最近项目中有用到disruptor,提供一个类似队列或者数据容器的功能,并发能力很强
概念:
Sequence:就是一个增长序列,类似oracle的增长序列,生产和消费程序都有Sequence,记录生产和消费程序的序列
Sequencer: 多个概念的一个组合,持有Sequence,等待策略等一些引用,生产者引用
SequenceBarrier:直接翻译就是序列屏障,就是Sequence和RingBuffer交互的一个屏障,单个生产者时,生产者不需要SequenceBarrier
RingBuffer:是一个数组,根据追踪生产和消费的Sequence来实现一个环形的数据结构
说明:
1 很多地方都说到RingBuffer是一个环形的数据结构,它功能上表现出来的确实是环形结构,但是实现上是一个数组,而是通过生产者覆盖已经读过的数据,消费者回头读取未读取过的数据来实现的环形数据结构,
很多画图画成环形的,很容易误导理解
2 RingBuffer的size为2的n次方,可是Sequence是一直递增的,不知道其他人怎么理解的,我原来没看代码前的理解就是它的长度不超过RingBuffer的长度,然后重置后重新增长,这个错误的理解主要是看了很多博客上的环形的那个图,不论生产还是消费的Sequence一直
都是递增的, 到RingBuffer取值时,会根据RingBuffer的长度转换成对应的下标值
1 maven pom
<dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>3.3.0</version> </dependency>
2 我现在只是用到,了解的不是很深,看了部分代码,参考了很多其他博客,下面是我自己的看法,不对的地方欢迎指正
2.1 测试代码是这样用的
TestEvent.java
public class TestEvent {
private String line;
public String getLine() {
return line;
}
public void setLine(String line) {
this.line = line;
}
}
生产者TestEventProducer.java:
public class TestEventProducer {
private RingBuffer<TestEvent> ringBuffer;
public TestEventProducer (RingBuffer<TestEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
/**
* 转换器,向队列里放值的时候调用(队列先设置固定长度的对象,然后通过set方法生产值)
*/
private static EventTranslatorOneArg<TestEvent, String> eventTranslatorOneArg = new EventTranslatorOneArg<TestEvent, String>() {
@Override
public void translateTo(TestEvent event, long sequence, String arg0) {
event.setLine(arg0);
}
};
/**
* 生产者向队列里放入数据
* @param line
*/
public void onData (String line) {
this.ringBuffer.publishEvent(eventTranslatorOneArg, line);
}
/**
* 处理数据
*/
public void handler () {
for (int i = 0; i < 1000; i++) {
this.onData("wozaizhe" + i);
}
}
消费者TestEventHandler:消费者从RingBuffer中拿出数据打印了一下
public class TestEventHandler implements WorkHandler<TestEvent> {
@Override
public void onEvent(TestEvent event) throws Exception {
System.out.println("处理了一行数据:" + event.getLine());
}
}
测试类:
public class TestEventMain {
public static final int BUFFER_SIZE = 8;
public static void main (String[] args) {
testDisruptor();
}
public static void testDisruptor () {
ExecutorService executor = Executors.newFixedThreadPool(8);
EventFactory<TestEvent> eventFactory = new TestEventFactory();
//创建disruptor,设置单生产者模式
Disruptor disruptor = new Disruptor(eventFactory, BUFFER_SIZE, executor, ProducerType.SINGLE,
new YieldingWaitStrategy ());
//设置消费者程序
disruptor.handleEventsWithWorkerPool(new TestEventHandler(), new TestEventHandler(),
new TestEventHandler(), new TestEventHandler());
//设置异常处理
disruptor.handleExceptionsWith(new TestEventExceptionHandler());
//启动disruptor并返回RingBuffer
RingBuffer<TestEvent> ringBuffer = disruptor.start();
//创建生产者线程,并生产
TestEventProducer producer = new TestEventProducer(ringBuffer);
producer.handler();
disruptor.shutdown();
executor.shutdown();
}
}
测试中使用的是单一的生产者,消费者有多个,使用WorkerPool来管理多个消费者
disruptor 的数据存放在RingBuffer中,RingBuffer的类结构:
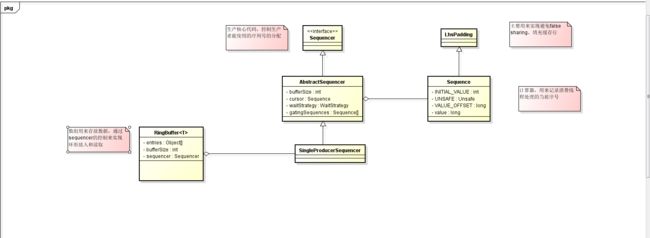
disruptor设计的主要类
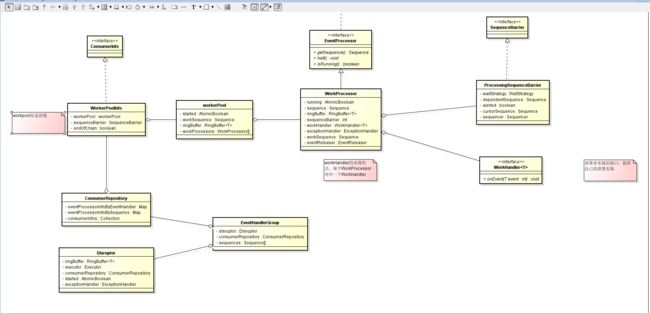
