转载自AlloyTeam:http://www.alloyteam.com/2015/11/we-will-be-componentized-web-long-text/
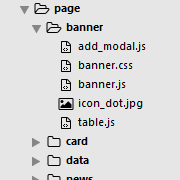
这篇文章将从两年前的一次技术争论开始。争论的聚焦就是下图的两个目录分层结构。我说按模块划分好,他说你傻逼啊,当然是按资源划分。
 《=》
《=》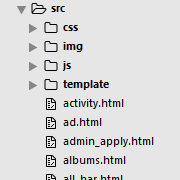
”按模块划分“目录结构,把当前模块下的所有逻辑和资源都放一起了,这对于多人独自开发和维护个人模块不是很好吗?当然了,那争论的结果是我乖乖地改回主流的”按资源划分“的目录结构。因为,没有做到JS模块化和资源模块化,仅仅物理位置上的模块划分是没有意义的,只会增加构建的成本而已。
虽然他说得好有道理我无言以对,但是我心不甘,等待他日前端组件化成熟了,再来一战!
而今天就是我重申正义的日子!只是当年那个跟你撕逼的人不在。
## 模块化的不足
模块一般指能够独立拆分且通用的代码单元。由于JavaScript语言本身没有内置的模块机制(ES6有了!!),我们一般会使用CMD或ADM建立起模块机制。现在大部分稍微大型一点的项目,都会使用requirejs或者seajs来实现JS的模块化。多人分工合作开发,其各自定义依赖和暴露接口,维护功能模块间独立性,对于项目的开发效率和项目后期扩展和维护,都是是有很大的帮助作用。
但,麻烦大家稍微略读一下下面的代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
require
(
[
'Tmpl!../tmpl/list.html'
,
'lib/qqapi'
,
'module/position'
,
'module/refresh'
,
'module/page'
,
'module/net'
]
,
function
(
listTmpl
,
QQapi
,
Position
,
Refresh
,
Page
,
NET
)
{
var
foo
=
''
,
bar
=
[
]
;
QQapi
.
report
(
)
;
Position
.
getLocaiton
(
function
(
data
)
{
//...
}
)
;
var
init
=
function
(
)
{
bind
(
)
;
NET
.
get
(
'/cgi-bin/xxx/xxx'
,
function
(
data
)
{
renderA
(
data
.
banner
)
;
renderB
(
data
.
list
)
;
}
)
;
}
;
var
processData
=
function
(
)
{
}
;
var
bind
=
function
(
)
{
}
;
var
renderA
=
function
(
)
{
}
;
var
renderB
=
function
(
data
)
{
listTmpl
.
render
(
'#listContent'
,
processData
(
data
)
)
;
}
;
var
refresh
=
function
(
)
{
Page
.
refresh
(
)
;
}
;
// app start
init
(
)
;
}
)
;
|
上面是具体某个页面的主js,已经封装了像Position,NET,Refresh等功能模块,但页面的主逻辑依旧是”面向过程“的代码结构。所谓面向过程,是指根据页面的渲染过程来编写代码结构。像:init -> getData -> processData -> bindevent -> report -> xxx 。 方法之间线性跳转,你大概也能感受这样代码弊端。随着页面逻辑越来越复杂,这条”过程线“也会越来越长,并且越来越绕。加之缺少规范约束,其他项目成员根据各自需要,在”过程线“加插各自逻辑,最终这个页面的逻辑变得难以维护。

