前言:
如果你对Solr怎么和Tomcat 集成以及如何使用mmseg4j和自定义的词库丰富完善中文分词,可以参照我的其它与Solr相关的博客。这篇将以简练的方式给出如何搭建Solr5.x的服务(以截止目前为止最新的Solr5.3为例),而且将使用Solr自带的Jetty Server,而不是集成tomcat。
一、准备条件
Solr5.x必须建立在JDK1.7的版本以上,先检查并确定安装正确的JDK。
$ java -version java version "1.7.0_55" Java(TM) SE Runtime Environment (build 1.7.0_55-b13) Java HotSpot(TM) 64-Bit Server VM (build 24.55-b03, mixed mode)
二、下载Solr
http://lucene.apache.org/solr/ , 选择download,并选择下载solr 最新的5.3.1版本。
如果是非windows版本的操作系统,如linux,OS,unix等选择下载slor-5.3.1.tgz,如果需要查看相关源码,可以选择solr-5.3.1-src.tgz并导入自己的eclipse等IDE开发工具中。本例中以linux系统为例说明。
三、安装solr5.x
1、解压tgz包
tar zxf solr-5.3.1.tgz
2. 为操作方便将Solr5.3.1重命名为Solr5:
mv solr5.3.1 solr5
四、可以开始运行Solr了(就是如此简单)
1、启动Server
由于是在linux中,所以可以直接使用
$ bin/solr start
如果在windows中,使用命令
bin\solr.cmd start
这两个命令都是在后台启动solr,由于使用了自带的Jetty Server,所以启动后的默认端口就是8983.
输入http://192.168.1.157:8983/solr, 即可看到Solr服务已经成功的启动了。
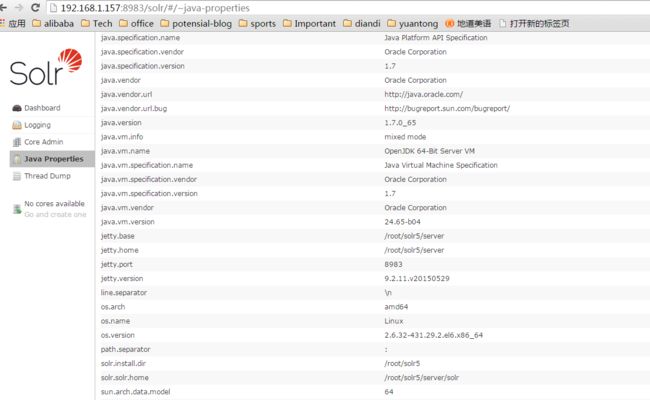
从图中,你也可以看到,Sorl5.3默认使用的Jetty的版本是9.2.11.v20150529,截止目前来说,是很新的版本了。
如果想提升jetty的性能,可以在如下的文件夹中进行jetty的配置修改:
/root/solr5/server/etc
2、使用help命令查看更多的Solr选项
bin/solr -help
如
bin/solr start -help
3、更多的Solr命令
bin/solr start -f : 以前置的方式启动Solr
bin/solr start / restart : 重启当前Solr服务
bin/solr start -p 8984 : 在指定的端口启动Solr
bin/solr stop -p 8983或者Ctrl +C:如果是以前置的方式启动Solr,则可以用Ctrl+c停止Solr服务,否则可以使用stop命令停止Solr服务。
bin/solr status: 检查Solr是否在运行
bin/solr create -c <name> : 创建一个core
$ bin/solr create -help: 创建相关的帮助命令
如果需要指定Solr启动时JVM等参数,则指定 -a,例如:
./solr start -p 44000 -a "-Xss1024k -Xms1024m -Xmx2048m -XX:NewRatio=5"
五、整合mmseg4j进行中文分词
1、关于mmseg4j的介绍,可以参照我的别的关于Solr中文分词的博客。
