《笔者带你剖析轻量级Sharding中间件——Kratos1.x》
之所以编写Kratos其实存在一个小插曲,当笔者满山遍野寻找成熟、稳定、高性能的Sharding中间件时,确实是翻山越岭,只不过始终没有找到一款合适笔者项目场景的中间件产品。依稀记得当年第一款使用的Sharding中间件就是淘宝的TDDL3.0,只可惜现在拿不到源码。而其它的中间件,大多都是基于Proxy的,相信做过分布式系统的人都知道,抛开网络消耗所带来的性能问题不谈,多一个外围系统依赖就意味着需要多增加和承担一份风险,因此与应用集成的方式,则成为笔者选择的首要条件。当然不是说基于Proxy方式的Sharding中间件不好,只能说我个人并不看重通用型需求,仅此而已。其实目前社区非常活跃的MyCat,笔者在这里要批评一下,既然开源,那么就请在GitHub上贴上使用手册,而不是配置手册,因为对于一个任何一个DVP而言,他要的是迅速上手的帮助文档,而不是要使用你们的开源产品还需要在淘宝上购买几十块一本的网络书,对于这一点,我非常鄙视和厌恶。
许多开发人员动不动就大谈分库分表来显示自己的成就感,那么笔者需要做的事情就是将其拉下神坛,让大家切切实实感受到一款平民化技术所带来的亲民性。作为一款数据路由工具,Kratos采用与应用集成的方式为开发人员带来超强的易用性。就目前而言,笔者测试环境上,物理环境选用为32库和1024表的库内分片模式,因此笔者就先不必王婆卖瓜,自卖自夸其所谓的高性能和高稳定。至于你是否能够从Kratos中获益,取决于你是否想用最简单,最易上手的方式来解决分库分表场景下的数据路由工作。
笔者此篇博文,并不是宣导和普及分库分表理论,而是作为Kratos货真价实的Sharding权威指南手册呈现给大家。目前Kratos1.3.0版本已经在Github上开源,地址为:https://github.com/gaoxianglong/kratos。
目录
一、Kratos简介;
二、互联网当下的数据拆分过程;
三、目前市面上常见的一些Sharding中间件产品对比;
四、Kratos的架构原型;
五、动态数据源层的Master/Slave读写分离;
六、Kratos的Sharding模型;
七、Sharding之库内分片;
八、Sharding之一库一片;
九、自动生成全局唯一的sequenceId;
十、自动生成kratos分库分表配置文件;
十一、注意事项;
一、Kratos简介
因为找不到合适的Shading中间件,其次一些开源的Shading中间件动不动就几万行的代码真有必要吗?因此诞生了编写自己中间件的想发。Kratos这个名字来源于笔者之前在PS3平台玩的一款ACT游戏《战神3》中嗜血杀神的主角奎爷Kratos,尽管笔者的Kratos并没有展现出秒杀其他Sharding中间件的霸气,但Kratos要做的事情很纯粹,仅仅就只是处理分库分表场景下的数据路由工作,它处于数据路由层,介于持久层与JDBC之间,因此没有其它看似有用实则花哨的鸡肋功能,并且与应用层集成的方式注定了Kratos必然拥有更好的易用性。
对于开发人员而言,在使用Kratos的时候,就好像是在操作同一个数据源一样,也就是说,之前你的sql怎么写,换上Kratos之后,业务逻辑无需做出变动,你只需要关心你的逻辑即可,数据路由工作,你完全可以放心的交由Kratos去处理。Kratos站在巨人的肩膀上,必然拥有更大的施展空间。首先Kratos依赖于Spring JDBC,那么如果你习惯使用JdbcTemplate,那就都不是问题,反之你可以先看一下笔者的博文《笔者带你剖析Spring3.x JDBC》。其次Kratos目前仅仅只支持Mysql数据库,对于其他RDBMS类型的数据库,基本上以后也不会支持,简单来说,通用型需求并不是Kratos的目标,做好一件事才是真正的实惠。
kratos的优点:
1、动态数据源的无缝切换;
2、master/slave一主一从读写分离;
3、单线程读重试(取决于的数据库连接池是否支持);
4、单独且友好支持Mysql数据库,不支持其它RDBMS库;
5、非Proxy架构,与应用集成,应用直连数据库,降低外围系统依赖带来的down机风险;
6、使用简单,侵入型低,站在巨人的肩膀上,依赖于Spring JDBC;
7、不做真正意义上的Sql解析任务,规避Sql解析过程中由词法解析、语法解析、语义解析等操作所带来的
