 :wq 就保存了。格式如下图:

4)再设置putty选项,点窗口左侧的SSh –> Auth ,单击窗口右侧的Browse… 选择刚刚生成的私钥, 再点Open ,此时输入root,就不用输入密码就能登录了。

如果在前面你设置了Key Passphrase ,那么此时就会提示你输入密码的。为了更加安全建议大家要设置一个Key Passphrase。
在linux中什么是一个文件的路径呢,说白了就是这个文件存在的地方,例如在上一章提到的/root/.ssh/authorized_keys 这就是一个文件的路径。如果你告诉系统这个文件的路径,那么系统就可以找到这个文件。在linux的世界中,存在着绝对路径和相对路径。
绝对路径:路径的写法一定由根目录”/”写起,例如/usr/local/mysql 这就是绝对路径。
相对路径:路径的写法不是由根目录”/”写起,例如,首先用户进入到/ 然后再进入到home ,命令为 cd /home 然后 cd test 此时用户所在的路径为 /home/test 。第一个cd命令后跟 /home 第二个cd命令后跟test ,并没有斜杠,这个test是相对于/home 目录来讲的,所以叫做相对路径。
pwd 这个命令打印出当前所在目录
![[image]](http://img.e-com-net.com/image/info2/4caf96a3846c490fa118260a940a20b2.jpg)
cd 进入到某一个目录
![[image]](http://img.e-com-net.com/image/info2/017e34b646ea400dacb24fd871ea4937.jpg)
./ 指的是当前目录
../ 指的是当前目录的上一级目录。

上图中,首先进入到/usr/local/lib/ 目录下,然后再进入 ./ 其实还是进入到当前目录下,用pwd查看当前目录,并没有发生变化,然后再进入../ 则是进入到了/usr/local/目录下,即/usr/local/lib目录的上一级目录。你看明白了吗?
mkdir 创建一个目录,这个命令在上一章节中提及过。mkdir 其实就是make directory的缩写。其语法为 mkdir [-mp] [目录名称] ,其中-m , –p 为其选项,-m:这个参数用来指定要创建目录的权限,该参数不常用,所以笔者不做重点解释。-p:这个参数很管用的,先来做个试验,你会一目了然的。
![[image]](http://img.e-com-net.com/image/info2/5ed65bf3a138499f8c8ba30b41d9eee7.png)
当我们想创建 /tmp/test/123 目录,可是提示不能创建,原因是/tmp/test目录不存在,你会说,这个linux怎么这样傻,/tmp/test目录不存在就自动创建不就OK了嘛,的确linux确实很傻,如果它发现要创建的目录的上一级目录不存在就会报错。然后linux也为我们想好了解决办法,即-p参数。
![[image]](http://img.e-com-net.com/image/info2/1116f6e43f5242f095c7a8caa100daca.jpg)
你看到这里,是不是明白-p参数的作用了?没错,它的作用就是递归创建目录,即使上级目录不存在。还有一种情况就是如果你想要创建的目录存在的话,会提示报错,然后你加上-p参数后,就不会报错了。
![[image]](http://img.e-com-net.com/image/info2/d130868c767c40e5a639f7291a16d670.jpg)
rmdir 删除一个目录。
![[image]](http://img.e-com-net.com/image/info2/a0b3c45a00c84d3ba490addca1ba5b5c.jpg)
rmdir 其实是rmove directory 缩写,其只有一个选项-p 类似与mkdir命令,这个参数的作用是将上级目录一起删除。举个例子吧,新建目录mkdir -p d1/d2/d3 ,rmdir -p d1/d2/d3相当于是删除了d1,d1/d2, d1/d2/d3。如果一个目录中还有目录,那么当你直接rmdir 该目录时,会提示该目录不为空,不能删除。如果你非要删除不为空的目录,那你用rm指令吧。
rm 删除目录或者文件
rmdir 只能删除目录但不能删除文件,要想删除一个文件,则要用rm命令了。rm同样也有很多选项。你可以通过 man rm 来获得详细帮助信息。在这里笔者只列举较常用的几个选项。
-f 强制的意思,如果不加这个选项,当删除一个不存在的文件时会报错。
![[image]](http://img.e-com-net.com/image/info2/dc170059c21e4b13ab231a6569c3c7cc.jpg)
-i 这个选项的作用是,当用户删除一个文件时会提示用户是否真的删除。
![[image]](http://img.e-com-net.com/image/info2/803e067352074bba92a28ca4b41c309d.png)
如果删除,输入y 否则输入 n
-r 当删除目录时,加该选项,如果不加这个选项会报错。rm是可以删除不为空的目录的。

你会发现,笔者在列举的rm例子中使用的是绝对路径,而ls 则使用的相对路径。这是为什么呢?
![[image]](http://img.e-com-net.com/image/info2/0f77fecdcd8b4ed8a47b38f78c06e0d5.jpg)
which 用来查找一个命令的绝对路径,这个命令笔者不详细介绍,因为平时笔者只用来查找一个命令的绝对路径。
alias 用来【环境变量PATH】
上边提到了alias,也提到了绝对路径的/bin/rm ,然后你意识到没有,为什么我们输入很多命令时是直接打出了命令,而没有去使用这些命令的绝对路径?这是因为环境变量PATH在起作用了。请输入 echo $PATH,这里的echo其实就是打印的意思,而PATH前面的$表示后面接的是变量。
![[image]](http://img.e-com-net.com/image/info2/7ca810692de148e4b16e08e3b31906d3.jpg)
因为/bin 在PATH的设定中,所以自然就可以找到ls了。如果你将 ls 移动到 /root 底下的话,然后你自己本身也在 /root 底下,但是当你执行 ls 的时候,他就是不理你?怎么办?这是因为 PATH 没有 /root 这个目录,而你又将 ls 移动到 /root 底下了,自然系统就找不到可执行文件了,因此就会告诉你, command not found !那么该怎么克服这种问题呢?
有两个方法,一种方法是直接将 /root 的路径加入 PATH 当中!如何增加?可以使用:
PATH=”$PATH”:/root
另一种方式则是使用完整档名,亦即直接使用相对或绝对路径来执行,例如:
/root/ls
./ls
关于rm,笔者使用最多便是-rf两个选项合用了。不管删除文件还是目录都可以。但是方便的同时也要多注意,万一你的手太快后边跟了/那样就会把你的系统文件全部删除的,切记切记。

ls 在前面的命令中多次用到它。现在你已经明白它的含义了吧。没有错,就是查看某个目录或者某个文件,是list的简写。ls 后可以跟一个目录,也可以跟一个文件。以下是ls的选项,在这里笔者并没有完全列出,只是列出了平时使用最多的选项。其他选项,你可以自行通过man ls 查询。
-a 全部的档案都列出,包括隐藏的。linux文件系统中同样也有隐藏文件。这些隐藏文件的文件名是以.开头的。例如.test, /root/.123, /root/.ssh 等等,隐藏文件可以是目录也可以是普通文件。
-l 详细列出文件的属性信息,包括大小、创建日期、所属主所属组等等。ll 这个命令等同于ls –l 。
![]()
--color=never/always/auto never即不要显示颜色,always 即总显示颜色,auto 是由系统自行判断。在Redhat/CentOS 系统中,默认是带颜色的,因为我们平时用的ls已经alias成了ls –color=tty 所以目录的颜色是蓝色的,而可执行文件的颜色是绿色。这样有助于帮我们区分文件的格式。
![]()
-d 后边跟目录,如果不加这个选项则列出目录下的文件,加上后只列车目录本身。
![[image]](http://img.e-com-net.com/image/info2/66214a00b50a4b1da2aa60175ddcfaad.jpg)
cp copy的简写,即拷贝。格式为 cp [选项] [ 来源文件 ] [目的文件] ,例如我想把test1 拷贝成test2 ,这样即可 cp test1 test2,以下介绍几个常用的选项
-d 这里涉及到一个“连接”的概念。连接分为软连接和硬连接。在以后的章节中会详细解释,现在你只要明白这里的软连接跟windows中的快捷方式类似即可。如果不加这个-d 则拷贝软连接时会把软连接的目标文件拷贝过去,而加上后,其实只是拷贝了一个连接文件(即快捷方式)。
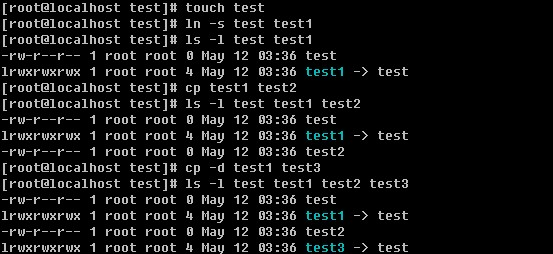
上例中的ln 命令即为建立连接的,以后再做详细解释。
-r 如果你要拷贝一个目录,必须要加-r选项,否则你是拷贝不了目录的。
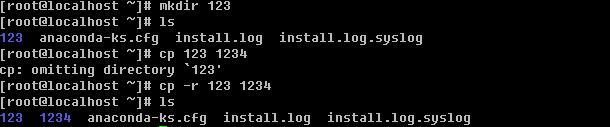
-i 如果遇到一个存在的文件,会问是否覆盖。在Redhat/CentOS系统中,我们使用的cp其实是cp –i
![[image]](http://img.e-com-net.com/image/info2/7db82943dbb7431284f5128efaa190f7.jpg)
下面简单做一个小试验,很快你就会明白-i 选项的作用了。

上例中,touch 命令,看字面意思就是摸一下,没错,如果有这个文件,则会改变文件的访问时间,如果没有这个文件就会创建这个文件。前面说过echo,其实就是打印,在这里所echo的内容”abc” 和 “def”并没有显示在屏幕上,而是分别写进了文件 111和222, 其写入作用的就是这个大于号”>” 在linux中这叫做重定向,即把前面产生的输出写入到后面的文件中。在以后的章节中会做详细介绍,这里你要明白它的含义即可。而cat 命令则是读一个文件,并把读出的内容打印到当前屏幕上。该命令也会在后续章节中详细介绍。
-u 该选项仅当目标文件存在时才会生效,如果源文件比目标文件新才会拷贝,否则不做任何动作。
mv 移动的意思,是move的简写。格式为 mv [ 选项 ] [源文件] [目标文件],下面介绍几个常用的选项。
-i 和cp的-i 一样,当目标文件存在时会问用户是否要覆盖。在Redhat/CentOS系统中,我们使用的mv其实是mv –i
-u 和上边cp 命令的-u选项一个作用,当目标文件存在时才会生效,如果源文件比目标文件新才会移动,否则不做任何动作。
该命令有集中情况,你注意到了吗?
1) 目标文件是目录,而且目标文件不存在;
2) 目标文件是目录,而且目标文件存在;
3) 目标文件不是目录不存在;
4) 目标文件不是目录存在;
目标文件是目录,存在和不存在,移动的结果是不一样的,如果存在,则会把源文件移动到目标文件目录中。不存在的话移动完后,目标文件是一个文件。这样说也许你会觉得有点不好理解,看例子吧。

windows下的重命名,在linux下用mv就可以搞定。
cat 比较常用的一个命令,即查看一个文件的内容并显示在屏幕上。
-n 查看文件时,把行号也显示到屏幕上。
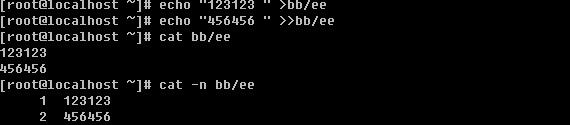
上例中出现了一个”>>”,这个符号跟前面介绍的”>”的作用都是重定向,即把前面输出的东西输入到后边的文件中,只是”>>”是追加的意思,而用”>”,如果文件中有内容则会删除文件中内容,而”>>”则不会。
-A 显示所有东西出来,包括特殊字符
![[image]](http://img.e-com-net.com/image/info2/588ff9d4d852413e812e144c3d28afa5.jpg)
tac 其实是cat的反写,同样的功能也是反向打印文件的内容到屏幕上。
![[image]](http://img.e-com-net.com/image/info2/765e24bdd87b4694bf331f1846674c60.jpg)
more 也是用来查看一个文件的内容。当文件内容太多,一屏幕不能占下,而你用cat肯定是看不前面的内容的,那么使用more就可以解决这个问题了。当看完一屏后按空格键继续看下一屏。但看完所有内容后就会退出。如果你想提前退出,只需按q键即可。
less 作用跟more一样,但比more好在可以上翻,下翻。空格键同样可以翻页,而按”j”键可以向下移动(按一下就向下移动一行),按”k”键向上移动。在使用more和less查看某个文件时,你可以按一下”/” 键,然后输入一个word回车,这样就可以查找这个word了。如果是多个该word可以按”n”键显示下一个。另外你也可以不按”/”而是按”?”后边同样跟word来搜索这个word,唯一不同的是,”/”是在当前行向下搜索,而”?”是在当前行向上搜索。
head head后直接跟文件名,则显示文件的前十行。如果加 –n 选项则显示文件前n行。
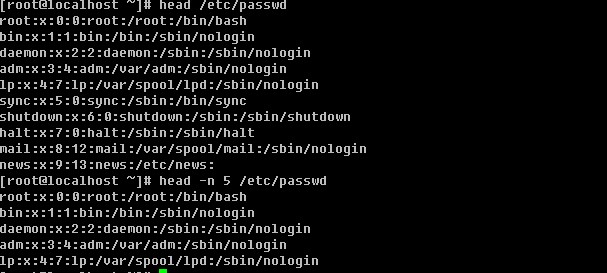
tail 和head一样,后面直接跟文件名,则显示文件最后十行。如果加-n 选项则显示文件最后n行。

-f 动态显示文件的最后十行,如果文件是不断增加的,则用-f 选项。如:tail -f /var/log/messages
【文件的所属主以及所属组】
一个linux目录或者文件,都会有一个所属主和所属组。所属主,即文件的拥有者,而所属组,即该文件所属主所在的一个组。Linux这样设置文件属性的目的是为了文件的安全。例如,test文件的所属主是user0 而test1文件的所属主是user1,那么user1是不能查看test文件的,相应的user0也不能查看test1文件。然后有这样一个应用,我想创建一个文件同时让user0和user1来查看怎么办呢?
这时“所属组”就派上用场了。即,创建一个群组users,让user0和user1同属于users组,然后建立一个文件test2,且其所属组为users,那么user0和user1都可以访问test2文件。
Linux文件属性不仅规定了所属主和所属组,还规定了所属主(user)、所属组(group)以及其他用户(others)对该文件的权限。你可以通过ls -l 来查看这些属性。

【linux文件属性】
上例中,用ls –l 查看当前目录下的文件时,共显示了9列内容(用空格划分列),都代表了什么含义呢?
第1列,包含的东西有该文件类型和所属主、所属组以及其他用户对该文件的权限。第一列共10位。其中第一位用来描述该文件的类型。上例中,我们看到的类型有”d”, “-“ ,其实除了这两种外还有”l”, “b”, “c”,”s”等。
d 表示该文件为目录;
- 表示该文件为普通文件;
l 表示该文件为连接文件(linux file),上边提到的软连接即为该类型;
![]()
b 表示该文件为块设备文件,比如磁盘分区
![[image]](http://img.e-com-net.com/image/info2/1ca707752ebf47cab72e6c3f89670997.jpg)
c 表示该文件为串行端口设备,例如键盘、鼠标。
s 表示该文件为套接字文件(socket),用于进程间通信。
后边的9位,每三个为一组。均为rwx 三个参数的组合。其中r 代表可读,w代表可写,x代表可执行。前三位为所属主(user)的权限,中间三位为所属组(group)的权限,最后三位为其他非本群组(others)的权限。下面拿一个具体的例子来述说一下。
一个文件的属性为-rwxr-xr-- ,它代表的意思是,该文件为普通文件,文件拥有者可读可写可执行,文件所属组对其可读不可写可执行,其他用户对其只可读。
对于一个目录来讲,打开这个目录即为执行这个目录,所以任何一个目录必须要有x权限才能打开并查看该目录。例如一个目录的属性为 drwxr--r-- 其所属主为root,那么除了root外的其他用户是不能打开这个目录的。
第2列,表示为连接占用的节点(inode),若为目录时,通常与该目录地下还有多少目录有关系,关于连接(link)在以后章节详细介绍。
第3列,表示该文件的所属主。
第4列,表示该文件的所属组。
第5列,表示该文件的大小。
第6列、第7列和第8列为该文件的创建日期或者最近的修改日期,分别为月份日期以及时间。
第9列,文件名。如果前面有一个. 则表示该文件为隐藏文件。
【更改文件的权限】
更改文件的权限,也就是更改所属主、所属组以及他们对应的读写执行权限。
1)更改所属组 chgrp
语法:chgrp [组名] [文件名]

这里用到了groupadd 命令,其含义即增加一个用户组。该命令在以后章节中做详细介绍,你只要知道它是用来增加用户组的即可。
2)更改文件的所属主 chown
语法:chown [ -R ] 账户名 文件名
chown [ -R ] 账户名:组名 文件名
这里的-R选项只作用于目录,作用是级联更改,即不仅更改当前目录,连目录里的目录或者文件全部更改。

useradd 是增加一个账户,以后会详细介绍。上例中,首先建立一个目录test,然后在test目录下创建一个普通文件test2,因为是以root的身份创建的目录和文件,所以所属主以及所属组都是root。chown user1 test 这使test的目录所属主由root变为了user1 ,然后test目录下的test2文件所属主以及所属组还是root。接着 chown –R user1:testgroup test 这样把test连同test目录下的test2 的所属主以及所属组都改变了。
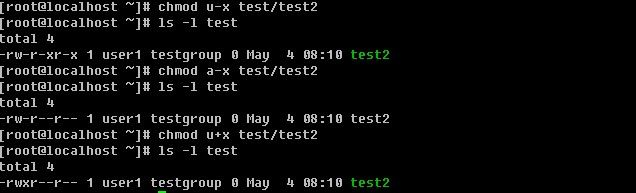
3)改变用户对文件的读写执行权限 chmod
在linux中为了方便更改这些权限,linux使用数字去代替rwx ,具体规则为r: 4 w:2 x:1 -:0 举个例子,-rwxrwx---用数字表示就是 770,具体是这样来的:
rwx = 4+2+1=7; rwx= 4+2+1=7; --- = 0+0+0=0
chmod 语法: chmod [-R] xyz 文件名 (这里的xyz,表示数字)
-R 选项作用同chown,级联更改。
值得提一下的是,在linux系统中,默认一个目录的权限为 755,而一个文件的默认权限为644.

如果你创建了一个目录,而该目录不想让其他人看到内容,则只需设置成 rwxr----- (740) 即可。
chmod 还支持使用rwx的方式来设置权限。!从之前的介绍中我们可以发现,基本上就九个属性分别是(1)user (2)group (3)others 三群啦!那么我们就可以藉由 u, g, o 来代表三群的属性!此外, a 则代表 all 亦即全部的三群!那么读写的属性就可以写成了 r, w, x!也就是可以使用底下的方式来看:

现在我想把一个文件设置成这样的权限 rwxr-xr-x (755),使用这种方式改变权限的命令为
![]()
另外还可以针对u, g, o, a增加或者减少某个权限(读,写,执行),例如
另外linux下还有两个比较特殊的权限s和t,请点击linux下文件的特殊权限s和t
umask
上边也提到了默认情况下,目录权限值为766,普通文件权限值为644。那么这个值是由谁规定呢?追究其原因就涉及到了umask。
umask语法: umask xxx (这里的xxx代表三个数字)
查看umask值只要输入umask然后回车。 umask预设是0022,其代表什么含义?先看一下下面的规则:
1)若用户建立为普通文件,则预设“没有可执行权限”,只有rw两个权限。最大为666(-rw-rw-rw-)
2)若用户建立为目录,则预设所有权限均开放,即777(drwxrwxrwx)
umask数值代表的含义为,上边两条规则中的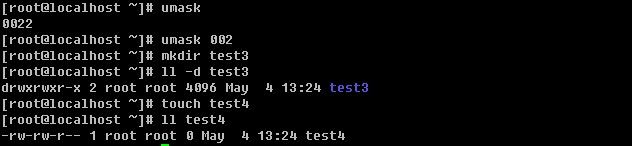
umask 可以在/etc/bashrc里面更改,预设情况下,root的umask为022,而一般使用者则为002,因为可写的权限非常重要,因此预设会去掉写权限。
chattr 修改文件的特殊属性
语法: chattr [+-=][ASaci [文件或者目录名]
+-= :分别为增加、减少、设定
A:增加该属性后,文件或目录的atime将不可被修改;
S:增加该属性后,会将数据同步写入磁盘中;
a:增加该属性后,只能追加不能删除,非root用户不能设定该属性;
c:自动压缩该文件,读取时会自动解压;
i:增加后,使文件不能被删除、重命名、设定连接、写入、新增数据;

增加i属性后不能在该目录中建立文件。

增加a属性后,只能追加不能删除。
lsattr 列出文件/目录的特殊属性
语法: lsattr [-aR] [文件/目录名]
-a:类似与ls 的-a 选项,即连同隐藏文件一同列出;
-R:连同子目录的数据一同列出

在上例中,test4是在test3目录增加a属性后建立的,所以test4也有a属性,通过这个例子可以看出,chattr 的属性是级联生效的,不仅对当前目录生效而且会对目录下的文件同样生效。
【在linux下搜索一个文件】
在windows下有一个搜索工具,可以让我们很快的找到一个文件,这是很有用的。然而在linux下搜索功能更加强大。
which 用来查找可执行文件的绝对路径。
在前面章节中已经多次用到该命令,需要注意的一点是,which只能用来查找PATH环境变量中出现的路径下的可执行文件。这个命令用的也是蛮多的,有时候我们不知道某个命令的绝对路径,which一下很容易就知道了。
![[image]](http://img.e-com-net.com/image/info2/23515b0f025244d9a1711f968cc51219.jpg)
当查找的文件在PATH变量中并没有时,就会报错。
whereis 通过预先生成的一个文件列表库去查找跟给出的文件名相关的文件。
语法: whereis [-bmsu] [文件名称]
-b:只找binary 文件
-m:只找在说明文件manual路径下的文件
-s:只找source来源文件
-u:没有说明档的文件
![[image]](http://img.e-com-net.com/image/info2/c087c86f29ff4537968a1b465d6a0ee2.jpg)
说明:whereis 笔者几乎很少用到,如果你感兴趣请深入研究。
locate 类似于whereis,也是通过查找预先生成的文件列表库来告诉用户要查找的文件在哪里。后边直接跟文件名。如果你的linux没有这个命令,请安装软件包 mlocate ,这个软件包在你的系统安装盘里,后缀名是RPM,随后介绍的find命令会告诉你如何查找这个包。如果你装的CentOS你可以使用这个命令来安装 yum install –y mlocate 。 前提是你的CentOS能连互联网。至于yum这个命令如何使用,到后续章节你自然会明白。如果你刚装上这个命令,初次使用会报错。
![]()
这是因为系统还没有生成那个文件列表库。你可以使用updatedb 命令立即生成(更新)这个库。如果你的服务器上正跑着重要的业务,那么你最好不要去运行这个命令,因为一旦运行,服务器的压力会变大。这个数据库默认情况下每周更新一次。所以你用locate命令去搜索一个文件,正好是在两次更新时间段内,那你肯定是得不到结果的。你可以到/etc/updated.conf 去配置这个数据库生成(更新)的规则。locate命令笔者用的也并不多,所以你只要明白有这么一个东西即可。你用到时再去深究其用法吧。
find 这个搜索工具是笔者用的最多的一个,所以请你务必要熟悉它。
语法: find [路径] [参数] 下面介绍几个笔者经常用的参数
-atime +n :访问或执行时间大于n天的文件
-ctime +n :写入、更改inode属性(例如更改所有者、权限或者连接)时间大于n天的文件
-mtime +n :写入时间大于n天的文件
看到这里,你对这三个time是不是有些晕了,那笔者就先给你介绍一下这三个time属性。
文件的 Access time,atime 是在读取文件或者执行文件时更改的。文件的 Modified time,mtime 是在写入文件时随文件内容的更改而更改的。文件的 Create time,ctime 是在写入文件、更改所有者、权限或链接设置时随 Inode 的内容更改而更改的。 因此,更改文件的内容即会更改 mtime 和 ctime,但是文件的 ctime 可能会在 mtime 未发生任何变化时更改,例如,更改了文件的权限,但是文件内容没有变化。 如何获得一个文件的atime mtime 以及ctime ?
ls -l 命令可用来列出文件的 atime、ctime 和 mtime。
ls -lc filename 列出文件的 ctime
ls -lu filename 列出文件的 atime
ls -l filename 列出文件的 mtime
atime不一定在访问文件之后被修改,因为:使用ext3文件系统的时候,如果在mount的时候使用了noatime参数那么就不会更新atime的信息。而这是加了 noatime 取消了, 不代表真实情況。反正, 這三個 time stamp 都放在 inode 中。若 mtime, atime 修改inode 就一定會改, 既然 inode 改了, 那 ctime 也就跟著要改了。
继续讲find常用的参数。
-name filename 直接查找该文件名的文件,这个使用最多了。
![[image]](http://img.e-com-net.com/image/info2/0be4ab5f69144269aa1d21205170d182.jpg)
-type type :通过文件类型查找。文件类型在前面部分已经简单介绍过,相信你已经大体上了解了。type 包含了 f, b, c, d, l, s 等等。后续的内容还会介绍文件类型的。

【linux的文件系统】
搞计算机的应该都知道windows的系统格式化硬盘时会指定格式,fat 或者 ntfs。而linux的文件系统格式为Ext2,或者Ext3 。早期的linux使用Ext2格式,目前的linux都使用了Ext3。 Ext2文件系统虽然是高效稳定的。但是,随着Linux系统在关键业务中的应用,Linux文件系统的弱点也渐渐显露出来了,因为Ext2文件系统是非日志文件系统。这在关键行业的应用是一个致命的弱点。Ext3文件系统是直接从Ext2文件系统发展而来,Ext3文件系统带有日志功能,可以跟踪记录文件系统的变化,并将变化内容写入日志,写操作首先是对日志记录文件进行操作,若整个写操作由于某种原因 (如系统掉电) 而中断,系统重启时,会根据日志记录来恢复中断前的写操作,而且这个过程费时极短。目前Ext3文件系统已经非常稳定可靠。它完全兼容Ext2文件系统。用户可以平滑地过渡到一个日志功能健全的文件系统中来。这实际上了也是ext3日志文件系统初始设计的初衷。
Linux文件系统在windows中是不能识别的,但是在linux系统中你可以挂载的windows的文件系统,linux目前支持MS-DOS,VFAT,FAT,BSD等格式。如果你使用的是Redhat或者CentOS,那么你不要妄图挂载NFS格式的文件到linux下,因为它不支持NFS。虽然有些版本的linux支持NFS,但不建议使用,因为目前的技术还不成熟。
Ext3文件系统为Redhat/CentOS默认使用的文件系统,除了Ext3文件系统外,有些linux发行版例如SuSE默认的文件系统为reiserFS ,Ext3 独特的优点就是易于转换,很容易在 Ext2 和 Ext3 之间相互转换,而具有良好的兼容性,其它优点 ReiserFS 都有,而且还比它做得更好。如高效的磁盘空间利用和独特的搜寻方式都是Ext3 所不具备的,速度上它也不能和 ReiserFS相媲美,在实际使用过程中,reiserFS 也更加安全高效,据说反删除功能也不错。
ReiserFS 的优势在于,它是基于 B*Tree 快速平衡树这种高效算法的文件系统,例如在处理小于 1k 的文件比 Ext3 快 10 倍。再一个就是 ReiserFS 空间浪费较少,它不会对一些小文件分配 inode,而是打包存放在同一个磁盘块 (簇) 中,Ext2/Ext3 是把它们单独存放在不同的簇上,如簇大小为 4k,那么 2 个 100 字节的文件会占用 2 个簇,ReiserFS 则只占用一个。当然 ReiserFS 也有缺点,就是每升级一个版本,都要将磁盘重新格式化一次。
【linux文件类型】
在前面的内容中简单介绍了普通文件(-),目录(d)等,在linux文件系统中,主要有以下几种类型的文件。
1)正规文件(regular file):就是一般类型的文件,当用ls –l 查看某个目录时,第一个属性为”-“的文件就是正规文件,或者叫普通文件。正规文件又可分成纯文字文件(ascii)和二进制文件(binary)。纯文本文件是可以通过cat, more, less等工具直接查看内容的,而二进制文件并不能。例如我们用的命令/bin/ls 这就是一个二进制文件。
2)目录(directory):这个很容易理解,就是目录,跟windows下的文件夹一个意思,只不过在linux中我们不叫文件夹,而是叫做目录。ls –l 查看第一个属性为”d”。
3)连接档(link):ls –l 查看第一个属性为 “l”,类似windows下的快捷方式。这种文件在linux中很常见,而且笔者在日常的系统运维工作中用的很多,所以你要特意留意一下这种类型的文件。在后续章节笔者会介绍。
4)设备档(device):与系统周边相关的一些档案,通常都集中在 /dev 这个目录之下!通常又分为两种:区块 (block) 设备档 :就是一些储存数据,以提供系统存取的接口设备,简单的说就是硬盘啦!例如你的一号硬盘的代码是 /dev/hda1 等等的档案啦!第一个属性为 “ b “;字符 (character) 设备档 :亦即是一些串行端口的接口设备,例如键盘、鼠标等等!第一个属性为 “ c “。
* linux 文件后缀名
对于后缀名这个概念,相信你不陌生吧。在linux系统中,文件的后缀名并没有具体意义,也就是说,你加或者不加,都无所谓。但是为了容易区分,linux爱好者们都习惯给文件加一个后缀名,这样当用户看到这个文件名时就会很快想到它到底是一个什么文件。例如1.sh, 2.tar.gz, my.cnf, test.zip等等,如果你首次接触这些文件,你也许会感到很晕,没有关系,随着学习的深入,你就会逐渐的了解这些文件了。笔者所列举的几个文件名中1.sh代表它是一个shell script ,2.tar.gz 代表它是一个压缩包,my.cnf 代表它是一个配置文件,test.zip 代表它是一个压缩文件。
另外需要你知道的是,早期Unix系统文件名最多允许14个字符,而新的Unix或者linux系统中,文件名最长可以到达 256 个字符!
【linux中的连接档】
在讲连接档之前,需要你先理解inode的概念。什么是inode呢?这就需要你知道磁盘的整体构造。磁盘是有多个盘片(类似与光盘)重叠在一起构成的,而每个盘片上会有一个可以移动的磁头,这个磁头的作用就是用来读写数据的。磁头并不是一直在动,当磁头固定时,盘片转一圈,这一圈就是一个磁道了。很多个盘片同半径的那一圈的磁道总和称为磁柱。而由圆心向外画出直线,可以得到一个个扇区,如图二所示,一个扇区的物理量大约是 512 bytes ( 约 0.5K )。
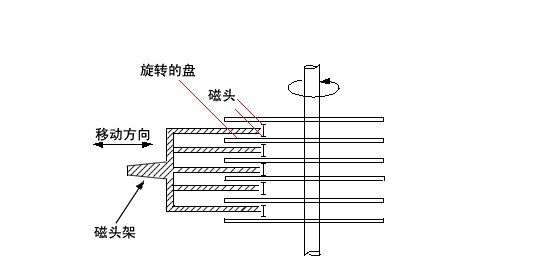
图一