2、mmseg4j支持Solr5需要使用附件的mmseg4j-solr-2.3.0.jar以及mmseg4j-core-1.10.jar,将这两个jar包放在类似于这样的目录下:
/root/solr5/server/solr-webapp/webapp/WEB-INF/lib
3. 创建一个core: universal
solr create -c universal
当在控制台上出现如下log时,表示创建过程没有什么问题:
Creating new core 'universal' using command:
http://localhost:8983/solr/admin/cores?action=CREATE&name=universal&instanceDir=universal
{
"responseHeader":{
"status":0,
"QTime":2357},
"core":"universal"}
在Solr Admin中可以看到新创建的univeral的信息:
4、开始集成mmseg4j:
进入该目录:/root/solr5/server/solr/universal/conf,修改其中managed-schema(在5.0前,该文件是shcema.xml,当然可以将该文件重命名为schema.xml,但不建议这么做),加入下面的内容并重启Solr,即可在Solr Admin 的console中看到新增的这些field了。
需要注意的是,将dicPath的值修改为相应的值。
<!-- mmseg4j-->
<field name="mmseg4j_complex_name" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<field name="mmseg4j_maxword_name" type="text_mmseg4j_maxword" indexed="true" stored="true"/>
<field name="mmseg4j_simple_name" type="text_mmseg4j_simple" indexed="true" stored="true"/>
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="/root/solr5/server/solr/universal/conf"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="/root/solr5/server/solr/universal/conf"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="/root/solr5/server/solr/universal/conf"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
</fieldType>
<!-- mmseg4j-->
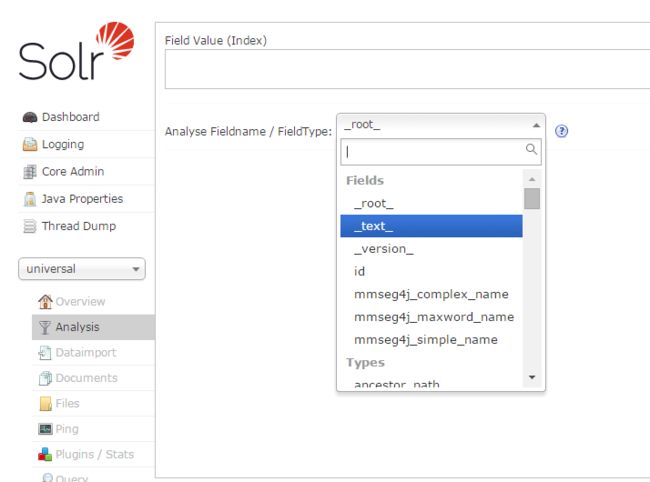
重启Solr 后,即可在新创建的univeral这个core的Analysis中看到mmseg4j新增的field
5、 修改stopwords:如将助词的、地、得等加到stopwords.txt中。
如在将“的”加入stopwords.txt之前,“我们的中国”的分词结果为:
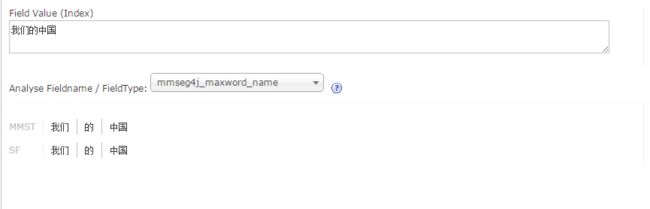
在/root/solr5/server/solr/universal/conf目录下中的stopwords.txt中加入“的”字和“我们”后,重新执行上面的分词,可以看到:
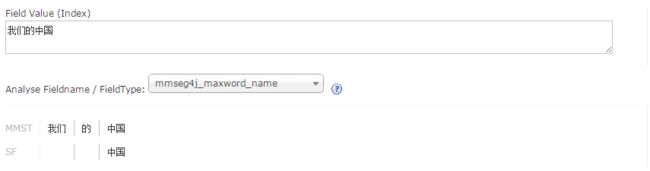