性能延迟,仅用正则表达式解析 片名和Route条件,解析过程仅耗时约<=1ms;
8、分库分表路由算法支持2类4种分片模式,库内分片/一库一片;
9、提供自动生成sequenceId的API支持;
10、提供自动生成配置文件的支持,降低配置出错率;
11、目标和职责定位明确,仅专注于Sharding,不支持其它多余或鸡肋功能、无需兼容通用性,因此核心代
码量少、易读易维护
二、互联网当下的数据拆分过程
对于一个刚上线的互联网项目来说,由于前期活跃度并不大,并发量相对较小,因此企业一般都会选择将所有数据存放在一个物理DB中进行读写操作。但随着后续的市场推广力度不断加强,活跃度不断提升,这时如果仅靠一个DB来支撑所有读写压力,就会显得力不从心。所以一般到了这个阶段,大部分Mysql DBA就会将数据库设置为读写分离状态(一主一从/一主多从),Master负责写操作,而Slave负责读操作。按照二八定律,80%的操作更多是读操作,那么剩下的20%则为写操作,经过读写分离后,大大提升了单库无法支撑的负载压力。不过光靠读写分离并不会一劳永逸,如果活跃度再次提升,相信又会再次遇见数据库的读写瓶颈。因此到了这个阶段,就需要实现垂直分库。
所谓垂直分库,简单来说就是根据业务的不同将原本冗余在单库中的业务表拆散,分布到不同的业务库中,实现分而治之的读写访问操作。当然我们都知道,传统RDBMS数据库中的数据表随着数据量的暴增,从维护性和高响应的角度去看,无论任何CRUD操作,对于数据库而言,都是一件极其伤脑筋的事情。即便设置了索引,检索效率依然低下,因为随着数据量的暴增,RDBMS数据库的性能瓶颈就会逐渐显露出来。这一点,Nosql数据库倒是做得很好,当然架构不同,所以不予比较。那么既然已经到了这个节骨眼上了,唯一的杀手锏就是在垂直分库的基础之上进行水平分区,也就是我们常说的Sharding。
简单来说,水平分区要做的事情,就是将原本冗余在单库中的业务表分散为N个子表(比如tab_0001、tab_0002、tab_0003、tab_0004...)分别存放在不同的子库中。理论上来讲,子表之间通过某种契约关联在一起,每一张子表均按段位进行数据存储,比如tab_0000存储1-10000的数据,而tab_0001存储10001-20000的数据。经过水平分区后,必然能够将原本由一张业务表维护的海量数据分配给N个子表进行读写操作和维护,大大提升了数据库的读写性能,降低了性能瓶颈。基于分库分表的设计,目前在国内一些大型网站中应用的非常普遍。
当然一旦实现分库分表后,将会牵扯到5个非常关键的问题,如下所示:
1、单机ACID被打破,分布式事务一致性难以保证;
2、数据查询需要进行跨库跨表的数据路由;
3、多表之间的关联查询会有影响;
4、单库中依赖于主键序列自增时生成的唯一ID会有影响;
5、强外键(外键约束)难以支持,仅能考虑弱外键(约定);
三、目前市面上常见的一些Sharding中间件产品对比
其实目前市面上的分库分表产品不在少数,但是这类产品,更多的是基于Proxy架构的方式,在对于不看重通用性的前提下,基于应用集成架构的中间件则只剩下淘宝的TDDL和Mysql官方的Fabric。其实笔者还是非常喜欢TDDL的,Kratos中所支持的库内分片就是效仿的TDDL,相信大家也看得出来笔者对TDDL的感情。但是TDDL并非是绝对完美的,其弊端同样明显,比如:社区推进力度缓慢、文档资料匮乏、过多的功能、外围系统依赖,再加上致命伤非开源,因此注定了TDDL无法为欣赏它的非淘宝系用户服务。而Fabric,笔者接触的太少了,并且正式版发行时间还是太短了,因此就不想当小白鼠去试用,避免出现hold不住的情况。目前常见的一些Shardig中间件产品对比,如图A-1所示:

图A-1 常见的Shading中间件对比
在基于Proxy架构的Sharding中间件中,大部分的产品基本上都是衍生子Cobar,并且这类产品对分片算法的支持都仅限于一库一片的分片方式。对于库内分片和一库一片等各自的优缺点,笔者稍后会进行讲解。具体使用什么样的中间件产品,还需要根据具体的应用场景而定,当然如果是你正在愁找不到完善的使用手册、配置手册之类的文档资料,Kratos你可以优先考虑。
四、Kratos的架构原型