图二
知道了大体的硬盘构造之后,再来谈一谈怎么硬盘分割( partition )呢?我们在进行硬盘分割的时候,最小都是以磁柱为单位进行分割的,那么分割完成之后自然就是格式化( format )啰,在 Linux 里面我们在进行格式化的时候必须要考虑到 Block 与 inode 的信息,这个 block 还好理解,他是我们磁盘可以记录的最小单位,是由数个 sector 所组成的,所以他的大小通常为 n*512 bytes ,例如 4K 。那么 inode 是什么? Block 是记录“档案内容数据”的地区,而 inode 则是记录“该档案的属性、及该档案放置在哪一个 Block 之内”的信息!所以,每个档案都会占用到至少一个 inode 。而当我们 Linux 系统要找到这个档案时,他会先去搜寻 inode table 找到这个档案的属性及数据放置的地区,然后再到数据去找到数据存放的 Block 进而将数据取出利用。这个 inode 数目在一开始就会被设定好,他的设定方式通常是利用 ( 硬盘大小 / 一个容量 ),这个容量至少应该比 Block 要大一些较佳,例如刚刚的 Block 订为 4K ,那么 inode 可以订为 8K 左右。所以,一颗 1GB 的硬盘,如果以 8K 来规划他的 inode 数时,他的 inode 就会有 131072 个 inode 啦!而一个 inode 的大小为 128 bytes 这么大!这么一来的话,我们就可以清楚的知道了,那就是一个 partition 格式化为一个 filesystem 之后,基本上,他一定会有 inode table 与 data area 两个区块,一个用来记录档案的信息与该档案放置的 block 区块,一个用来记录档案的内容!
由于我们 Linux 在读取数据的时候,是先查询 inode table 以得到数据是放在那个 Block 里面,然后再去该 Block 里面读取真正的数据内容!然后,那个 block 是我们在格式化硬盘的时候规定出来的一个值,这个 block 是由 2 的 n 次方个sector 所集结而成的!所以,他是 0.5K 的倍数!假设我们 block 规划为 4KBytes 好了,那么由于一个 inode 与一个block 最多均只纪录一个档案,所以,如果你的一个档案有 0.1 K bytes 这么大时,你要晓得的是,由于你的 block 为 4K bytes ,因此,你就会有 3.9 Kbytes 的空间浪费掉!所以,当你在格式化硬盘的时候,请千万注意到你的系统未来的使用方向。
【ln 建立连接档】
前面提到过两次连接档的概念,现在终于该好好介绍下这部分内容了。连接档分为两种,硬连接(hard link)和软连接(symbolic link)。
Hard Links: 上面内容中说过,当系统要读取一个文件时,就会先去读inode table,然后再去根据inode中的信息到块区域去将数据取出来。而hard link 是直接再建立一个inode连接到文件放置的块区域。也就是说,进行hard link的时候实际上该文件内容没有任何变化,只是增加了一个指到这个文件的inode,不过这样一来就会有个问题,因为增加的inode会连接到块区域,而目录本身仅仅消耗inode而已,那么hard link就不能连接目录了。请你记住,hard link 有两个限制:1 不能跨文件系统,因为不通的文件系统有不同的inode table; 2 不能连接目录。
Symbolic Links:跟hard link不同,这个是建立一个独立的文件,而这个文件的作用是当读取这个连接文件时,它会把读取的行为转发到该文件所link的文件上。这样讲,也许比较绕口,那么就来举一个例子。现在有文件a,我们做了一个软连接文件b(只是一个连接文件,非常小),b指向了文件a。当读取b时,那么b就会把读取的动作转发到a上,这样就读取到了文件a。所以,当你删除文件a时,文件b并不会被删除,但是再读取b时,会提示无法打开文件。而,当你删除b时,a是不会有任何影响的。
看样子,似乎 hard link 比较安全,因为即使某一个 inode 被杀掉了,只要有任何一个 inode 存在,那么该文件就不会不见!不过,不幸的是,由于 Hard Link 的限制太多了,包括无法做目录的 link ,所以在用途上面是比较受限的!反而是 Symbolic Link 的使用方向较广!那么如何建立软连接和硬连接呢?这就用到了ln 命令。
ln 语法: ln [-s] [来源文件] [目的文件]
ln 常用的选项就一个-s ,如果不加就是建立硬连接,加上就建立软连接。
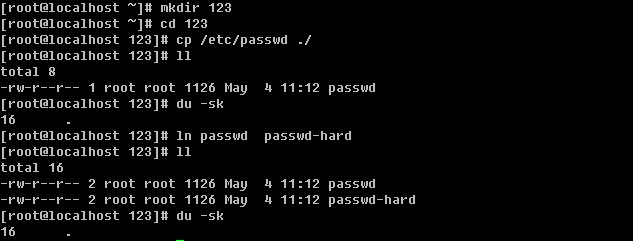
在建立硬连接前后,123目录所占空间大小并没有改变。
![[image]](http://img.e-com-net.com/image/info2/d5c915f08ac441368cd8b50cf9e6b77d.jpg)
当把源文件删除后,空间仍旧没有变化。说明了删除一个文件其实只是删除了inode信息。
![]()
不能创建目录的硬连接。
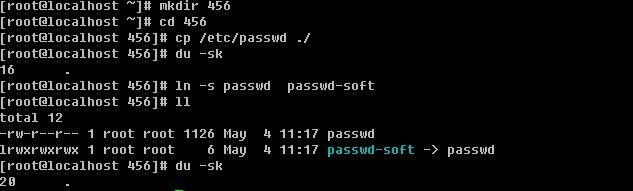
建立软连接后,456目录增加了4k

删除源文件后会提示“没有这个文件”的错误。

目录是可以软连接的。
![[image]](http://img.e-com-net.com/image/info2/da346094979f441796a7d4f17fd9f05d.jpg)
删除软连接对源文件没有任何影响。
【认识/etc/passwd和/etc/shadow】
这两个文件可以说是linux系统中最重要的文件之一。如果没有这两个文件或者这两个文件出问题,则你是无法正常登录linux系统的。

/etc/passwd由’:’分割成7个字段,每个字段的具体含义是:
1)用户名(如第一行中的root就是用户名),代表用户账号的字符串。用户名字符可以是大小写字母、数字、减号(不能出现在首位)、点以及下划线,其他字符不合法。虽然用户名中可以出现点,但不建议使用,尤其是首位为点时,另外减号也不建议使用,因为容易造成混淆。
2)存放的就是该账号的口令,为什么是’x’呢?早期的unix系统口令确实是存放在这里,但基于安全因素,后来就将其存放到/etc/shadow中了,在这里只用一个’x’代替。
3)这个数字代表用户标识号,也叫做uid。系统识别用户身份就是通过这个数字来的,0就是root,也就是说你可以修改test用户的uid为0,那么系统会认为root和test为同一个账户。通常uid的取值范围是0~65535,0是超级用户(root)的标识号,1~499由系统保留,作为管理账号,普通用户的标识号从500开始,如果我们自定义建立一个普通用户,你会看到该账户的标识号是大于或等于500的。
4)表示组标识号,也叫做gid。这个字段对应着/etc/group 中的一条记录,其实/etc/group和/etc/passwd基本上类似。
5)注释说明,该字段没有实际意义,通常记录该用户的一些属性,例如姓名、电话、地址等等。不过,当你使用finger的功能时就会显示这些信息的(稍后做介绍)。
6)用户的家目录,当用户登录时就处在这个目录下。root的家目录是/root,普通用户的家目录则为/home/username,这个字段是可以自定义的,比如你建立一个普通用户test1,要想让test1的家目录在/data目录下,只要修改/etc/passwd文件中test1那行中的该字段为/data即可。
7)shell,用户登录后要启动一个进程,用来将用户下达的指令传给内核,这就是shell。Linux的shell有很多种sh, csh, ksh, tcsh, bash等,而Redhat/CentOS的shell就是bash。查看/etc/passwd文件,该字段中除了/bin/bash外还有/sbin/nologin比较多,它表示不允许该账号登录。如果你想建立一个账号不让他登录,那么就可以把该字段改成/sbin/nologin,默认是/bin/bash。
![[image]](http://img.e-com-net.com/image/info2/8c65fce9facc48aba7fa4c3165e45148.png)
再来看看/etc/shadow这个文件,和/etc/passwd类似,用”:”分割成9个字段。
1)用户名,跟/etc/passwd对应。
2)用户密码,这个才是该账号的真正的密码,不过这个密码已经加密过了,但是有些黑客还是能够解密的。所以为了安全,该文件属性设置为600,只允许root读写。
3)上次更改密码的日期,这个数字是这样计算得来的,距离1970年1月1日到上次更改密码的日期,例如上次更改密码的日期为2012年1月1日,则这个值就是365*(2012-1970)+1=15331。
4)要过多少天才可以更改密码,默认是0,即不限制。
5)密码多少天后到期。即在多少天内必须更改密码,例如这里设置成30,则30天内必须更改一次密码,否则将不能登录系统,默认是99999,可以理解为永远不需要改。
6)密码到期前的警告期限,若这个值设置成7,则表示当7天后密码过期时,系统就发出警告告诉用户,提醒用户他的密码将在7天后到期。
7)账号失效期限。你可以这样理解,如果设置这个值为3,则表示:密码已经到期,然而用户并没有在到期前修改密码,那么再过3天,则这个账号就失效了,即锁定了。
8)账号的生命周期,跟第三段一样,是按距离1970年1月1日多少天算的。它表示的含义是,账号在这个日期前可以使用,到期后账号作废。
9)作为保留用的,没有什么意义。
【新增/删除用户和用户组】
a. 新增一个组 groupadd [-g GID] groupname
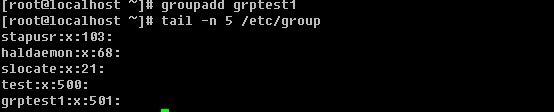
不加-g 则按照系统默认的gid创建组,跟用户一样,gid也是从500开始的

-g选项可以自定义gid
b. 删除组 gropudel groupname
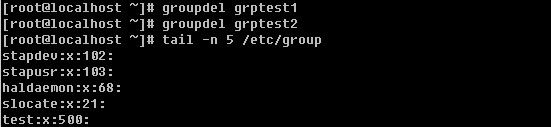
没有特殊选项。
c. 增加用户 useradd [-u UID] [-g GID] [-d HOME] [-M] [-s]
-u 自定义UID
-g 使其属于已经存在的某个GID
-d 自定义用户的家目录
-M 不建立家目录
-s 自定义shell

你会发现,创建test11时,加上了-M选项后,在/etc/passwd文件中test11那行的第六字段依然有/home/test11,可是ls查看该目录时,会提示该目录不存在。
![]()
-M选项的作用就是不创建用户的家目录。
-d. 删除用户 userdel [-r] username
![[image]](http://img.e-com-net.com/image/info2/0ae20b68116d46b1b681bae3762bf987.png)
-r 选项的作用是删除用户时,连同用户的家目录一起删除。
【chfn 更改用户的finger (不常用)】
前面内容中提到了findger,即在/etc/passwd文件中的第5个字段中所显示的信息,那么如何去设定这个信息呢?

就是chfn这个命令了。修改完后,就会在/etc/passwd文件中的test的那一行第五个字段中看到相关信息了,默认是空的。
【创建/修改一个用户的密码 “passwd [username]”】
等创建完账户后,默认是没有设置密码的,虽然没有密码,但该账户同样登录不了系统。只有设置好密码后方可登录系统。
为用户创建密码时,为了安全起见,请尽量设置复杂一些。你可以按照这样的规则来设置密码:a. 长度大于10个字符;b. 密码中包含大小写字母数字以及特殊字符(*&等);c. 不规则性(不要出现root, happy, love, linux, 123456, 111111等等单词或者数字);d. 不要带有自己名字、公司名字、自己电话、自己生日等。

passwd 后面不跟用户名则是更改当前用户的密码,当前用户为root,所以此时修改的是root的密码,后面跟test则修改的是test的密码。
【用户身份切换】
Linux系统中,有时候普通用户有些事情是不能做的,除非是root用户才能做到。这时就需要临时切换到root身份来做事了。
![[image]](http://img.e-com-net.com/image/info2/0afdce99c8544402b0bd3eaca6ed74ca.jpg)
用test账号登录linux系统,然后使用su - 就可以切换成root身份,前提是知道root的密码。
![[image]](http://img.e-com-net.com/image/info2/1ab00472c7e342888da6326e6d27c218.jpg)
你可以使用echo $LOGNAME来查看当前登录的用户名
![[image]](http://img.e-com-net.com/image/info2/9ebb1e82d00d46a8a4771514b8befe87.jpg)
su 的语法为: su [-] username
后面可以跟”-”也可以不跟,普通用户su不加username时就是切换到root用户,当然root用户同样可以su到普通用户。
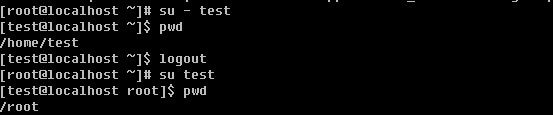
加”-“后会连同用户的环境变量一起切换过来。su test 后虽然切换到了test用户,但是当前目录还是切换前的/root目录,然后当用su - test时切换用户后则到了test的家目录/home/test。当用root切换普通用户时,是不需要输入密码的。这也体现了root用户至高无上的权利。
用su是可以切换用户身份,如果每个普通用户都能切换到root身份,如果某个用户不小心泄漏了root的密码,那岂不是系统非常的不安全?没有错,为了改进这个问题,产生了sudo这个命令。使用sudo执行一个root才能执行的命令是可以办到的,但是需要输入密码,这个密码并不是root的密码而是用户自己的密码。默认只有root用户能使用sudo命令,普通用户想要使用sudo,是需要root预先设定的,即,使用visudo命令去编辑相关的配置文件/etc/sudoers。如果没有visudo这个命令,请使用” yum install -y sudo”安装。
![]()
默认root能够sudo是因为这个文件中有一行” root ALL=(ALL) ALL” 在该行下面加入” test ALL=(ALL) ALL”就可以让test用户拥有了sudo的权利。如果每增加一用户就设置一行,这样太麻烦了。所以你可以这样设置。
![]()
把这一行前面的”

【查看磁盘或者目录的容量 df 和 du】
df 查看已挂载磁盘的总容量、使用容量、剩余容量等,可以不加任何参数,默认是按k为单位显示的
![[image]](http://img.e-com-net.com/image/info2/6578004ac18d460a91518d67bb4cc2ee.jpg)
df常用参数有 –i -h -k –m等
-i 使用inodes 显示结果
![[image]](http://img.e-com-net.com/image/info2/2c00edd64335458fabde928131de76e9.jpg)
-h 使用合适的单位显示,例如G
![[image]](http://img.e-com-net.com/image/info2/daf78063178f4c5a91ab45683f18e659.jpg)
-k -m 分别为使用K,M为单位显示

简单介绍一下,你看到的相关数据。Filesystem 表示扇区,也就是你划分磁盘时所分的区;1K-blocks/1M-blocks表示以1K/1M为单位;Used 和 Available 分别是已使用和剩余;Use% 就是已经使用的百分比,如果这个值大于90% 那么你就应该注意了,磁盘很有可能马上就会变满的;Mounted on 则表示该分区(扇区)所挂载的地方。
du 用来查看某个目录所占空间大小
语法:du [-abckmsh] [文件或者目录名] 常用的参数有:
-a:全部文件与目录大小都列出来。如果不加任何选项和参数只列出目录(包含子目录)大小。

-b:列出的值以bytes为单位输出,默认是以Kbytes
![[image]](http://img.e-com-net.com/image/info2/bef6a704eef64f0fa2f5a38e5b3763e5.jpg)
-c:最后加总
![[image]](http://img.e-com-net.com/image/info2/8e014a3fec6a4340ad89918efd949783.jpg)
-k:以KB为单位输出
-m:以MB为单位输出
-s:只列出总和
-h:系统自动调节单位,例如文件太小可能就几K,那么就以K为单位显示,如果大到几G,则就以G为单位显示。笔者习惯用 du –sh filename 这样的形式。
![[image]](http://img.e-com-net.com/image/info2/dd8ecb52da0144b7b45244fc6e9732a1.jpg)
【磁盘的分区和格式化】
笔者经常做的事情就是拿一个全新的磁盘来分区并格式化。这也说明了作为一个linux系统管理员,对于磁盘的操作必须要熟练。所以请你认真学习该部分内容。
fdisk linux下的硬盘分区工具
语法: fdisk [-l ] [设备名称]
-l :后边不跟设备名会直接列出系统中所有的磁盘设备以及分区表,加上设备名会列出该设备的分区表。
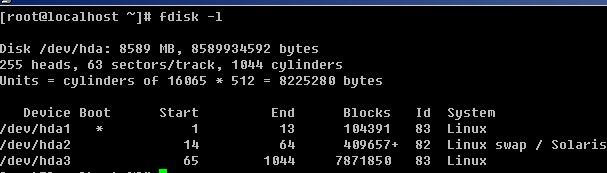

如果不加-l 则进入另一个模式,在该模式下,可以对磁盘进行分区操作。

刚进入该模式下,会有一个提示Command (m for help): 此时按m则会打印出帮助列表,如果你英文好,我想你不难理解这些字母的功能。笔者常用的有p, n,d, w, q.
P:打印当前磁盘的分区情况。

n:重新建立一个新的分区。
w:保存操作。
q:退出。
d:删除一个分区
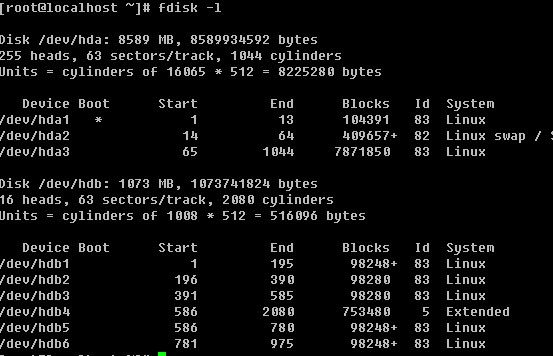
因为笔者的linux系统是安装在虚拟机上的,所以我可以增加一块新的磁盘。然后笔者会把新的磁盘分成多个分区。

当再次fdisk -l 查看时发现多了一个/dev/hdb 设备,并提示该设备没有可用的分区表。那么下面就来分一下这个/dev/hdb.
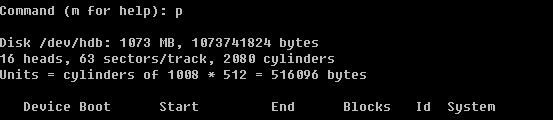
首先用p查看一下,并没有任何分区信息。

用n创建一个新的分区,会提示要建立e (extended 扩展分区)或者p (primary partition主分区),这里笔者选择主分区,所以按了p回车后,又让输入First cylinder 你或者直接回车或者输入一个数字,因为这块磁盘是新的并没有任何分区,所以直接回车其实就是从1开始了。你也可以自定义输入,但不要超过2080,笔者这里输入1回车。此时会提示要分多大,可以写一个数值(2-2080),也可以输入+sizeK或者+sizeM,后者比较直观容易理解,所以笔者在这里输入+100M,即我分了一个100M的主分区。再用p查看时,果真多出来一个分区。然后笔者继续重复前面的操作,建立了4个主分区。当笔者再次输入n创建分区时,结果提示错了。
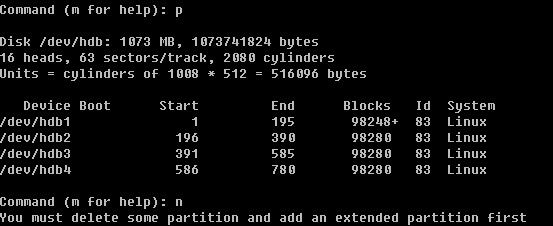
由此你会发现,在linux中最多只能创建4个主分区,那如果你想多创建几个分区如何做?很容易,在创建完第三个分区后,创建第四个分区时选择扩展分区。
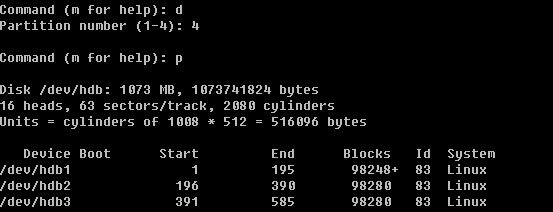 先删除第四个主分区,然后建立一个扩展分区
先删除第四个主分区,然后建立一个扩展分区

在建立扩展分区时,会问你要分多少给这个扩展分区,笔者直接回车,即把所有空间都分给了这个扩展分区。这个扩展分区/dev/hdb4并不能往里写数据,它只是一个空壳子,需要我们继续在这个空壳中继续创建分区。
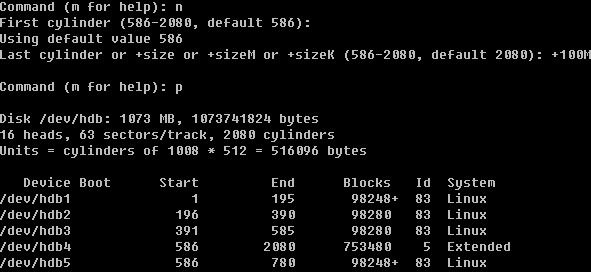
当建立完扩展分区,然后按n创建新分区时你会发现不再提示是要建立p还是e了,因为我们已经不能再创建p了。在这里需要你明白的是,hdb5 其实只是 hdb4 中的一个子分区,到目前为止可用的分区也才4个,那笔者就再创建第5个分区出来。
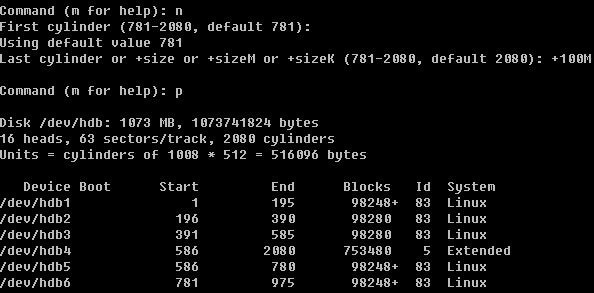
然后按w保存,该模式自动退出,如果你不想保存分区信息直接按q即可退出。
![[image]](http://img.e-com-net.com/image/info2/8d63dda85ffd4210b284817408b9988d.jpg)
下面我们把刚分好的分区删除,重新建立分区。如何删除你还记得吧,对了就是直接按d然后选择合适的数字。删除完所有分区后,这块磁盘就恢复如初了。
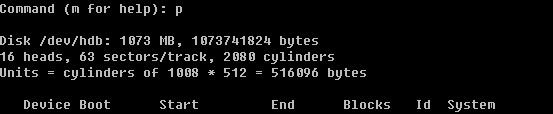
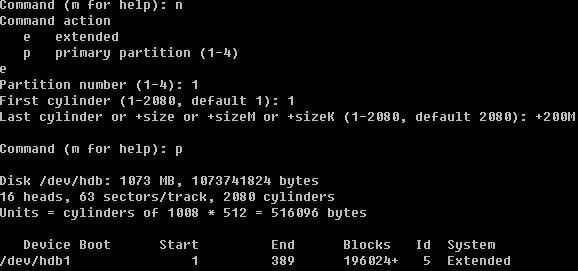
第一个分区,我们就建立成扩展分区。并且分给它200M。
![[image]](http://img.e-com-net.com/image/info2/db311b6ef414435081520e75a3d3dd89.jpg)
当再次新建分区时,发生了变化,不再是p或者e了,而是p或者l(逻辑分区),这是为什么呢?在上面也提到了,一个扩展分区只是一个空壳,在扩展分区下才可以继续划分小的分区,这个小的分区其实就是逻辑分区了。

而且这个逻辑分区默认都是从字数5开始的,因为前面的数字要么给主分区留着,要么给扩展分区留着。由此我们也可以得到,在linux中最多可以创建4个主分区,一旦创建4个主分区后就不能增加任何分区了。另外最多也只能创建一个扩展分区。扩展分区下的逻辑分区最多可以创建多少呢?IDE的硬盘(类似于hda, hdb, hdc 等)最多可以创建10个(hdb5-hdb15),这是笔者试验出来的结果。有的资料说linux下的逻辑分区是没有限制的,也有的说最大可以到64,至于对不对,需要你去近一步考察了,我们没有必要多么深入的研究这个问题,也没有什么意义。
通过以上操作,相信你也学会了用fdisk 来分区了吧。值得提出的是,不要闲着没事分区玩儿,这操作的危险性是很高的,一不留神就把你服务器上的数据全部给分没有了。如果有分区的操作,那么请保持百分之二百的细心,切记切记!
mkfs.ext2 / mkfs.ext3 /mke2fs 格式化linux硬盘分区
当用man查询这三个命令的帮助文档时,你会发现我们看到了同一个帮助文档,这说明三个命令是一样的。常用的选项有:
-b:分区时设定每个数据区块占用空间大小,目前支持1024, 2048 以及4096 bytes每个块。
-i:设定inode大小
-N:设定inode数量,有时使用默认的inode数不够用,所以要自定设定inode数量。
-c:在格式化前先检测一下磁盘是否有问题,加上这个选项后会非常慢
-L:预设该分区的标签label
-j:建立ext3格式的分区,如果使用mkfs.ext3 就不用加这个选项了

不加任何选项,直接格式化/dev/hdb1
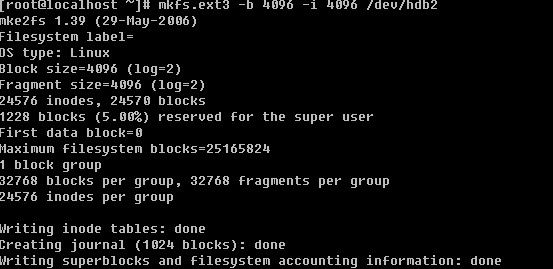
上例中更改了block size为4096 默认是1024,而inode大小设定为4096。
下面的例子分区时自定义分区的label(标签)名。
![[image]](http://img.e-com-net.com/image/info2/aaac6770772143f3a29d790ed8df948a.jpg)
e2label 用来查看或者修改分区的标签(label)
这个命令很简单,后边直接跟分区编号,即可查看该分区的label,当想要修改标签名时,分区编号后边跟想要的标签名即可。

fsck 检查硬盘有没有坏道
语法: fsck [-Aar] [分区]
-A :加该参数时,后不需要跟分区名作为参数。它会自动检查/etc/fstab 文件下的所有分区(开机过程中就会执行一次该操作);
-a :自动修复检查到有问题的分区;
-r :当检查到有坏道的分区时会让用户决定是否修复。