上面是主要类图,RingBuffer只负责存储,生产者和消费者取号的协调工作都是由SingleProducerSequencer来完成的
从代码分析:
(1) 创建Disruptor
public Disruptor(final EventFactory<T> eventFactory,
final int ringBufferSize,
final Executor executor,
final ProducerType producerType,
final WaitStrategy waitStrategy)
{
this(RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
executor);
}
//创建RingBuffer
public static <E> RingBuffer<E> create(ProducerType producerType,
EventFactory<E> factory,
int bufferSize,
WaitStrategy waitStrategy)
{
switch (producerType)
{
case SINGLE:
return createSingleProducer(factory, bufferSize, waitStrategy);
case MULTI:
return createMultiProducer(factory, bufferSize, waitStrategy);
default:
throw new IllegalStateException(producerType.toString());
}
}
//创建Sequencer并实例化到RingBuffer中
public static <E> RingBuffer<E> createSingleProducer(EventFactory<E> factory,
int bufferSize,
WaitStrategy waitStrategy)
{
SingleProducerSequencer sequencer = new SingleProducerSequencer(bufferSize, waitStrategy);
return new RingBuffer<E>(factory, sequencer);
}
创建Disruptor的过程: 创建了一个RingBuffer,实例化了生产者sequencer,实例化了其他参数
(2) 设置消费者程序
源码:
//被调用的方法
public EventHandlerGroup<T> handleEventsWithWorkerPool(final WorkHandler<T>... workHandlers)
{
return createWorkerPool(new Sequence[0], workHandlers);
}
//创建workpool
EventHandlerGroup<T> createWorkerPool(final Sequence[] barrierSequences, final WorkHandler<? super T>[] workHandlers)
{
//创建SequenceBarrier,每次消费者要读取RingBuffer中的下一个值都要通过SequenceBarrier来获取SequenceBarrier用来协调多个消费者并发的问题
final SequenceBarrier sequenceBarrier = ringBuffer.newBarrier(barrierSequences);
//实现在下个方法
final WorkerPool<T> workerPool = new WorkerPool<T>(ringBuffer, sequenceBarrier, exceptionHandler, workHandlers);
consumerRepository.add(workerPool, sequenceBarrier);
return new EventHandlerGroup<T>(this, consumerRepository, workerPool.getWorkerSequences());
}
//workpool 构造方法
public WorkerPool(final RingBuffer<T> ringBuffer,
final SequenceBarrier sequenceBarrier,
final ExceptionHandler exceptionHandler,
final WorkHandler<? super T>... workHandlers)
{
this.ringBuffer = ringBuffer;
final int numWorkers = workHandlers.length;
//创建一个和消费者线程个数相同的WorkProcessor数组
workProcessors = new WorkProcessor[numWorkers];
for (int i = 0; i < numWorkers; i++)
{
//消费者在源码中的表现形式就是WorkProcessor,通过构造方法可以知道,一个workpool中的消费者程序,使用的是相同的sequenceBarrier, workSequence
workProcessors[i] = new WorkProcessor<T>(ringBuffer,
sequenceBarrier,
workHandlers[i],
exceptionHandler,
workSequence);
}
}
这个部分就是创建一个workpool,根据每个WorkHandler创建对应的WorkProcessor,同一个workpool中的消费者线程共享同一个sequenceBarrier,workSequence,类的关系可以看上面的类图
(3) 启动disruptor
public RingBuffer<T> start()
{
//获取每一个消费者程序的Sequence和workpool的Sequence
Sequence[] gatingSequences = consumerRepository.getLastSequenceInChain(true);
ringBuffer.addGatingSequences(gatingSequences);
checkOnlyStartedOnce();
for (ConsumerInfo consumerInfo : consumerRepository)
{
consumerInfo.start(executor);
}
return ringBuffer;
}
//根据一系列的引用,找到消费者程序WorkProcessor,初始化每个WorkProcessor的sequence,然后执行提交到线程池执行