开发需要小心翼翼,生怕影响“过程线”后面正常逻辑。并且每一次加插或修改都是bug泛滥,无不令产品相关人员个个提心吊胆。
## 页面结构模块化
基于上面的面向过程的问题,行业内也有不少解决方案,而我们团队也总结出一套成熟的解决方案:Abstractjs,页面结构模块化。我们可以把我们的页面想象为一个乐高机器人,需要不同零件组装,如下图,假设页面划分为tabContainer,listContainer和imgsContainer三个模块。最终把这些模块add到最终的pageModel里面,最终使用rock方法让页面启动起来。
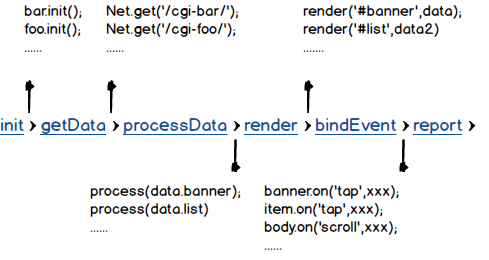
(原过程线示例图)
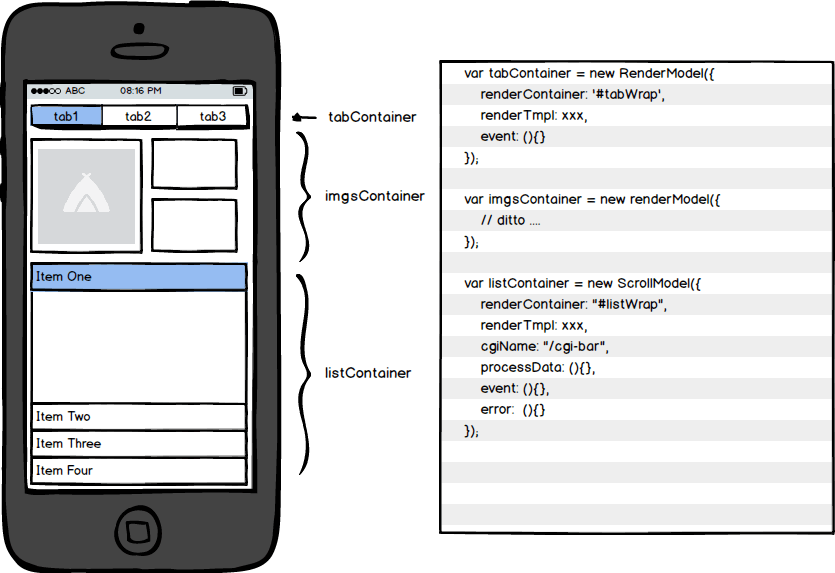
(页面结构化示例图)
下面是伪代码的实现
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
require
(
[
'Tmpl!../tmpl/list.html'
,
'Tmpl!../tmpl/imgs.html'
,
'lib/qqapi'
,
'module/refresh'
,
'module/page'
]
,
function
(
listTmpl
,
imgsTmpl
,
QQapi
,
Refresh
,
Page
)
{
var
tabContainer
=
new
RenderModel
(
{
renderContainer
:
'#tabWrap'
,
data
:
{
}
,
renderTmpl
:
"<li soda-repeat='item in data.tabs'>{{item}}</li>"
,
event
:
function
(
)
{
// tab's event
}
}
)
;
var
listContainer
=
new
ScrollModel
(
{
scrollEl
:
$
.
os
.
ios
?
$
(
'#Page'
)
:
window
,
renderContainer
:
'#listWrap'
,
renderTmpl
:
listTmpl
,
cgiName
:
'/cgi-bin/index-list?num=1'
,
processData
:
function
(
data
)
{
//...
}
,
event
:
function
(
)
{
// listElement's event
}
,
error
:
function
(
data
)
{
Page
.
show
(
'数据返回异常['
+
data
.
retcode
+
']'
)
;
}
}
)
;
var
imgsContainer
=
new
renderModel
(
{
renderContainer
:
'#imgsWrap'
,
renderTmpl
:
listTmpl
,
cgiName
:
'/cgi-bin/getPics'
,
processData
:
function
(
data
)
{
//...
}
,
event
:
function
(
)
{
// imgsElement's event
}
,
complete
:
function
(
data
)
{
QQapi
.
report
(
)
;
}
}
)
;
var
page
=
new
PageModel
(
)
;
page
.
add
(
[
tabContainer
,
listContainer
,
imgsContainer
]
)
;
page
.