当你使用fsck检查磁盘有无坏道时,会提示用户“跑这个任务可能会导致某些挂载的文件系统损坏”,所以这个命令不要轻易运行。否则真的遇到问题,系统甚至都不能启动了。

【挂载/卸载磁盘】
在上面的内容中讲到了磁盘的分区和格式化,那么格式化完了后,如何去用它呢?这就涉及到了挂载这块磁盘。格式化后的磁盘其实是一个块设备文件,类型为b,也许你会想,既然这个块文件就是那个分区,那么直接在那个文件中写数据不就写到了那个分区中么?当然不行。
在挂载某个分区前需要先建立一个挂载点,这个挂载点是以目录的形式出现的。一旦把某一个分区挂载到了这个挂载点(目录)下,那么再往这个目录写数据使,则都会写到该分区中。这就需要你注意一下,在挂载该分区前,挂载点(目录)下必须是个空目录。其实目录不为空并不影响所挂载分区的使用,但是一旦挂载上了,那么该目录下以前的东西就不能看到了。只有卸载掉该分区后才能看到。
mount 挂载设备
![[image]](http://img.e-com-net.com/image/info2/d0411fbb2fff421e99b9a567d8c14868.png)
先建立/test1 /test2 目录,然后在/test1目录下建立一个1.txt文件。
![]()
把/dev/hdb1分区挂载到/test1目录,然后再查看/test1目录发下,1.txt不存在了。此时往/test1目录下写数据,则会写到/dev/hdb1分区中。在讲mount的-a选项时,我们有必要先了解一下这个文件 /etc/fstab

这个文件是系统启动时,需要挂载的各个分区。第一列就是分区的label;第二列是挂载点;第三列是分区的格式;第四列则是mount的一些挂载参数,等下会详细介绍一下有哪些参数,一般情况下,直接写defaults即可;第五列的数字表示是否被dump备份,是的话这里就是1,否则就是0;第六列是开机时是否自检磁盘,就是刚才讲过的那个fsck检测。1,2都表示检测,0表示不检测,在Redhat中,这个1,2还有个说法,/ 分区必须设为1,而且整个fstab中只允许出现一个1,这里有一个优先级的说法。1比2优先级高,所以先检测1,然后再检测2,如果有多个分区需要开机检测那么都设置成2吧,1检测完了后会同时去检测2。下面该说说第四列中常用到的参数了。
async/sync :async表示和磁盘和内存不同步,系统每隔一段时间把内存数据写入磁盘中,而sync则会时时同步内存和磁盘中数据;
auto/noauto :开机自动挂载/不自动挂载;
default:按照大多数永久文件系统的缺省值设置挂载定义,它包含了rw, suid, dev, exec, auto, nouser,async ;
ro:按只读权限挂载 ;
rw:按可读可写权限挂载 ;
exec/noexec :允许/不允许可执行文件执行,但千万不要把根分区挂载为noexec,那就无法使用系统了,连mount命令都无法使用了,这时只有重新做系统了;
user/nouser :允许/不允许root外的其他用户挂载分区,为了安全考虑,请用nouser ;
suid/nosuid :允许/不允许分区有suid属性,一般设置nosuid ;
usrquota :启动使用者磁盘配额模式,磁盘配额相关内容在后续章节会做介绍;
grquota :启动群组磁盘配额模式;
学完这个/etc/fstab后,我们就可以自己修改这个文件,增加一行来挂载新增分区。例如,笔者增加了这样一行
/dev/hdb1 /test1 ext3 defaults 0 0
那么系统再重启时就会挂载这个分区了。
讲完了/etc/fstab 我们继续回来讲这个mount,mout -a 如果运行了这个命令,则会把/etc/fstab中出现的所有磁盘分区挂载上。所以当你在/etc/fstab文件中增加一行后,你完全可以直接运行mount -a 来挂载你增加的那行,这样就不用重启啦。
你可以使用mount -o 选项来重新挂载一个分区,并同时指定你想要的选项(即上边介绍fstab第六列中那些)
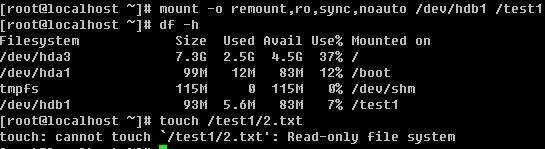
看到了吧,使用了ro选项,则不能新建文件了。
![[image]](http://img.e-com-net.com/image/info2/954b43afeb8242ca95df53e675661e27.jpg)
再重新挂载一次就恢复正常了,如果不加任何其他选项,则就是defaults。
笔者在日常的运维工作中遇到过这样的情况,一台服务器上新装了亮块磁盘,磁盘a(在服务器上显示为sdc)和磁盘b(在服务器上显示为sdd),有一次把这两块磁盘都拔掉了,然后再重新插上,重启机器,结果磁盘编号调换了,a变成了sdd,b变成了sdc(这是因为把磁盘插错了插槽),问题来了。通过上边的学习,你挂载磁盘是通过/dev/hdb1 这样的分区名字来挂载的,如果先前加入到了/etc/fstab 中,结果系统启动后则会挂载错分区。那么怎么样避免这样的情况发生?
blkid 这个命令是用来显示磁盘分区uuid的,uuid其实就是一大串字符,在linux系统中每一个分区都会有唯一的一个uuid。说到这,聪明的你想到了吧,没有错,我们就用这唯一的uuid来挂载磁盘分区。
![[image]](http://img.e-com-net.com/image/info2/8ffdea40b0434d4cb69588c6fdcdf90e.jpg)
这个命令笔者只是用来显示uuid,没有其他用途所以不做详细介绍,当然你也可以在命令后边跟某一个分区,只显示该分区的uuid。

看到了吧,其实是很好用的。那么怎么让它也开机启动?很简单,把刚才敲的mount 磁盘的命令直接写到 /etc/rc.d/rc.local 文件即可。对了,笔者到现在还没有给你讲过这个rc.local文件的作用。简单点说,系统启动完后会执行这个文件中的命令。所以只要你想开机后运行什么命令统统写入到这个文件下面吧。
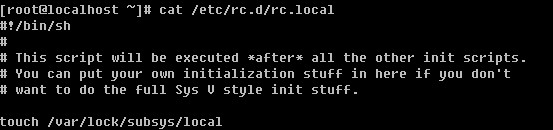
其实这个文件就是一个shell 脚本,以后笔者会单独用一章来介绍它。行开头的”

mount 还有一个比较常用的选项就是-t ,后边指定文件系统的类型,比如挂载软盘时就需要指定 vfat,而挂载光盘时就需要指定iso9660,但在笔者多年来的经验,目前的系统都是智能识别所要挂载分区的系统格式类别的。也就是说,用不着你去指定,它会自动判断的。
![]()
umount 卸载设备
现在你学会了如何挂载一个设备,那么如何去卸载一个设备呢,这就要用到umount了,这个命令也简单的很,后边可以跟挂载点,也可以跟分区名(/dev/hdb1)

有时也许你会遇到比较难卸载的设备,就像在windows下无法删除U盘一样,教你一个特管用的方法就是 umount -l /dev/hdb1 ,这个-l选项有强制卸载的意思,你一定要记住哦,非常有用的。
【建立一个swap文件】
从装系统时就接触过这个swap了,前面也说过它类似与windows的虚拟内存,分区的时候一般大小为内存的2倍,如果你的内存超过4G,那么你分8G似乎是没有必要了。分4G足够日常交换了。然而,还会有虚拟内存不够用的情况发生。如果真遇到了,莫非还要重新分一下磁盘?当然不能!那我们就增加一个虚拟的磁盘出来。
基本的思路就是:建立swapfile &
![[image]](http://img.e-com-net.com/image/info2/c544435269de4c9a91886e15a83f33a3.jpg)
利用dd 来创建一个419M的文件/tmp/newdisk出来,其中if代表从哪个文件读,/dev/zero是linux下特有的一个0生成器,of表示输出到哪个文件,bs即块大小,count则定义有多少个块。
![]()
mkswap 这个命令是专门格式化swap格式的分区的,这个命令用的时候一定要看清楚了,否则把其他分区给格式化错了就只有哭了。
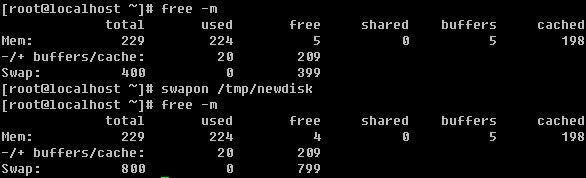
free 是用来查看系统内存以及虚拟内存使用情况的,-m选项是以M的形式查看。可以看到当前系统的。而swapon 是启用我们新建的swap文件,启用后再用free查看发现多了400M。
![[image]](http://img.e-com-net.com/image/info2/13e0db187bcf48ecbd91562ff46ef8ca.jpg)
我们还可以用swapoff 关闭启用的swap文件。
【磁盘配额】
磁盘配合其实就是给每个用户分配一定的磁盘额度,只允许他使用这个额度范围内的磁盘空间。在linux系统中,是多用户多任务的环境,所以会有很多人共用一个磁盘的情况。针对每个用户去限定一定量的磁盘空间是有必要的,这样才显得公平。
在linux中,用来管理磁盘配额的东西就是quota了。如果你的linux上没有quota,则需要你安装这个软件包 quota-3.13-5.el5.RPM (其实版本是多少无所谓了,关键是这个软件包)。quota在实际应用中是针对整个分区进行限制的。如果你的/dev/hda3 是挂载在/home 目录下的,那么/home 所有目录都会受到限制。
quota 这个模块主要分为quota quotacheck quotaoff quotaon quotastats edquota setquota warnquota repquota这几个命令,下面就分别介绍这些命令。
quota 用来显示某个组或者某个使用者的限额。
语法:quota [-guvs] [user,group]
-g :显示某个组的限额
-u :显示某个用户的限额
-v :显示的意思
-s :选择inod或硬盘空间来显示
quotacheck 用来扫描某一个磁盘的quota空间。
语法:quotacheck [-auvg] /path
-a :扫描所有已经mount的具有quota支持的磁盘
-u :扫描某个使用者的文件以及目录
-g :扫描某个组的文件以及目录
-v :显示扫描过程
-m :强制进行扫描
edquota 用来编辑某个用户或者组的quota值。
语法:edquota [-u user] [-g group] [-t]
edquota -p user -u user
-u :编辑某个用户的quota
-g :编辑某个组的quota
-t :编辑宽限时间
-p :拷贝某个用户或组的quta到另一个用户或组
当运行edquota -u user 时,系统会打开一个文件,你会看到这个文件中有7列,它们分别代表的含义是:
Filesystem :磁盘分区,如/dev/hda3
blocks :当前用户在当前的Filesystem中所占用的磁盘容量,单位是Kb。该值请不要修改。
soft/hard :当前用户在该Filesystem内的quota值,soft指的是最低限额,可以超过这个值,但必须要在宽限时间内将磁盘容量降低到这个值以下。hard指的是最高限额,即不能超过这个值。当用户的磁盘使用量高于soft值时,系统会警告用户,提示其要在宽限时间内把使用空间降低到soft值之下。
inodes :目前使用掉的inode的状态,不用修改。
quotaon 启动quta,在编辑好quota后,需要启动才能是quta生效
语法:quotaon [-a] [-uvg directory]
-a :全部设定的quota启动
-u :启动某个用户的quota
-g :启动某个组的quota
-s :显示相关信息
quotaoff 关闭quota
该命令常用只有一种情况 quotaoff -a 关闭全部的quota
以上讲了很多quota的相关命令,那么接下来笔者教你如何在实践应用中去做这个磁盘配额。整个执行过程如下:
首先先确认一下,你的/home目录是不是单独的挂载在一个分区下,用df 查看即可。如果不是则需要你跟我一起做。否则这一步即可省略。
![[image]](http://img.e-com-net.com/image/info2/b21c1604ed2b4e1aa6e1aeccac2191fe.jpg)
笔者的linux系统中,/home并没有单独占用一个分区。所以需要把/home目录挂载在一个单独的分区下,因为quota是针对分区来限额的。
笔者用fdisk -l 查看目前/dev/hdb 磁盘有5个可用分区,所以笔者打算把/dev/hdb1挂载在/home 目录下
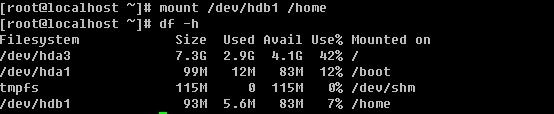
看到了吧,目前笔者的/home目录已经是一个单独的分区了。
1)建立测试用户

首先建立一个test用户,则同时建立了一个test组。可以在/etc/passwd中有以test为开头的行,其中uid和gid都为500 ,然后又建立一个test1账号,使其加入test组,查看/etc/passwd文件发现test和test1用户的gid都为500。(也许你对/etc/passwd文件、增加一个用户以及uid和gid等概念不熟悉,没有关系,在以后的章节中会做介绍,在这里只需要你明白即可)
2)打开磁盘的quota功能
默认linux并没有对任何分区做quota的支持,所以需要我们手动打开磁盘的quota功能,你是否记得,在前面内容中分析/etc/fstab文件的第四列时讲过这个quota选项(usrquota, grpquota)。没错,要想打开这个磁盘的quota支持就是需要修改这个第四列的。用vim编辑/etc/fstab 加入一行,如下图:
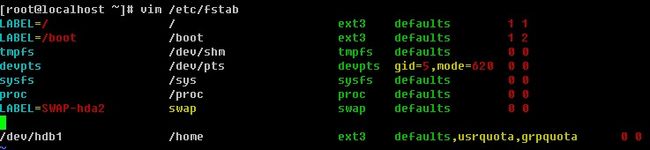
vim命令将会在后续章节详细介绍,前面介绍过如何进入编辑模式以及如何保存文件。如果你的linux系统已经有/home这一行,那么直接修改第四列,加上usrquota,grpguota(中间没有空格)。接下来需要重新挂载/home。

另外你也可以这样实现重新挂载/home
![]()
如何查看是否启用了quota呢?

只要查看/etc/mtab文件中/home所在那行是否有usrguota,grpquota即可。笔者的/dev/hdb1现在已经支持了quota
3)扫描磁盘的使用者使用状况,并产生重要的aquota.group与aquota.user
这一步就需要用到quotacheck了,aquota.group与aqouta.user分别是组以及用户磁盘配额需要的配置文件。如果没有这两个文件,则磁盘配额是不会生效的。

当首次使用quotacheck命令时,会提示“cannot stat old user quota file ……”其实这是在提示你在/home目录下没有aquota.user以及aquota.group两个文件。没有关系,因为以前并没有配置过磁盘配额,当然没有这两个文件了。当执行完quotacheck命令后,会在/home目录下生成这两个文件的。
4)启动quota配额
![[image]](http://img.e-com-net.com/image/info2/eb4eea555c6e4a1ea308e7f42775f562.jpg)
5)编辑用户磁盘配额
先来设定test账户的配额,然后直接把test的配额拷贝给test1即可。这里就需要用到edquota了。
![[image]](http://img.e-com-net.com/image/info2/7576346c52d2425480616a9fde7fa945.jpg)
讲上面内容修改为
![[image]](http://img.e-com-net.com/image/info2/3f2ddd3abce64bb9a39fcb3db257b8a6.jpg)
其中单位是Kb,所以soft 值大约为20Mb,hard值为30Mb,保存这个文件,保存的方式跟vim一个文件的方式一样的。
![]()
将test的配额复制给test1。下面继续设定宽限时间。
![[image]](http://img.e-com-net.com/image/info2/4fd89016878e48448afe1993e0c5632c.jpg)
默认是7days 在这里我们改为1days。下面查看一下test以及test1用户的配额吧。

