一,简介
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务,如相册网站、视频网站等等。使用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。同时FastDFS提供了Java,C和PHP等语言的客户端API,我们可以在应用服务端通过API操作文件系统。
二,原理分析
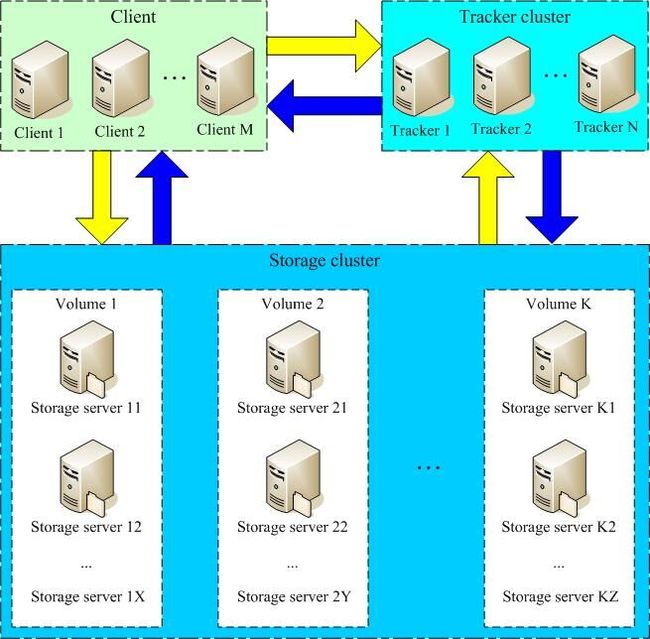
FastDFS包含两种角色:跟踪器Tracker和存储节点Storage,都可以单台或多台部署。
Storage存储节点的分组(同一组内的存储节点文件完全一致,负载均衡分摊IO压力):
类Google FS都支持文件冗余备份,例如Google FS、TFS的备份数是3。一个文件存储到哪几个存储结点,通常采用动态分配的方式。 采用这种方式,一个文件存储到的结点是不确定的。举例说明,文件备份数是3,集群中有A、B、C、D四个存储结点。文件1可能存储在A、B、C三个结点, 文件2可能存储在B、C、D三个结点,文件3可能存储在A、B、D三个结点。
FastDFS采用了分组存储方式。集群由一个或多个组构成,集群存储总容量为集群中所有组的存储容量之和。一个组由一台或多台存储服务器组成,同组内的多台Storage server之间是互备关系,同组存储服务器上的文件是完全一致的。文件上传、下载、删除等操作可以在组内任意一台 Storage server上进行。类似木桶短板效应,一个组的存储容量为该组内存储服务器容量最小的那个,由此可见组内存储服务器的软硬件配置最好是一致的。
采用分组存储方式的好处是灵活、可控性较强。比如上传文件时,可以由客户端直接指定上传到的组。一个分组的存储服务器访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。采用这样的分组存储方式,可以使用FastDFS对文件进行管理,使用主流的Web server如Apache、nginx等进行文件下载。
文件上传流程:
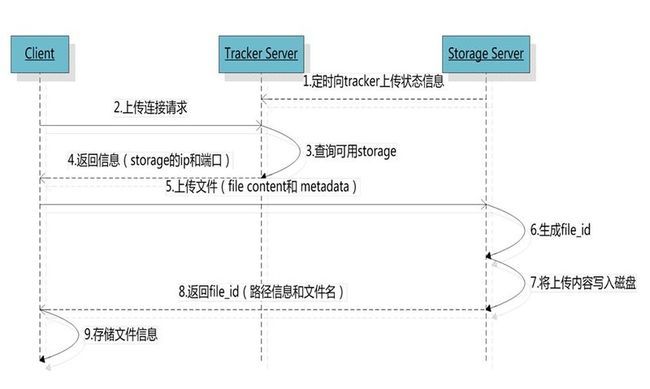
流程描述:
1,当集群中不止一台跟踪器tracker server时,由于tracker之间是完全对等的,客户端在上传文件时可以任务选择其中的一台进行连接。
2,选择文件存储节点的分组group。当tracker接收到client上传文件的请求时,会为该文件分配一个可以存储该文件的group(存储节点组),当然客户端也可以手动指定存储该文件的组。自动分配的策略有1,Round robin(所有存储节点组group轮询选择);2,Load balance(剩余空间的多的group优先,存储节点Storage与跟踪器tracker之间建立socket长连接,实时向tracker跟踪器汇报空间大小等存储信息)。
3,选择分组下的一个存储节点Storage。当选定一个存储节点组group之后,接下来则需选择一个具体的存储节点Storage,具体策略有1,Round robin(该存储节点组group内轮询选择);2,First server ordered by ip(按ip排序);3,First server ordered by priority(按Storage存储节点设置的优先级排序,优先存储在级别高的Storage,该Storage存写binlog日志,然后该group内的其他存储节点基于binlog进行复制,保证最后group内所有存储节点文件完全一致)。