简单来说,分库分表中间件无非就是根据Sharding算法对持有的多数据源进行动态切换,这是任何Sharding中间件最核心的部分。一旦在程序中使用Kratos后,应用层将会持有N个数据源,Kratos通过路由条件进行运算,然后通过Route技术对数据库和数据表进行读写操作。在此大家需要注意,Kratos内部并没有实现自己的ConnectionPool,这也就意味着,给了开发人员极大的自由,使之可以随意切换任意的ConnectionPool产品,比如你觉得C3P0没有BonePC性能高,那么你可以切换为BonePC。
对于开发人员而言,你并不需要关心底层的数据库和表的划分规则,程序中任何的CRUD操作,都像是在操作同一个数据库一样,并且读写效率还不能够比之前低太多(比如几毫秒或者实际毫秒之内完成),而Kratos就承担着这样的一个任务。Kratos所处的领域模型定位,如图A-2所示:

图A-2 Kratos的领域模型定位
如图A-2所示,Kratos的领域模型定位处于持久层和JDBC之间。之前笔者曾经提及过,Kratos是站在巨人的肩膀上,这个巨人正是Spring。简单来说,Kratos重写了JdbcTemplate,并使用了Spring提供的AbstractRoutingDataSource作为动态数据源层。因此从另外一个侧面反应了Kratos的源码注定是简单、轻量、易阅读、易维护的,因为Kratos更多的关注点只会停留在Master/Slave读写分离层和分库分表层。我们知道一般的Shading中间件,动不动就几万行代码,其中得“猫腻”有很多,不仅数据库连接池要自己写、动态数据源要自己写,再加上一些杂七杂八的功能,比如:通用性支持、多种类型的RDBMS或者Nosql支持,那么代码自然冗余,可读性极差。在Kratos中,这些都问题完全会“滚犊子”,因为Kratos只会考虑如何通过Sharding规则实现数据路由。Kratos的3层架构,如图A-3所示:

图A-3 Kratos的3层架构
既然Kratos只考虑最核心的功能,同时也就意味着它的性能恒定指标还需要结合其他第三方产品,比如Kratos的动态数据源层所使用的ConnectionPool为C3P0,尽管非常稳定的,但是性能远远比不上使用BonePC,因此大家完全可以将Kratos看做一个高效的黏合剂,它的核心任务就是数据路由,你别指望Kratos还能为你处理边边角角的零碎琐事,想要什么效果,自行组合配置,这就是Kratos,一个简单、轻量级的Sharding中间件。Kratos的应用总体架构,如图A-4所示:

图A-4 Kratos的应用总体架构
五、动态数据源层的Master/Slave读写分离
当大家对Kratos有了一个基本的了解后,那么接下来我们就来看看如何在程序中使用Kratos。com.gxl.kratos.jdbc.core.KratosJdbcTemplate是Kratos提供的一个Jdbc模板,它继承自Spring的JdbcTemplate。简单来说,KratosJdbcTemplate几乎支持JdbcTemplate的所有方法(除批量操作外)。对于开发人员而言,只需要将JdbcTemplate替换为KratosJdbcTemplate即可,除此之外,程序中没有其他任何需要进行修改的地方,这种低侵入性相信大家都应该能够接受。
一般来说,数据库的主从配置,既可以一主一从,也可以一主多从,但目前Kratos仅支持一主一从。接下来我们再来看看如何在配置文件中配置一主一从的读写分离操作,如下所示:
<import resource="datasource1-context.xml" /> <aop:aspectj-autoproxy proxy-target-class="true" /> <context:component-scan base-package="com"> <context:include-filter type="annotation" expression="org.aspectj.lang.annotation.Aspect" /> </context:component-scan> <bean id="kJdbcTemplate" class="com.gxl.kratos.jdbc.core.KratosJdbcTemplate"> <constructor-arg name="isShard" value="false"/> <property