6)编辑组磁盘配额
![[image]](http://img.e-com-net.com/image/info2/5136637df65c4d569cc45bfe40f9f72e.jpg)
设定组test的soft配额值为40M,hard值为50M。下面查看组test的配额。
![[image]](http://img.e-com-net.com/image/info2/e2f3918397df43d4a1c35cf961657006.jpg)
7)设定开机启动
前面已经讲到启动磁盘配额的命令是quotaon -aug ,所以要想开机启动,只需将这条命令加入到 /etc/rc.d/rc.local文件即可。
![]()
键盘移动 (Move)
一切都从键盘的移动
k -> 上 up
j -> 下 down
h -> 左 left
l -> 右 right
z -> 重画屏幕,当前光标变成屏幕的第一行 (redraw current line at top of window)
CTRL-f -> 跳到下一页 (page down)
CTRL-b -> 跳到上一页 (page up)
跳跃指令 (jumps)
跳跃指令类似于游览器中的<前进><后退>按钮
CTRL-] -> 跟着link/tag转入 (follow link/tag)
CTRL-o -> 回到上一次的jump (go back)
CTRL-i -> 跳回下一个 (go forward)
:ju -> 显示所有的可以跳跃的地方 (print jump list)
重做/回复
u -> undo
CTRL-r -> redo
vim的undo是树结构的,你可以回到这个结构中的任何地方
:undo 2 -> undo 到结构的2层 (undo to tree 2)
:undolist -> 显示所有的undo列表 (show undo list)
:earlier 10s -> undo到10秒前的编辑 (undo to 10 seconds ago)
:earlier 10h -> undo到10小时前的编辑 (back to 10 hours ago)
:earlier 1m -> undo到1分钟前 (back to 1 minutes ago)
下面是undo的tree结构的解释
………..one
…………. |
……..change 1
…………. |
………one too
………. /……..
…..change 2 ……. change 3
………… | ………………… |
…….one two ………. me too
……….. |
….. change 4
………..|
…… not two
视觉模式 (visual)
v -> 进入视觉模式
在视觉模式内可以作block的编辑
CTRL-v -> visual block
打印 (print)
:hardcopy -> 打印vim中的内容 (print text)
混合视觉模式 (visual) 可以选择打印的区域
没试过是否可以直接给值打印(应该可以)例如 :1,15hardcopy 打印前15行
将文件写成网页格式 (html)
:source $VIMRUNTIME/syntax/2html.vim -> change current open file to html
格式 (format)
dos/windows跟unix/linux对于文件的结束是不一样的。vim可以直接设定/更改格式
用纸令:set fileformats=unix,dos 可以改变文件的格式 (change format)
:set ff=unix -> 设定文件成unix格式 (set file in unix format)
:set ff=dos -> 设定文件成dos格式 (set file in dos format)
:set ff? -> 检查当前文件格式 (check the format of current file)
如果改变格式,直接:w存档就会存成新的格式了。
加密 (encryption)
vim可以给文件加密码
vim -x 文件名 (filename) -> 输入2次密码,保存后文件每次都会要密码才能进入 (encrypt the file with password)
vim 处理加密文件的时候,并不会作密码验证,也就是说,当你打开文件的时候,vim不管你输入的密码是否正确,直接用密码对本文进行解密。如果密码错误,你看 到的就会是乱码,而不会提醒你密码错误(这样增加了安全性,没有地方可以得知密码是否正确)当然了,如果用一个够快的机器作穷举破解,vim还是可以揭开的vim
语法显示 (syntax)
:syntax enable -> 打开语法的颜色显示 (turn on syntax color)
:syntax clear -> 关闭语法颜色 (remove syntax color)
:syntax off -> 完全关闭全部语法功能 (turn off syntax)
:syntax manual -> 手动设定语法 (set the syntax manual, when need syntax use :set syntax=ON)
输入特殊字符 (special character)
CTRL-v 编码就可以了
例如 CTRL-v 273 -> ÿ 得到 ÿ
二进 制文件 (binary file)
vim可以显示,编辑2进位文件
vim -b datafile
:set display=uhex -> 这样会以uhex显示。用来显示一些无法显示的字符(控制字符之类)(display in uhex play non-display char)
:%!xxd -> 更改当前文件显示为2进位 (change display to binary)
:%!xxd -r -> 更改二进位为text格式 (convert back to text)
自动完成 (auto-completion)
vim本身有自动完成功能(这里不是说ctag,而是vim内建的)
CTRL-p -> 向后搜索自动完成 (search backward)
CTRL-n -> 向前搜索自动完成 (search forward)
CTRL-x+CTRL-o -> 代码自动补全 (code completion)
自动备份 (backup)
vim可以帮你自动备份文件(储存的时候,之前的文件备份出来)
:set backup -> 开启备份,内建设定备份文件的名字是 源文件名加一个 ‘~’ (enable backup default filename+~)
:set backupext=.bak -> 设定备份文件名为源文件名.bak (change backup as filename.bak)
自动备份有个问题就是,如果你多次储存一个文件,那么这个你的备份文件会被不断覆盖,你只能有最后一次存文件之前的那个备份。没关系,vim还提 供了patchmode,这个会把你第一次的原始文件备份下来,不会改动
:set patchmode=.orig -> 保存原始文件为 文件名.orig (keep orignal file as filename.orig)
开启,保存与退出 (save & exit)
:w -> 保存文件 (write file)
:w! -> 强制保存 (force write)
:q -> 退出文件 (exit file without save)
:q! -> 强制退出 (force quite without save)
:e filename -> 打开一个文件名为filename的文件 (open file to edit)
:e! filename -> 强制打开一个文件,所有未保存的东西会丢失 (force open, drop dirty buffer)
:saveas filename -> 另存为 filename (save file as filename)
编辑指令 (edit)
a -> 在光表后插入 (append after cursor)
A -> 在一行的结尾插入 (append at end of the line)
i -> 在光标前插入 (insert before cursor)
I -> 在第一个非空白字符前插入 (insert before first non-blank)
o -> 光标下面插入一个新行 (open line below)
O -> 光标上面插入一个新行 (open line above)
x -> 删除光标下(或者之后)的东西 (delete under and after cursor)
例如x就是删除当前光标下,3x就是删除光标下+光标后2位字符
X -> 删除光标前的字符 (delete before cursor)
d -> 删除 (delete)
可以用dd删除一行,或者3dw删除3个词等等
J -> 将下一行提到这行来 (join line)
r -> 替换个字符 (replace characters)
R -> 替换多个字符 (replace mode – continue replace)
gr -> 不影响格局布置的替换 (replace without affecting layout)
c -> 跟d键一样,但是删除后进入输入模式 (same as “d” but after delete, in insert mode)
S -> 删除一行(好像dd一样)但是删除后进入输入模式 (same as “dd” but after delete, in insert mode)
s -> 删除字符,跟(d)一样,但是删除后进入输入模式 (same as “d” but after delete, in insert mode)
s4s 会删除4个字符,进入输入模式 (delete 4 char and put in insert mode)
~ -> 更改大小写,大变小,小变大 (change case upper-> lower or lower->upper)
gu -> 变成小写 (change to lower case)
例如 guG 会把光标当前到文件结尾全部变成小写 (change lower case all the way to the end)
gU -> 变成大写 (change to upper case)
例如 gUG 会把光标当前到文件结尾全部变成大写 (change upper case all the way to the end)
复制与粘贴 (copy & paste)
y -> 复制 (yank line)
yy -> 复制当前行 (yank current line)
“{a-zA-Z}y -> 把信息复制到某个寄存中 (yank the link into register {a-zA-Z})
例如我用 “ayy 那么在寄存a,就复制了一行,然后我再用“byw复制一个词在寄存b
粘贴的时候,我可以就可以选择贴a里面的东西还是b里面的,这个就好像是多个复制版一样
“y -> 这个是把信息复制进系统的复制版(可以在其他程序中贴出来)(yank to OS buffer)
p -> 当前光标下粘贴 (paste below)
P -> 当前光标上粘贴 (paste above)
“{a-zA-Z}p -> 将某个寄存的内容贴出来 (paste from register)
例如“ap那么就在当前光标下贴出我之前在寄存a中 的内容。“bP就在当前光标上贴出我之前寄存b的内容
“p -> 从系统的剪贴板中读取信息贴入vim (paste from OS buffer to vim)
reg -> 显示所有寄存中的内容 (list all registers)
书签 (Mark)
书签是vim中非常强大的一个功能,书签分为文件书签跟全局书签。文件书签是你标记文件中的不同位置,然后可以在文件内快速跳转到你想要的位置。 而全局书签是标记不同文件中的位置。也就是说你可以在不同的文件中快速跳转
m{a-zA-Z} -> 保存书签,小写的是文件书签,可以用(a-z)中的任何字母标记。大写的是全局 书签,用大写的(A-Z)中任意字母标记。(mark position as bookmark. when lower, only stay in file. when upper, stay in global)
‘{a-zA-Z} -> 跳转到某个书签。如果是全局书签,则会开启被书签标记的文件跳转至标记的行 (go to mark. in file {a-z} or global {A-Z}. in global, it will open the file)
’0 -> 跳转入现在编辑的文件中上次退出的位置 (go to last exit in file)
” -> 跳转如最后一次跳转的位置 (go to last jump -> go back to last jump)
‘” -> 跳转至最后一次编辑的位置 (go to last edit)
g’{mark} -> 跳转到书签 (jump to {mark})
:delm{marks} -> 删除一个书签 (delete a mark) 例如:delma那么就删除了书签a
:delm! -> 删除全部书签 (delete all marks)
:marks -> 显示系统全部书签 (show all bookmarks)
标志 (tag)
:ta -> 跳转入标志 (jump to tag)
:ts -> 显示匹配标志,并且跳转入某个标志 (list matching tags and select one to jump)
:tags -> 显示所有标志 (print tag list)
运行外部命令 (using an external program)
:! -> 直接运行shell中的一个外部命令 (call any external program)
:!make -> 就直接在当前目录下运行make指令了 (run make on current path)
:r !ls -> 读取外部运行的命令的输入,写入当然vim中。这里读取ls的输出 (read the output of ls and append the result to file)
:3r !date -u -> 将外部命令date -u的结果输入在vim的第三行中 (read the date -u, and append result to 3rd line of file)
:w !wc -> 将vim的内容交给外部指令来处理。这里让wc来处理vim的内容 (send vim’s file to external command. this will send the current file to wc command)
vim对于常用指令有一些内建,例如wc (算字数)(vim has some buildin functions, such like wc)
g CTRL-G -> 计算当前编译的文件的字数等信息 (word count on current buffer)
!!date -> 插入当前时间 (insert current date)
多个文件的编辑 (edit multifiles)
vim可以编辑多个文件,例如
vim a.txt b.txt c.txt 就打开了3个文件
:next -> 编辑下一个文件 (next file in buffer)
:next! -> 强制编辑下个文件,这里指如果更改了第一个文件 (force to next file in buffer if current buffer changed)
:wnext -> 保存文件,编辑下一个 (save the file and goto next)
:args -> 查找目前正在编辑的文件名 (find out which buffer is editing now)
:previous -> 编辑上个文件 (previous buffer)
:previous! -> 强制编辑上个文件,同 :next! (force to previous buffer, same as :next!)
:last -> 编辑最后一个文件 (last buffer)
:first -> 编辑最前面的文件 (first buffer)
:set autowrite -> 设定自动保存,当你编辑下一个文件的时候,目前正在编辑的文件如果改动,将会自动保存 (automatic write the buffer when you switch to next buffer)
:set noautowrite -> 关闭自动保存 (turn autowrite off)
:hide e abc.txt -> 隐藏当前文件,打开一个新文件 abc.txt进行编辑 (hide the current buffer and edit abc.txt)
:buffers -> 显示所有vim中的文件 (display all buffers)
:buffer2 -> 编辑文件中的第二个 (edit buffer 2)
vim中很多东西可以用简称来写,就不用打字那么麻烦了,例如 :edit=:e, :next=:n 这样.
分屏 (split)
vim提供了分屏功能(跟screen里面的split一样)
:split -> 将屏幕分成2个 (split screen)
:split abc.txt -> 将屏幕分成两个,第二个新的屏幕中显示abc.txt的内容 (split the windows, on new window, display abc.txt)
:vsplit -> 竖着分屏 (split vertically)
:{d}split -> 设定分屏的行数,例如我要一个屏幕只有20行,就可以下:20split (split the windows with {d} line. 20split: open new windows with 3 lines)
:new -> 分屏并且在新屏中建立一个空白文件 (split windows with a new blank file)
CTRL-w+j/k/h/l -> 利用CTRL加w加上j/k/h/l在不同的屏内切换 (switch, move between split screens)
CTRL-w+ -/+ -> 增减分屏的大小 (change split size)
CTRL-w+t -> 移动到最顶端的那个屏 (move to the top windows)
CTRL-w+b -> 移动到最下面的屏 (move to bottom window)
:close -> 关闭一个分出来的屏 (close splited screen)
: only -> 只显示光标当前屏 ,其他将会关闭(only display current active screen, close all others )
:qall -> 退出所有屏 (quite all windows)
:wall -> 保存所有屏 (write to all windows)
:wqall -> 保存并退出所有屏 (write and quite all windows)
:qall! -> 退出所有屏,不保存任何变动 (quite all windows without save)
开启文件的时候,利用 -o选项,就可以直接开启多个文件在分屏中 (with -o option from command line, it will open files and display in split mode)
vim -o a.txt b.txt
今天有人说不会看diff,其实vim也可以用来看diff,这个也是属于分屏的部分,这里也写一下。
vimdiff a.txt b.txt 如果直接给 -d选项是一样的 vim -d a.txt b.txt
:diffsplit abc.txt 如果你现在已经开启了一个文件,想vim帮你区分你的文件跟abc.txt有什么区别,可以在vim中用diffsplit的方式打开第二个文件,这个时 候vim会用split的方式开启第二个文件,并且通过颜色,fold来显示两个文件的区别
这样vim就会用颜色帮你区分开2个文件的区别。如果文件比较大(源码)重复的部分会帮你折叠起来(折叠后面会说)
现在来说patch
:diffpatch filename 通过:diffpatch 你的patch的文件名,就可以以当前文件加上你的patch来显示。vim会split一个新的屏,显示patch后的信息并且用颜色标明区别。
如果不喜欢上下对比,喜欢左右(比较符合视觉)可以在前面加vert,例如:
:vert diffsplit abc.txt
:vert diffpatch abc.txt
看完diff,用: only回到原本编辑的文件,觉 得diff的讨厌颜色还是在哪里,只要用:diffoff关闭就好了。
还有个常用的diff中的就是 :diffu 这个是 :diffupdate 的简写,更新用
TAB
除了split之外, vim还可以用 tab
:tab split filename -> 这个就用tab的方式来显示多个文件 (use tab to display buffers)
gt -> 到下一个tab (go to next tab)
gT -> 到上一个tab (go to previous tab)
vim大多数东西都是可一给数字来执行的,tab也是一样
0gt ->跳到第一个tab (switch to 1st tab)
5gt -> 跳到第五个tab (switch to 5th tab)
关闭所有的tab可以使用qall的指令。另外让vim在启动的时候就自动用tabnew的方式来开启多个文件,可以用alias
linux: 添加 alias vim=’vim -p’ 到 ~/.bashrc
windows: 自己写个vim.bat的文件,然后放在path中,文件内容:
@echo off
vim -p %* 当需要更改多个tab中的文件的时候,可以用 :tabdo 这个指令 这个就相当于 loop 到你的所有的 tab 中然后运行指令。
例如有5个文件都在tab里面,需要更改一个变量名称:abc 到 def, 就可以用 :tabdo %s/abc/def/g 这样所有的5个tab里面的abc就都变成def了
折叠 (folding)
vim的折叠功能。。。我记得应该是6版出来的时候才推出的吧。这个对于写程序的人来说,非常有用。
zfap -> 按照段落折叠 (fold by paragraph)
zo -> 打开一个折叠 (open fold)
zc -> 关闭一个折叠 (close fold)
zf -> 创建折叠 (create fold) 这个可以用v视觉模式,可以直接给行数等等
zr -> 打开一定数量的折叠,例如3rz (reduce the folding by number like 3zr)
zm -> 折叠一定数量(之前你定义好的折叠) (fold by number)
zR -> 打开所有的折叠 (open all fold)
zM -> 关闭所有的摺叠 (close all fold)
zn -> 关闭折叠功能 (disable fold)
zN -> 开启折叠功能 (enable fold)
zO -> 将光标下所有折叠打开 (open all folds at the cursor line)
zC -> 将光标下所有折叠关闭 (close all fold at cursor line)
zd -> 将光标下的折叠删除,这里不是删除内容,只是删除折叠标记 (delete fold at cursor line)
zD -> 将光标下所有折叠删除 (delete all folds at the cursor line)
按照tab来折叠,python最好用的 (ford by indent, very useful for python)
:set foldmethod=indent -> 设定后用zm 跟 zr 就可以的开关关闭了 (use zm zr)
保存 (save view)
对于vim来说,如果你设定了折叠,但是退出文件,不管是否保持文件,折叠部分会自动消失的。这样来说非常不方便。所以vim给你方法去保存折 叠,标签,书签等等记录。最厉害的是,vim对于每个文件可以保存最多10个view,也就是说你可以对同一个文件有10种不同的标记方法,根据你的需 要,这些东西都会保存下来。
:mkview -> 保存记录 (save setting)
:loadview -> 读取记录 (load setting)
:mkview 2 -> 保存记录在寄存2 (save view to register 2)
:loadview 3 -> 从寄存3中读取记录 (load view from register 3)
常用指令 (commands)
:set ic ->设定为搜索时不区分大小 写 (search case insensitive)
:set noic ->搜索时区分大小写。 vim内定是这个(case sensitive )
& -> 重复上次的”:s” (repeat previous “:s”)
. -> 重复上次的指令 (repeat last command)
K -> 在man中搜索当前光标下的词 (search man page under cursor)
{0-9}K -> 查找当前光标下man中的章节,例如5K就是同等于man 5 (search section of man. 5K search for man 5)
:history -> 查看命令历史记录 (see command line history)
q: -> 打开vim指令窗口 (open vim command windows)
:e -> 打开一个文件,vim可以开启http/ftp/scp的文件 (open file. also works with http/ftp/scp)
:e http://www.google.com/index.html -> 这里就在vim中打开google的index.html (open google’s index.html)
:cd -> 更换vim中的目录 (change current directory in vim)
:pwd -> 显示vim当前目录 (display pwd in vim)
gf -> 打开文件。例如你在vim中有一行写了#include 那么在abc.h上面按gf,vim就会把abc.h这个文件打开 (look for file. if you have a file with #include , then the cursor is on abc.h press gf, it will open the file abc.h in vim )
记录指令 (record)
q{a-z} -> 在某个寄存中记录指令 (record typed char into register)
q{A-Z} -> 将指令插入之前的寄存器 (append typed char into register{a-z})
q -> 结束记录 (stop recording)
@{a-z} -> 执行寄存中的指令 (execute recording)
@@ -> 重复上次的指令 (repeat previours :@{a-z})
还是给个例子来说明比较容易明白
我现在在一个文件中下qa指令,然后输入itest然后ESC然后q
这里qa就是说把我的指令记录进a寄存,itest实际是分2步,i 是插入 (insert) 写入的文字是 text 然后用ESC退回指令模式q结束记录。这样我就把itest记录再一个寄存了。
下面我执行@a那么就会自动插入test这个词。@@就重复前一个动作,所以还是等于@a
搜索 (search)
vim超级强大的一个功能就是搜索跟替换了。要是熟悉正表达(regular expressions)这个搜索跟后面的替换将会是无敌利器(支持RE的编辑器不多吧)
从简单的说起
# -> 光标下反向搜索关键词 (search the word under cursor backward)
* -> 光标下正向搜索关键词 (search the word under cursor forward)
/ -> 向下搜索 (search forward)
? -> 向上搜索 (search back)
这里可以用 /abc 或 ?abc的方式向上,向下搜索abc
% -> 查找下一个结束,例如在”(“下查找下一个”)”,可以找”()”, “[]” 还有shell中常用的 if, else这些 (find next brace, bracket, comment or #if/#else/#endif)
下面直接用几个例子说话
/a* -> 这个会搜到 a aa aaa
/(ab)* -> 这个会搜到 ab abab ababab
/ab+ -> 这个会搜到 ab abb abbb
/folers= -> 这个会搜到 folder folders
/ab{3,5} -> 这个会搜到 abbb abbbb abbbbb
/ab{-1,3} -> 这个会在abbb中搜到ab (will match ab in abbb)
/a.{-}b -> 这个会在axbxb中搜到axb (match ‘axb’ in ‘axbxb’)
/a.b -> 会搜索到任何a开头后面有b的 (match ab any)
/foo|bar -> 搜索foo或者bar,就是同时搜索2个词 (match ‘foo’ or ‘bar’)
/one|two|three -> 搜索3个词 (match ‘one’, ‘two’ or ‘three’)
/(foo|bar)+ -> 搜索foo, foobar, foofoo, barfoobar等等 (match ‘foo’, ‘foobar’, ‘foofoo’, ‘barfoobar’ … )
/end(if|while|for) -> 搜索endif, endwhile endfor (match ‘endif’, ‘endwhile’, ‘endfor’)
/forever&… -> 这个会在forever中搜索到”for”但是不会在fortuin中搜索到”for” 因为我们这里给了&…的限制 (match ‘for’ in ‘forever’ will not match ‘fortuin’)
特殊字符前面加^就可以 (for special character, user “^” at the start of range)
/”[^"]*”
这里解释一下
” 双引号先引起来 (double quote)
[^"] 任何不是双引号的东西(any character that is not a double quote)
* 所有的其他 (as many as possible)
” 结束最前面的引号 (double quote close)
上面那个会搜到“foo” “3!x”这样的包括引号 (match “foo” -> and “3!x” include double quote)
更多例子,例如搜索车牌规则,假设车牌是 “1MGU103” 也就是说,第一个是数字,3个大写字幕,3个数字的格式。那么我们可以直接搜索所有符合这个规则的字符
(A sample license plate number is “1MGU103″. It has one digit, three upper case
letters and three digits. Directly putting this into a search pattern)
这个应该很好懂,我们搜索
\数字\大写字母\大写字母\大写字母\数字\数字\数字
/\d\u\u\u\d\d\d
另外一个方法,是直接定义几位数字(不然要是30位,难道打30个\u去?)
(specify there are three digits and letters with a count)
/\d\u{3}\d{3}
也可以用范围来搜索 (Using [] ranges)
/[0-9][A-Z]{3}[0-9]{3}
用到范围搜索,列出一些范围(range)
这个没什么好说了,看一下就都明白了,要全部记住。。。用的多了就记住了,用的少了就忘记了。每次看帮助,呵呵
/[a-z]
/[0123456789abcdef] = /[0-9a-f]
\e
\t
\r
\b
简写 (item matches equivalent)
\d digit [0-9]
\D non-digit [^0-9]
\x hex digit [0-9a-fA-F]
\X non-hex digit [^0-9a-fA-F]
\s white space [ ] ( and )
\S non-white characters [^ ] (not and )
\l lowercase alpha [a-z]
\L non-lowercase alpha [^a-z]
\u uppercase alpha [A-Z]
\U non-uppercase alpha [^A-Z]
:help /[] –> 特殊的定义的,可以在vim中用用help来看 (everything about special)
:help /\s –> 普通的也可以直接看一下 (everything about normal)
替换 (string substitute) – RX
替换其实跟搜索是一样的。只不过替换是2个值,一个是你搜索的东西,一个是搜索到之后要替换的 string substitute (use rx)
%s/abc/def/ -> 替换abc到def (substitute abc to def)
%s/abc/def/c -> 替换abc到def,会每次都问你确定(substitute on all text with confirmation (y,n,a,q,l))
1,5s/abc/def/g -> 只替换第一行到第15行之间的abc到def (substitute abc to def only between line 1 to 5)
54s/abc/def/ -> 只替换第54行的abc到def (only substitute abc to def on line 54)
结合上面的搜索正表达式,这个替换功能。。。就十分只强大。linux中很多地方都是用正表达来做事请的,所以学会了受益无穷。
全局 (global)
这个不知道怎么翻译,反正vim是叫做global,可以对搜索到的东西执行一些vim的命令。我也是2-3个星期前因为读log中一些特殊的东 西,才学会用的。 (find the match pater and execute a command)
global具体自行方法是 g/pattern/command
:g/abc/p -> 查找并显示出只有abc的行 (only print line with “abc” )
:g/abc/d -> 删除所有有abc的行 (delete all line with “abc”)
:v/abc/d -> 这个会把凡是不是行里没有abc的都删掉 (delete all line without “abc”)
信息过滤 (filter)
vim又一强大功能
! -> 用!就是告诉vim,执行过滤流程 (tell vim to performing a filter operation)
!5G -> 从光标下向下5行执行过滤程序 (tell vim to start filter under cursor and go down 5 lines)
正式指令开始,这里用sort来做例子:
!5Gsort -> 从光标下开始执行sort,一共执行5行,就是说我只要sort5行而已 (this will sort the text from cursor line down to 5 lines)
!Gsort -k3 -> 可以直接代sort的参数,我要sort文字中的第三段 (sort to the end of file by column 3)
!! -> 值过滤当前的这行 (filter the current line)
如果觉得!这样的方法5G这样的方法用起来别扭(我是这么觉得),可以用标准的命令模式来做
!其实就是个:.,而已 (to type the command)
:.,start,end!sort 这里定义:.,起始行,结束行!运行指令
:.,$!sort -> 从当前这行一直执行至文件结束 (sort from current line to end)
:.0,$!sort -> 从文件的开始第一个行一直执行到文件结束 (sort from start of file to end)
:.10,15!sort -> 只在文件的第10行到第15行之间执行 (sort between line 10 to 15)
在windows下我们接触最多的压缩文件就是.rar格式的了。但在linux下这样的格式是不能识别的,它有自己所特有的压缩工具。但有一种文件在windows和linux下都能使用那就是.zip格式的文件了。压缩的好处不用笔者介绍相信你也晓得吧,它不仅能节省磁盘空间而且在传输的时候还能节省网络带宽呢。
在linux下最常见的压缩文件通常都是以.tar.gz为结尾的,除此之外还有.tar, .gz, .bz2, .zip等等。以前也介绍过linux系统中的后缀名其实要不要无所谓,但是对于压缩文件来讲必须要带上。这是为了判断压缩文件是由哪种压缩工具所压缩,而后才能去正确的解压缩这个文件。以下介绍常见的后缀名所对应的压缩工具。
.gz gzip压缩工具压缩的文件
.bz2 bzip2压缩工具压缩的文件
.tar tar打包程序打包的文件(tar并没有压缩功能,只是把一个目录合并成一个文件)
.tar.gz可以理解为先用tar打包,然后再gzip压缩
.tar.bz2同上,先用tar打包,然后再bzip2压缩
【gzip】
语法:gzip [-d
-d:解压缩时使用
-
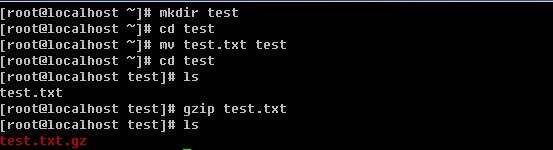
压缩test.txt后,则变成了test.txt.gz
![]()
用-d解压缩
要注意的是,gzip不可以压缩目录
![]()
【bzip2】
语法:bzip2 [-dz] filename
-d:解压缩
-z:压缩
![[image]](http://img.e-com-net.com/image/info2/a4e7093b61c94a62933e995278e5b3f1.jpg)
其实-z参数是可以省略掉的,你不妨试试
![]()
跟gzip的解压类似,也是用-d解压。
【tar】
语法:tar [-zjxcvfpP] filename
-z:是否同时用gzip压缩
-j:是否同时用bzip2压缩
-x:解包或者解压缩
-t:查看tar包里面的文件
-c:建立一个tar包或者压缩文件包
-v:可视化
-f:后面跟文件名,压缩时跟-f文件名,意思是压缩后的文件名为filename,解压时跟-f文件名,意思是解压filename。请注意,如果是多个参数组合的情况下带有-f,请把f写到最后面。
-p:使用原文件的属性,压缩前什么属性压缩后还什么属性。(不常用)
-P:可以使用绝对路径。(不常用)
--exclude filename:在打包或者压缩时,不要将filename文件包括在内。(不常用)

首先在test目录下建立test111目录,然后在test111目录下建立test2.txt,并写入”nihao”到test2.txt中,接着是用tar把test111打包成test111.tar。请记住-f参数后跟的是打包后的文件名。
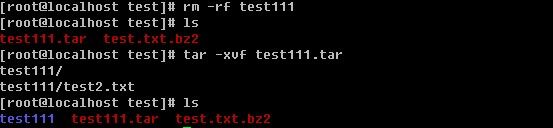
删除原来的test111目录,然后解包test111.tar,不管是打包还是解包,原来的文件是不会删除的。
![[image]](http://img.e-com-net.com/image/info2/f218c40bee714674ad5c2ecea4d3f245.jpg)
打包的同时使用gzip压缩

用-tf跟包名来查看包或者压缩包内的文件都有哪些

先删除test111,然后用tar -zxvf来解压.tar.gz的压缩包。
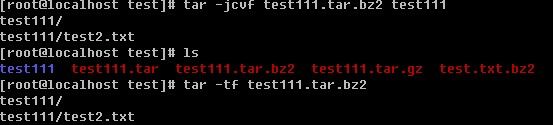
-jcvf打包的同时用bzip2压缩,-tf同样可以查看.tar.bz2的压缩包
![[image]](http://img.e-com-net.com/image/info2/eb2a8e131b8a4920927ed8be64acf86a.jpg)
-jxvf解压缩.tar.bz2的压缩包
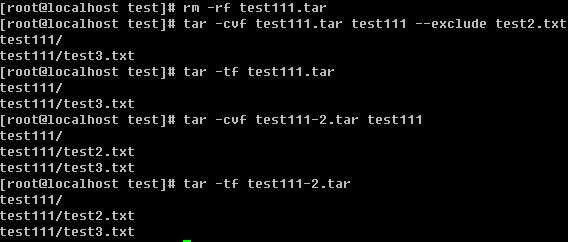
--exclude参数的作用就是打包的时候过滤掉某些文件,如果想过滤多个文件怎么办
![]()
只能是继续跟--exclude filename了
在windows下安装一个软件很轻松,只要双击.exe的文件,安装提示连续“下一步”即可,然而linux系统下安装一个软件似乎并不那么轻松了,因为我们不是在图形界面下。所以你要学会如何在linux下安装一个软件。
在前面的内容中多次提到的yum,这个yum是Redhat所特有的安装RPM程序包的工具,使用起来相当方便。因为使用RPM安装某一个程序包有可能会因为该程序包依赖另一个程序包而无法安装。而使用yum工具就可以连同依赖的程序包一起安装。当然CentOS同样可以使用yum工具,而且在CentOS中你可以免费使用yum,但Redhat中只有当你付费后才能使用yum,默认是无法使用yum的。在介绍yum之前先说一说RPM相关的东西。
【RPM工具】
RPM是”Redhat Package Manager”的缩写,根据名字也能猜到这是Redhat公司开发出来的。RPM是以一种数据库记录的方式来将你所需要的套件安装到你的Linux主机的一套管理程序。也就是说,你的linux系统中存在着一个关于RPM的数据库,它记录了安装的包以及包与包之间依赖相关性。RPM包是预先在linux机器上编译好并打包好的文件,安装起来非常快捷。但是也有一些缺点,比如安装的环境必须与编译时的环境一致或者相当;包与包之间存在着相互依赖的情况;卸载包时需要先把依赖的包卸载掉,如果依赖的包是系统所必须的,那就不能卸载这个包,否则会造成系统崩溃。
如果你的光驱中还有系统安装盘的话,你可以通过”mount /dev/cdrom /mnt”命令把光驱挂载到/mnt目录下,那么你会在/mnt/CentOS目录下看到很多.rpm的文件,这就是RPM包了。
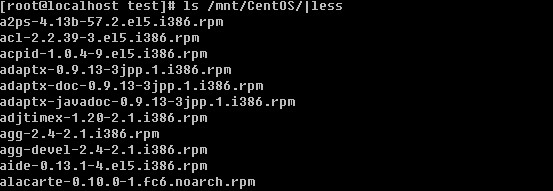
每一个rpm包的名称都由”-“和”.”分成了若干部分。就拿a2ps-4.13b-57.2.el5.i386.rpm这个包来解释一下,1)安装一个rpm包
![]()
-i:安装的意思
-v:可视化
-h:显示安装进度
另外在安装一个rpm包时常用的附带参数有:
--force强制安装,即使覆盖属于其他包的文件也要安装
--nodeps当要安装的rpm包依赖其他包时,即使其他包没有安装,也要安装这个包
2)升级一个rpm包
rpm -Uvh filename -U:即升级的意思
3)卸载一个rpm包
rpm -e filename这里的filename是通过rpm的查询功能所查询到的,稍后会作介绍。
![[image]](http://img.e-com-net.com/image/info2/2ad40ac1bc1b43aeae2951472950b619.jpg)
卸载时后边跟的filename和安装时的是有区别的。上面命令提到的“|”在linux系统中用的非常多也非常有用,它是一个管道符,用来把前面运行的结果传递给后面的命令。以后会做详细介绍,而后出现的grep命令则是用来过滤某个关键词的工具,在后续章节中会做详细介绍。
4)查询一个包是否安装
rpm -q rpm包名(这里的包名,是不带有平台信息以及后缀名的)
![[image]](http://img.e-com-net.com/image/info2/fc48e2e32ea74a678a0edc8e684fd55b.png)
如果加上了平台信息以及后缀名反而不能查出来。你还可以查询当前系统中所安装的所有rpm包。
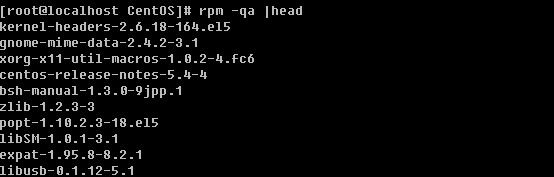
因为太多,所以笔者列出前十个。
5)得到一个rpm包的相关信息
rpm -qi包名(同样不需要加平台信息与后缀名)

6)列出一个rpm包安装的文件
rpm -ql包名
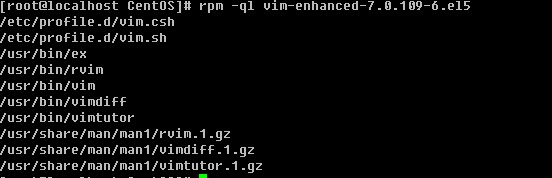
通过上面的命令可以看出vim是通过安装vim-enhanced-7.0.109-6.el5这个rpm包得来的。那么反过来如何通过一个文件去查找是由安装哪个rpm包得来的?
7)列出某一个文件属于哪个rpm包
rpm -qf文件的绝对路径
![]()
前面讲过如何查找一个文件(可执行命令)的绝对路径
![]()
所以你也可以把这两条命令连起来写
![]()
看到了吗,which vim这条命令是由两个反引号引起来的,这代表引用反引号里面的命令所产生的结果。关于rpm工具的使用还有很多内容,笔者就不一一列举了,只要你掌握上面这些内容,完全够你平时工作用的了。
【yum工具】
介绍完rpm工具后,还需要你掌握最常用的yum工具,这个工具比rpm工具好用多了,当然前提是你使用的linux系统是支持yum的。yum最大的优势在于可以联网去下载所需要的rpm包,然后自动安装,在这个工程中如果要安装的rpm包有依赖关系,yum会帮你解决掉这些依赖关系依次安装所有rpm包。下面笔者介绍常用的yum命令。
1)列出所有可用的rpm包“yum list “
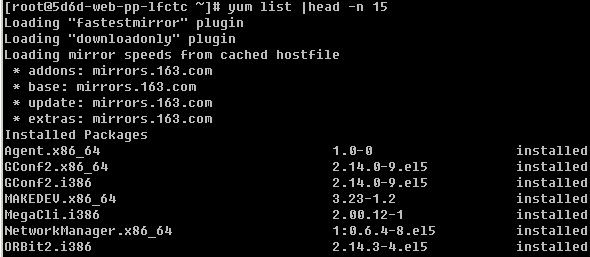
限于篇幅,笔者只列举出来前7个包信息。从上例中可以看到有”mirrors.163.com”信息出现,这是在告诉用户,它是从mirrors.163.com这里下载到的rpm包资源。如果你使用的是CentOS则你可以从/etc/yum.repos.d/CentOS-Base.repo这个文件下看到相关的配置信息。从上面的例子中你还可以看到最左侧是rpm包名字,中间是版本信息,最右侧是安装信息,如果安装了就显示installed,未安装则显示base或者extras,如果是该rpm包已安装但需要升级则显示updates。
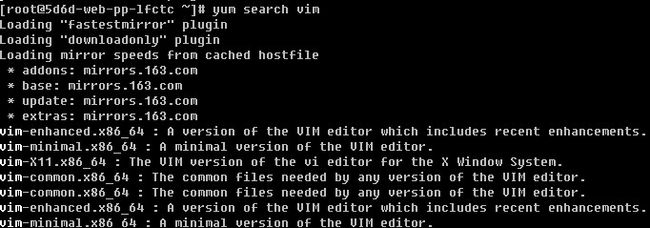
2)搜索一个rpm包“yum search [相关关键词]”
除了这样搜索外,笔者常用的是利用grep来过滤
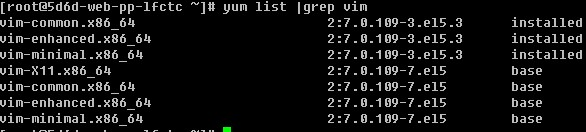
相信你也会喜欢用后者吧,这样看起来简明的多。
3)安装一个rpm包“yum install [-y] [rpm包名]”
如果不加-y选项,则会以与用户交互的方式安装,首先是列出需要安装的rpm包信息,然后会问用户是否需要安装,输入y则安装,输入n则不安装。而笔者嫌这样太麻烦,所以直接加上-y选项,这样就省略掉了问用户是否安装的那一步。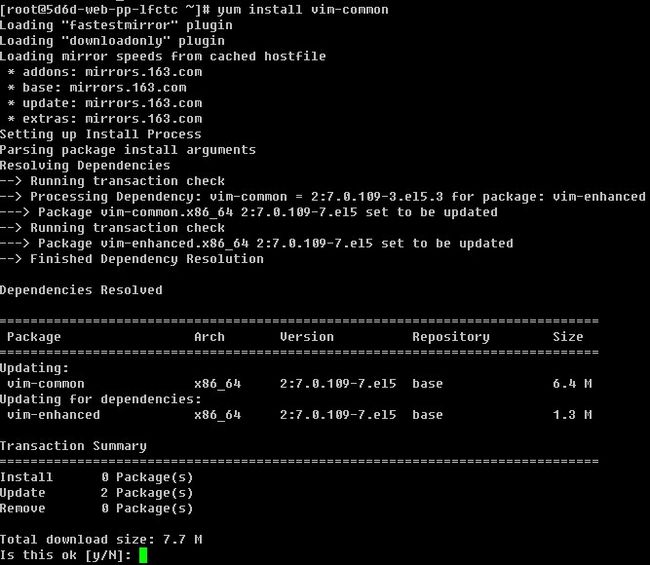
4)卸载一个rpm包“yum remove [-y] [rpm包名]”
卸载和安装一样,你也可以直接加上-y选项来省略掉和用户交互的步骤。在这里笔者要提醒你一下,卸载某个rpm包一定要看清楚了,不要连其他重要的rpm包一起卸载了,以免影响正常的业务。
4)升级一个rpm包“yum update [-y] [rpm包]”

以上介绍了如何使用yum搜索、安装、卸载以及升级一个rpm包,如果你掌握了这些那么你就已经可以解决日常工作中遇到的与rpm包相关问题了。当然yum工具还有好多其他好用的命令,笔者不在列举出来,如果你感兴趣就去man一下吧。除此之外,笔者还会教你一些关于yum的小应用。
1使用本地的光盘来制作一个yum源
有时候你的linux系统不能联网,当然就不能很便捷的使用联网的yum源了,这时候就需要你自己会利用linux系统光盘制作一个yum源。具体步骤如下:
a.挂载光盘
[root@fortest Server]
b.删除/etc/yum.repos.d目录所有的repo文件
[root@fortest Server]
c.创建新文件dvd.repo
[root@fortest Server]
加入以下内容:
[dvd]
name=install dvd
baseurl=file:///mnt
enabled=1
gpgcheck=0
d.刷新repos,生成缓存
[root@fortest Server]
然后就可以使用yum命令安装你所需要的软件包了
2利用yum工具下载一个rpm包
有时,我们需要下载一个rpm包,只是下载下来,拷贝给其他机器使用,前面也介绍过yum安装rpm包的时候,首先得下载这个rpm包然后再去安装,所以使用yum完全可以做到只下载而不安装。
a.首选要安装yum-downloadonly
b.下载一个rpm包而不安装
c.下载到指定目录
【安装源码包】
其实,在linux下面安装一个源码包是最常用的,笔者在日常的管理工作中,大部分软件都是通过源码安装的。安装一个源码包,是需要我们自己把源代码编译成二进制的可执行文件。如果你读得懂这些源代码,那么你就可以去修改这些源代码自定义功能,然后再去编译成你想要的。使用源码包的好处除了可以自定义修改源代码外还可以定制相关的功能,因为源码包在编译的时候是可以附加额外的选项的。
源码包的编译用到了linux系统里的编译器,常见的源码包一般都是用C语言开发的,这也是因为C语言为linux上最标准的程序语言。Linux上的C语言编译器叫做gcc,利用它就可以把C语言变成可执行的二进制文件。所以如果你的机器上没有安装gcc就没有办法去编译源码。你可以使用yum install -y gcc来完成安装。
安装一个源码包,通常需要三个步骤:
1. ./config在这一步可以定制功能,加上相应的选项即可,具有有什么选项可以通过”./config --help ”命令来查看。在这一步会自动检测你的linux系统与相关的套件是否有编译该源码包时需要的库,因为一旦缺少某个库就不能完成编译。只有检测通过后才会生成一个Makefile文件。
2. make使用这个命令会根据Makefile文件中预设的参数进行编译,这一步其实就是gcc在工作了。
3. make install安装步骤,生成相关的软件存放目录和配置文件的过程。
上面介绍的3步并不是所有的源码包软件都一样的,笔者以前也曾经遇到过,安装步骤并不是这样,也就是说源码包的安装并非具有一定的标准安装步骤。这就需要你拿到源码包解压后,然后进入到目录找相关的帮助文档,通常会以INSTALL或者README为文件名。所以,你一定要去看一下。下面笔者会编译安装一个源码包来帮你更深刻的去理解如何安装源码包。
1.下载一个源码包
![[image]](http://img.e-com-net.com/image/info2/113354527bdb4abca0fe13e6e75ddc3d.jpg)
这里要提一下,建议以后你把所有下载的源码包放到/usr/local/src/目录下,这个并不是必须的,只是一个约定。方便你和你的同事将来更好的去运维这台服务器。wget即为下载的命令,后边跟源码包的下载地址。该地址为笔者从网上找的一个apache的下载地址。
2.解压源码包
![]()
一般的源码包都是一个压缩包,如何解压一个.tar.gz的包上一章讲过的。
3.配置相关的选项,并生成Makefile