public RingBuffer<T> start(final Executor executor)
{
if (!started.compareAndSet(false, true))
{
throw new IllegalStateException("WorkerPool has already been started and cannot be restarted until halted.");
}
final long cursor = ringBuffer.getCursor();
workSequence.set(cursor);
for (WorkProcessor<?> processor : workProcessors)
{
processor.getSequence().set(cursor);
executor.execute(processor);
}
return ringBuffer;
}
启动Disruptor就是启动消费者线程
(4)单一生产者生产数据
@Override
public <A> void publishEvent(EventTranslatorOneArg<E, A> translator, A arg0)
{
//获取RingBuffer下一个可操作的序列
final long sequence = sequencer.next();
//把数据set到队列,设置cursor的序列
translateAndPublish(translator, sequence, arg0);
}
/**
* @see Sequencer#next()
*/
@Override
public long next()
{
return next(1);
}
/**
* @see Sequencer#next(int)
*/
@Override
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
//RingBuffer持有Sequencer,SingleProducerSequencer有nextValue和cachedValue两个成员变量,前者记录生产者生产到的位置,后者记录消费者线程中序列号最小的序列号,即是在最前面的消费者的序号
long nextValue = this.nextValue;
long nextSequence = nextValue + n;
//wrapPoint是一个很关键的变量,这个变量决定生产者是否可以覆盖序列号nextSequence,wrapPoint是为什么是nextSequence - bufferSize;RingBuffer表现出来的是一个环形的数据结构,实际上是一个长度为bufferSize的数组,
//nextSequence - bufferSize如果nextSequence小于bufferSize wrapPoint是负数,表示可以一直生产;如果nextSequence大于bufferSize wrapPoint是一个大于0的数,由于生产者和消费者的序列号差距不能超过bufferSize
//(超过bufferSize会覆盖消费者未消费的数据),wrapPoint要小于等于多个消费者线程中消费的最小的序列号,即cachedValue的值,这就是下面if判断的根据
long wrapPoint = nextSequence - bufferSize;
long cachedGatingSequence = this.cachedValue;
//继续生成会覆盖消费者未消费的数据
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
long minSequence;
//判断wrapPoint是否大于消费者线程最小的序列号,如果大于,不能写入,继续等待
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue)))
{
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
//满足生产条件了,缓存这次消费者线程最小消费序号,供下次使用
this.cachedValue = minSequence;
}
//缓存生产者最大生产序列号
this.nextValue = nextSequence;
return nextSequence;
}
(5) 消费者程序WorkProccessor
//线程的逻辑
@Override
public void run()
{
if (!running.compareAndSet(false, true))
{
throw new IllegalStateException("Thread is already running");
}
sequenceBarrier.clearAlert();
notifyStart();
//标志位,用来标志一次消费过程,此标志位在代码方面用的很巧妙,把两次执行揉成一段代码
boolean processedSequence = true;
//用来缓存消费者可以使用的RingBuffer最大序列号
long cachedAvailableSequence = Long.MIN_VALUE;
//记录被分配的WorkSequence的序列号,也是去RingBuffer取数据的序列号
long nextSequence = sequence.get();
T event = null;
while (true)
{
try
{
// if previous sequence was processed - fetch the next sequence and set
// that we have successfully processed the previous sequence
// typically, this will be true
// this prevents the sequence getting too far forward if an exception
// is thrown from the WorkHandler
//每次消费开始执行
if (processedSequence)
{
processedSequence = false;
//使用CAS算法从WorkPool的序列WorkSequence取得可用序列nextSequence
do
{
nextSequence = workSequence.get() + 1L;
sequence.set(nextSequence - 1L);
}
while (!workSequence.compareAndSet(nextSequence - 1L, nextSequence));
