Spark Runtime里的主要层次分析,梳理Runtime组件和执行流程,
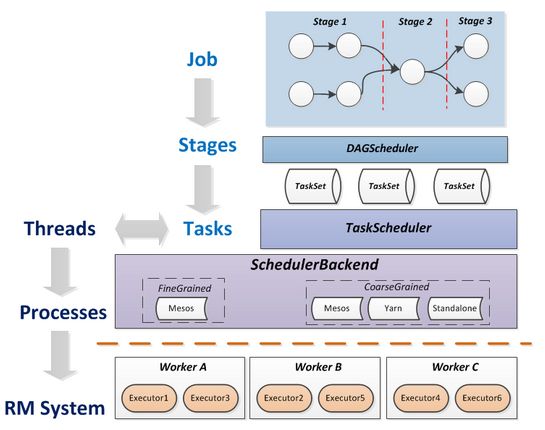
DAGScheduler
Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
面向stage的切分,切分依据为宽依赖
维护waiting jobs和active jobs,维护waiting stages、active stages和failed stages,以及与jobs的映射关系
主要职能
- 接收提交Job的主入口,
submitJob(rdd, ...)或runJob(rdd, ...)。在SparkContext里会调用这两个方法。
- 生成一个Stage并提交,接着判断Stage是否有父Stage未完成,若有,提交并等待父Stage,以此类推。结果是:DAGScheduler里增加了一些waiting stage和一个running stage。
- running stage提交后,分析stage里Task的类型,生成一个Task描述,即TaskSet。
- 调用
TaskScheduler.submitTask(taskSet, ...)方法,把Task描述提交给TaskScheduler。TaskScheduler依据资源量和触发分配条件,会为这个TaskSet分配资源并触发执行。 -
DAGScheduler提交job后,异步返回JobWaiter对象,能够返回job运行状态,能够cancel job,执行成功后会处理并返回结果
- 处理
TaskCompletionEvent
- 如果task执行成功,对应的stage里减去这个task,做一些计数工作:
- 如果task是ResultTask,计数器
Accumulator加一,在job里为该task置true,job finish总数加一。加完后如果finish数目与partition数目相等,说明这个stage完成了,标记stage完成,从running stages里减去这个stage,做一些stage移除的清理工作 - 如果task是ShuffleMapTask,计数器
Accumulator加一,在stage里加上一个output location,里面是一个MapStatus类。MapStatus是ShuffleMapTask执行完成的返回,包含location信息和block size(可以选择压缩或未压缩)。同时检查该stage完成,向MapOutputTracker注册本stage里的shuffleId和location信息。然后检查stage的output location里是否存在空,若存在空,说明一些task失败了,整个stage重新提交;否则,继续从waiting stages里提交下一个需要做的stage
- 如果task是ResultTask,计数器
- 如果task是重提交,对应的stage里增加这个task
- 如果task是fetch失败,马上标记对应的stage完成,从running stages里减去。如果不允许retry,abort整个stage;否则,重新提交整个stage。另外,把这个fetch相关的location和map任务信息,从stage里剔除,从
MapOutputTracker注销掉。最后,如果这次fetch的blockManagerId对象不为空,做一次ExecutorLost处理,下次shuffle会换在另一个executor上去执行。 - 其他task状态会由
TaskScheduler处理,如Exception, TaskResultLost, commitDenied等。
- 如果task执行成功,对应的stage里减去这个task,做一些计数工作:
- 其他与job相关的操作还包括:cancel job, cancel stage, resubmit failed stage等
其他职能
1. cacheLocations 和 preferLocation
privateval cacheLocs =newHashMap[Int,Array[Seq[TaskLocation]]]TaskScheduler
维护task和executor对应关系,executor和物理资源对应关系,在排队的task和正在跑的task。
内部维护一个任务队列,根据FIFO或Fair策略,调度任务。
TaskScheduler本身是个接口,spark里只实现了一个TaskSchedulerImpl,理论上任务调度可以定制。下面是TaskScheduler的主要接口:
def start():Unitdef postStartHook(){}def stop():Unitdef submitTasks(taskSet:TaskSet):Unitdef cancelTasks(stageId:Int, interruptThread:Boolean)def setDAGScheduler(dagScheduler:DAGScheduler):Unitdef executorHeartbeatReceived(execId:String, taskMetrics:Array[(Long,TaskMetrics)], blockManagerId:BlockManagerId):Boolean主要职能