rock
(
)
;
}
)
;
|
我们把这些常用的请求CGI,处理数据,事件绑定,上报,容错处理等一系列逻辑方法,以页面块为单位封装成一个Model模块。
这样的一个抽象层Model,我们可以清晰地看到该页面块,请求的CGI是什么,绑定了什么事件,做了什么上报,出错怎么处理。新增的代码就应该放置在相应的模块上相应的状态方法(preload,process,event,complete…),杜绝了以往的无规则乱增代码的行文。并且,根据不同业务逻辑封装不同类型的Model,如列表滚动的ScrollModel,滑块功能的SliderModel等等,可以进行高度封装,集中优化。
现在基于Model的页面结构开发,已经带有一点”组件化“的味道。每个Model都带有各自的数据,模板,逻辑。已经算是一个完整的功能单元。但距离真正的WebComponent还是有一段距离,至少满足不了我的”理想目录结构“。
## WebComponents 标准
我们回顾一下使用一个datapicker的jquery的插件,所需要的步奏:
1. 引入插件js
2. 引入插件所需的css(如果有)
3. copy 组件的所需的html片段
4. 添加代码触发组件启动
现阶段的“组件”基本上只能达到是某个功能单元上的集合。他的资源都是松散地分散在三种资源文件中,而且组件作用域暴露在全局作用域下,缺乏内聚性很容易就会跟其他组件产生冲突,如最简单的css命名冲突。对于这种“组件”,还不如上面的页面结构模块化。
于是W3C按耐不住了,制定一个WebComponents标准,为组件化的未来指引了明路。
下面以较为简洁的方式介绍这份标准,力求大家能够快速了解实现组件化的内容。(对这部分了解的同学,可以跳过这一小节)
1. <template>模板能力
模板这东西大家最熟悉不过了,前些年见的较多的模板性能大战artTemplate,juicer,tmpl,underscoretemplate等等。而现在又有mustachejs无逻辑模板引擎等新入选手。可是大家有没有想过,这么基础的能力,原生HTML5是不支持的(T_T)。
而今天WebComponent将要提供原生的模板能力
|
1
2
3
|
<
template
id
=
"datapcikerTmpl"
>
<
div
>我是原生的模板
<
/
div
>
<
/
template
>
|
template标签内定义了datapcikerTmpl的模板,需要使用的时候就要innerHTML= document.querySelector('#datapcikerTmpl').content;可以看出这个原生的模板够原始,模板占位符等功能都没有,对于动态数据渲染模板只能自力更新。
2. ShadowDom 封装组件独立的内部结构
ShadowDom可以理解为一份有独立作用域的html片段。这些html片段的CSS环境和主文档隔离的,各自保持内部的独立性。也正是ShadowDom的独立特性,使得组件化成为了可能。
|
1
2
3
|
var
wrap
=
document
.
querySelector
(
'#wrap'
)
;
var
shadow
=
wrap
.
createShadowRoot
(
)
;
shadow
.
innerHTML
=
'<p>you can not see me </p>'
|
在具体dom节点上使用createShadowRoot方法即可生成其ShadowDom。就像在整份Html的屋子里面,新建了一个shadow的房间。房间外的人都不知道房间内有什么,保持shadowDom的独立性。
3. 自定义原生标签
初次接触Angularjs的directive指令功能,设定好组件的逻辑后,一个<Datepicker />就能引入整个组件。如此狂炫酷炸碉堡天的功能,实在令人拍手称快,跃地三尺。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
var
tmpl
=
document
.
querySelector
(
'#datapickerTmpl'
)
;
var
datapickerProto
=
Object
.
create
(
HTMLElement
.
prototype
)
;
// 设置把我们模板内容我们的shadowDom
datapickerProto
.
createdCallback
=
function
(
)
{
var
root
=
this
.
createShadowRoot
(
)
;
root
.
appendChild
(
document
.
importNode
(
tmpl
.
content
,
true
)
)
;
}
;
var
datapicker
=
docuemnt
.