name="dataSource" ref="kDataSourceGroup"/> <property name="wr_weight" value="r1w0"/> </bean> <bean id="kDataSourceGroup" class="com.gxl.kratos.jdbc.datasource.config.KratosDatasourceGroup"> <property name="targetDataSources"> <map key-type="java.lang.Integer"> <entry key="0" value-ref="dataSource1"/> <entry key="1" value-ref="dataSource2"/> </map> </property> </bean>
上述程序实例中,com.gxl.kratos.jdbc.datasource.config.KratosDatasourceGroup就是一个用于管理多数据源的Group,它继承自Spring提供的AbstractRoutingDataSource,并充当了动态数据源层的角色,由此基础之上实现DBRoute。我们可以看见,在<entry/>标签中,key属性指定了数据源索引,而value-ref属性指定了数据源,通过这种简单的键值对关系就可以明确的切换到具体的目标数据源上。
在com.gxl.kratos.jdbc.core.KratosJdbcTemplate中,isShard属性实际上就是一个Sharding开关,缺省为false,也就意味着缺省是没有开启分库分表的,那么在不Sharding的情况下,我们依然可以使用Kratos来完成读写分离操作。在wr_weight属性中定义了读写分离的权重索引,也就是说,我们有多少个主库,就一定需要有多少个从库,比如主库有1个,从库也应该是1个,因此KratosDatasourceGroup中持有的数据源个数就应该一共是2个,索引从0-1,如果主库的索引为0,那么从库的索引就应该为1,也就是“r1w0”。当配置完成后,一旦Kratos监测到执行的操作为写操作时,就会自动切换为主库的数据源,而当操作为读操作的时候,就会自动切换为从库的数据源,从而实现一主一从的读写分离操作。
六、Kratos的Sharding模型
目前市面上的Sharding中间的分库分表算法有2种最常见的类型,分别是库内分片和一库一片。笔者先从库内分片开始谈起,并且会在后续进行比较这2种分片算法的优劣势,让大家更好的进行选择使用。
库内分片是TDDL采用的一种分片算法,这种分片算法相对来说较为复杂,因为不仅需要根据路由条件计算出数据应该落盘到哪一个库,还需要计算需要落盘到哪一个子表中。比如我们生产上有32个库,数据库表有1024张,那么平均每个库中存放的子表数量就应该是32个。库内分片算法示例,如图A-5所示:
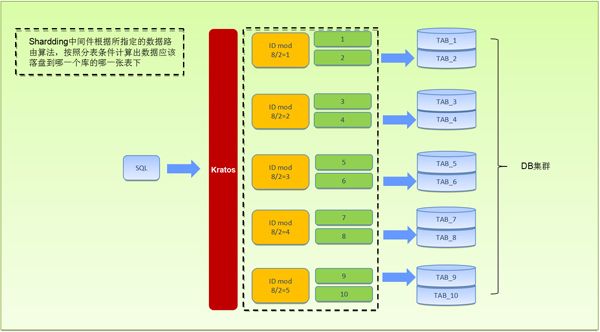
图A-5 库内分片
一库一片目前是非常常见的一种分片算法,它同时具备了简单性和易维护性等特点。简单来说,一旦通过路由算法计算出数据需要落盘到哪一个库后,就等于间接的计算出了需要落盘到哪一个子表下。假设我们有1024个子表,那么对应的数据库也应该是1024个,当计算出数据需要落盘到第105个库的时候,自然子表也就是第105个。一库一片算法示例,如图A-6所示:

图A-6 一库一片
那么我们究竟在生产中应该选择库内分片还是一库一片呢?尽管Kratos这2种分片算法都同时支持,但生产上所使用的分片算法最好是统一的,千万别一个子系统的分片算法使用的库内分片,而另外一个子系统使用的是一库一片,因为这样对于DBA来说将会极其痛苦,不仅维护极其困难,数据迁移也是一个头痛的问题。笔者建议优先考虑一库一片这种分片方式,因为这种分片方式维护更简单,并且在后期数据库扩容时,数据迁移工作更加容易和简单,毕竟算出来库就等于算出来表,迁移越简单就意味着生产上停应用的时间更短。当然究竟应该选择哪一种分片算法,还需要你自行考虑抉择。
七、Sharding之库内分片
之前笔者已经提及过,Kratos的低侵入性设计只需要将原本的JdbcTemplate替换为KratosJdbcTemplate即可,除此之外,程序要不需要修改任何地方,因为读写分离操作、分库分表操作都仅仅只是在配置文件中进行配置的,无需耦合在业务逻辑中。库内分片的配置,如下所示:
<import resource="datasource1-context.xml" />
<aop:aspectj-autoproxy proxy-target-class="true" />
<!-- 自动扫描 -->
<context:component-scan base-package="com">
<context:include-filter type="annotation"
expression="org.aspectj.lang.annotation.Aspect" />
</context:component-scan>
<bean id="kJdbcTemplate" class="com.gxl.kratos.jdbc.core.KratosJdbcTemplate">
<!-- Sharding开关 -->
<constructor-arg name="isShard" value="true"/>
<property name="dataSource" ref="kDataSourceGroup"/>
<!--读写权重 -->
<property name="wr_weight" value="r32w0"/>
<!-- 分片算法模式,false为库内分片,true为一库一片 -->
<property name="shardMode" value="false"/>
<!-- 分库规则 -->
<property name="dbRuleArray" value="#userinfo_id|email_hash# % 1024 / 32"/>
<!-- 分表规则 -->
<property name="tbRuleArray" value="#userinfo_id|email_hash# % 1024 % 32"/>
</bean>
<bean id="kDataSourceGroup" class="com.gxl.kratos.jdbc.datasource.config.KratosDatasourceGroup">
<property name="targetDataSources">
<map key-type="java.lang.Integer">
<entry key="0" value-ref="dataSource1"/>
<!-- 省略一部分数据源... -->
<entry key="63" value-ref="dataSource2"/>
</map>
</property>
</bean>
上述程序示例中,笔者使用的是一主一从读写分离+库内分片模式。主库一共是32个(1024个子表,每个库包含子表数为32个),那么自然从库也就是32个,在KratosDatasourceGroup中一共会持有64个数据源,数据源索引为0-63。那么在KratosJdbcTemplate中首先要做的事情是将分库分片开关打开,然后读写权重索引wr_weight属性的比例是“r32w0”,这也就意味着0-31都是主库,而32-63都是从库,Kratos会根据这个权重索引来自动根据所执行的操作切换到对应的主从数据源上。属性shardMode其实就是指明了需要Kratos使用哪一种分片算法,true为一库一片,而false则为库内分片。
属性dbRuleArray指明了分库规则,“#userinfo_id|email_hash# % 1024 / 32”指明了路由条件可能包括两个,分别为userinfo_id和email_hash。然后根据路由条件先%tbSize,最后在/dbSize,即可计算出具体的数据源。在此大家需要注意,库的倍数一定要是表的数量,否则数据将无法均匀分布到所有的子表上。或许大家有个疑问,为什么路由条件会有多个呢?这是因为在实际的开发过程中,我们所有的查询条件都需要根据路由条件来,并且实际情况不可能只有一个理由条件,甚至有可能更多(比如反向索引表)。因此通过符号“|”分隔开多个路由条件。当一条sql执行时,Kratos会匹配sql条件中的第一个数据库参数字段是否是分库分表条件,如果不是则会抛出异常com.gxl.kratos.jdbc.exception.ShardException。分表规则“#userinfo_id|email_hash# % 1024 % 32”其实大致和分库规则一样,只不过最后并非是/dbSize,而是%dbSize。经过分库分表算法后,一条sql就会被解析并落盘到指定的库和指定的表中。