可以看出“我们”和“的”已经作为停止词,不在出现在分词结果中。
6、修改词库,增加更多的中文分词,mmseg4j默认是使用mmseg4j-core-1.10.0.jar中的words.dic,总共只有不到15万的中文词,而整理一个中文词库,位于上面dic指定的目录下/root/solr5/server/solr/universal/conf,总共有71万的词库,包括搜狗词库,庖丁词库,以及一些名人词库,如果需要增加更多的中文词,只需要在其中增加即可。如果需要该词库,可以给我留言,我会发出来,总共有将近8m,作为附件太大。
在使用该词库前,如果对“林书豪来中国了”进行分词,得到的结果是:
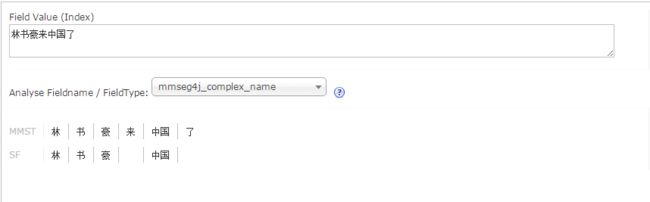
你会看到,分词并不准确,将林书豪作为3个字拆成了“林”,“书”,“豪”,而不是作为一个整体“林书豪”。
使用我自己整理的中文分词后,即本例中将word.dic拷贝到目录:
/root/solr5/server/solr/universal/conf 并重启solr重新进行分词分析后结果为:
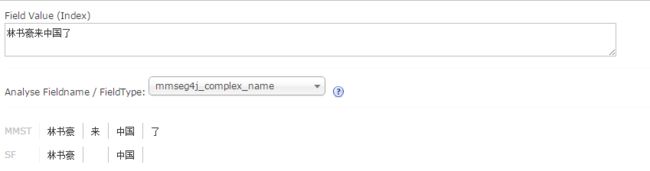
这样Solr5.x和mmseg4j的集成就基本完成了,如果有什么分词不对的,可以借助Solr Admin并修改words.dic解决问题。
9、mmseg4j-complex和mmseg4j-maxword的区别
如果你使用我归纳好的中文词库或者其它中文词库并借助Solr Admin进行分析,你会发现mmseg4j-complex算法搜索的精确度更高,而mmseg4j-maxword算法搜索出的内容会更多。
我们假定我们的分词库中存在着”林书豪“,”书豪“,”林书“3个词。
在mmseg4j-complex算法中,"林书豪"会被完整分词为"林书豪",而mmseg4j-maxword中由于只支持两个字的分词,“林书豪”会被分词为“林书”,“书豪”。这也就以为这如果你选的是mmseg4j-complex算法,你要搜索出含有“林书豪”的内容,则你必须完整的输入“林书豪”才会能够搜得出结果,而在mmseg4j-maxword算法中,你只需要输入“林书”或者“书豪”就可以得出想要的结果了。
所以在实际开发过程中,我们常常需要在精度和广度之间得出权衡的时候,可以选择性的丰富词库,更改词库,比我我希望输入“林书”或者“书豪”的时候就可以得到我想要的结果,那么我就可以在词库中加入“林书”和“书豪”,并且使用mmseg4j-maxword算法,但是我希望的是输入完整的林书豪才能得到我希望的搜索结果,那么就需要使用mmseg4j-complex算法,而且词库中需要加入“林书豪”。
10、在words.dic中分词的顺序是很重要的,比如对于上面的例子“林书豪来中国了”,如果选择mmseg4j-complex算法,并且在词库的最后加入“来中国”,那么你可以看到分词的结果为后面的”来中国“将替代前面的“中国”。
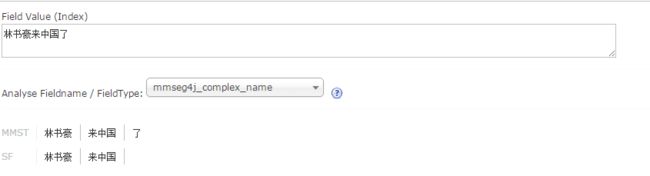
11、 基于上面的分析,我们还可以得出更好的words.dic词库,如果我们确定我们整个项目中都选择mmseg4j-maxword算法,那么我词库中就只需要最多两个字的词就行了,比如讲三个字的“林书豪”拆分成“林书”和"书豪“,将四个字的”迈克乔丹“,拆分成”迈克“,”乔丹“。当然如果两种算法都有可能用到,即有些字段我们希望用mmseg4j-complex算法来进行分词,有的字段我们希望用mmseg4j-maxword来进行分词,那么最好是将2个字的次放在最后,将3个字或者4个字的词放在前面,这样就行程了一个具有150万中文词的词库了。