使用./config --help可以查看可用的选项。一般常用的有”--prefix=PREFIX “这个选项的意思是定义软件包安装到哪里。到这里,笔者再提一个小小的约定,通常源码包都是安装在/usr/local/目录下的。比如,我们把apache安装在/usr/local/apache2下,那么这里就应该这样写” --prefix=/usr/local/apache2”。其他还有好多选项,如果你有耐心你可以挨个去看一看都有什么作用。
![]()
笔者在这里只定义了apache的安装目录,其他都是默认。回车后,开始执行check操作。
等check结束后生成了Makefile文件
![]()
除了查看有没有生成Makefile文件来判定有没有完成./config的操作外,还可以通过这个命令”echo $?”来判定,如果是0,则表示上一步操作成功完成,否则就是没有成功。
![]()
4.进行编译

这一步操作,就是把源代码编译成二进制的可执行文件,这一步也是最漫长的一步,编译时间的长短取决于源代码的多少和机器配置。
5.安装
![]()
在安装前,先确认上一步操作是否成功完成。

make install会创建相应的目录以及文件。当完成安装后,会在/usr/local目录下多了一个apache2目录,这就是apache所安装的目录了。
![]()
其实在日常的源码安装工作中,并不是每个都像笔者这样顺利完成安装的,遇到错误不能完成安装的情况是很多的。通常都是因为缺少某一个库文件导致的。这就需要你仔细琢磨报错信息或者查看当前目录下的config.log去得到相关的信息。另外,如果自己不能解决那就去网上google一下吧,通常你会得到你想要的答案。
日常的linux系统管理工作中必不可少的就是shell脚本,如果不会写shell脚本,那么你就不算一个合格的管理员。目前很多单位在招聘linux系统管理员时,shell脚本的编写是必考的项目。有的单位甚至用shell脚本的编写能力来衡量这个linux系统管理员的经验是否丰富。笔者讲这些的目的只有一个,那就是让你认真对待shell脚本,从一开始就要把基础知识掌握牢固,然后要不断的练习,只要你shell脚本写的好,相信你的linux求职路就会轻松的多。笔者在这一章中并不会多么详细的介绍shell脚本,而只是带你进入shell脚本的世界,如果你很感兴趣那么请到网上下载相关的资料或者到书店购买相关书籍吧。
在学习shell 脚本之前,需要你了解很多关于shell的知识,这些知识是编写shell脚本的基础,所以希望你能够熟练的掌握。
【什么是shell】
简单点理解,就是系统跟计算机硬件交互时使用的中间介质,它只是系统的一个工具。实际上,在shell和计算机硬件之间还有一层东西那就是系统内核了。打个比方,如果把计算机硬件比作一个人的躯体,而系统内核则是人的大脑,至于shell,把它比作人的五官似乎更加贴切些。回到计算机上来,用户直接面对的不是计算机硬件而是shell,用户把指令告诉shell,然后shell再传输给系统内核,接着内核再去支配计算机硬件去执行各种操作。
笔者接触的linux发布版本(Redhat/CentOS)系统默认安装的shell叫做bash,即Bourne Again Shell,它是sh(Bourne Shell)的增强版本。Bourn Shell 是最早行起来的一个shell,创始人叫Steven Bourne,为了纪念他所以叫做Bourn Shell,检称sh。那么这个bash有什么特点呢?
1)记录命令历史
我们敲过的命令,linux是会有记录的,预设可以记录1000条历史命令。这些命令保存在用户的家目录中的.bash_history文件中。有一点需要你知道的是,只有当用户正常退出当前shell时,在当前shell中运行的命令才会保存至.bash_history文件中。
与命令历史有关的有一个有意思的字符那就是”!”了。常用的有这么几个应用:(1)!! (连续两个”!”),表示执行上一条指令;(2)!n(这里的n是数字),表示执行命令历史中第n条指令,例如”!100”表示执行命令历史中第100个命令;(3)!字符串(字符串大于等于1),例如!ta,表示执行命令历史中最近一次以ta为开头的指令。

2)指令和文件名补全
在本教程最开始笔者就介绍过这个功能了,记得吗?对了就是按tab键,它可以帮你补全一个指令,也可以帮你补全一个路径或者一个文件名。连续按两次tab键,系统则会把所有的指令或者文件名都列出来。
3)别名
前面也出现过alias的介绍,这个就是bash所特有的功能之一了。我们可以通过alias把一个常用的并且很长的指令别名一个简洁易记的指令。如果不想用了,还可以用unalias解除别名功能。直接敲alias会看到目前系统预设的alias :

看到了吧,系统预设的alias指令也就这几个而已,你也可以自定义你想要的指令别名。alias语法很简单,alias [命令别名]=[’具体的命令’]。
4)通配符
在bash下,可以使用*来匹配零个或多个字符,而用?匹配一个字符。
![[image]](http://img.e-com-net.com/image/info2/4625dee343f6492c91316361eb9be92f.jpg)
5)输入输出从定向
输入重定向用于改变命令的输入,输出重定向用于改变命令的输出。输出重定向更为常用,它经常用于将命令的结果输入到文件中,而不是屏幕上。输入重定向的命令是<,输出重定向的命令是>,另外还有错误重定向2>,以及追加重定向>>,稍后会详细介绍。
6)管道符
前面已经提过过管道符”|”,就是把前面的命令运行的结果丢给后面的命令。
7)作业控制。
当运行一个进程时,你可以使它暂停(按Ctrl+z),然后使用fg命令恢复它,利用bg命令使他到后台运行,你也可以使它终止(按Ctrl+c)。
【变量】
前面章节中笔者曾经介绍过环境变量PATH,这个环境变量就是shell预设的一个变量,通常shell预设的变量都是大写的。变量,说简单点就是使用一个较简单的字符串来替代某些具有特殊意义的设定以及数据。就拿PATH来讲,这个PATH就代替了所有常用命令的绝对路径的设定。因为有了PATH这个变量,所以我们运行某个命令时不再去输入全局路径,直接敲命令名即可。你可以使用echo命令显示变量的值。

除了PATH, HOME, LOGNAME外,系统预设的环境变量还有哪些呢?
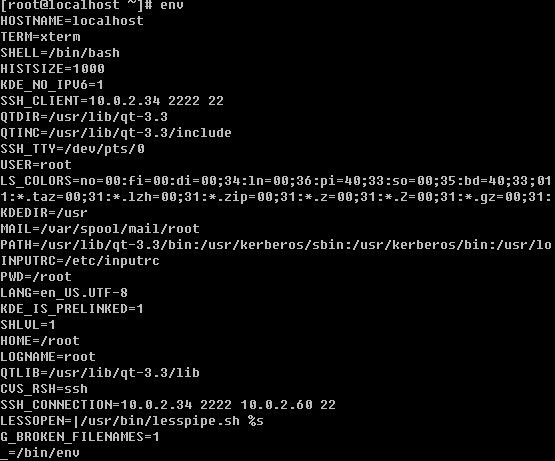
使用env命令即可全部列出系统预设的全部系统变量了。不过登录的用户不一样这些环境变量的值也不一样。当前显示的就是root这个账户的环境变量了。下面笔者简单介绍一下常见的环境变量:
PATH 决定了shell将到哪些目录中寻找命令或程序
HOME 当前用户主目录
HISTSIZE 历史记录数
LOGNAME 当前用户的登录名
HOSTNAME 指主机的名称
SHELL 前用户Shell类型
LANG 语言相关的环境变量,多语言可以修改此环境变量
MAIL 当前用户的邮件存放目录
PWD 当前目录
env命令显示的变量只是环境变量,系统预设的变量其实还有很多,你可以使用set命令把系统预设的全部变量都显示出来。
限于篇幅,笔者在上例中并没有把所有显示结果都截图。set不仅可以显示系统预设的变量,也可以连同用户自定义的变量显示出来。用户自定义变量?是的,用户自己同样可以定义变量。
![[image]](http://img.e-com-net.com/image/info2/eb7695e2200a446eb52cf262364b9473.jpg)
虽然你可以自定义变量,但是该变量只能在当前shell中生效,不信你再登录一个shell试试?
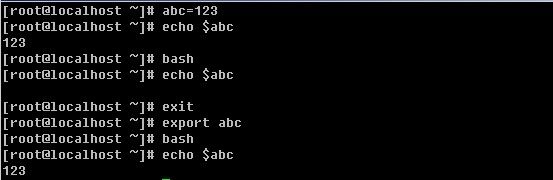
![[image]](http://img.e-com-net.com/image/info2/74f26312ef2e4ba4a98d379577283c8a.jpg)
使用bash命令即可再打开一个shell,此时先前设置的myname变量已经不存在了,退出当前shell回到原来的shell,myname变量还在。那要想设置的变量一直生效怎么办?有两种情况:
1) 要想系统内所有用户登录后都能使用该变量
需要在/etc/profile文件最末行加入 “export myname=Aming” 然后运行”source /etc/profile”就可以生效了。此时你再运行bash命令或者直接su - test账户看看。

2)只想让当前用户使用该变量
需要在用户主目录下的.bashrc文件最后一行加入“export myname=Aming” 然后运行”source .bashrc”就可以生效了。这时候再登录test账户,myname变量则不会生效了。上面用的source命令的作用是,讲目前设定的配置刷新,即不用注销再登录也能生效。
笔者在上例中使用”myname=Aming”来设置变量myname,那么在linux下设置自定义变量有哪些规则呢?
a. 设定变量的格式为”a=b”,其中a为变量名,b为变量的内容,等号两边不能有空格;
b. 变量名只能由英、数字以及下划线组成,而且不能以数字开头;
c. 当变量内容带有特殊字符(如空格)时,需要加上单引号;
![[image]](http://img.e-com-net.com/image/info2/78df045db39e47b0b8e9325a14b1e6e1.jpg)
有一种情况,需要你注意,就是变量内容中本身带有单引号,这就需要用到双引号了。
![[image]](http://img.e-com-net.com/image/info2/02d0674c109e4b31a2ed0360e3cf5338.jpg)
d. 如果变量内容中需要用到其他命令运行结果则可以使用反引号;
![]()
e. 变量内容可以累加其他变量的内容,需要加双引号;
![[image]](http://img.e-com-net.com/image/info2/63a5660a4eb842979f42d05f88a12116.jpg)
在这里如果你不小心把双引号加错为单引号,将得不到你想要的结果
![[image]](http://img.e-com-net.com/image/info2/938da54a4b3e41ba9d52e13d98a4ab00.jpg)
通过上面几个例子也许你能看得出,单引号和双引号的区别:用双引号时不会取消掉里面出现的特殊字符的本身作用(这里的$),而使用单引号则里面的特殊字符全部失去它本身的作用。
在前面的例子中笔者多次使用了bash命令,如果在当前shell中运行bash指令后,则会进入一个新的shell,这个shell就是原来shell的子shell了,不妨你用pstree指令来查看一下。
![[image]](http://img.e-com-net.com/image/info2/c2d35d44a5b04e5b892a2be783c319a1.jpg)
pstree这个指令会把linux系统中所有进程通过树形结构打印出来。限于篇幅笔者没有全部列出,你可以直接输入pstree查看即可。在父shell中设定一个变量后,进入子shell后该变量是不会生效的,如果想让这个变量在子shell中生效则要用到export指令,笔者曾经在前面用过。
export其实就是声明一下这个变量的意思,让该shell的子shell也知道变量abc的值是123.如果export后面不加任何变量名,则它会声明所有的变量。
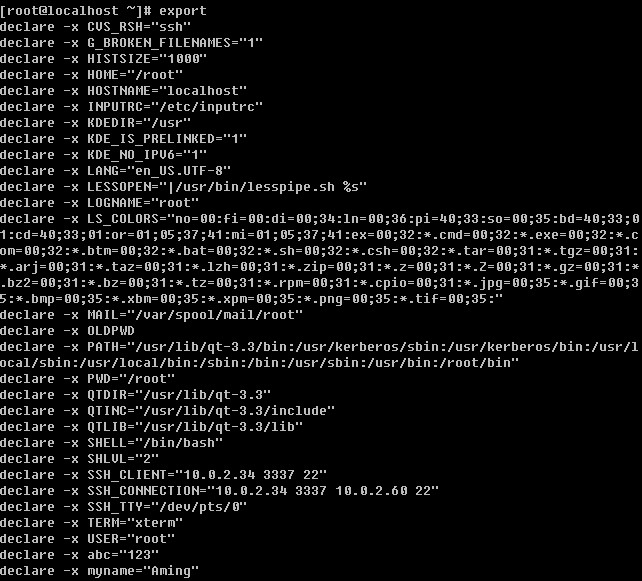
在最后面连同我们自定义的变量都被声明了。
前面光讲如何设置变量,如果想取消某个变量怎么办?只要输入”unset 变量名”即可。
![[image]](http://img.e-com-net.com/image/info2/f4579ea635f94a6994fb839fa25f46b8.jpg)
用unset abc后,再echo $abc则不再输出任何内容。
【系统环境变量与个人环境变量的配置文件】
上面讲了很多系统的变量,那么在linux系统中,这些变量被存到了哪里呢,为什么用户一登陆shell就自动有了这些变量呢?
/etc/profile :这个文件预设了几个重要的变量,例如PATH, USER, LOGNAME, MAIL, INPUTRC, HOSTNAME, HISTSIZE, umas等等。
/etc/bashrc :这个文件主要预设umask以及PS1。这个PS1就是我们在敲命令时,前面那串字符了,例如笔者的linux系统PS1就是 [root@localhost ~]
![]()
\u就是用户,\h 主机名, \W 则是当前目录,\$就是那个’
除了两个系统级别的配置文件外,每个用户的主目录下还有几个这样的隐藏文件:
.bash_profile :定义了用户的个人化路径与环境变量的文件名称。每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次。
.bashrc :该文件包含专用于你的shell的bash信息,当登录时以及每次打开新的shell时,该该文件被读取。例如你可以将用户自定义的alias或者自定义变量写到这个文件中。
.bash_history :记录命令历史用的。
.bash_logout :当退出shell时,会执行该文件。可以把一些清理的工作放到这个文件中。
【linux shell中的特殊符号】
你在学习linux的过程中,也许你已经接触过某个特殊符号,例如”*”,它是一个通配符号,代表零个或多个字符或数字。下面笔者就说一说常用到的特殊字符。
1. * :代表零个或多个字符或数字。
![]()
test后面可以没有任何字符,也可以有多个字符,总之有或没有都能匹配出来。
2. ? :只代表一个任意的字符
![[image]](http://img.e-com-net.com/image/info2/48efd4002abb4fb790eb8ab142065526.jpg)
不管是数字还是字母,只要是一个都能匹配出来。
3.
![[image]](http://img.e-com-net.com/image/info2/94392a8f516d4e94b17424f3df634aec.jpg)
在命令的开头或者中间插入”
4. \ :脱意字符,将后面的特殊符号(例如”*” )还原为普通字符。
![]()
5. | :管道符,前面多次说过,它的作用在于将符号前面命令的结果丢给符号后面的命令。这里提到的后面的命令,并不是所有的命令都可以的,一般针对文档操作的命令比较常用,例如cat, less, head, tail, grep, cut, sort, wc, uniq, tee, tr, split, sed, awk等等,其中grep, sed, awk为正则表达式必须掌握的工具,在后续内容中详细介绍。
6. $ :除了用于变量前面的标识符外,还有一个妙用,就是和’!’结合起来使用。
![[image]](http://img.e-com-net.com/image/info2/ff9c6b4fba474bc08bcfa0615e188518.png)
‘!$’表示上条命中中最后一个变量(也许称为变量不合适,总之就是上条命令中最后出现的那个东西)例如上边命令最后是test.txt那么在当前命令下输入!$则代表test.txt。
1)grep :过滤一个或多个字符,将会在后续内容中详细介绍其用法。
![[image]](http://img.e-com-net.com/image/info2/0ced34cfec064a36ae8c3119e8f6252c.jpg)
2) cut :截取某一个字段
语法:cut -d “分隔字符” [-cf] n 这里的n是数字
-d :后面跟分隔字符,分隔字符要用双引号括起来
-c :后面接的是第几个字符
-f :后面接的是第几个区块
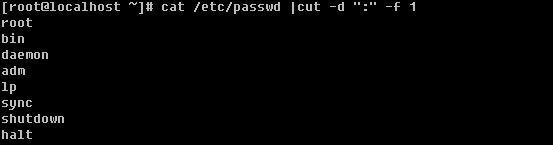
-d 后面跟分隔字符,这里使用冒号作为分割字符,-f 1 就是截取第一段,-f和1之间的空格可有可无。

-c 后面可以是1个数字n,也可以是一个区间n1-n2,还可以是多个数字n1,n2,n3
![[image]](http://img.e-com-net.com/image/info2/35692c7550894befb087a63fbdf3d767.jpg)
3) sort :用做排序
语法:sort [-t 分隔符] [-kn1,n2] [-nru] 这里的n1 < n2
-t 分隔符 :作用跟cut的-d一个意思
-n :使用纯数字排序
-r :反向排序
-u :去重复
-kn1,n2 :由n1区间排序到n2区间,可以只写-kn1,即对n1字段排序
![[image]](http://img.e-com-net.com/image/info2/71cb8e3627b64ca09754cc2f517f6241.jpg)

![[image]](http://img.e-com-net.com/image/info2/6fa6272d0dc64d37ba0a5d2d3f116dfa.jpg)
4) wc :统计文档的行数、字符数、词数,常用的选项为:
-l :统计行数
-m :统计字符数
-w :统计词数
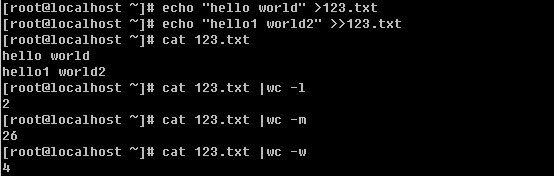
5) uniq :去重复的行,笔者常用的选项只有一个:
-c :统计重复的行数,并把行数写在前面

有一点需要注意,在进行uniq之前,需要先用sort排序然后才能uniq,否则你将得不到你想要的,笔者上面的试验当中已经是排序过所以省略掉那步了。
6)tee :后跟文件名,类似与重定向”>”,但是比重定向多了一个功能,在把文件写入后面所跟的文件中的同时,还显示在屏幕上。
![[image]](http://img.e-com-net.com/image/info2/6f7ee9168e03418699a1c44a6c5c0225.jpg)
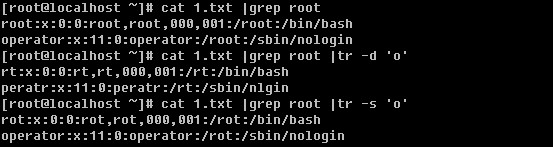
7)tr :替换字符,常用来处理文档中出现的特殊符号,如DOS文档中出现的^M符号。常用的选项有两个:
-d :删除某个字符,-d 后面跟要删除的字符
-s :把重复的字符去掉
最常用的就是把小写变大写: tr ‘[a-z]’ ‘[A-Z]’
![]()
当然替换一个字符也是完全可以的。

不过替换、删除以及去重复都是针对一个字符来讲的,有一定局限性。如果是针对一个字符串就不再管用了,所以笔者建议只是简单了解这个tr即可,以后你还会学到更多可以实现针对字符串操作的工具。
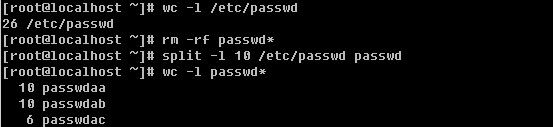
8)split :切割文档,常用选项:
-b :依据大小来分割文档,单位为byte
![]()
格式如上例,后面的passwd为分割后文件名的前缀,分割后的文件名为passwdaa, passwdab, passwdac …
-l :依据行数来分割文档
6. ; :分号。平时我们都是在一行中敲一个命令,然后回车就运行了,那么想在一行中运行两个或两个以上的命令如何呢?则需要在命令之间加一个”;”了。
![[image]](http://img.e-com-net.com/image/info2/da99ef0289834b68a7f5f53e87c68e0c.jpg)
7. ~ :用户的家目录,如果是root则是 /root ,普通用户则是 /home/username

8. & :如果想把一条命令放到后台执行的话,则需要加上这个符号。通常用于命令运行时间非常长的情况。
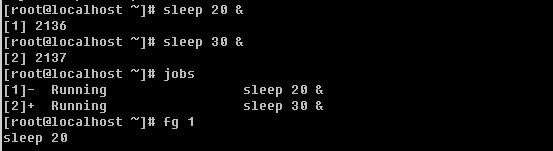
![[image]](http://img.e-com-net.com/image/info2/6f0a1b719eb34e85ab12ffa1496bab15.jpg)
使用jobs可以查看当前shell中后台执行的任务。用fg可以调到前台执行。这里的sleep命令就是休眠的意思,后面跟数字,单位为秒,常用语循环的shell脚本中。
![]()
此时你按一下CTRL +z 使之暂停,然后再输入bg可以再次进入后台执行。
![[image]](http://img.e-com-net.com/image/info2/303789e024504f68b85158e548daaf76.jpg)
如果是多任务情况下,想要把任务调到前台执行的话,fg后面跟任务号,任务号可以使用jobs命令得到。
9. >, >>, 2>, 2>> :前面讲过重定向符号> 以及>> 分别表示取代和追加的意思,然后还有两个符号就是这里的2> 和 2>> 分别表示错误重定向和错误追加重定向,当我们运行一个命令报错时,报错信息会输出到当前的屏幕,如果想重定向到一个文本里,则要用2>或者2>>。

10. [ ] :中括号,中间为字符组合,代表中间字符中的任意一个

11. && 与 ||
在上面刚刚提到了分号,用于多条命令间的分隔符。另外还有两个可以用于多条命令中间的特殊符号,那就是 “&&”和”||”。下面笔者把这几种情况全列出:
1) command1 ; command2
2) command1 && command2
3) command1 || command2
使用”;”时,不管command1是否执行成功都会执行command2; 使用”&&”时,只有command1执行成功后,command2才会执行,否则command2不执行;使用”||”时,command1执行成功后command2 不执行,否则去执行command2,总之command1和command2总有一条命令会执行。

这部分内容可以说是学习shell脚本之前必学的内容。如果你这部分内容学的越好,那么你的shell脚本编写能力就会越强。所以不要嫌这部分内容啰嗦,也不要怕麻烦,要用心学习。一定要多加练习,练习多了就能熟练掌握了。
在计算机科学中,正则表达式是这样解释的:它是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。对于系统管理员来讲,正则表达式贯穿在我们的日常运维工作中,无论是查找某个文档,抑或查询某个日志文件分析其内容,都会用到正则表达式。
其实正则表达式,只是一种思想,一种表示方法。只要我们使用的工具支持表示这种思想那么这个工具就可以处理正则表达式的字符串。常用的工具有grep, sed, awk等,下面笔者就介绍一下这三种工具的使用方法。
【grep / egrep】
笔者在前面的内容中多次提到并用到grep命令,可见它的重要性。所以好好学习一下这个重要的命令吧。你要知道的是grep连同下面讲的sed, awk都是针对文本的行才操作的。
语法:grep [-cinvABC] ‘word’ filename
-c:打印符合要求的行数
-i:忽略大小写
-n:在输出符合要求的行的同时连同行号一起输出
-v:打印不符合要求的行
-A:后跟一个数字(有无空格都可以),例如–A2则表示打印符合要求的行以及下面两行
-B:后跟一个数字,例如–B2则表示打印符合要求的行以及上面两行
-C:后跟一个数字,例如–C2则表示打印符合要求的行以及上下各两行

以下,笔者举几个小例子帮助你好好掌握这个grep工具的用法。
a.过滤出带有某个关键词的行并输出行号
![[image]](http://img.e-com-net.com/image/info2/6893fea734e7405e8037b947e7f1d564.jpg)
b.过滤不带有某个关键词的行,并输出行号

c.过滤出所有包含数字的行

在前面也提到过这个”[ ]”的应用,如果是数字的话就用[0-9]这样的形式,当然有时候也可以用这样的形式[15]即只含有1或者5,注意,它不会认为是15。如果要过滤出数字以及大小写字母则要这样写[0-9a-zA-Z]。另外[ ]还有一种形式,就是[^字符]表示除[ ]内的字符之外的字符。
![[image]](http://img.e-com-net.com/image/info2/021b3f780bed4bf29bba201818733ccf.png)
这就表示筛选包含oo字符串,但是不包含r字符。
d.过滤出文档中以某个字符开头或者以某个字符结尾的行

在正则表达式中,”^”表示行的开始,”$”表示行的结尾,那么空行则表示”^$”,如果你只想筛选出非空行,则可以使用“grep -v ‘^$’ filename”得到你想要的结果。现在想一下,如何打印出不以英文字母开头的行呢?

e.过滤任意一个字符与重复字符
![[image]](http://img.e-com-net.com/image/info2/fbc3e494e5ea41deb6f2dd8cf2c2a7cf.png)
“.”表示任意一个字符,上例中,就是把符合r与o之间有两个任意字符的行过滤出来。
“*”表示零个或多个前面的字符。

‘ooo*’表示oo, ooo, oooo …或者更多的’o’。现在你是否想到了’.*’这个组合表示什么意义?
![[image]](http://img.e-com-net.com/image/info2/56c75579c82b467b9cde8c5817fb36f0.png)
‘.*’表示零个或多个任意字符,空行也包含在内。
f.指定要过滤字符出现的次数

这里用到了{ },其内部为数字,表示前面的字符要重复的次数。上例中表示包含有两个o即’oo’的行。注意,{ }左右都需要加上脱意字符’\’。另外,使用{ }我们还可以表示一个范围的,具体格式是‘\{n1,n2\}’其中n1<n2,表示重复n1到n2次前面的字符,n2还可以为空,则表示大于等于n1次。
上面部分讲的grep,另外笔者常常用到egrep这个工具,简单点讲,后者是前者的扩展版本,我们可以用egrep完成grep不能完成的工作,当然了grep能完成的egrep完全可以完成。如果你嫌麻烦,egrep了解一下即可,因为grep的功能已经足够可以胜任你的日常工作了。下面笔者介绍egrep不用于grep的几个用法。为了试验方便,笔者把test.txt编辑成如下内容:
rot:x:0:0:/rot:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
operator:x:11:0:operator:/rooot:/sbin/nologin
roooot:x:0:0:/rooooot:/bin/bash
1111111111111111111111111111111
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
a.筛选一个或一个以上前面的字符
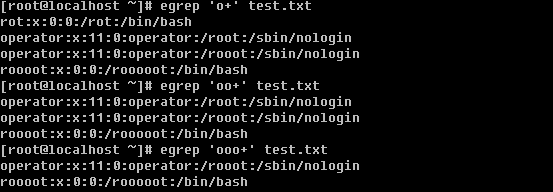
和grep不同的是,egrep这里是使用’+’的。
b.筛选零个或一个前面的字符

c.筛选字符串1或者字符串2
![[image]](http://img.e-com-net.com/image/info2/2375689ad89a4600ac7a904ca5fe0a26.png)
中间有一个’|’表示或者的意思,笔者用这个用的很多,所以这个你最好记一下。
d. egrep中’( )’的应用
![[image]](http://img.e-com-net.com/image/info2/5ae261965f054a519ebaeacbb9637d44.png)
用’( )’表示一个整体,例如(oo)+就表示1个’oo’或者多个’oo’
![[image]](http://img.e-com-net.com/image/info2/8f6468b07c184c4b96cfafa517abdc96.png)
【sed工具的使用】
grep工具的功能其实还不够强大,其实说白了,grep实现的只是查找功能,而它却不能实现把查找的内容替换掉。以前用vim的时候,可以查找也可以替换,但是只局限于在文本内部来操作,而不能输出到屏幕上。sed工具以及下面要讲的awk工具就能实现把替换的文本输出到屏幕上的功能了,而且还有其他更丰富的功能。sed和awk都是流式编辑器,是针对文档的行来操作的。
a.打印某行sed -n ‘n’p filename单引号内的n是一个数字,表示第几行
![]()
b.打印多行打印整个文档用-n ‘1,$’p

c.打印包含某个字符串的行
![]()
上面grep中使用的特殊字符,如’^’, ‘$’, ‘.’, ‘*’等同样也能在sed中使用。
![[image]](http://img.e-com-net.com/image/info2/f0d44b99d54249c3aa413f7a45447691.png)

d. -e可以实现多个行为
![]()
e.删除某行或者多行
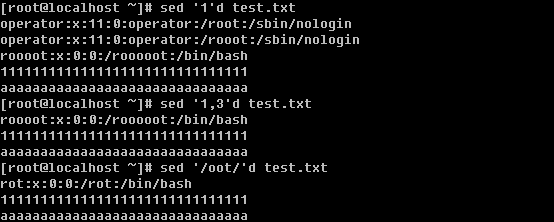
‘d’这个字符就是删除的动作了,不仅可以删除指定的单行以及多行,而且还可以删除匹配某个字符的行,另外还可以删除从某一行一直到文档末行。
![]()
f.替换字符或字符串