4,选择Storage path。当分配好存储节点Storage server之后,接下来则是选择存储路径,Storage 会为文件分配一个存储目录,支持如下规则1,Round robin(多个存储目录间轮询);2,剩余存储空间最多的优先。
5,生成全局唯一的字符串File ID。由Storage server ip + 文件创建时间 + 文件大小 + 文件crc32 +随机数,然后进行base64编码而成的字符串。
6,当选定存储目录之后,storage会为文件分配一个File ID,每个存储目录下有两级256*256的子目录,storage会按文件fileid进行两次hash(猜测),路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下。
7,生成文件名。当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由group、存储目录、两级子目录、File ID、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。

文件下载流程:
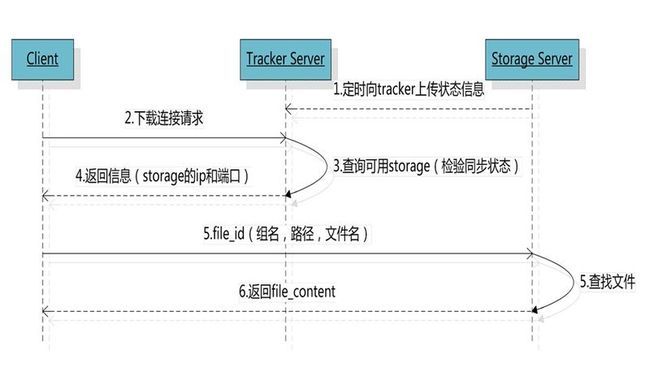
文件下载流程分析:
跟upload file一样,在download file时客户端可以选择任意tracker server。client发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。由于group内的文件同步时在后台异步进行的,所以有可能出现在读到时候,文件还没有同步到某 些storage server上,为了尽量避免访问到这样的storage,tracker按照如下规则选择group内可读的storage。
选择读的storage规则:1. 该文件上传到的源头storage - 源头storage只要存活着,肯定包含这个文件,源头的地址被编码在文件名中。 2. 文件创建时间戳==storage被同步到的时间戳 且(当前时间-文件创建时间戳) > 文件同步最大时间(如5分钟) - 文件创建后,认为经过最大同步时间后,肯定已经同步到其他storage了。 3. 文件创建时间戳 < storage被同步到的时间戳。 - 同步时间戳之前的文件确定已经同步了 4. (当前时间-文件创建时间戳) > 同步延迟阀值(如一天)。 - 经过同步延迟阈值时间,认为文件肯定已经同步了。
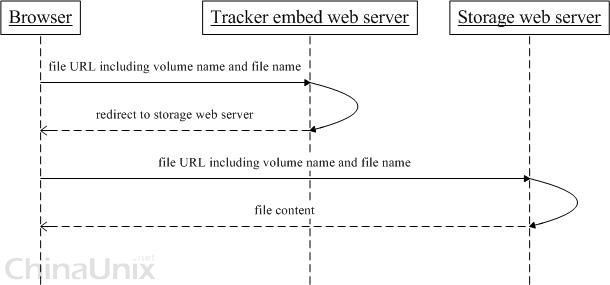
三,HTTP访问支持
FastDFS的tracker和storage都内置了http协议的支持,客户端可以通过http协议来下载文件,tracker在接收到请求时,通 过http的redirect机制将请求重定向至文件所在的storage上;除了内置的http协议外,FastDFS还提供了通过apache或nginx扩展模块下载文件的支持。
四,分布式文件系统对比
FastDFS与HDFS,TFS等特性比较。TFS是淘宝使用的分布式文件系统,用于海量小文件的存储,但使用和部署过于复杂,不够轻量化。HDFS是Hadoop分布式计算使用的文件系统,主要解决并行计算中分布式存储数据的问题。其单个数据文件通常很大,采用了分块(切分)存储的方式。