八、Sharding之一库一片
一库一片类似于库内分片的配置,但又细微的不同,之前笔者曾经提及过,使用一库一片算法后,根据路由条件计算出库后,就等于间接计算出表,那么配置文件中就只需配置分库规则即可。一库一片的配置,如下所示:
<import resource="datasource1-context.xml" />
<aop:aspectj-autoproxy proxy-target-class="true" />
<!-- 自动扫描 -->
<context:component-scan base-package="com">
<context:include-filter type="annotation"
expression="org.aspectj.lang.annotation.Aspect" />
</context:component-scan>
<bean id="kJdbcTemplate" class="com.gxl.kratos.jdbc.core.KratosJdbcTemplate">
<!-- Sharding开关 -->
<constructor-arg name="isShard" value="true"/>
<property name="dataSource" ref="kDataSourceGroup"/>
<!--读写权重 -->
<property name="wr_weight" value="r32w0"/>
<!-- 分片算法模式,false为库内分片,true为一库一片 -->
<property name="shardMode" value="true"/>
<!-- 分库规则 -->
<property name="dbRuleArray" value="#userinfo_id|email_hash# % 32"/>
</bean>
<bean id="kDataSourceGroup" class="com.gxl.kratos.jdbc.datasource.config.KratosDatasourceGroup">
<property name="targetDataSources">
<map key-type="java.lang.Integer">
<entry key="0" value-ref="dataSource1"/>
<!-- 省略一部分数据源... -->
<entry key="63" value-ref="dataSource2"/>
</map>
</property>
</bean>
上述程序示例中,笔者使用的是一主一从读写分离+一库一片模式。主库一共是32个(32个子表,每个库包含子表数为1个),那么自然从库也就是32个,在KratosDatasourceGroup中一共会持有64个数据源,数据源索引为0-63。权重索引wr_weight属性的比例是“r32w0”,这也就意味着0-31都是主库,而32-63都是从库,Kratos会根据这个权重索引来自动根据所执行的操作切换到对应的主从数据源上。属性shardMode其实就是指明了需要Kratos使用哪一种分片算法,true为一库一片,而false则为库内分片。
属性dbRuleArray指明了分库规则,“#userinfo_id|email_hash# % 32”指明了路由条件可能包括两个,分别为userinfo_id和email_hash。然后根据路由条件%dbSize即可计算出数据究竟应该落盘到哪一个库的哪一个子表下。
九、自动生成全局唯一的sequenceId
一旦我们分库分表后,原本单库中使用的序列自增Id将无法再继续使用,那么这应该怎么办呢?其实解决这个问题并不困难,目前有2种方案,第一种是所有的应用统一调用一个集中式的Id生成器,另外一种则是每个应用集成一个Id生成器。无论选择哪一种方案,Id生成器所持有的DB都只有一个,也就是说,通过一个通用DB去管理和生成全局以为的sequenceId。