registerElement
(
'datapicker'
,
{
prototype
:
datapickerProto
}
)
;
|
Object.create方式继承HTMLElement.prototype,得到一个新的prototype。当解析器发现我们在文档中标记它将检查是否一个名为createdCallback的方法。如果找到这个方法它将立即运行它,所以我们把克隆模板的内容来创建的ShadowDom。
最后,registerElement的方法传递我们的prototype来注册自定义标签。
上面的代码开始略显复杂了,把前面两个能力“模板”“shadowDom”结合,形成组件的内部逻辑。最后通过registerElement的方式注册组件。之后可以愉快地<datapicker></datapicker>的使用。
4. imports解决组件间的依赖
|
1
|
<
link
rel
=
"import"
href
=
"datapciker.html"
>
|
这个类php最常用的html导入功能,HTML原生也能支持了。
WebComponents标准内容大概到这里,是的,我这里没有什么Demo,也没有实践经验分享。由于webComponents新特性,基本上除了高版本的Chrome支持外,其他浏览器的支持度甚少。虽然有polymer帮忙推动webcompoents的库存在,但是polymer自身的要求版本也是非常高(IE10+)。所以今天的主角并不是他。
我们简单来回顾一下WebCompoents的四部分功能:
1 .<template>定义组件的HTML模板能力
2. Shadow Dom封装组件的内部结构,并且保持其独立性
3. Custom Element 对外提供组件的标签,实现自定义标签
4. import解决组件结合和依赖加载
## 组件化实践方案
官方的标准看完了,我们思考一下。一份真正成熟可靠的组件化方案,需要具备的能力。
“资源高内聚”—— 组件资源内部高内聚,组件资源由自身加载控制
“作用域独立”—— 内部结构密封,不与全局或其他组件产生影响
“自定义标签”—— 定义组件的使用方式
“可相互组合”—— 组件正在强大的地方,组件间组装整合
“接口规范化”—— 组件接口有统一规范,或者是生命周期的管理
个人认为,模板能力是基础能力,跟是否组件化没有强联系,所以没有提出一个大点。
既然是实践,现阶段WebComponent的支持度还不成熟,不能作为方案的手段。而另外一套以高性能虚拟Dom为切入点的组件框架React,在facebook的造势下,社区得到了大力发展。另外一名主角Webpack,负责解决组件资源内聚,同时跟React极度切合形成互补。
所以【Webpack】+【React】将会是这套方案的核心技术。
不知道你现在是“又是react+webpack”感到失望 ,还是“太好了是react+webpack”不用再学一次新框架的高兴
,还是“太好了是react+webpack”不用再学一次新框架的高兴![]() 。无论如何下面的内容不会让你失望的。
。无论如何下面的内容不会让你失望的。
### 一,组件生命周期

React天生就是强制性组件化的,所以可以从根本性上解决面向过程代码所带来的麻烦。React组件自身有生命周期方法,能够满足“接口规范化”能力点。并且跟“页面结构模块化”的所封装抽离的几个方法能一一对应。另外react的jsx自带模板功能,把html页面片直接写在render方法内,组件内聚性更加紧密。
由于React编写的JSX是会先生成虚拟Dom的,需要时机才真正插入到Dom树。使用React必须要清楚组件的生命周期,其生命周期三个状态:
Mount: 插入Dom
Update: 更新Dom
Unmount: 拔出Dom
mount这单词翻译增加,嵌入等。我倒是建议“插入”更好理解。插入!拔出!插入!拔出!默念三次,懂了没?别少看黄段子的力量,

组件状态就是: 插入-> 更新 ->拔出。
然后每个组件状态会有两种处理函数,一前一后,will函数和did函数。
componentWillMount() 准备插入前
componentDidlMount() 插入后
componentWillUpdate() 准备更新前
componentDidUpdate() 更新后
componentWillUnmount() 准备拔出前
因为拔出后基本都是贤者形态(我说的是组件),所以没有DidUnmount这个方法。
另外React另外一个核心:数据模型props和state,对应着也有自个状态方法
getInitialState() 获取初始化state。
getDefaultProps() 获取默认props。对于那些没有父组件传递的props,通过该方法设置默认的props
componentWillReceiveProps() 已插入的组件收到新的props时调用
还有一个特殊状态的处理函数,用于优化处理
shouldComponentUpdate():判断组件是否需要update调用
加上最重要的render方法,React自身带的方法刚刚好10个。对于初学者来说是比较难以消化。但其实getInitialState,componentDidMount,render三个状态方法都能完成大部分组件,不必望而却步。
回到组件化的主题。
一个页面结构模块化的组件,能独立封装整个组件的过程线
![]()
我们换算成React生命周期方法:
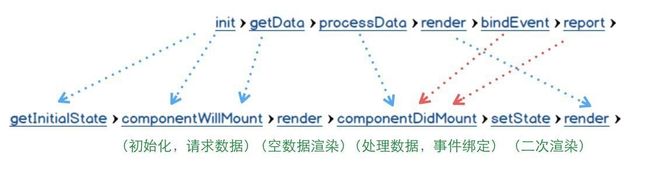
组件的状态方法流中,有两点需要特殊说明:
1,二次渲染:
由于React的虚拟Dom特性,组件的render函数不需自己触发,根据props和state的改变自个通过差异算法,得出最优的渲染。
请求CGI一般都是异步,所以必定带来二次渲染。只是空数据渲染的时候,有可能会被React优化掉。当数据回来,通过setState,触发二次render
2,componentWiillMount与componentDidMount的差别
和大多数React的教程文章不一样,ajax请求我建议在WillMount的方法内执行,而不是组件初始化成功之后的DidMount。这样能在“空数据渲染”阶段之前请求数据,尽早地减少二次渲染的时间。