上例中的’s’就是替换的命令,’g’为本行中全局替换,如果不加’g’,只换该行中出现的第一个。
除了可以使用’/’外,还可以使用其他特殊字符例如’
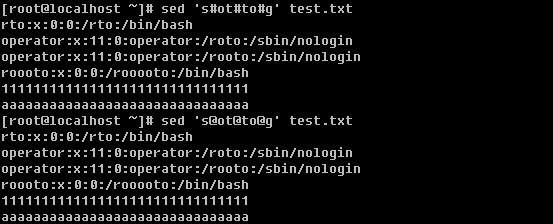
现在思考一下,如何删除文档中的所有数字或者字母?
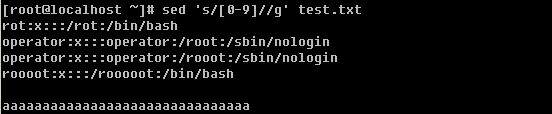
有意思吧,[0-9]表示任意的数字。这里你也可以写成[a-zA-Z]甚至[0-9a-zA-Z]
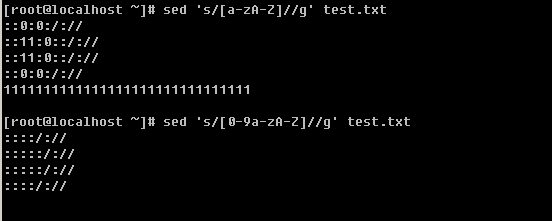
g.调换两个字符串的位置
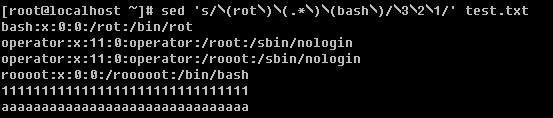
这个就需要解释一下了,上例中用’()’把所想要替换的字符括起来成为一个整体,因为括号在sed中属于特殊符号,所以需要在前面加脱意字符’\’,替换时则写成’\1’, ‘\2’, ‘\3’的形式。除了调换两个字符串的位置外,笔者还常常用到在某一行前或者后增加指定内容。
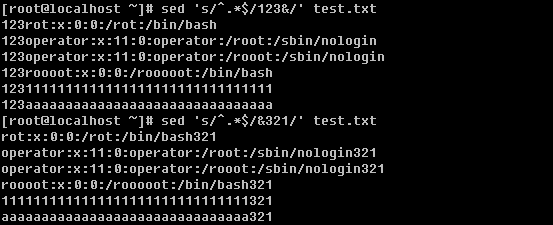
h.直接修改文件的内容
sed -i ‘s/:/
sed常用到的也就上面这些了,只要你多加练习就能熟悉它了。为了能让你更加牢固的掌握sed的应用,笔者留几个练习题给你,希望你能认真完成。
1.把/etc/passwd复制到/root/test.txt,用sed打印所有行;
2.打印test.txt的3到10行;
3.打印test.txt中包含’root’的行;
4.删除test.txt的15行以及以后所有行;
5.删除test.txt中包含’bash’的行;
6.替换test.txt中’root’为’toor’;
7.替换test.txt中’/sbin/nologin’为’/bin/login’
8.删除test.txt中5到10行中所有的数字;
9.删除test.txt中所有特殊字符(除了数字以及大小写字母);
10.把test.txt中第一个单词和最后一个单词调换位置;
11.把test.txt中出现的第一个数字和最后一个单词替换位置;
12.把test.txt中第一个数字移动到行末尾;
13.在test.txt 20行到末行最前面加’aaa:’;
现在给出以上练习题的答案,你如果实在想不出如何操作,那你看看答案吧,请尽量多想一下。
1. /bin/cp /etc/passwd /root/test.txt ; sed -n '1,$'p test.txt
2. sed -n '3,10'p test.txt
3. sed -n '/root/'p test.txt
4. sed '15,$'d test.txt
5. sed '/bash/'d test.txt
6. sed 's/root/toor/g' test.txt
7. sed 's
8. sed '5,10s/[0-9]//g' test.txt
9. sed 's/[^0-9a-zA-Z]//g' test.txt
10. sed 's/\(^[a-zA-Z][a-zA-Z]*\)\([^a-zA-Z].*\)\([^a-zA-Z]\)\([a-zA-Z][a-zA-Z]*$\)/\4\2\3\1/' test.txt
11. sed 's
12. sed 's
13. sed '20,$s/^.*$/aaa:&/' test.txt
【awk工具的使用】
上面也提到了awk和sed一样是流式编辑器,它也是针对文档中的行来操作的,一行一行的去执行。awk比sed更加强大,它能做到sed能做到的,同样也能做到sed不能做到的。awk工具其实是很复杂的,有专门的书籍来介绍它的应用,但是笔者认为学那么复杂没有必要,只要能处理日常管理工作中的问题即可。何必让自己的脑袋装那么东西来为难自己?毕竟用的也不多,即使现在教会了你很多,你也学会了,如果很久不用肯定就忘记了。鉴于此,笔者仅介绍比较常见的awk应用,如果你感兴趣的话,再去深入研究吧。
a.截取文档中的某个段
![]()
解释一下,-F选项的作用是指定分隔符,如果不加-F指定,则以空格或者tab为分隔符。
![[image]](http://img.e-com-net.com/image/info2/739033b1e8974b91a46a23d39e7ce369.png)
Print为打印的动作,用来打印出某个字段。$1为第一个字段,$2为第二个字段,依次类推,有一个特殊的那就是$0,它表示整行。
![]()
注意awk的格式,-F后紧跟单引号,然后里面为分隔符,print的动作要用’{ }’括起来,否则会报错。print还可以打印自定义的内容,但是自定义的内容要用双引号括起来。
![[image]](http://img.e-com-net.com/image/info2/ca647c14af2e45d483d98159ca38ba16.png)
b.匹配字符或字符串
![]()
跟sed很类似吧,不过还有比sed更强大的匹配。
![]()
可以让某个段去匹配,这里的’~’就是匹配的意思,继续往下看
![[image]](http://img.e-com-net.com/image/info2/d05d80f74a94420e82aa474541d78cb3.png)
awk还可以多次匹配,如上例中匹配完root,再匹配test,它还可以只打印所匹配的段。
![]()
不过这样没有啥意义,笔者只是为了说明awk确实比sed强大。
d.条件操作符
![]()
awk中是可以用逻辑符号判断的,比如’==’就是等于,也可以理解为“精确匹配”。另外也有’>’, ‘>=’, ‘<’, ‘<=’, ‘!=’等等,值得注意的是,即使$3为数字,awk也不会把它当数字看待,它会认为是一个字符。所以不要妄图去拿$3当数字去和数字做比较。

这样是得不到我们想要的效果的。这里只是字符与字符之间的比较,’6’是>’500’的。
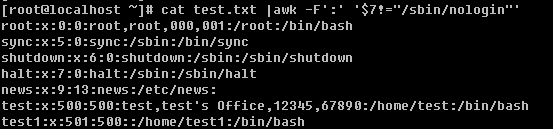
上例中用的是’!=’即不匹配。
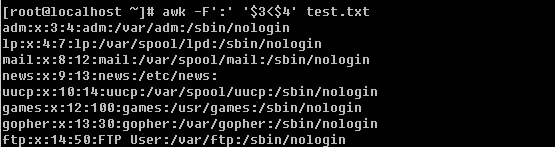
另外还可以使用”&&”和“||”表示“并且”和“或者”的意思。
![[image]](http://img.e-com-net.com/image/info2/b299aa201c6241e1a8ee3fdf30a010ce.png)
也可以是或者的关系
![[image]](http://img.e-com-net.com/image/info2/06b828756ccb4d2f9aca2d7089394e60.png)
d. awk的内置变量
常用的变量有:
NF:用分隔符分隔后一共有多少段;
NR:行数
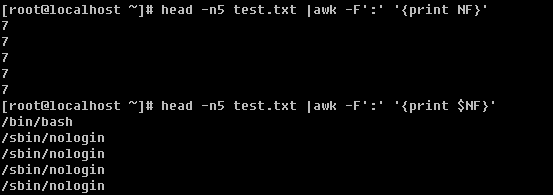
上例中,打印总共的段数以及最后一段的值。
可以使用NR作为条件,来打印出指定的行。
![]()
e. awk中的数学运算
![[image]](http://img.e-com-net.com/image/info2/fe5661d754bf4342b7d6ed8930f42250.png)
awk比较强的地方,还在于能把某个段改成指定的字符串,下面还有更强的呢!
![[image]](http://img.e-com-net.com/image/info2/22dee7c8cd7d4b2badd43656cad653c6.png)
当然还可以计算某个段的总和。
![]()
这里的END要注意一下,表示所有的行都已经执行,这是awk特有的语法,其实awk连同sed都可以写成一个脚本文件,而且有他们特有的语法,在awk中使用if判断、for循环都是可以的,只是笔者认为日常管理工作中没有必要使用那么复杂的语句而已。
![]()
注意这里’( )’的使用。
基本上,正则表达的内容就这些了。但是笔者要提醒你一下,笔者介绍的这些仅仅是最基本的东西,并没有提啊深入的去讲sed和awk,但是完全可以满足日常工作的需要,有时候也许你会碰到比较复杂的需求,如果真遇到了就去请教一下google吧。下面出几道关于awk的练习题,希望你要认真完成。
1.用awk打印整个test.txt(以下操作都是用awk工具实现,针对test.txt);
2.查找所有包含’bash’的行;
3.用’:’作为分隔符,查找第三段等于0的行;
4.用’:’作为分隔符,查找第一段为’root’的行,并把该段的’root’换成’toor’(可以连同sed一起使用);
5.用’:’作为分隔符,打印最后一段;
6.打印行数大于20的所有行;
7.用’:’作为分隔符,打印所有第三段小于第四段的行;
终于到shell脚本这章了,在以前笔者卖了好多关子说shell脚本怎么怎么重要,确实shell脚本在linux系统管理员的运维工作中非常非常重要。下面笔者就带你正式进入shell脚本的世界吧。
到现在为止,你明白什么是shell脚本吗?如果明白最好了,不明白也没有关系,相信随着学习的深入你就会越来越了解到底什么是shell脚本。首先它是一个脚本,并不能作为正式的编程语言。因为是跑在linux的shell中,所以叫shell脚本。说白了,shell脚本就是一些命令的集合。举个例子,我想实现这样的操作:1)进入到/tmp/目录;2)列出当前目录中所有的文件名;3)把所有当前的文件拷贝到/root/目录下;4)删除当前目录下所有的文件。简单的4步在shell窗口中需要你敲4次命令,按4次回车。这样是不是很麻烦?当然这4步操作非常简单,如果是更加复杂的命令设置需要几十次操作呢?那样的话一次一次敲键盘会很麻烦。所以不妨把所有的操作都记录到一个文档中,然后去调用文档中的命令,这样一步操作就可以完成。其实这个文档呢就是shell脚本了,只是这个shell脚本有它特殊的格式。
Shell脚本能帮助我们很方便的去管理服务器,因为我们可以指定一个任务计划定时去执行某一个shell脚本实现我们想要需求。这对于linux系统管理员来说是一件非常值得自豪的事情。现在的139邮箱很好用,发邮件的同时还可以发一条邮件通知的短信给用户,利用这点,我们就可以在我们的linux服务器上部署监控的shell脚本,比如网卡流量有异常了或者服务器web服务器停止了就可以发一封邮件给管理员,同时发送给管理员一个报警短信这样可以让我们及时的知道服务器出问题了。
有一个问题需要约定一下,【shell脚本的基本结构以及如何执行】

Shell脚本通常都是以.sh为后缀名的,这个并不是说不带.sh这个脚本就不能执行,只是大家的一个习惯而已。所以,以后你发现了.sh为后缀的文件那么它一定会是一个shell脚本了。test.sh中第一行一定是“
![[image]](http://img.e-com-net.com/image/info2/7f15e8f0f5a8458e878f643fc572b391.png)
Shell脚本的执行很简单,直接”sh filename “即可,另外你还可以这样执行
![[image]](http://img.e-com-net.com/image/info2/5c34d015bd654c77ac313da3b7a71b2f.png)
默认我们用vim编辑的文档是不带有执行权限的,所以需要加一个执行权限,那样就可以直接使用’./filename’执行这个脚本了。另外使用sh命令去执行一个shell脚本的时候是可以加-x选项来查看这个脚本执行过程的,这样有利于我们调试这个脚本哪里出了问题。
![[image]](http://img.e-com-net.com/image/info2/18febc03ed97485c88495512fce5b7e0.png)
该shell脚本中用到了’date’这个命令,它的作用就是用来打印当前系统的时间。其实在shell脚本中date使用率非常高。有几个选项笔者常常在shell脚本中用到:
![]()
%Y表示年,%m表示月,%d表示日期,%H表示小时,%M表示分钟,%S表示秒
![]()
注意%y和%Y的区别。
![[image]](http://img.e-com-net.com/image/info2/8da4401d9a6d4a62bf00475e8a1097fd.png)
-d选项也是经常要用到的,它可以打印n天前或者n天后的日期,当然也可以打印n个月/年前或者后的日期。
![[image]](http://img.e-com-net.com/image/info2/bc6b44960fa4461aa6a775767cef8d7b.png)
另外星期几也是常用的
![]()
【shell脚本中的变量】
在shell脚本中使用变量显得我们的脚本更加专业更像是一门语言,开个玩笑,变量的作用当然不是为了专业。如果你写了一个长达1000行的shell脚本,并且脚本中出现了某一个命令或者路径几百次。突然你觉得路径不对想换一下,那岂不是要更改几百次?你固然可以使用批量替换的命令,但是也是很麻烦,并且脚本显得臃肿了很多。变量的作用就是用来解决这个问题的。

在test2.sh中使用到了反引号,你是否还记得它的作用?’d’和’d1’在脚本中作为变量出现,定义变量的格式为“变量名=变量的值”。当在脚本中引用变量时需要加上’$’符号,这跟前面讲的在shell中自定义变量是一致的。下面看看脚本执行结果吧。
![[image]](http://img.e-com-net.com/image/info2/4ff7895f673f4c8f98371ffe92777b33.png)
下面我们用shell计算两个数的和。

数学计算要用’[ ]’括起来并且外头要带一个’$’。脚本结果为:
![]()
Shell脚本还可以和用户交互。
这就用到了read命令了,它可以从标准输入获得变量的值,后跟变量名。”read x”表示x变量的值需要用户通过键盘输入得到。脚本执行过程如下:
![[image]](http://img.e-com-net.com/image/info2/311095737a254a0089fc5d21c8169ca8.png)
我们不妨加上-x选项再来看看这个执行过程:

在test4.sh中还有更加简洁的方式。

read -p 选项类似echo的作用。执行如下:
![[image]](http://img.e-com-net.com/image/info2/55003c3b00df4e0bb16b090c8ca91d8b.png)
你有没有用过这样的命令”/etc/init.d/iptables restart “前面的/etc/init.d/iptables文件其实就是一个shell脚本,为什么后面可以跟一个”restart”?这里就涉及到了shell脚本的预设变量。实际上,shell脚本在执行的时候后边是可以跟变量的,而且还可以跟多个。不妨笔者写一个脚本,你就会明白了。

执行过程如下:
![[image]](http://img.e-com-net.com/image/info2/67df88d126f74b49a7421b8f18caa599.png)
在脚本中,你会不会奇怪,哪里来的$1和$2,这其实就是shell脚本的预设变量,其中$1的值就是在执行的时候输入的1,而$2的值就是执行的时候输入的$2,当然一个shell脚本的预设变量是没有限制的,这回你明白了吧。另外还有一个$0,不过它代表的是脚本本身的名字。不妨把脚本修改一下。
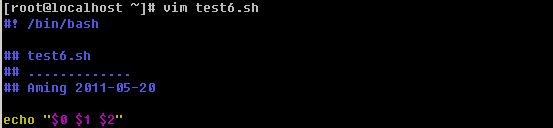
执行结果想必你也猜到了吧。
![]()
【shell脚本中的逻辑判断】
如果你学过C或者其他语言,相信你不会对if陌生,在shell脚本中我们同样可以使用if逻辑判断。在shell中if判断的基本语法为:
1)不带else
if判断语句; then
command
fi

在if1.sh中出现了((a<60))这样的形式,这是shell脚本中特有的格式,用一个小括号或者不用都会报错,请记住这个格式,即可。执行结果为:
![]()
2)带有else
if判断语句; then
command
else
command
fi

执行结果为:
![]()
3)带有elif
if判断语句一; then
command
elif判断语句二; then
command
else
command
fi

这里的&&表示“并且”的意思,当然你也可以使用||表示“或者”,执行结果:
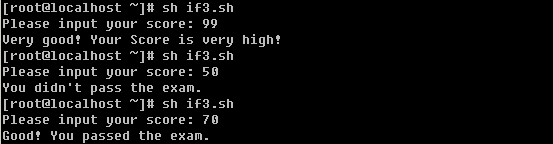
以上只是简单的介绍了if语句的结构。在判断数值大小除了可以用”(( ))”的形式外,还可以使用”[ ]”。但是就不能使用>, < , =这样的符号了,要使用-lt(小于),-gt(大于),-le(小于等于),-ge(大于等于),-eq(等于),-ne(不等于)。
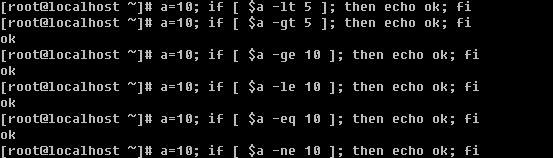
再看看if中使用&&和||的情况。
![[image]](http://img.e-com-net.com/image/info2/334e9d8bfa214bd685db092b05218d6f.png)
shell脚本中if还经常判断关于档案属性,比如判断是普通文件还是目录,判断文件是否有读写执行权限等。常用的也就几个选项:
-e:判断文件或目录是否存在
-d:判断是不是目录,并是否存在
-f:判断是否是普通文件,并存在
-r:判断文档是否有读权限
-w:判断是否有写权限
-x:判断是否可执行
使用if判断时,具体格式为:if [ -e filename ] ; then

在shell脚本中,除了用if来判断逻辑外,还有一种常用的方式,那就是case了。具体格式为:
case变量in
value1)
command
;;
value2)
command
;;
value3)
command
;;
*)
command
;;
esac
上面的结构中,不限制value的个数,*则代表除了上面的value外的其他值。下面笔者写一个判断输入数值是奇数或者偶数的脚本。

$a的值或为1或为0,执行结果为:
![[image]](http://img.e-com-net.com/image/info2/0e6e370a6f264473a61064c99f7db245.png)
也可以看一下执行过程:

case脚本常用于编写系统服务的启动脚本,例如/etc/init.d/iptables中就用到了,你不妨去查看一下。
【shell脚本中的循环】
Shell脚本中也算是一门简易的编程语言了,当然循环是不能缺少的。常用到的循环有for循环和while循环。下面就分别介绍一下两种循环的结构。
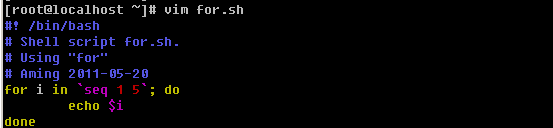
脚本中的seq 1 5表示从1到5的一个序列。你可以直接运行这个命令试下。脚本执行结果为:
![[image]](http://img.e-com-net.com/image/info2/01aeb36dd3984f56a2646f09b8199bda.png)
通过这个脚本就可以看到for循环的基本结构:
for变量名in循环的条件;do
command
done
![[image]](http://img.e-com-net.com/image/info2/e51a179c01334d54a0e8c6ce5b6bb69e.png)
循环的条件那一部分也可以写成这样的形式,中间用空格隔开即可。你也可以试试,for i in `ls`; do echo $i; done和for i in `cat test.txt`;do echo $i; done

再来看看这个while循环,基本格式为:
while条件; do
command
done
脚本的执行结果为:
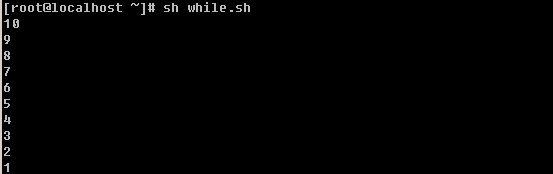
另外你可以把循环条件忽略掉,笔者常常这样写监控脚本。
while :; do
command
done
【shell脚本中的函数】
如果你学过开发,肯定知道函数的作用。如果你是刚刚接触到这个概念的话,也没有关系,其实很好理解的。函数就是把一段代码整理到了一个小单元中,并给这个小单元起一个名字,当用到这段代码时直接调用这个小单元的名字即可。有时候脚本中的某段代总是重复使用,如果写成函数,每次用到时直接用函数名代替即可,这样就节省了时间还节省了空间。
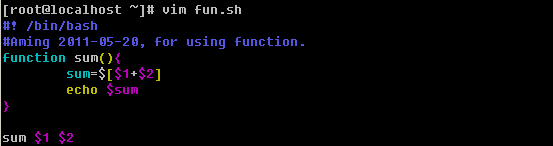
fun.sh中的sum()为自定义的函数,在shell脚本中要用
function函数名() {
command
}
这样的格式去定义函数。
上个脚本执行过程如下:
![]()
有一点笔者要提醒你一下,在shell脚本中,函数一定要写在最前面,不能出现在中间或者最后,因为函数是要被调用的,如果还没有出现就被调用,肯定是会出错的。
Shell脚本大体上就介绍这么多了,笔者所举的例子都是最基础的,所以即使你把所有例子完全掌握也不代表你的shell脚本编写能力有多么好。所以剩下的日子里你尽量要多练习,多写脚本,你写的脚本越多,你的能力就越强。希望你能够找专门介绍shell脚本的书籍深入的去研究一下它。随后笔者将给你留几个shell脚本的练习题,你最好不要偷懒。
1.编写shell脚本,计算1-100的和;
2.编写shell脚本,要求输入一个数字,然后计算出从1到输入数字的和,要求,如果输入的数字小于1,则重新输入,直到输入正确的数字为止;
3.编写shell脚本,把/root/目录下的所有目录(只需要一级)拷贝到/tmp/目录下;
4.编写shell脚本,批量建立用户user_00, user_01, … ,user_100并且所有用户同属于users组;
5.编写shell脚本,截取文件test.log中包含关键词’abc’的行中的第一列(假设分隔符为”:”),然后把截取的数字排序(假设第一列为数字),然后打印出重复次数超过10次的列;
6.编写shell脚本,判断输入的IP是否正确(IP的规则是,n1.n2.n3.n4,其中1<n1<255, 0<n2<255, 0<n3<255, 0<n4<255)。
以下为练习题答案:
1.
sum=0
for i in `seq 1 100`; do
sum=$[$i+$sum]
done
echo $sum
2.
n=0
while [ $n -lt "1" ]; do
read -p "Please input a number, it must greater than "1":" n
done
sum=0
for i in `seq 1 $n`; do
sum=$[$i+$sum]
done
echo $sum
3.
for f in `ls /root/`; do
if [ -d $f ] ; then
cp -r $f /tmp/
fi
done
4.
groupadd users
for i in `seq 0 9`; do
useradd -g users user_0$i
done
for j in `seq 10 100`; do
useradd -g users user_$j
done
5.
awk -F':' '$0~/abc/ {print $1}' test.log >/tmp/n.txt
sort -n n.txt |uniq -c |sort -n >/tmp/n2.txt
awk '$1>10 {print $2}' /tmp/n2.txt
6.
checkip() {
if echo $1 |egrep -q '^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$' ; then
a=`echo $1 | awk -F. '{print $1}'`
b=`echo $1 | awk -F. '{print $2}'`
c=`echo $1 | awk -F. '{print $3}'`
d=`echo $1 | awk -F. '{print $4}'`
for n in $a $b $c $d; do
if [ $n -ge 255 ] || [ $n -le 0 ]; then
echo "the number of the IP should less than 255 and greate than 0"
return 2
fi
done
else
echo "The IP you input is something wrong, the format is like 192.168.100.1"
return 1
fi
}
rs=1
while [ $rs -gt 0 ]; do
read -p "Please input the ip:" ip
checkip $ip
rs=`echo $?`
done
echo "The IP is right!"
【监控系统的状态】
1. w查看当前系统的负载
![[image]](http://img.e-com-net.com/image/info2/72305de23c10428bb1b69949cfe2f801.png)
相信所有的linux管理员最常用的命令就是这个’w’了,该命令显示的信息还是蛮丰富的。第一行从左面开始显示的信息依次为:时间,系统运行时间,登录用户数,平均负载。第二行开始以及下面所有的行,告诉我们的信息是,当前登录的都有哪些用户,以及他们是从哪里登录的等等。其实,在这些信息当中,笔者认为我们最应该关注的应该是第一行中的’load average:’后面的三个数值。
第一个数值表示1分钟内系统的平均负载值;第二个数值表示5分钟内系统的平均负载值;第三个数值表示15分钟系统的平均负载值。这个值的意义是,单位时间段内CPU活动进程数。当然这个值越大就说明你的服务器压力越大。一般情况下这个值只要不超过你服务器的cpu数量就没有关系,如果你的服务器cpu数量为8,那么这个值若小于8,就说明你的服务器没有压力,否则就要关注一下了。到这里你肯定会问,如何查看服务器有几个cpu?
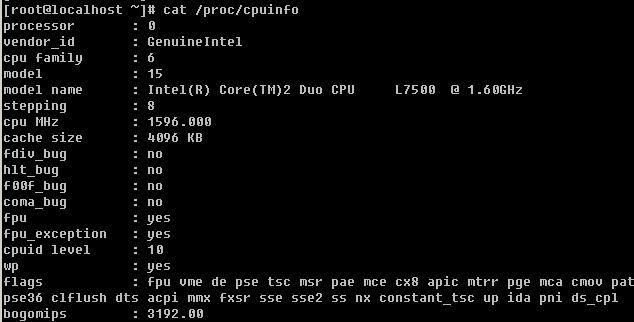
就是用这个命令了。’/proc/cpuinfo’这个文件记录了cpu的详细信息。目前市面上的服务器通常都是2颗4核cpu,在linux看来,它就是8个cpu。查看这个文件时则会显示8段类似的信息,而最后一段信息中processor :后面跟的是’7’。所以查看当前系统有几个cpu,你可以使用这个命令:’ grep -c 'processor' /proc/cpuinfo’ 。
![]()
2. vmstat监控系统的状态
![[image]](http://img.e-com-net.com/image/info2/1f1580006c7c418089bd7ca2265bc091.png)
上面讲的w查看的是系统整体上的负载,通过看那个数值可以知道当前系统有没有压力,但是具体是哪里(CPU,内存,磁盘等)有压力就无法判断了。通过vmstat就可以知道具体是哪里有压力。vmstat命令打印的结果共分为6部分:procs, memory, swap, io, system, cpu.请重点关注一下红色标出的项。
1)procs显示进程相关信息
2)memory内存相关信息
swpd:表示切换到交换分区中的内存数量;
free:当前空闲的内存数量;
buff:缓冲大小,(即将写入磁盘的);
cache:缓存大小,(从磁盘中读取的);
3)swap内存交换情况
4)io磁盘使用情况
5)system显示采集间隔内发生的中断次数
in:表示在某一时间间隔中观测到的每秒设备中断数;
cs:表示每秒产生的上下文切换次数;
6)CPU显示cpu的使用状态
us:显示了用户下所花费cpu时间的百分比;
sy:显示系统花费cpu时间百分比;
id:表示cpu处于空闲状态的时间百分比;
st:表示被偷走的cpu所占百分比(一般都为0,不用关注);
以上所介绍的各个参数中,笔者经常会关注r列,b列,和wa列,三列代表的含义在上边说得已经很清楚。IO部分的bi以及bo也是我要经常参考的对象。如果磁盘io压力很大时,这两列的数值会比较高。另外当si, so两列的数值比较高,并且在不断变化时,说明内存不够了,内存中的数据频繁交换到交换分区中,这往往对系统性能影响极大。