目前市面上几乎所有的Sharding中间件都没有提供sequenceId的支持,而Kratos的工具包中却为大家提供了支持。Kratos选择的是每个应用都集成一个Id生成器,而没有采用集中式Id生成器,因为在分布式场景下,多一个外围系统依赖就意味着多一分风险,相信这个道理大家都应该懂。那么究竟应该如何使用Kratos提供的Id生成器呢?首先我们需要单独准备一个全局DB出来,然后使用Kratos的建表语句,如下所示:
CREATE TABLE kratos_sequenceid( k_id INT NOT NULL AUTO_INCREMENT COMMENT '主键', k_type INT NOT NULL COMMENT '类型', k_useData BIGINT NOT NULL COMMENT '申请占位数量', PRIMARY KEY (k_id) )ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_bin;
当成功建立好生成sequenceId所需要的数据库表后,接下来要做的事情就是进行调用。生成sequenceId,如下所示:
/**
* 获取SequenceId
*
* @author gaoxianglong
*/
public @Test void getSequenceId() {
/* 初始化数据源信息 */
DbConnectionManager.init("account", "pwd", "url", "driver");
System.out.println(SequenceIDManger.getSequenceId(1, 1, 5000));
}
上述程序示例中,首先需要调用com.gxl.kratos.utils.sequence.DbConnectionManager类的init()方法对数据源进行初始化,然后调用com.gxl.kratos.utils.sequence.DbConnectionManager类的getSequenceId()方法即可成功获取全局唯一的sequenceId。在此大家需要注意,Kratos生成的sequenceId是一个17-19位之间的整型,在getSequenceId()方法中,第一个参数为IDC机房编码,第二个参数为类型操作码,而最后一个参数非常关键,就是需要向DB中申请的内存占位数量(自增码)。
简单来说,相信大家都知道,既然业务库都分库分表了,就是为了缓解数据库读写瓶颈,当并发较高时,一个生成sequenceId的通用数据库能扛得住吗?笔者告诉你,扛得住!就是因为内存占位。其实原理很简单,当第一次应用从Id生成器中去拿sequenceId时,Id生成器会锁表并将数据库字段k_useData更新为5000,那么第二次应用从Id生成器中去拿sequenceId时,将不会与DB建议物理会话链接,而是直接在内存中去消耗着5000内存占位数,直至消耗殆尽时,才会重新去数据库中申请下一次的内存占位。
那么问题又来了,如果并发访问会不会有问题呢?其实保证全局唯一性有3点,第一是程序中会加锁,其次数据库会for update,最后每一个操作码都是唯一的,都会管理自己旗下的内存占位数(通过Max()函数比较,累加下一个5000)。或许你会在想,如何提升Id生成器的性能,尽可能的避免与数据库建立物理会话,没错,这么想是对的,每次假设从数据库申请的占位数量是50000,那么性能肯定比只申请5000好,但是这也有弊端,一旦程序出现down机,内存中的内存数量就会丢失,只能重新申请,这会造成资源浪费。
十、自动生成kratos分库分表配置文件
Kratos的工具包中除了提供有自动生成sequenceId的功能外,还提供有自动生成分库分表配置文件等功能。笔者自己是非常喜欢这个功能。因为这很明显可以减少配置出错率。比如我们采用库内分片模式,32个库1024个表,数据源配置文件中,需要配置的数据源信息会有32个,当然这通过手工的方式也未尝不可,无非就是一个kratos分库分表配置文件+一个dataSource文件(如果主从的话,还需要一个从库的dataSource文件),dataSource文件中需要编写32个数据源信息的<bean/>标签。但是如果我们使用的是一库一片这种分片方式,使用的库的数量是1024个的时候呢?dataSource文件中需要定义的数据源将会是1024个?写不死你吗?你能保证配置不会出问题?