willMount只会执行一次,非常适合做init的事情。
didMount也只会执行一次,并且这时候真实的Dom已经形成,非常适合事件绑定和complete类的逻辑。
### 二,JSX很丑,但是组件内聚的关键!
WebComponents的标准之一,需要模板能力。本是以为是我们熟悉的模板能力,但React中的JSX这样的怪胎还是令人议论纷纷。React还没有火起来的时候,大家就已经在微博上狠狠地吐槽了“JSX写的代码这TM的丑”。这其实只是Demo阶段JSX,等到实战的大型项目中的JSX,包含多状态多数据多事件的时候,你会发现………….JSX写的代码还是很丑。
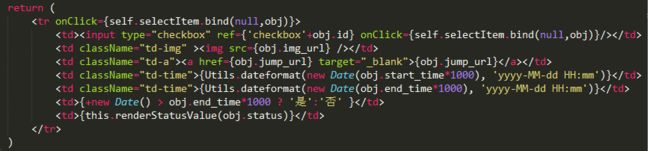
(即使用sublime-babel等插件高亮,逻辑和渲染耦合一起,阅读性还是略差)
为什么我们会觉得丑?因为我们早已经对“视图-样式-逻辑”分离的做法潜移默化。
基于维护性和可读性,甚至性能,我们都不建议直接在Dom上面绑定事件或者直接写style属性。我们会在JS写事件代理,在CSS上写上classname,html上的就是清晰的Dom结构。我们很好地维护着MVC的设计模式,一切安好。直到JSX把他们都糅合在一起,所守护的技术栈受到侵略,难免有所抵制。
但是从组件化的目的来看,这种高内聚的做法未尝不可。
下面的代码,之前的“逻辑视图分离”模式,我们需要去找相应的js文件,相应的event函数体内,找到td-info的class所绑定的事件。
对比起JSX的高度内聚,所有事件逻辑就是在本身jsx文件内,绑定的就是自身的showInfo方法。组件化的特性能立马体现出来。
|
1
|
<
p
className
=
"td-info"
onClick
=
{
this
.
showInfo
}
>
{
obj
.
info
}
<
/
p
>
|
(注意:虽然写法上我们好像是HTML的内联事件处理器,但是在React底层并没有实际赋值类似onClick属性,内层还是使用类似事件代理的方式,高效地维护着事件处理器)
再来看一段style的jsx。其实jsx没有对样式有硬性规定,我们完全可遵循之前的定义class的逻辑。任何一段样式都应该用class来定义。在jsx你也完全可以这样做。但是出于组件的独立性,我建议一些只有“一次性”的样式直接使用style赋值更好。减少冗余的class。
|
1
2
3
|
<
div
className
=
"list"
style
=
{
{
background
:
"#ddd"
}
}
>
{
list_html
}
<
/
div
>
|
或许JSX内部有负责繁琐的逻辑样式,可JSX的自定义标签能力,组件的黑盒性立马能体验出来,是不是瞬间美好了很多。
|
1
2
3
4
5
6
7
8
|
render
:
function
(
)
{
return
(
<
div
>
<
Menus
bannerNums
=
{
this
.
state
.
list
.
length
}
>
<
/
Menus
>
<
TableList
data
=
{
this
.
state
.