笔者用vmstat时,经常用这样的形式,’vmstat 1 5’表示每隔1秒钟打印一次系统状态,连续打印5次。当然你也可以‘vmstat 1 ‘表示每隔1秒钟打印一次系统状态,一直打印,除非你按ctrl + c强制结束。
3. top显示进程所占系统资源

这个命令用于动态监控进程所占系统资源,每隔3秒变一次。这个命令的特点是把占用系统资源(CPU,内存,磁盘IO等)最高的进程放到最前面。top命令打印出了很多信息,包括系统负载(load average)、进程数(Tasks)、cpu使用情况、内存使用情况以及交换分区使用情况。其实上面这些内容可以通过其他命令来查看,所以用top重点查看的还是下面的进程使用系统资源详细状况。这部分东西反映的东西还是比较多的,不过需要你关注的也就是几项:%CPU, %MEM, COMMAND这些项目所代表的意义,不用笔者介绍相信你也能看懂吧。
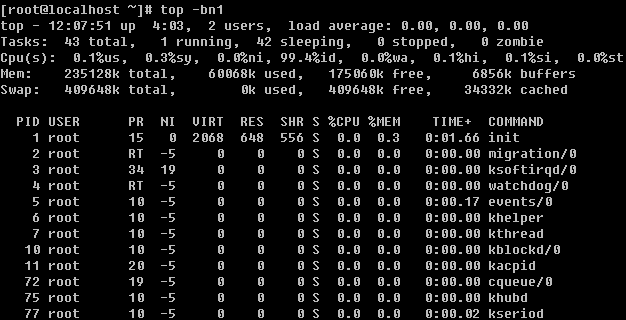
另外笔者使用top命令时还常常使用-bn1这个组合选项,它表示非动态打印系统资源使用情况,可以用在脚本中,你不妨记一下,以后也许你会用得到。
4. sar监控系统状态
sar命令很强大,它可以监控系统所有资源状态,比如平均负载、网卡流量、磁盘状态、内存使用等等。它不同于其他系统状态监控工具的地方在于,它可以打印历史信息,可以显示当天从零点开始到当前时刻的系统状态信息。如果你系统没有安装这个命令,请使用”yum install -y sysstat”命令安装。初次使用sar命令会报错,那是因为sar工具还没有生成相应的数据库文件(时时监控就不会了,因为不用去查询那个库文件)。它的数据库文件在” /var/log/sa/”目录下,默认保存9天。因为这个命令太过复杂,所以笔者只介绍几个。
1)查看网卡流量‘sar -n DEV ‘

IFACE这列表示设备名称,rxpck/s表示每秒进入收取的包的数量,txpck/s表示每秒发送出去的包的数量,rxbyt/s表示每秒收取的数据量(单位Byte),txbyt/s表示每秒发送的数据量。后面几列不需要关注。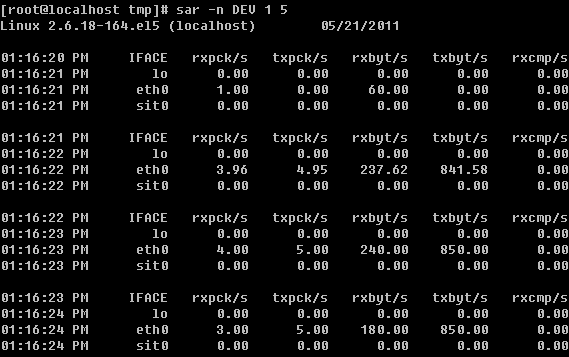
另外也可以查看某一天的网卡流量历史,使用-f选项,后面跟文件名,如果你的系统格式Redhat或者CentOS那么sar的库文件一定是在/var/log/sa/目录下的。
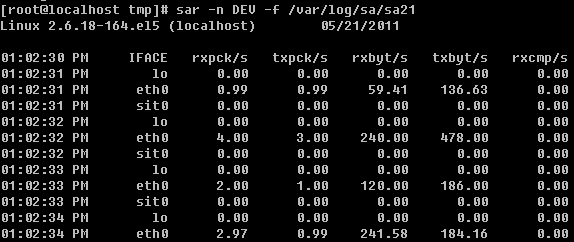
2)查看历史负载‘sar -q’

这个命令有助于我们查看服务器在过去的某个时间的负载状况。
关于sar的介绍笔者不愿写太多,毕竟介绍太多会给你带来更多的压力,其实笔者介绍这个命令的目的只是让你学会查看网卡流量(这是非常有用的)。如果你很感兴趣那就man一下吧,它的用法太多了。
5. free查看内存使用状况
![[image]](http://img.e-com-net.com/image/info2/9c03e30801824f7d888fa1589c5a8571.png)
只要你敲一个free然后回车就可以当前系统的总内存大小以及使用内存的情况。从上图中可看到当前系统内存总大小为235128(单位是k)已经使用120368,剩余94760。其实真正剩余并不是这个94760,而是第二行的213388,真正使用的也是第二行的21740。这是因为系统初始化时,就已经分配出很大一部分内存给缓存,这部分缓存用来随时提供给程序使用,如果程序不用,那这部分内存就空闲。所以,![[image]](http://img.e-com-net.com/image/info2/a90982aebbfc497da93f392da912424b.png)
6. ps查看系统进程
作为系统管理员,一定要知道你所管理的系统都有那些进程在运行,在windows下只要打开任务管理器即可查看。在linux下呢?其实在上面介绍的top命令就可以,但是不够专业,当然还有专门显示系统进程的命令。
对了,就是这个’ps aux’。笔者也经常看到有的人喜欢用’ps -elf’大同小异,显示的信息基本上是一样的。 ps命令还有更多的用法,笔者不再做介绍,因为你只要会用这个命令就足够了,请man一下。下面介绍上图上出现的几个参数的意义。
PID:进程的id,这个id很有用,在linux中内核管理进程就得靠pid来识别和管理某一个程,比如我想终止某一个进程,则用‘kill进程的pid’,有时并不能杀掉,则需要加一个-9选项了’kill -9进程pid’
STAT:表示进程的状态,进程状态分为以下几种(D 不能中断的进程(通常为IO)
R 正在运行中的进程
S 已经中断的进程,通常情况下,系统中大部分进程都是这个状态
T 已经停止或者暂停的进程,如果我们正在运行一个命令,比如说sleep 10,如果我们按一下ctrl -z让他暂停,那么我们用ps查看就会显示T这个状态
W这个好像是说,从内核2.6xx以后,表示为没有足够的内存页分配
X 已经死掉的进程(这个好像从来不会出现)
Z 僵尸进程,杀不掉,打不死的垃圾进程,占系统一小点资源,不过没有关系。如果太多,就有问题了。一般不会出现。
< 高优先级进程
N 低优先级进程
L 在内存中被锁了内存分页
s 主进程
l 多线程进程
+ 代表在前台运行的进程
这个ps命令是笔者在工作中用的非常多的命令之一,所以请记住它吧。关于ps命令的使用,笔者经常会连同管道符一起使用,用来查看某个进程或者它的数量。
上面的6不对,需要减掉1,因为使用grep命令时,grep命令本身也算作了一个。
7. netstat查看网络状况

netstat命令用来打印网络连接状况、系统所开放端口、路由表等信息。笔者最常用的关于netstat的命令就是这个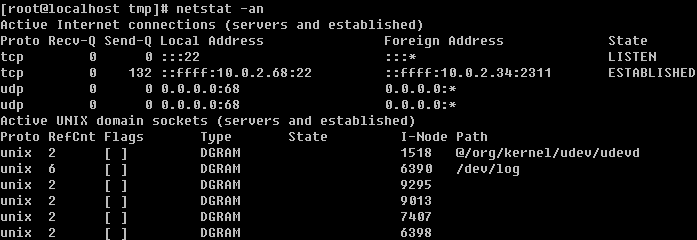
如果你所管理的服务器是一台提供web服务(80端口)的服务器,那么你就可以使用netstat -an |grep 80开查看当前连接web服务的有哪些IP了。
8.抓包工具tcpdump
有时候,也许你会有这样的需求,想看一下某个网卡上都有哪些数据包,尤其是当你初步判定你的服务器上有流量攻击。这时,使用抓包工具来抓一下数据包,就可以知道有哪些IP在攻击你了。
如果你没有tcpdump这个命令,需要用’yum install -y tcpdump ’命令去安装一下。上图中第三列和第四列显示的信息为哪一个IP+port在连接哪一个IP+port,后面的信息是该数据包的相关信息,如果不懂也没有关系,毕竟你不是专门搞网络的,而这里需要你关注的只是第三列以及第四列。-i选项后面跟设备名称,如果你想抓eth1网卡的包,后面则要跟eth1.至于-nn选项的作用是让第三列和第四列显示成IP+端口号的形式,如果不加-nn则显示的是主机名+服务名称。
【linux网络相关】
1. ifconfig查看网卡IP
ifconfig类似与windows的ipconfig,不加任何选项和参数只打印当前网卡的IP相关信息(子网掩码、网关等)
当然ifconfig后面可以跟设备名,只打印指定设备的IP信息。
在windows下设置IP非常简单,然而在命令窗口下如何设置?这就需要去修改配置文件/etc/sysconfig/network-scripts/ifcfg-eth0了,如果是eth1那么配置文件是/etc/sysconfig/network-scripts/ifcfg-eth1.

如果想修改IP的话,则只需要修改IPADDR , NETMASK以及GATEWAY即可。如果你的linux是通过dhcp服务器自动获得的IP,那么配置文件肯定和上图中的不一样,BOOTPROTO那里会是’dhcp’,如果你要配置成静态IP的话,这里就需要写成’none’。关于如何设置IP以及子网掩码的这些知识属于网络相关的基础知识了,如果你对这方面比较陌生的话,建议你去看看网络相关的资料。当修改完IP后需要重启网络服务新IP才能生效,重启命令为’ service network restart’
![[image]](http://img.e-com-net.com/image/info2/92a1cec1019b4d75b7ff1e0d21143c1f.png)
另外如果你有多个网卡的情况时,只想重启某一个网卡的话,还可以使用这个命令。
![]()
ifdown即停掉网卡,ifup即启动网卡。2.给一个网卡设定多个IP
在linux系统中,网卡是可以设定多重IP的,笔者曾经管理的一台服务器的eth1就设定了5个IP,实在是够变态的。

