转载请注明出处哈:http://carlosfu.iteye.com/blog/2254154
一、现象:
redis-cluster某个分片内存飙升,明显比其他分片高很多,而且持续增长。并且主从的内存使用量并不一致。
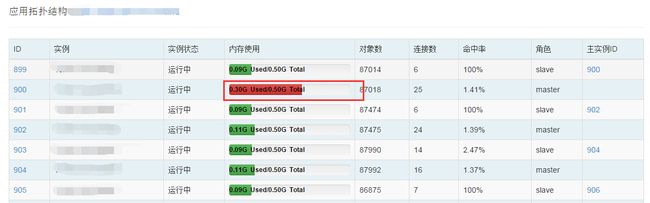
二、分析可能原因:
1. redis-cluster的bug (这个应该不存在)
2. 客户端的hash(key)有问题,造成分配不均。(redis使用的是crc16, 不会出现这么不均的情况)
3. 存在个别大的key-value: 例如一个包含了几百万数据set数据结构(这个有可能)
4. 主从复制出现了问题。
5. 其他原因
三、调查原因:
1. 经查询,上述1-4都不存在
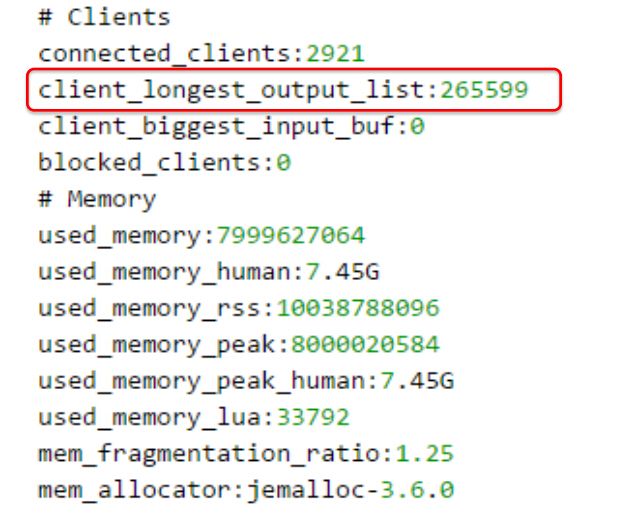
2. 观察info信息,有一点引起了怀疑: client_longes_output_list有些异常。
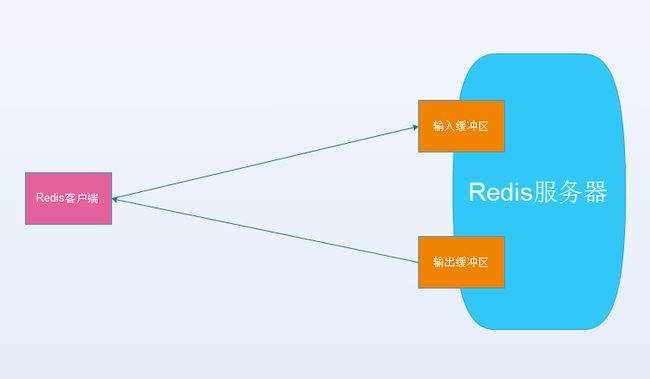
3. 于是理解想到服务端和客户端交互时,分别为每个客户端设置了输入缓冲区和输出缓冲区,这部分如果很大的话也会占用Redis服务器的内存。
从上面的client_longest_output_list看,应该是输出缓冲区占用内存较大,也就是有大量的数据从Redis服务器向某些客户端输出。
于是使用client list命令(类似于mysql processlist) redis-cli -h host -p port client list | grep -v "omem=0",来查询输出缓冲区不为0的客户端连接,于是查询到祸首monitor,于是豁然开朗.

monitor的模型是这样的,它会将所有在Redis服务器执行的命令进行输出,通常来讲Redis服务器的QPS是很高的,也就是如果执行了monitor命令,Redis服务器在Monitor这个客户端的输出缓冲区又会有大量“存货”,也就占用了大量Redis内存。
四、紧急处理和解决方法
进行主从切换(主从内存使用量不一致),也就是redis-cluster的fail-over操作,继续观察新的Master是否有异常,通过观察未出现异常。
查找到真正的原因后,也就是monitor,关闭掉monitor命令的进程后,内存很快就降下来了。
五、 预防办法:
1. 为什么会有monitor这个命令发生,我想原因有两个:
(1). 工程师想看看究竟有哪些命令在执行,就用了monitor
(2). 工程师对于redis学习的目的,因为进行了redis的托管,工程师只要会用redis就可以了,但是作为技术人员都有学习的好奇心和欲望。
2. 预防方法:
(1) 对工程师培训,讲一讲redis使用过程中的坑和禁忌
(2) 对redis云进行介绍,甚至可以让有兴趣的同学参与进来
(3) 针对client做限制,但是官方也不建议这么做,官方的默认配置中对于输出缓冲区没有限制。
client-output-buffer-limit normal 0 0 0
(4) 密码:redis的密码功能较弱,同时多了一次IO
(5) 修改客户端源代码,禁止掉一些危险的命令(shutdown, flushall, monitor, keys *),当然还是可以通过redis-cli来完成
(6) 添加command-rename配置,将一些危险的命令(flushall, monitor, keys * , flushdb)做rename,如果有需要的话,找到redis的运维人员处理
rename-command FLUSHALL "随机数" rename-command FLUSHDB "随机数" rename-command KEYS "随机数"
六、模拟实验:
1. 开启一个空的Redis(最简,直接redis-server)
redis-server初始化内存使用量如下:
# Memory used_memory:815072 used_memory_human:795.97K used_memory_rss:7946240 used_memory_peak:815912 used_memory_peak_human:796.79K used_memory_lua:36864 mem_fragmentation_ratio:9.75 mem_allocator:jemalloc-3.6.0
client缓冲区:
# Clients connected_clients:1 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0
2. 开启一个monitor:
redis-cli -h 127.0.0.1 -p 6379 monitor
3. 使用redis-benchmark:
redis-benchmark -h 127.0.0.1 -p 6379 -c 500 -n 200000
4. 观察
(1) info memory:内存一直增加,直到benchmark结束,monitor输出完毕,但是used_memory_peak_human(历史峰值)依然很高--观察附件中日志
(2)info clients: client_longest_output_list: 一直在增加,直到benchmark结束,monitor输出完毕,才变为0
--观察附件中日志
(3)redis-cli -h host -p port client list | grep "monitor" omem一直很高,直到benchmark结束,monitor输出完毕,才变为0
--观察附件中日志
监控脚本:
while [ 1 == 1 ]
do
now=$(date "+%Y-%m-%d_%H:%M:%S")
echo "=========================${now}==============================="
echo " #Client-Monitor"
redis-cli -h 127.0.0.1 -p 6379 client list | grep monitor
redis-cli -h 127.0.0.1 -p 6379 info clients
redis-cli -h 127.0.0.1 -p 6379 info memory
#休息100毫秒
usleep 100000
done 完整的日志文件:
http://dl.iteye.com/topics/download/096f5da0-4318-332e-914f-6f7c7298ddc9