list
}
>
<
/
TableList
>
<
/
div
>
)
;
}
|
虽然JSX本质上是为了虚拟Dom而准备的,但这种逻辑和视图高度合一对于组件化未尝不是一件好事。
学习完React这个组件化框架后,看看组件化能力点的完成情况
“资源高内聚”—— (33%) html与js内聚
“作用域独立”—— (50%) js的作用域独立
“自定义标签”—— (100%)jsx
“可相互组合”—— (50%) 可组合,但缺乏有效的加载方式
“接口规范化”—— (100%)组件生命周期方法
### Webpack 资源组件化
对于组件化的资源独立性,一般的模块加载工具和构建流程视乎变得吃力。组件化的构建工程化,不再是之前我们常见的,css合二,js合三,而是体验在组件间的依赖于加载关系。webpack正好符合需求点,一方面填补组件化能力点,另一方帮助我们完善组件化的整体构建环境。
首先要申明一点是,webpack是一个模块加载打包工具,用于管理你的模块资源依赖打包问题。这跟我们熟悉的requirejs模块加载工具,和grunt/gulp构建工具的概念,多多少少有些出入又有些雷同。
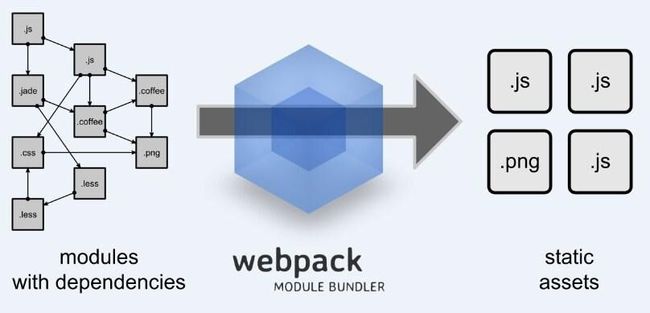
首先webpak对于CommonJS与AMD同时支持,满足我们模块/组件的加载方式。
|
1
2
3
4
|
require
(
"module"
)
;
require
(
"../file.js"
)
;
exports
.
doStuff
=
function
(
)
{
}
;
module
.
exports
=
someValue
;
|
|
1
2
3
|
define
(
"mymodule"
,
[
"dep1"
,
"dep2"
]
,
function
(
d1
,
d2
)
{
return
someExportedValue
;
}
)
;
|
当然最强大的,最突出的,当然是模块打包功能。这正是这一功能,补充了组件化资源依赖,以及整体工程化的能力
根据webpack的设计理念,所有资源都是“模块”,webpack内部实现了一套资源加载机制,可以把想css,图片等资源等有依赖关系的“模块”加载。这跟我们使用requirejs这种仅仅处理js大大不同。而这套加载机制,通过一个个loader来实现。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// webpack.config.js
module
.
exports
=
{
entry
:
{
entry
:
'./index.jsx'
,
}
,
output
:
{
path
:
__dirname
,
filename
:
'[name].min.js'
},
module
:
{
loaders
:
[
{
test
:
/
\
.
css
$
/
,
loader
:
'style!css'
}
,
{
test
:
/
\
.
(
jsx
|
js
)
?
$
/
,
loader
:
'jsx?harmony'
,
exclude
:
/
node_modules
/
}
,
{
test
:
/
\
.
(
png
|
jpg
|
jpeg
)
$
/
,
loader
:
'url-loader?limit=10240'
}
]
}
}
;
|
上面一份简单的webpack配置文件,留意loaders的配置,数组内一个object配置为一种模块资源的加载机制。test的正则为匹配文件规则,loader的为匹配到文件将由什么加载器处理,多个处理器之间用!分隔,处理顺序从右到左。
如style!css,css文件通过css-loader(处理css),再到style-loader(inline到html)的加工处理流。
jsx文件通过jsx-loader编译,‘?’开启加载参数,harmony支持ES6的语法。
图片资源通过url-loader加载器,配置参数limit,控制少于10KB的图片将会base64化。
#### 资源文件如何被require?
|
1
2
3
4
5
6
|
// 加载组件自身css
require
(
'./slider.css'
)
;
// 加载组件依赖的模块
var
Clip
=
require
(
'./clipitem.js'
)
;
// 加载图片资源
var
spinnerImg
=
require
(
'./loading.png'
)
;
|
在webpack的js文件中我们除了require我们正常的js文件,css和png等静态文件也可以被require进来。我们通过webpack命令,编译之后,看看输出结果如何:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
webpackJsonp
(
[
0
]
,
{
/* 0 */
/***/
function
(
module
,
exports
,
__webpack_require__
)
{
// 加载组件自身css
__webpack_require__
(
1
)
;
// 加载组件依赖的模块
var
Clip
=
__webpack_require__
(
5
)
;
// 加载图片资源
var
spinnerImg
=
__webpack_require__
(
6
)
;
/***/
}
,
/* 1 */
/***/
function
(
module
,
exports
,
__webpack_require__
)
{
/***/
}
,
/* 2 */
/***/
function
(
module
,
exports
,
__webpack_require__
)
{
exports
=
module
.
exports
=
__webpack_require__
(
3
)
(
)
;
exports
.
push
(
[
module
.
id
,
".slider-wrap{\r\n position: relative;\r\n width: 100%;\r\n margin: 50px;\r\n background: #fff;\r\n}\r\n\r\n.slider-wrap li{\r\n text-align: center;\r\n line-height: 20px;\r\n}"
,
""
]
)
;
/***/
}
,
/* 3 */
/***/
function
(
module
,
exports
)
{
/***/
}
,
/* 4 */
/***/
function
(
module
,
exports
,
__webpack_require__
)
{
/***/
}
,
/* 5 */
/***/
function
(
module
,
exports
)
{
console
.
log
(
'hello, here is clipitem.js'
)
;
/***/
}
,
/* 6 */
/***/
function
(
module
,
exports
)
{
module
.
exports
=
"data:image/png;base64,iVBORw0KGg......"