把ifcfg-eth0复制成ifcfg-eth0:1然后编辑ifcfg-eth0:1修改DEVICE以及IPADDR保存后重启网卡。

再次查看eth0上就有两个IP了。3.查看网卡连接状态
![]()
mii-tool这个命令用来查看网卡是否连接,如图显示![]()
如果你的机器是虚拟机,那么你使用该命令时应该显示成如下:
![[image]](http://img.e-com-net.com/image/info2/1658bf8f415c4bdaa2958c6f5f3dbc6b.png)
这是因为使用的是虚拟网卡,不支持这个工具查看。不用多关注此,你记住这个mii-tool命令即可,它可是会经常用到的。
4.更改主机名
当装完系统后,默认主机名为localhost,使用hostname就可以知道你的linux的主机名是什么。
![]() 同样使用hostname可以更改你的主机名。
同样使用hostname可以更改你的主机名。
![[image]](http://img.e-com-net.com/image/info2/02d524789e074b4892d2c0fb6fdbfc75.png)
下次登录时就会把命令提示符![]() 中的’localhost’更改成’Aming’。不过这样修改只是保存在内存中,下次重启还会变成未改之前的主机名,所以需要你还要去更改相关的配置文件’/etc/sysconfig/network’。
中的’localhost’更改成’Aming’。不过这样修改只是保存在内存中,下次重启还会变成未改之前的主机名,所以需要你还要去更改相关的配置文件’/etc/sysconfig/network’。
![[image]](http://img.e-com-net.com/image/info2/ba758e57eef840e7a4295ad88e827128.png)
把HOSTNAME=localhost.localdomain修改成你想要的主机名,这样再重启就会读取这个配置文件中的HOSTNAME.
5.设置DNS
DNS是用来解析域名用的,平时我们访问网站都是直接输入一个网址,而dns把这个网址解析到一个IP。关于dns的概念,如果你很陌生的话,那就去网上查一下吧。在linux下面设置dns非常简单,只要把dns地址写到一个配置文件中即可。这个配置文件就是![[image]](http://img.e-com-net.com/image/info2/e1d7a013dd884f26aab1f1dcc7f4cc1c.png)
resolv.conf有它固有的格式,一定要写成’nameserver IP’的格式,上面那行以’;’为开头的行是一行注释,没有实际意义,建议写两个或多个namserver,默认会用第一个namserver去解析域名,当第一个解析不到时会使用第二个。在linux下面有一个特殊的文件![[image]](http://img.e-com-net.com/image/info2/8de76a1a14e14eb595a09486f354ee68.png)
它的格式如上图,每一行作为一条记录,分成两部分,第一部分是IP,第二部分是域名
当然了,关于MySQL的内容也是非常多的,只不过对于linux系统管理员来讲,一些基本的操作已经可以应付日常的管理工作了,至于更高深的那是DBA(专门管理数据库的技术人员)的事情了。
【更改mysql数据库root的密码】
首次进入数据库是不用密码的
/usr/local/mysql/bin/mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.0.86 MySQL Community Server (GPL)
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
现在已经进入到了mysql的操作界面了。退出的话,直接输入exit即可。
mysql>exit
Bye
先解释一下上面的命令的含义,-u用来指定要登录的用户,root用户是mysql自带的管理员账户,默认没有密码的,那么如何给root用户设定密码?按如下操作:
/usr/local/mysql/bin/mysqladmin -u root password ‘123456’
这样就可以设定root用户的密码了。其中mysqladmin就是用来设置密码的工具,-u指定用户,passwod后跟要定义的密码,密码需要用单引号或者双引号括起来。另外你也许发现了,敲命令时总在前面加/usr/local/mysql/bin/这样很累。但是直接打mysql又不能用,这是因为在系统变量$PATH中没有/usr/local/mysql/bin/这个目录,所以需要这样操作(如果你的linux可以直接打出mysql这个命令,则不要做这个操作):
vim /etc/profile
在最后加入一行:
export PATH=$PATH:/usr/local/mysql/bin/
保存后运行
source /etc/profile
设定完密码后,再来运行最开始进入mysql数据库操作界面的命令:
mysql -u root
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
就报错了,这是因为root用户有密码。
mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 5
Server version: 5.0.86 MySQL Community Server (GPL)
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
需要加-p选项指定密码,这时就会提示你输入密码了。
当设定密码后,如果要想更改密码如何操作呢?
mysqladmin -u root -p password "123456789"
Enter password:
输入原来root的密码就可以更改密码了。
【连接数据库】
刚刚讲过通过使用mysql -u root -p就可以连接数据库了,但这只是连接的本地的数据库’localhost’,然后有很多时候都是去连接网络中的某一个主机上的mysql。
mysql -u user1 -p –P 3306 -h 10.0.2.69
其中-P(大写)指定远程主机mysql的绑定端口,默认都是3306;-h指定远程主机的IP
【一些基本的MySQL操作命令】
1.查询当前所有的库
mysql>show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| test |
+--------------------+
2.查询某个库的表
mysql>use mysql;
Database changed
mysql>show tables;
+---------------------------+
| Tables_in_mysql |
+---------------------------+
| columns_priv |
| db |
| func |
| help_category |
| help_keyword |
| help_relation |
| help_topic |
| host |
| proc |
| procs_priv |
| tables_priv |
| time_zone |
| time_zone_leap_second |
| time_zone_name |
| time_zone_transition |
| time_zone_transition_type |
| user |
+---------------------------+
3.查看某个表的字段
mysql>desc func;//func是表名
+-------+------------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------------------+------+-----+---------+-------+
| name | char(64) | NO | PRI | | |
| ret | tinyint(1) | NO | | 0 | |
| dl | char(128) | NO | | | |
| type | enum('function','aggregate') | NO | | NULL | |
+-------+------------------------------+------+-----+---------+-------+
4.查看某个表的表结构(创建表时的详细结构)
mysql>show create table func;
|Table | CreateTable |
| func | CREATE TABLE `func` (
`name` char(64) collate utf8_bin NOT NULL default '',
`ret` tinyint(1) NOT NULL default '0',
`dl` char(128) collate utf8_bin NOT NULL default '',
`type` enum('function','aggregate') character set utf8 NOT NULL,
PRIMARY KEY (`name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='User defined functions' |
+-------+----------------------------------------------------------------------------------------------------------------------
5.查看当前是哪个用户
mysql>select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
6.查看当前所在数据库
mysql>select database();
+------------+
| database() |
+------------+
| mysql |
+------------+
7.创建一个新库
mysql>create database db1;
Query OK, 1 row affected (0.04 sec)
8.创建一个表
mysql>create table t1 ( `id` int(4), `name` char(40));
Query OK, 0 rows affected (0.02 sec)
mysql>desc t1;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(4) | YES | | NULL | |
| name | char(40) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
9.查看当前数据库版本
mysql>select version();
+-----------+
| version() |
+-----------+
| 5.0.86 |
+-----------+
10.查看当前系统时间
mysql>select current_date, current_time;
+--------------+--------------+
| current_date | current_time |
+--------------+--------------+
| 2011-05-31 | 08:52:50 |
+--------------+--------------+
11.查看当前mysql的状态
mysql> show status;
+-----------------------------------+----------+
| Variable_name | Value |
+-----------------------------------+----------+
| Aborted_clients | 0 |
| Aborted_connects | 1 |
| Binlog_cache_disk_use | 0 |
| Binlog_cache_use | 0 |
| Bytes_received | 664 |
| Bytes_sent | 6703 |
这个命令打出很多东西,显示你的mysql状态。
12.查看mysql的参数
mysql>show variables;
很多参数都是可以在/etc/my.cnf中定义的。
13.创建一个普通用户并授权
mysql>grant all on *.* to user1 identified by '123456';
Query OK, 0 rows affected (0.01 sec)
all表示所有的权限(读、写、查询、删除等等操作),*.*前面的*表示所有的数据库,后面的*表示所有的表,identified by后面跟密码,用单引号括起来。这里的user1指的是localhost上的user1,如果是给网络上的其他机器上的某个用户授权则这样:
mysql>grant all on db1.* to 'user2'@'10.0.2.100' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
用户和主机的IP之间有一个@,另外主机IP那里可以用%替代,表示所有主机。例如:
mysql>grant all on db1.* to 'user3'@'%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
【一些常用的sql】
1.查询语句
mysql>select count(*) from mysql.user;
mysql.user表示mysql库的user表;count(*)表示表中共有多少行。
mysql>select * from mysql.db;
查询mysql库的db表中的所有数据
mysql>select db from mysql.db;
查询mysql库db表的db段。
mysql>select * from mysql.db where host like '10.0.%';
查询mysql库db表host字段like 10.0.%的行,这里的%表示匹配所有,类似于前面介绍的通配符。
2.插入一行
mysql>insert into db1.t1 values (1, 'abc');
Query OK, 1 row affected (0.00 sec)
t1表在前面已经创建过。
mysql>select * from db1.t1;
+------+------+
| id | name |
+------+------+
| 1 | abc |
+------+------+
3.更改某一行
mysql>update db1.t1 set name='aaa' where id=1;
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
这样就把原来id为1的那行中的name改成’aaa’
4.删除表
mysql>drop table db1.t1;
Query OK, 0 rows affected (0.01 sec)
5.删除数据库
mysql>drop database db1;
Query OK, 0 rows affected (0.07 sec)
6.备份与恢复库
mysqldump -uroot -p mysql >mysql.sql
这里的mysqldump 就是备份的工具了,-p后面的mysql指的是mysql库,把备份的文件重定向到mysql.sql。如果恢复的话,只要:
mysql -uroot -p mysql < mysql.sql
关于MySQL的基本操作笔者就介绍这么多,当然学会了这些还远远不够,希望你能够在你的工作中学习到更多的知识,如果你对MySQL有很大兴趣,不妨深入研究一下,毕竟多学点总没有坏处
【什么是NFS】
NFS会经常用到,用于在网络上共享存储。这样讲,你对NFS可能不太了解,笔者不妨举一个例子来说明一下NFS是用来做什么的。假如有三台机器A、B、C,它们需要访问同一个目录,目录中都是图片,传统的做法是把这些图片分别放到A、B、C。但是使用NFS只需要放到A上,然后A共享给B和C即可。访问的时候,B和C是通过网络的方式去访问A上的那个目录的。
【配置NFS】
NFS配置起来还是蛮简单的,只需要编辑配置文件/etc/exports即可。下面笔者先创建一个简单的NFS服务器。
[root@localhost ~]
/home/ 10.0.2.0/24(rw,sync,all_squash,anonuid=501,anongid=501)
这个配置文件就这样简单一行。共分为三部分,第一部分就是本地要共享出去的目录,第二部分为允许访问的主机(可以是一个IP也可以是一个IP段)第三部分就是小括号里面的,为一些权限选项。关于第三部分,笔者简单介绍一下:
rw:读写;
ro:只读;
sync:同步模式,内存中数据时时写入磁盘;
async:不同步,把内存中数据定期写入磁盘中;
no_root_squash:加上这个选项后,root用户就会对共享的目录拥有至高的权限控制,就像是对本机的目录操作一样。不安全,不建议使用;
root_squash:和上面的选项对应,root用户对共享目录的权限不高,只有普通用户的权限,即限制了root;
all_squash:不管使用NFS的用户是谁,他的身份都会被限定成为一个指定的普通用户身份;
anonuid/anongid:要和root_squash以及all_squash一同使用,用于指定使用NFS的用户限定后的uid和gid,前提是本机的/etc/passwd中存在这个uid和gid。
介绍了上面的相关的权限选项后,再来分析一下笔者刚刚配置的那个/etc/exports文件。其中要共享的目录为/home,信任的主机为10.0.2.0/24这个网段,权限为读写,同步,限定所有使用者,并且限定的uid和gid都为501。
【使用NFS】
当编辑完配置文件/etc/exports后,就该启动NFS服务了。启动方法为:
[root@localhost ~]
NFS是依托portmap的,所以首先要启动portmap,然后启动NFS才能是刚才的配置生效。启动完NFS后,就该使用NFS服务了。
[root@localhost ~]
Export list for 127.0.0.1:
/home 10.0.2.0/24
用shoumount -e加IP就可以查看NFS的共享情况,上例中,就可以看到127.0.0.1的共享目录为/home,信任主机为10.0.2.0/24这个网段。另外这个showmount命令还有一个常用的选项就是-a了,它的意思是,把连接本机的NFS的client全部列出。
[root@localhost ~]
[root@localhost ~]
All mount points on localhost:
10.0.2.69:/home
前面的mount命令为挂载NFS共享目录,相信你能看懂这个格式。showmount -a命令列出所有的clinet。
NFS服务中还有一个常用的命令那就是exportfs,它的常用选项为[-aruv]。
-a:全部挂载或者卸载;
-r:重新挂载;
-u:卸载某一个目录;
-v:显示共享的目录;
使用exportfs命令,当改变/etc/exports配置文件后,不用重启nfs服务直接用这个exportfs即可。
[root@localhost ~]
/tmp/ 10.0.2.0/24(rw,sync,no_root_squash)
[root@localhost ~]
exporting 10.0.2.0/24:/tmp
更改目录后,直接exportfs -arv即可生效。
在上面使用到了mount命令来挂载nfs,其实mount这个nfs服务还是有些说法的。首先是用-t nfs来指定挂载的类型为nfs。另外在使用nfs时,常用一个选项就是nolock了,即在挂载nfs服务时,不加锁。
[root@localhost ~]
[root@localhost ~]
All mount points on localhost:
10.0.2.69:/home
10.0.2.69:/tmp
另外我们还可以把要挂载的nfs目录写到client上的/etc/fstab文件中,挂载时只需要mount -a即可。
[root@localhost ~]
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
LABEL=SWAP-hda2 swap swap defaults 0 0
10.0.2.69:/tmp /mnt nfs nolock 0 0
写完/etc/fstab文件后,只需要mount -a即可挂载nfs服务的共享目录。
[root@localhost ~]
[root@localhost ~]
[root@localhost ~]
Filesystem Size Used Avail Use% Mounted on
/dev/hda3 7.3G 3.7G 3.3G 53% /
/dev/hda1 99M 12M 83M 12% /boot
tmpfs 84M 0 84M 0% /dev/shm
10.0.2.69:/tmp 7.3G 3.7G 3.3G 53% /mnt
【什么是FTP】
也许你对FTP不陌生,但是你是否了解FTP到底是个什么玩意?FTP是File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于Internet上的控制文件的双向传输。同时,它也是一个应用程序(Application)。用户可以通过它把自己的PC机与世界各地所有运行FTP协议的服务器相连,访问服务器上的大量程序和信息。FTP的主要作用,就是让用户连接上一个远程计算机(这些计算机上运行着FTP服务器程序)察看远程计算机有哪些文件,然后把文件从远程计算机上拷到本地计算机,或把本地计算机的文件送到远程计算机去。FTP用的比NFS更多,所以你一定要熟练配置它。
【配置ftp】
安装Redhat/CentOS系统时也许你会连带着把ftp装上,系统默认带的ftp是vsftp,比较常用,配置也很简单。但笔者常使用的ftp软件为pure-ftpd。因为这个软件比vsftp配置起来更加灵活和安全。下面是笔者配置pure-ftpd的过程:
下载最新的pure-ftp源码包pure-ftpd-1.0.21.tar.bz2
./configure \
"--prefix=/usr/local/pureftpd" \
"--without-inetd" \
"--with-altlog" \
"--with-puredb" \
"--with-throttling" \
"--with-largefile" \
"--with-peruserlimits" \
"--with-tls" \
"--with-language=simplified-chinese"
启动
用配置文件
在启动pure-ftp之前需要先修改配置文件,配置文件为/usr/local/pureftpd/etc/pure-ftpd.conf,你可以打开看一下,里面内容很多,如果你英文好,可以好好研究一番,下面是我的配置文件,如果你嫌麻烦,直接拷贝过去即可。
____________________________________
ChrootEveryone yes
BrokenClientsCompatibility no
MaxClientsNumber 50
Daemonize yes
MaxClientsPerIP 8
VerboseLog no
DisplayDotFiles yes
AnonymousOnly no
NoAnonymous no
SyslogFacility ftp
DontResolve yes
MaxIdleTime 15
PureDB /usr/local/pureftpd/etc/pureftpd.pdb
LimitRecursion 2000 8
AnonymousCanCreateDirs no
MaxLoad 4
AntiWarez yes
Umask 133:022
MinUID 100
AllowUserFXP no
AllowAnonymousFXP no
ProhibitDotFilesWrite no
ProhibitDotFilesRead no
AutoRename no
AnonymousCantUpload no
PIDFile /usr/local/pureftpd/var/run/pure-ftpd.pid
MaxDiskUsage 99
CustomerProof yes
启动命令:/usr/local/pureftpd/sbin/pure-config.pl /usr/local/pureftpd/etc/pure-ftpd.conf
【什么是squid】
Squid是比较知名的代理软件,它不仅可以跑在linux上还可以跑在windows以及Unix上,它的技术已经非常成熟。目前使用Squid的用户也是十分广泛的。Squid与Linux下其它的代理软件如Apache、Socks、TIS FWTK和delegate相比,下载安装简单,配置简单灵活,支持缓存和多种协议。
Squid的缓存功能相当好用,不仅可以减少带宽的占用,同样也大大降低了后台的WEB服务器的磁盘I/O的压力。Squid接收用户的下载申请,并自动处理所下载的数据。也就是说,当一个用户象要下载一个主页时,它向Squid发出一个申请,要Squid替它下载,然后Squid连接所申请网站并请求该主页,接着把该主页传给用户同时保留一个备份,当别的用户申请同样的页面时,Squid把保存的备份立即传给用户,使用户觉得速度相当快。
Squid将数据元缓存在内存中,同时也缓存DNS查寻的结果,除此之外,它还支持非模块化的DNS查询,对失败的请求进行消极缓存。Squid支持SSL,支持访问控制。由于使用了ICP,Squid能够实现重叠的代理阵列,从而最大限度的节约带宽。
Squid对硬件的要求是内存一定要大,不应小于128M,硬盘转速越快越好,最好使用服务器专用SCSI硬盘,处理器要求不高,400MH以上既可。
【安装squid】
wget http://www.squid-cache.org/Versions/v2/2.6/squid-2.6.STABLE20.tar.gz
tar zxvf squid-2.6.STABLE20.tar.gz
cd squid-2.6.STABLE20
ulimit -HSn 65535
useradd squid编译参数./configure --prefix=/usr/local/squid \
--disable-dependency-tracking \
--enable-dlmalloc \
--enable-gnuregex \
--disable-carp \
--enable-async-io=240 \
--with-pthreads \
--enable-storeio=ufs,aufs,diskd,null \
--disable-wccp \
--disable-wccpv2 \
--enable-kill-parent-hack \
--enable-cachemgr-hostname=localhost \
--enable-default-err-language=Simplify_Chinese \
--with-build-environment=POSIX_V6_ILP32_OFFBIG \
--with-maxfd=65535 \
--with-aio \
--disable-poll \
--enable-epoll \
--enable-linux-netfilter \
--enable-large-cache-files \
--disable-ident-lookups \
--enable-default-hostsfile=/etc/hosts \
--with-dl \
--with-large-files \
--enable-removal-policies=heap,lru \
--enable-delay-pools \
--enable-snmp \
--disable-internal-dns
make && make install
关于squid的版本,有必要提一下,目前squid最新版本已经到了3.1了,但是笔者认为2.6版本比较好用,如果你有兴趣可以研究一下3.1。
【squid配置】
编辑配置文件/usr/local/squid/etc/squid.conf
把原来配置文件删除,替换成:
http_port 80 transparent
cache_replacement_policy lru
修改完配置文件后保存,然后初始化squid
mkdir /cache1 /cache2 /var/log/squid
chown -R squid:squid /cache1 /cache2 /var/log/squid
/usr/local/squid/sbin/squid -z
nohup /usr/local/squid/bin/RunCache &
启动后,可以去看看cache.log在这个日志中,你可以看到很多关于squid的信息,当然也包括一些错误日志。
如果想开机启动则需要在/etc/rc.d/rc.local中最后加入一行
/usr/local/bin/RunCache &
到这里算是配置完成了,但是还有一个问题,就是如何定义被代理的web以及域名?单单看配置文件并没有说代理的web是哪一个。确实,这个配置文件其实可以代理多台web,只要你在/etc/hosts中定义要代理的域名以及IP即可,hosts格式在前面已经介绍过。笔者要提醒你的是,如果是一台web上的多个域名,请不要写一行,虽然hosts是允许的,但是如果写成一个IP对应多个域名,squid代理时就会出错。所以有几个域名就要写几行。
更改/etc/hosts后要重启squid才能生效:
/usr/local/squid/sbin/squid -krec
在重启前可以先检测一下,是否有错,命令为:
/usr/local/squid/sbin/squid –kcheck
如果没有错,则不会显示任何信息,否则会显示一些信息出来。
【关于Tomcat】
目前有很多网站使用jsp的程序编写,所以解析jsp的程序就必须要有相关的软件来完成。Tomcat就是用来解析jsp程序的一个软件,Tomcat是Apache软件基金会(Apache
Software Foundation)的Jakarta项目中的一个核心项目,由Apache、Sun和其他一些公司及个人共同开发而成。因为Tomcat技术先进、性能稳定,而且免费,因而深受Java爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web应用服务器。
Tomcat是一个轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP程序的首选。对于一个初学者来说,可以这样认为,当在一台机器上配置好Apache服务器,可利用它响应对HTML页面的访问请求。实际上Tomcat部分是Apache服务器的扩展,但它是独立运行的,所以当你运行tomcat时,它实际上作为一个与Apache独立的进程单独运行的。
【安装Tomcat】
Tomcat的安装分为两个步骤:安装JDK;安装Tomcat。
JDK(Java Development Kit)是Sun Microsystems针对Java开发员的产品。自从Java推出以来,JDK已经成为使用最广泛的Java SDK。JDK是整个Java的核心,包括了Java运行环境,Java工具和Java基础的类库。所以要想运行jsp的程序必须要有JDK的支持,理所当然安装Tomcat的前提是安装好JDK。
1.安装JDK
下载jdk-6u23-linux-i586.bin
cd /usr/local/src/
wget http://dl.dropbox.com/u/182853/jdk-6u23-linux-i586.bin
(如果该版本不合适请到下面的官方网站下载适合你的版本):
https://cds.sun.com/is-bin/INTERSHOP.enfinity/WFS/CDS-CDS_Developer-Site/en_US/-/USD/ViewProductDetail-Start?ProductRef=jdk-6u23-oth-JPR@CDS-CDS_Developer
chmod a+x jdk-6u23-linux-i586.bin
sh jdk-6u23-linux-i586.bin
此时会出现JDK安装授权协议。可以一路按Enter浏览,当出现Do you agree to the above
license terms? [yes or no]的字样,输入yes即可。
mv jdk1.6.0_23 /usr/local/
2.设置环境变量
vim /etc/profile
在末尾输入以下内容
JAVA_HOME=/usr/local/jdk1.6.0_23/
JAVA_BIN=/usr/local/jdk1.6.0_23/bin
JRE_HOME=/usr/local/jdk1.6.0_23/jre
PATH=$PATH:/usr/local/jdk1.6.0_23/bin:/usr/local/jdk1.6.0_23/jre/bin
CLASSPATH=/usr/local/jdk1.6.0_23/jre/lib:/usr/local/jdk1.6.0_23/lib:/usr/local/jdk1.6.0_23/jre/lib/charsets.jar
export JAVA_HOME JAVA_BIN
JRE_HOME PATH CLASSPATH执行命令source /etc/profile,使配置立即生效
source /etc/profile
检测是否设置正确:
java –version
如果显示如下内容,则配置正确。
java version "1.4.2"
gij (GNU libgcj) version 4.1.2 20080704
(Red Hat 4.1.2-46)
Copyright (C) 2006 Free Software
Foundation, Inc.
This is free software; see the source for
copying conditions. There is NO warranty; not even for MERCHANTABILITY or
FITNESS FOR A PARTICULAR PURPOSE.
3.安装Tomcat
cd /usr/local/src/
wget http://archive.apache.org/dist/tomcat/tomcat-7/v7.0.14/bin/apache-tomcat-7.0.14.tar.gz
如果觉得这个版本不适合你,请到tomcat官方网站下载适合你的版本。
tar zxvf apache-tomcat-7.0.14.tar.gz
mv apache-tomcat-7.0.14 /usr/local/tomcat
cp -p /usr/local/tomcat/bin/catalina.sh
/etc/init.d/tomcat
vim /etc/init.d/tomcat
在第二行加入以下内容:
JAVA_HOME=/usr/local/jdk1.6.0_23/
CATALINA_HOME=/usr/local/tomcat
chmod 755 /etc/init.d/tomcat
chkconfig --add tomcat
chkconfig tomcat on
启动tomcat:
service tomcat start
查看是否启动成功:
ps aux |grep tomcat
如果有进程的话,请在浏览器中输入http://IP:8080/你会看到tomcat的主界面。
【配置tomcat】
在配置tomcat前,先来看看tomcat的几个目录:
find /usr/local/tomcat/ -maxdepth 1
-type d(-maxdepth的作用指定目录级数,后边跟1代表只查找1级目录)
/usr/local/tomcat/
/usr/local/tomcat/lib
tomcat的库文件目录
/usr/local/tomcat/temp 临时文件存放目录
/usr/local/tomcat/webapps
web应用目录,也就是我们访问的web程序文件所在目录
/usr/local/tomcat/conf 配置文件目录
/usr/local/tomcat/logs 日志文件所在目录
/usr/local/tomcat/work 存放JSP编译后产生的class文件
/usr/local/tomcat/bin
tomcat的脚本文件
Tomcat的主配置文件为/usr/local/tomcat/conf/server.xml
1.配置tomcat服务的访问端口。
默认是8080,如果你想修改为80,则需要修改server.xml文件。
找到 <Connector
port="8080" protocol="HTTP/1.1"
修改为:<Connector
port="80" protocol="HTTP/1.1"
2.配置新的虚拟主机
cd /usr/local/tomcat/conf/
vim server.xml
找到</Host>,下一行插入新的<Host>,内容如下:
<Host
name="www.example.cn" appBase="/data/tomcatweb"
unpackWARs="false" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
<Context
path="" docBase="./" debug="0"
reloadable="true" crossContext="true"/>
</Host>
完成后,重启tomcat
service tomcat stop; service tomcat start
测试新建的虚拟主机,首先需要修改你电脑的hosts文件
vim /data/tomcatweb/test.jsp加入以下内容:
<html><body><center>
Now time is: <%=new
java.util.Date()%>
</center></body></html>
保存后,在你的浏览器里输入 http://www.example.cn/test.jsp看是否访问到如下内容:
以前我们在windows上共享文件的话,只需右击要共享的文件夹然后选择共享相关的选项设置即可。然而如何实现windows和linux的文件共享呢?这就涉及到了samba服务了,这个软件配置起来也不难,使用也非常简单。
【samba配置文件smb.conf】
一般你装系统的时候会默认安装samba,如果没有安装,只需要运行这个命令安装(CentOS):
“yum
install -y samba samba-client”
Samba的配置文件为/etc/samba/smb.conf,通过修改这个配置文件来完成我们的各种需求。打开这个配置文件,你会发现很多内容都用”
10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">或者”;”注视掉了。先看一下未被注释掉的部分:
[global]
workgroup = MYGROUP
server string = Samba Server Version %v
security = user
passdb backend = tdbsam
load
printers = yes
cups
options = raw
[homes]
comment = Home Directories
browseable = no
writable = yes
[printers]
comment = All Printers
path = /var/spool/samba
browseable = no
guest ok = no
writable = no
printable = yes
主要有以上三个部分:[global], [homes], [printers]。
[global]定义全局的配置,”workgroup”用来定义工作组,相信如果你安装过windows的系统,你会对这个workgroup不陌生。一般情况下,需要我们把这里的”MYGROUP”改成”WORKGROUP”(windows默认的工作组名字)。
security
= user
mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">这里指定samba的安全等级。关于安全等级有四种:
share:用户不需要账户及密码即可登录samba服务器
user:由提供服务的samba服务器负责检查账户及密码(默认)
server:检查账户及密码的工作由另一台windows或samba服务器负责
domain:指定windows域控制服务器来验证用户的账户及密码。
passdb
backend = tdbsam mso-hansi-font-family:Calibri">(用户后台),samba有三种用户后台:smbpasswd, tdbsam和ldapsam.
smbpasswd:该方式是使用smb工具smbpasswd给系统用户(真实用户或者虚拟用户)设置一个Samba密码,客户端就用此密码访问Samba资源。smbpasswd在/etc/samba中,有时需要手工创建该文件。
tdbsam:使用数据库文件创建用户数据库。数据库文件叫passdb.tdb,在/etc/samba中。passdb.tdb用户数据库可使用smbpasswd–a创建Samba用户,要创建的Samba用户必须先是系统用户。也可使用pdbedit创建Samba账户。pdbedit参数很多,列出几个主要的:
pdbedit–a username:新建Samba账户。
pdbedit–x username:删除Samba账户。
pdbedit–L:列出Samba用户列表,读取passdb.tdb数据库文件。
pdbedit–Lv:列出Samba用户列表详细信息。
pdbedit–c“[D]”–u username:暂停该Samba用户账号。
pdbedit–c“[]”–u username:恢复该Samba用户账号。
ldapsam:基于LDAP账户管理方式验证用户。首先要建立LDAP服务,设置“passdb backend =
ldapsam:ldap://LDAP Server”
load
printers和cups options两个参数用来设置打印机相关。
除了这些参数外,还有几个参数需要你了解:
netbios
name = MYSERVER mso-hansi-font-family:Calibri">设置出现在“网上邻居”中的主机名
hosts
allow = 127. 192.168.12. 192.168.13.
mso-hansi-font-family:Calibri">用来设置允许的主机,如果在前面加”;”则表示允许所有主机
log file
= /var/log/samba/%m.log
font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">定义samba的日志,这里的%m是上面的netbios name
max log
size = 50
mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">指定日志的最大容量,单位是K
[homes]该部分内容共享用户自己的家目录,也就是说,当用户登录到samba服务器上时实际上是进入到了该用户的家目录,用户登陆后,共享名不是homes而是用户自己的标识符,对于单纯的文件共享的环境来说,这部分可以注视掉。
[printers]该部分内容设置打印机共享。
【samba实践】
注意:在试验之前,请先检测selinux是否关闭,否则可能会试验不成功。关于如何关闭selinux请查看第十五章 linux系统日常管理的“linux的防火墙”部分
1.共享一个目录,任何人都可以访问,即不用输入密码即可访问,要求只读。
打开samba的配置文件/etc/samba/smb.conf
[global]部分
把”MY GROUP”改成”WORKGROUP”
把”security = user”修改为“security = share”
然后在文件的最末尾处加入以下内容:
[share]
comment = share all
path
= /tmp/samba
browseable = yes
public = yes
writable = no
mkdir
/tmp/samba
chmod 777
/tmp/samba
启动samba服务
/etc/init.d/smb
start
测试:
首先测试你配置的smb.conf是否正确,用下面的命令
testparm
如果没有错误,则在你的windows机器上的浏览器中输入file://IP/share看是否能访问
2.共享一个目录,使用用户名和密码登录后才可以访问,要求可以读写
打开samba的配置文件/etc/samba/smb.conf
[global]部分内容如下:
[global]
workgroup = WORKGROUP
server string = Samba Server Version %v
security
= user
passdb backend = tdbsam
load
printers = yes
cups
options = raw
然后加入以下内容:
[myshare]
comment = share for users
path
= /samba
browseable = yes
writable = yes
public
= no
保存配置文件,创建目录:
mkdir /samba
chmod 777
/samba
然后添加用户。因为在[globa]中” passdb backend = tdbsam”,所以要使用” pdbedit”来增加用户,注意添加的用户必须在系统中存在。
useradd user1 user2
pdbedit
-a user1 mso-hansi-font-family:Calibri">添加user1账号,并定义其密码
pdbedit
-a user2
pdbedit
-L
Calibri;mso-hansi-font-family:Calibri">列出所有的账号
测试:
打开IE浏览器输入file://IP/myshare/然后输入用户名和密码
3.使用linux访问samba服务器
Samba服务在linux下同样可以访问。前提是你的linux安装了samba-client软件包。安装完后就可以使用smbclient命令了。
smbclient
//IP/共享名 -U用户名
如:[root@localhost]
Password:
Domain=[LOCALHOST]
OS=[Unix] Server=[Samba 3.0.33-3.29.el5_6.2]
smb:
\>
出现如上所示的界面。可以打一个”?”列出所有可以使用的命令。常用的有cd, ls, rm, pwd, tar, mkdir,
chown, get, put等等,使用help +命令可以打印该命令如何使用,其中get是下载,put是上传。
另外的方式就是通过mount挂载了:
如:
mount -t cifs //10.0.4.67/myshare /mnt -o
username=user1,password=123456
格式就是这样,要指定-t cifs //IP/共享名本地挂载点 -o后面跟username和password
挂载完后就可以像使用本地的目录一样使用共享的目录了。
【关于Nagios】
Nagios是一款用于监控系统和网络的开源应用软件,它的模式是服务器—客户端,也就是说首先要在在一台服务器上(server)部署相应的主要套件,然后在要监控的服务器上部署客户端程序,这样server会和client通信,从而监控client端的各项资源。Nagios功能十分强大几乎所有的项目都可以监控,大到服务器的存活状态,小到服务器上的某一个服务(web)。这些功能都是通过自定义插件(或者叫做脚本)来实现。
当Nagios监控到某项资源发生异常会通知到用户,你可以接入手机短信接口也可以接入邮件接口。我们可以通过web页面来查看Nagios所监控的各项资源,默认搭建的Nagios服务器只能监控简单的几个项目,而其他服务之类的监控项目都是由我们自己开发的插件来实现的。
【需要下载的软件】
nagios-3.0.5
nagios-plugins-1.4.13
nrpe-2.12.tar.gz
apache-2.2.11
// 以上软件版本可以不一样
【监控中心Server端的配置】
1. 安装apache (略,请参考第16章中相关内容,只需安装,到后边再配置)
2. 建立nagios账户
useradd nagios
3. 下载软件
cd /usr/local/src/
wget http://syslab.comsenz.com/downloads/linux/nagios-3.0.5.tar.gz
wget http://syslab.comsenz.com/downloads/linux/nagios-plugins-1.4.13.tar.gz
wget http://syslab.comsenz.com/downloads/linux/nrpe-2.12.tar.gz
4. 编译安装nagios
cd /usr/local/src/
tar zxvf nagios-3.0.5.tar.gz
cd nagios-3.0.5
./configure --prefix=/usr/local/nagios
make all
make install
make install-init 10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">把nagios做成一个运行脚本,使nagios随系统开机启动
make install-config 10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">把配置文件样例复制到nagios的安装目录
make install-commandmode
mso-hansi-font-family:Calibri">给外部命令访问nagios配置文件的权限
chown -R nagios:nagios /usr/local/nagios
5. 编译安装nagios-plugins
cd /usr/local/src/
tar zxvf nagios-plugins-1.4.13.tar.gz
cd nagios-plugins-1.4.13
./configure --prefix=/usr/local/nagios
--with-nagios-user=nagios --with-nagios-group=nagios
make && make install
查看是否安装成功的方法是:
ls /usr/local/nagios/libexec/
看这个目录下是否有插件文件
6. 安装nrpe
cd /usr/local/src/
tar zxvf nrpe-2.12.tar.gz
cd nrpe-2.12
./configure --enable-ssl --enable-command-args
make all
make install-plugin
make install-daemon
make install-daemon-config
7. 配置web接口
vim /usr/local/apache2/conf/httpd.conf
在最后加入以下内容:
ScriptAlias
/nagios/cgi-bin /usr/local/nagios/sbin
<Directory
"/usr/local/nagios/sbin/">
AllowOverride
AuthConfig
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
Alias /nagios/ /usr/local/nagios/share/
<Directory
"/usr/local/nagios/share">
Options None
AllowOverride
AuthConfig
Order allow,deny
Allow from all
</Directory>
8. 配置nagios
cd /usr/local/nagios/etc/
vim cgi.cfg
把 use_authentication=1 改成 use_authentication=0 意思是不用用户验证
9. 启动nagios
在启动前先检测一下:
/usr/local/nagios/bin/nagios -v
/usr/local/nagios/etc/nagios.cfg
如果最后显示如下,则说明配置没有问题了。
Total Warnings:
0
Total
Errors: 0
启动命令:
/etc/init.d/nagios start
或者:
/usr/local/nagios/bin/nagios -d
/usr/local/nagios/etc/nagios.cfg
此时,就可以访问web页面的nagios了,在浏览器中输入:
http://IP/nagios/ 看看吧。
【在要监控的机器上client部署nagios】
如果你打开了web页面,点击左栏的Host Detail 会在右栏看到一行数据,其中Host 名为 “localhost” ,Status显示为”up”,并且显示为绿色,如果是其他颜色就说明你的localhost出了问题。目前只有一行数据,也就是说只监控了监控中心(localhost)一台主机,那么如何添加其他机器被它监控呢?这就需要在要被监控的机器上也部署nagios软件。
1. 添加账户
useradd nagios
2. 安装nrpe
cd /usr/local/src/
wget http://syslab.comsenz.com/downloads/linux/nrpe-2.12.tar.gz
tar zxvf nrpe-2.12.tar.gz
cd nrpe-2.12
./configure --enable-ssl
--enable-command-args
make all
make install-plugin
make install-daemon
make install-daemon-config
3. 安装nagios-plugin
cd /usr/local/src/
wget http://syslab.comsenz.com/downloads/linux/nagios-plugins-1.4.13.tar.gz
tar zxvf nagios-plugins-1.4.13.tar.gz
cd nagios-plugins-1.4.13
./configure --prefix=/usr/local/nagios
--with-nagios-user=nagios --with-nagios-group=nagios
make && make install
到此就算安装完成了,请查看/usr/local/nagios/目录下是否有四个目录分别为:bin etc libexec share 另外在libexec目录下会有很多check_开头的文件。如果你的机器上没有,就请重新安装吧。
4. 配置
vim /usr/local/nagios/etc/nrpe.cfg
找到”allowed_hosts=127.0.0.1” 改成 “allowed_hosts=127.0.0.1,10.0.4.67”
// 后边的IP是server的IP
找到” dont_blame_nrpe=0” 改成 “dont_blame_nrpe=1”
5. 启动nrpe
/usr/local/nagios/bin/nrpe -c
/usr/local/nagios/etc/nrpe.cfg -d
【在监控中心添加被监控主机】
添加主机当然是要到server端(监控中心)修改配置文件了。
1. 修改主配置文件
cd /usr/local/nagios/etc/
vim nagios.cfg
增加内容:
cfg_dir=/usr/local/nagios/etc/services 10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">定义一个目录,以后把新增加的主机信息文件全部放到这里
2. 添加被监控主机信息
mkdir /usr/local/nagios/etc/services
cd /usr/local/nagios/etc/services
vim 10.0.4.56.cfg 加入如下内容:
define
host{
use linux-server
host_name 10.0.4.56
alias 10.0.4.56
address 10.0.4.56
}
define
service{
use generic-service
host_name 10.0.4.56
service_description check_ping
check_command check_ping!100.0,20%!200.0,50%
max_check_attempts 5
normal_check_interval 1
}
define
service{
use generic-service
host_name 10.0.4.56
service_description check_ssh
check_command check_ssh
max_check_attempts 5
normal_check_interval 1
}
define
service{
use generic-service
host_name 10.0.4.56
service_description check_http
check_command check_http
max_check_attempts 5
normal_check_interval 1
}
// 注意,这里的IP是client端的IP,监控的项目有三个ping, ssh, http。其实这三个项目使用的脚本都为本地脚本,也就是说,即使远程主机没有安装nagios和nrpe同样可以监控这些项目。但是如果想监控load,disk,等等就需要通过nrpe服务来搞定了,道理很简单,load和disk都需要登录到远程主机上去获得信息,而ping,ssh,http都不需要的。这个到远程主机获取相关的信息的过程是由nrpe完成的。如果你的client上没有启动nrpe服务那么我们是无法获取远程主机的load和disk等信息的。下面笔者配置一下使用nrpe来监控远程主机的相关项目。
在server端编辑/usr/local/nagios/etc/objects/commands.cfg
vim /usr/local/nagios/etc/objects/commands.cfg 10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">在最后面添加如下内容
define
command{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
然后编辑10.0.4.56.cfg (还是server上)
cd /usr/local/nagios/etc/services
vim 10.0.4.56.cfg 10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">加入如下内容:
define
service{
use generic-service
host_name 10.0.4.56
service_description check_load
check_command check_nrpe!check_load
max_check_attempts 5
normal_check_interval 1
}
define
service{
use generic-service
host_name 10.0.4.56
service_description check_disk_hda1
check_command check_nrpe!check_hda1
max_check_attempts 5
normal_check_interval 1
}
define
service{
use generic-service
host_name 10.0.4.56
service_description check_disk_hda2
check_command check_nrpe!check_hda2
max_check_attempts 5
normal_check_interval
1
}
// 这里需要解释一下相关的”check_command”, 先看这个” check_nrpe!check_load” 这里的check_nrpe就是上面/usr/local/nagios/etc/objects/commands.cfg中刚刚定义的,后面的check_load是在远程主机上定义的一个命令脚本。具体在哪里定义稍后介绍。为什么中间加一个”!”,这个是nagios特有的形式,无需关心。下面需要到远程主机上去定义上面用到的脚本了。
在远程主机上编辑/usr/local/nagios/etc/nrpe.cfg 文件
vim /usr/local/nagios/etc/nrpe.cfg (client上)
把” command[check_hda1]”那行改成:
command[check_hda1]=/usr/local/nagios/libexec/check_disk
-w 20% -c 10% -p /dev/hda1
然后再增加一行:
command[check_hda2]=/usr/local/nagios/libexec/check_disk
-w 20% -c 10% -p /dev/hda2
// 这里的check_hda1 和 check_hda2 都是自定义的,和server端的定义的service中的check_command对应。也就是说,如果在server端定义了一个service(通过nrpe方式)那么必须要在客户端上的nrpe.cfg中定义相应的脚本。保存这个文件后,需要重新启动一下nrpe服务。
killall nrpe ; /usr/local/nagios/bin/nrpe -c
/usr/local/nagios/etc/nrpe.cfg -d (client上)
3. 重启nagios服务
修改了配置需要重启服务才能使添加的监控主机生效。
/etc/init.d/nagios restart (server上)
此时再到web页面去观察是否多了一台10.0.4.56
【在nagios客户端上自定义监控脚本】
在开始,笔者就讲过,我们可以自定义写监控脚步,从上面的例子中也可以看到监控磁盘状态时,是根据磁盘分区来监控的。这样不免有些麻烦,因为每台主机的磁盘分区状况都不一样(一样还好),而且有多少个分区就需要定义多少个命令。所以笔者就自定义写一个shell脚本来监控所有的磁盘分区:
1. 在客户端上创建脚本/usr/local/nagios/libexec/check_disk.sh
vim /usr/local/nagios/libexec/check_disk.sh 写入如下内容:(client上)
row=`df
-h -P|wc -l`
status=0
for i in
`seq 2 $row`
do
spare=`df -h -P|sed -n "$i"p|awk '{print $4}'`
use_percentage=`df -h -P|sed -n "$i"p|sed -n
"s/\%//"p|awk '{print $5}'`
spare_percentage=`expr 100 - $use_percentage`
partition_name=`df -h -P|sed
-n "$i"p|awk '{print $6}'`
if [
"$spare_percentage" -lt "3" ];then
echo -n "$partition_name CRITICAL ${spare_percentage}% $spare "
status[$i]=2
elif
[ "$spare_percentage" -lt "5" ];then
echo -n "$partition_name WARNING! ${spare_percentage}% $spare "
status[$i]=1
else
echo -n "$partition_name OK ${spare_percentage}% $spare "
status[$i]=0
fi
done
zhuangtai=0
for j in
`seq 2 $row`
do
if [
"${status[$j]}" -gt "$zhuangtai" ];then
zhuangtai=${status[$j]}
fi
done
exit
$zhuangtai
2. 保存后,修改该脚本的权限
chmod +x /usr/local/nagios/libexec/check_disk.sh (client上)
3. 然后编辑/usr/local/nagios/etc/nrpe.cfg文件
vim /usr/local/nagios/etc/nrpe.cfg 10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">加入一行:(client上)
command[check_disk]=/usr/local/nagios/libexec/check_disk.sh
保存,重启nrpe服务
killall nrpe ; /usr/local/nagios/bin/nrpe -c
/usr/local/nagios/etc/nrpe.cfg -d (client上)
4. 检测刚才的脚本是否正常运行的方法是,到server端执行如下命令:
/usr/local/nagios/libexec/check_nrpe -H
10.0.4.56 -c check_disk (server上)
如果正常的话,会输出一行磁盘检测的数据,否则可能会报错。
5. 到server上添加相应的service
cd /usr/local/nagios/etc/services (server上)
vim 10.0.4.56.cfg 10.5pt;font-family:宋体;mso-ascii-font-family:Calibri;mso-hansi-font-family:Calibri">加入如下内容:
define
service{
use generic-service
host_name 10.0.4.56
service_description check_disk
check_command check_nrpe!check_disk
max_check_attempts 5
normal_check_interval 1
}
6. 重启nagios服务
/etc/init.d/nagios restart (server上)
【配置nagios报警邮件】
现在139邮箱有顺便发短信的功能,所以当有报警时,只需发送到你的139邮箱你就同样会收到一条报警短信。这样做的优势就是不用再去买短信网关了,节省了很大一笔钱。
vim
/usr/local/nagios/etc/objects/contacts.cfg
把” email nagios@localhost” 修改成 “email 你的139邮箱”
vim
/usr/local/nagios/etc/objects/templates.cfg
找到:
define service{
name generic-service
之所以看这一段,是因为在上面添加的10.0.4.56.cfg 定义了很多generic-service所以要关注这段的配置。
define
service{
name generic-service
active_checks_enabled 1
passive_checks_enabled 1
parallelize_check 1
obsess_over_service 1
check_freshness 0
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
failure_prediction_enabled 1
process_perf_data 1
retain_status_information 1
retain_nonstatus_information 1
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 10
retry_check_interval 2
ontact_groups admins
notification_options w,u,c,r
notification_interval 60
notification_period 24x7
register 0
}
其中有几个参数需要你注意:
notifications_enabled
: 是否开启提醒功能。1为开启,0为禁用。一般,这个选项会在主配置文件(nagios.cfg)中定义,效果相同。
notification_interval: 重复发送提醒信息的最短间隔时间。默认间隔时间是60分钟。如果这个值设置为0,将不会发送重复提醒。
notification_period: 发送提醒的时间段。非常重要的主机(服务)我定义为7×24,一般的主机(服务)就定义为上班时间。如果不在定义的时间段内,无论什么问题发生,都不会发送提醒。
notification_options: 这个参数定义了发送提醒包括的情况:d = 状态为DOWN, u = 状态为UNREACHABLE , r = 状态恢复为OK , f = flapping。,n=不发送提醒。
要想正确发送邮件,上面的参数得配置合理才行。