-
submitTasks(taskSet),接收DAGScheduler提交来的tasks
- 为tasks创建一个
TaskSetManager,添加到任务队列里。TaskSetManager跟踪每个task的执行状况,维护了task的许多具体信息。 - 触发一次资源的索要。
- 首先,
TaskScheduler对照手头的可用资源和Task队列,进行executor分配(考虑优先级、本地化等策略),符合条件的executor会被分配给TaskSetManager。 - 然后,得到的Task描述交给
SchedulerBackend,调用launchTask(tasks),触发executor上task的执行。task描述被序列化后发给executor,executor提取task信息,调用task的run()方法执行计算。
- 首先,
- 为tasks创建一个
-
cancelTasks(stageId),取消一个stage的tasks
- 调用
SchedulerBackend的killTask(taskId, executorId, ...)方法。taskId和executorId在TaskScheduler里一直维护着。
- 调用
-
resourceOffer(offers: Seq[Workers]),这是非常重要的一个方法,调用者是SchedulerBacnend,用途是底层资源SchedulerBackend把空余的workers资源交给TaskScheduler,让其根据调度策略为排队的任务分配合理的cpu和内存资源,然后把任务描述列表传回给SchedulerBackend
- 从worker offers里,搜集executor和host的对应关系、active executors、机架信息等等
- worker offers资源列表进行随机洗牌,任务队列里的任务列表依据调度策略进行一次排序
- 遍历每个taskSet,按照进程本地化、worker本地化、机器本地化、机架本地化的优先级顺序,为每个taskSet提供可用的cpu核数,看是否满足
- 默认一个task需要一个cpu,设置参数为
"spark.task.cpus=1" - 为taskSet分配资源,校验是否满足的逻辑,最终在
TaskSetManager的resourceOffer(execId, host, maxLocality)方法里 - 满足的话,会生成最终的任务描述,并且调用
DAGScheduler的taskStarted(task, info)方法,通知DAGScheduler,这时候每次会触发DAGScheduler做一次submitMissingStage的尝试,即stage的tasks都分配到了资源的话,马上会被提交执行
- 默认一个task需要一个cpu,设置参数为
-
statusUpdate(taskId, taskState, data),另一个非常重要的方法,调用者是SchedulerBacnend,用途是SchedulerBacnend会将task执行的状态汇报给TaskScheduler做一些决定
- 若
TaskLost,找到该task对应的executor,从active executor里移除,避免这个executor被分配到其他task继续失败下去。 - task finish包括四种状态:finished, killed, failed, lost。只有finished是成功执行完成了。其他三种是失败。
- task成功执行完,调用
TaskResultGetter.enqueueSuccessfulTask(taskSet, tid, data),否则调用TaskResultGetter.enqueueFailedTask(taskSet, tid, state, data)。TaskResultGetter内部维护了一个线程池,负责异步fetch task执行结果并反序列化。默认开四个线程做这件事,可配参数"spark.resultGetter.threads"=4。
- 若
TaskResultGetter取task result的逻辑
- 对于success task,如果taskResult里的数据是直接结果数据,直接把data反序列出来得到结果;如果不是,会调用
blockManager.getRemoteBytes(blockId)从远程获取。如果远程取回的数据是空的,那么会调用TaskScheduler.handleFailedTask,告诉它这个任务是完成了的但是数据是丢失的。否则,取到数据之后会通知BlockManagerMaster移除这个block信息,调用TaskScheduler.handleSuccessfulTask,告诉它这个任务是执行成功的,并且把result data传回去。 - 对于failed task,从data里解析出fail的理由,调用
TaskScheduler.handleFailedTask,告诉它这个任务失败了,理由是什么。
SchedulerBackend
在TaskScheduler下层,用于对接不同的资源管理系统,SchedulerBackend是个接口,需要实现的主要方法如下:
def start():Unitdef stop():Unitdef reviveOffers():Unit// 重要方法:SchedulerBackend把自己手头上的可用资源交给TaskScheduler,TaskScheduler根据调度策略分配给排队的任务吗,返回一批可执行的任务描述,SchedulerBackend负责launchTask,即最终把task塞到了executor模型上,executor里的线程池会执行task的run()def killTask(taskId:Long, executorId:String, interruptThread:Boolean):Unit=thrownewUnsupportedOperationException粗粒度:进程常驻的模式,典型代表是standalone模式,mesos粗粒度模式,yarn
细粒度:mesos细粒度模式
这里讨论粗粒度模式,更好理解:CoarseGrainedSchedulerBackend。
维护executor相关信息(包括executor的地址、通信端口、host、总核数,剩余核数),手头上executor有多少被注册使用了,有多少剩余,总共还有多少核是空的等等。
主要职能
- Driver端主要通过actor监听和处理下面这些事件:
-
RegisterExecutor(executorId, hostPort, cores, logUrls)。这是executor添加的来源,通常worker拉起、重启会触发executor的注册。CoarseGrainedSchedulerBackend把这些executor维护起来,更新内部的资源信息,比如总核数增加。最后调用一次makeOffer(),即把手头资源丢给TaskScheduler去分配一次,返回任务描述回来,把任务launch起来。这个makeOffer()的调用会出现在任何与资源变化相关的事件中,下面会看到。 -
StatusUpdate(executorId, taskId, state, data)。task的状态回调。首先,调用TaskScheduler.statusUpdate上报上去。然后,判断这个task是否执行结束了,结束了的话把executor上的freeCore加回去,调用一次makeOffer()。 -
ReviveOffers。这个事件就是别人直接向SchedulerBackend请求资源,直接调用makeOffer()。 -
KillTask(taskId, executorId, interruptThread)。这个killTask的事件,会被发送给executor的actor,executor会处理KillTask这个事件。 -
StopExecutors。通知每一个executor,处理StopExecutor事件。 -
RemoveExecutor(executorId, reason)。从维护信息中,那这堆executor涉及的资源数减掉,然后调用TaskScheduler.executorLost()方法,通知上层我这边有一批资源不能用了,你处理下吧。TaskScheduler会继续把executorLost的事件上报给DAGScheduler,原因是DAGScheduler关心shuffle任务的output location。DAGScheduler会告诉BlockManager这个executor不可用了,移走它,然后把所有的stage的shuffleOutput信息都遍历一遍,移走这个executor,并且把更新后的shuffleOutput信息注册到MapOutputTracker上,最后清理下本地的CachedLocationsMap。
-
-
reviveOffers()方法的实现。直接调用了makeOffers()方法,得到一批可执行的任务描述,调用launchTasks。 -
launchTasks(tasks: Seq[Seq[TaskDescription]])方法。
- 遍历每个task描述,序列化成二进制,然后发送给每个对应的executor这个任务信息
- 如果这个二进制信息太大,超过了9.2M(默认的akkaFrameSize 10M 减去 默认 为akka留空的200K),会出错,abort整个taskSet,并打印提醒增大akka frame size
- 如果二进制数据大小可接受,发送给executor的actor,处理
LaunchTask(serializedTask)事件。
- 遍历每个task描述,序列化成二进制,然后发送给每个对应的executor这个任务信息
Executor
Executor是spark里的进程模型,可以套用到不同的资源管理系统上,与SchedulerBackend配合使用。
内部有个线程池,有个running tasks map,有个actor,接收上面提到的由SchedulerBackend发来的事件。
事件处理
-
launchTask。根据task描述,生成一个TaskRunner线程,丢尽running tasks map里,用线程池执行这个TaskRunner -
killTask。从running tasks map里拿出线程对象,调它的kill方法。
http://www.mamicode.com/info-detail-530178.html