/***/
}
]
)
;
|
webpack编译之后,输出文件视乎乱糟糟的,但其实每一个资源都被封装在一个函数体内,并且以编号的形式标记(注释)。这些模块,由webpack的__webpack_require__内部方法加载。入口文件为编号0的函数index.js,可以看到__webpack_require__加载其他编号的模块。
css文件在编号1,由于使用css-loader和style-loader,编号1-4都是处理css。其中编号2我们可以看我们的css的string体。最终会以内联的方式插入到html中。
图片文件在编号6,可以看出exports出base64化的图片。
#### 组件一体输出
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// 加载组件自身css
require
(
'./slider.css'
)
;
// 加载组件依赖的模块
var
React
=
require
(
'react'
)
;
var
Clip
=
require
(
'../ui/clipitem.jsx'
)
;
// 加载图片资源
var
spinnerImg
=
require
(
'./loading.png'
)
;
var
Slider
=
React
.
createClass
(
{
getInitialState
:
function
(
)
{
// ...
}
,
componentDidMount
:
function
(
)
{
// ...
}
,
render
:
function
(
)
{
return
(
<
div
>
<
Clip
data
=
{
this
.
props
.
imgs
}
/
>
<
img
className
=
"loading"
src
=
{
spinnerImg
}
/
>
<
/
div
>
)
;
}
}
)
;
module
.
exports
=
Slider
;
|
如果说,react使到html和js合为一体。
那么加上webpack,两者结合一起的话。js,css,png(base64),html 所有web资源都能合成一个JS文件。这正是这套方案的核心所在:组件独立一体化。如果要引用一个组件,仅仅require('./slider.js') 即可完成。
加入webpack的模块加载器之后,我们组件的加载问题,内聚问题也都成功地解决掉
“资源高内聚”—— (100%) 所有资源可以一js输出
“可相互组合”—— (100%) 可组合可依赖加载
### CSS模块化实践
很高兴,你能阅读到这里。目前我们的组件完成度非常的高,资源内聚,易于组合,作用域独立互不污染。。。。等等![]() ,视乎CSS模块的完成度有欠缺。
,视乎CSS模块的完成度有欠缺。
那么目前组件完成度来看,CSS作用域其实是全局性的,并非组件内部独立。下一步,我们要做得就是如何让我们组件内部的CSS作用域独立。
这时可能有人立马跳出,大喊一句“德玛西亚!”,哦不,应该是“用sass啊傻逼!”。可是项目组件化之后,组件的内部封装已经很好了,其内部dom结构和css趋向简单,独立,甚至是破碎的。LESS和SASS的一体式样式框架的设计,他的嵌套,变量,include,函数等丰富的功能对于整体大型项目的样式管理非常有效。但对于一个功能单一组件内部样式,视乎就变的有点格格不入。“不能为了框架而框架,合适才是最好的”。视乎原生的css能力已经满足组件的样式需求,唯独就是上面的css作用域问题。
这里我给出思考的方案: classname随便写,保持原生的方式。编译阶段,根据组件在项目路径的唯一性,由【组件classname+组件唯一路径】打成md5,生成全局唯一性classname。正当我要写一个loader实现我的想法的时候,发现歪果仁已经早在先走一步了。。。。
这里具体方案参考我之前博客的译文:http://www.alloyteam.com/2015/10/8536/
之前我们讨论过JS的模块。现在通过Webpack被加载的CSS资源叫做“CSS模块”?我觉得还是有问题的。现在style-loader插件的实现本质上只是创建link[rel=stylesheet]元素插入到document中。这种行为和通常引入JS模块非常不同。引入另一个JS模块是调用它所提供的接口,但引入一个CSS却并不“调用”CSS。所以引入CSS本身对于JS程序来说并不存在“模块化”意义,纯粹只是表达了一种资源依赖——即该组件所要完成的功能还需要某些asset。
因此,那位歪果仁还扩展了“CSS模块化”的概念,除了上面的我们需要局部作用域外,还有很多功能,这里不详述。具体参考原文 http://glenmaddern.com/articles/css-modules
非常赞的一点,就是cssmodules已经被css-loader收纳。所以我们不需要依赖额外的loader,基本的css-loader开启参数modules即可
|
1
2
3
4
5
6
7
8
|
//webpack.config.js
.