既然手动编写配置文件可能会出现错误,那么究竟应该如何使用Kratos提供的自动生成配置文件功能来降低出错率呢?Kratos自动生成配置文件,如下所示:
/**
* 生成核心配置文件
*
* @author gaoxianglong
*/
public @Test void testCreateCoreXml() {
CreateXml c_xml = new CreateXml();
/* 是否控制台输出生成的配置文件 */
c_xml.setIsShow(true);
/* 配置分库分片信息 */
c_xml.setDbSize("1024");
c_xml.setShard("true");
c_xml.setWr_weight("r0w0");
c_xml.setShardMode("false");
c_xml.setDbRuleArray("#userinfo_id|email_hash# % 1024");
//c_xml.setTbRuleArray("#userinfo_id|email_hash# % 1024 % 32");
/* 执行配置文件输出 */
System.out.println(c_xml.createCoreXml(new File("e:/kratos-context.xml")));
}
/**
* 生成数据源配置文件
*
* @author gaoxianglong
*/
public @Test void testCreateDadasourceXml() {
CreateXml c_xml = new CreateXml();
/* 是否控制台输出生成的配置文件 */
c_xml.setIsShow(true);
/* 数据源索引起始 */
c_xml.setDataSourceIndex(1);
/* 配置分库分片信息 */
c_xml.setDbSize("1024");
/* 配置数据源信息 */
c_xml.setJdbcUrl("jdbc:mysql://ip:3306/um");
c_xml.setUser("${name}");
c_xml.setPassword("${password}");
c_xml.setDriverClass("${driverClass}");
c_xml.setInitialPoolSize("${initialPoolSize}");
c_xml.setMinPoolSize("${minPoolSize}");
c_xml.setMaxPoolSize("${maxPoolSize}");
c_xml.setMaxStatements("${maxStatements}");
c_xml.setMaxIdleTime("${maxIdleTime}");
/* 执行配置文件输出 */
System.out.println(c_xml.createDatasourceXml(new File("e:/dataSource-context.xml")));
}
/**
* 生成master/slave数据源配置文件
*
* @author gaoxianglong
*/
public @Test void testCreateMSXml() {
CreateXml c_xml = new CreateXml();
c_xml.setIsShow(true);
/* 生成master数据源信息 */
c_xml.setDataSourceIndex(1);
c_xml.setDbSize("32");
c_xml.setJdbcUrl("jdbc:mysql://ip1:3306/um");
c_xml.setUser("${name}");
c_xml.setPassword("${password}");
c_xml.setDriverClass("${driverClass}");
c_xml.setInitialPoolSize("${initialPoolSize}");
c_xml.setMinPoolSize("${minPoolSize}");
c_xml.setMaxPoolSize("${maxPoolSize}");
c_xml.setMaxStatements("${maxStatements}");
c_xml.setMaxIdleTime("${maxIdleTime}");
System.out.println(c_xml.createDatasourceXml(new File("e:/masterDataSource-context.xml")));
/* 生成slave数据源信息 */
c_xml.setDataSourceIndex(33);
c_xml.setDbSize("32");
c_xml.setJdbcUrl("jdbc:mysql://ip2:3306/um");
c_xml.setUser("${name}");
c_xml.setPassword("${password}");
c_xml.setDriverClass("${driverClass}");
c_xml.setInitialPoolSize("${initialPoolSize}");
c_xml.setMinPoolSize("${minPoolSize}");
c_xml.setMaxPoolSize("${maxPoolSize}");
c_xml.setMaxStatements("${maxStatements}");
c_xml.setMaxIdleTime("${maxIdleTime}");
System.out.println(c_xml.createDatasourceXml(new File("e:/slaveDataSource-context.xml")));
}
十一、注意事项
一旦在程序中使用Kratos进行Sharding后,sql的编写一定要注意,否则将无法进行路由。sql规则如下所示:
1、暂时不支持分布式事物,因此无法保证事务一致性;
2、不支持多表查询,所有多表查询sql,务必全部打散为单条sql分开查询;
3、不建议使用一些数据库统计函数、Order by语句等;
4、sql的参数第一个必须是路由条件;
5、不支持数据库别名;
6、路由条件必须是整型;
7、采用连续分片时,子表后缀为符号"_"+4位整型,比如“tb_0001”——"tb_1024";
注意:
目前Kratos还处于1.2阶段,未来还有很长的路要走,现在笔者测试环境上已经在大规模的使用,后续生产环境上将会开始投放使用,因此如果各位在使用过程中有任何疑问,都可以通过企鹅群:150445731进行交流,或者获取Kratos的构件。