}
//如果可使用的最大序列号cachedAvaliableSequence大于等于我们要使用的序列号nextSequence,直接从RingBuffer取数据;不然进入else
if (cachedAvailableSequence >= nextSequence)
{
//可以满足消费的条件,根据序列号去RingBuffer去读取数据
event = ringBuffer.get(nextSequence);
workHandler.onEvent(event);
//一次消费结束,设置标志位
processedSequence = true;
}
else
{//等待生产者生产,获取到最大的可以使用的序列号
cachedAvailableSequence = sequenceBarrier.waitFor(nextSequence);
}
}
catch (final AlertException ex)
{
if (!running.get())
{
break;
}
}
catch (final Throwable ex)
{
// handle, mark as processed, unless the exception handler threw an exception
exceptionHandler.handleEventException(ex, nextSequence, event);
processedSequence = true;
}
}
notifyShutdown();
running.set(false);
}
//ProcessorSequencerBarrier.java等待生产者生产出更多的产品用来消费
@Override
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
//根据选用的等待策略来等待生产者生产
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
//这个不明白是为什么,生产者最大的序列小于要使用的序列,直接返回了,上面的run()方法中的while循环要再执行一遍,不明白此处的用意
if (availableSequence < sequence)
{
return availableSequence;
}
//返回较大的Sequence
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
//YieldingWaitStrategy 等待策略,先尝试一百次,再不满足条件,当前线程就yield,让其他线程先执行
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
//等待次数
int counter = SPIN_TRIES;
//循环,如果生产的最大序列号小于消费者需要的序列号,继续等待,等待次数超过counter次,线程yield
//这里dependentSequence就是cursorSequence,在ProcessorSequencerBarrier构造函数中可以看到
while ((availableSequence = dependentSequence.get()) < sequence)
{
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
//counter大于0则减一返回,否则当前线程yield
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
barrier.checkAlert();
if (0 == counter)
{
Thread.yield();
}
else
{
--counter;
}
return counter;
}
消费者的整体逻辑:多个消费者共同使用同一个Sequence即workSequence,大家都从这个sequence里取得序列号,通过CAS保证线程安全,然后每个消费者拿到序列号nextSequence后去和RingBuffer的cursor比较,即生产者生产到的最大序列号比较,如果自己要取的序号还没有被生产者生产出来,则等待生产者生成出来后再从RingBuffer中取数据,处理数据
上面的每个线程run()方法是while(true)怎么停下来的呢,通过跑出异常来控制的,抛出AlertException,在捕捉到异常后break循环语句块
促使抛出异常在关闭disruptor的时候
(6)disruptor关闭
public void shutdown(final long timeout, final TimeUnit timeUnit) throws TimeoutException
{
final long timeOutAt = System.currentTimeMillis() + timeUnit.toMillis(timeout);
//断是否有剩余消息未发送,有则继续循环
while (hasBacklog())
{
if (timeout >= 0 && System.currentTimeMillis() > timeOutAt)
{
throw TimeoutException.INSTANCE;
}
// Busy spin
}
//数据全部发送和消费完毕
halt();
}
/**
* Confirms if all messages have been consumed by all event processors
*/
private boolean hasBacklog()
{
final long cursor = ringBuffer.getCursor();
for (final Sequence consumer : consumerRepository.getLastSequenceInChain(false))
{
//通过判断生产数是否等于消费数,等于表示生产消费结束,返回false
if (cursor > consumer.get())
{
return true;
}
}
return false;
}
//线程运行设置为false, Barrier的alert设置为true,run()方法执行while循环的时候会检查一下alert,为true则跳出循环
@Override
public void halt()
{
running.set(false);
sequenceBarrier.alert();
}
总体来说:RingBuffer在生产Sequencer中记录一个cursor,追踪生产者生产到的最新位置,通过WorkSequence和sequence记录整个workpool消费的位置和每个WorkProcessor消费到位置,来协调生产和消费程序