.
.
module
:
{
loaders
:
[
{
test
:
/
\
.
css
$
/
,
loader
:
'style!css?modules&localIdentName=[local]__[name]_[hash:base64:5]'
}
,
]
}
.
.
.
.
|
modules参数代表开启css-modules功能,loaclIdentName为设置我们编译后的css名字,为了方便debug,我们把classname(local)和组件名字(name)输出。当然可以在最后输出的版本为了节省提交,仅仅使用hash值即可。另外在react中的用法大概如下。
|
1
2
3
4
5
6
7
8
9
10
11
|
var
styles
=
require
(
'./banner.css'
)
;
var
Banner
=
new
React
.
createClass
(
{
.
.
.
render
:
function
(
)
{
return
(
<
div
>
<
div
className
=
{
styles
.
classA
}
>
<
/
div
>
<
/
div
>
)
}
}
)
;
|
最后这里关于出于对CSS一些思考,
关于css-modules的其它功能,我并不打算使用。在内部分享【我们竭尽所能地让CSS变得复杂】中提及:
我们项目中大部分的CSS都不会像boostrap那样需要变量来设置,身为一线开发者的我们大概能够感受到:设计师们改版UI,绝对不是简单的换个色或改个间距,而是面目全非的全新UI,这绝对不是一个变量所能解决的”维护性“。
反而项目实战过程中,真正要解决的是:在版本迭代过程中那些淘汰掉的过期CSS,大量地堆积在项目当中。我们像极了家中的欧巴酱不舍得丢掉没用的东西,因为这可是我们使用sass或less编写出具有高度的可维护性的,肯定有复用的一天。
这些堆积的过期CSS(or sass)之间又有部分依赖,一部分过期没用了,一部分又被新的样式复用了,导致没人敢动那些历史样式。结果现网项目迭代还带着大量两年前没用的样式文件。
组件化之后,css的格局同样被革新了。可能postcss才是你现在手上最适合的工具,而不在是sass。
到这里,我们终于把组件化最后一个问题也解决了。
“作用域独立”—— (100%) 如同shadowDom作用域独立
到这里,我们可以开一瓶82年的雪碧,好好庆祝一下。不是吗?

### 组件化之路还在继续
webpack和react还有很多新非常重要的特性和功能,介于本文仅仅围绕着组件化的为核心,没有一一阐述。另外,配搭gulp/grunt补充webpack构建能力,webpack的codeSplitting,react的组件通信问题,开发与生产环境配置等等,都是整套大型项目方案的所必须的,限于篇幅问题。可以等等我更新下篇,或大家可以自行查阅。
但是,不得不再安利一下react-hotloader神器。热加载的开发模式绝对是下一代前端开发必备。严格说,如果没有了热加载,我会很果断地放弃这套方案,即使这套方案再怎么优秀,我都讨厌react需要5~6s的编译时间。但是hotloader可以在我不刷新页面的情况下,动态修改代码,而且不单单是样式,连逻辑也是即时生效。
如上在form表单内。使用热加载,表单不需要重新填写,修改submit的逻辑立刻生效。这样的开发效率真不是提高仅仅一个档次。必须安利一下。
或许你发现,使用组件化方案之后,整个技术栈都被更新了一番。学习成本也不少,并且可以预知到,基于组件化的前端还会很多不足的问题,例如性能优化方案需要重新思考,甚至最基本的组件可复用性不一定高。后面很长一段时间,需要我们不断磨练与优化,探求最优的前端组件化之道。
至少我们可以想象,不再担心自己写的代码跟某个谁谁冲突,不再为找某段逻辑在多个文件和方法间穿梭,不再copy一片片逻辑然后改改。我们每次编写都是可重用,可组合,独立且内聚的组件。而每个页面将会由一个个嵌套组合的组件,相互独立却相互作用。
对于这样的前端未来,有所期待,不是很好吗
至此,感谢你的阅读。