lucene打分机制
一:相似度算法
lucene采用的是基于VSM(向量空间模型)的相似度算法,查询向量(query vector)与搜索出来的文档向量(document vector) 形成N个夹角,计算q 和d 之间的夹角,最小的 就是相
似度最高的。

二:lucene的打分公式
看下lucene的打分公式:
tf: 一个term在一个文档中出现的次数
idf:一个term在多少个文档中出现过
t.getBoost:lucene自有的权重配置,默认为1
norm:字段标准化。
在Lucene中score简单说是由 tf * idf * boost * norm 计算得出的。
代码实现,必要时可以重写代码。在Lucene的DefaultSimilarity类
1:协调coord(q,d)
@Override
public float coord(int overlap, int maxOverlap) {
return overlap / (float)maxOverlap;
}
2:queryNorm(q) 查询规范 (对排序没有任何影响)
/** Implemented as <code>1/sqrt(sumOfSquaredWeights)</code>. */
@Override
public float queryNorm(float sumOfSquaredWeights) {
return (float)(1.0 / Math.sqrt(sumOfSquaredWeights));
}
3:tf 单个文档词频
函数图:
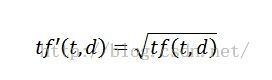
只在商品名称中出现了1次。。他的tf =1
Math.sqrt 取平方根 Math.sqrt(9)=3.0如果搜索“笔记本” ,在分类和商品名称中都出现了 他的tf 就是1.414 (2次的平方根)
只在商品名称中出现了1次。。他的tf =1
@Override
public float tf(float freq) {
return (float)Math.sqrt(freq);
}
4:idf(t) 一个term在多少个文档中出现过

numDocs 总文档数 docFreq 在多少文档中出现过
如果搜索“笔记本” ,总文档有1000个 ,,出现100次。。那么idf=2
如果出现10次 那么其idf =3
idf 越高、在总文档数中 该词出现的频率越低
5:t.getBoost() 权重
6:norm(t,d) 标准化

对term和文档的字段长度进行标准化计算 ,如果字段的长度越长,那么该值越低。
@Override
public float lengthNorm(FieldInvertState state) {
final int numTerms;
if (discountOverlaps)
numTerms = state.getLength() - state.getNumOverlap();
else
numTerms = state.getLength();
return state.getBoost() * ((float) (1.0 / Math.sqrt(numTerms)));
}
电商体验:
在电商搜索中。一般基于VSM算法推导出来的lucene算法的tfidf会被忽视,应为这两个值没有用的。真正用到的是boost算法和norm算法。。主要作用还是boost算法。还有
solr的一个bf参数。。一个函数计算值