文章目标
本文旨在描述MMSEG中文分词算法核心设计概念,简要介绍中文分词实现方式(基于语法,基于词典,基于统计)。适用于对中文分词感兴趣的入门读者。
阅读目录
文章分为以下几个内容点,大家可以选择性阅读。
1. 分词必要性(即为什么要分词)
2. 中文分词基本实现方式(基于语法,基于词典,基于统计)
3. MMSEG分词算法设计实现
4. mmseg4j 与 solr 集成
5. 参阅文档
1. 分词必要性
什么是分词
分词是指将输入文本划分成若干个词汇单元的过程,如:
Hi tom, nice to meet you! -> [Hi,tom,nice,to,meet,you]
为什么要分词
在数据检索领域,为了实现数据快速检索,通常都对源数据建索引,索引的存储结构(如B树,B+树,Tire树等)通常都是基于关键字的,即关键字索引。关键字的提取就依赖于分词组件。当然,分词的应用并不局限于此,如智能交互,机器学习等领域都会用到。
2. 中文分词基本实现方式
由于中文语法表达有别于其它语系(如英文可用空格识别词汇),造就了中文词汇识别的特殊性。对中文分词的实现方式,大致可分为以下几类
基于语法规则的分词(主谓宾定状补,名词,动词,形容词等)
利用句法,语义进行词性标注,以解决歧义分词。由于语法组合复杂,词性难以规整,在当前阶段,分词效果并不理想。
基于词典分词
将输入文本逐一与词典匹配(正向/逆向),匹配成功的词将被筛选出来。实现简单高效,但对词典依赖性强。
基于统计的分词
词是由语素单元组成,相邻N个字在资料库中出现频率越高,成词机率越大,所以这种方式是具备语言学习能力的。但需要完备的资料库做词频统计,实践中对歧义分词还需要自定义词典做匹配,门槛较高,实现复杂。
3. MMSEG分词算法设计实现
MMSEG是一种基于词典文件的分词算法,算法核心有两点:匹配算法(Matching algorithm)与歧义消除规则(Ambiguity resolution rules)。
3.1 匹配算法
匹配算法即用输入文本与词典文件内容做匹配,相等的词将被筛选出来。匹配算法分为两种模式,不同模式下的分词算法会有不同的分词效果:
- Simple模式:
匹配所有以Cn为首且在词典中出现的词。比如“南京市长”,假设n=1,则可能出现(依赖词典)的结果:[南京市长] => [南京, 南京市, 南京市长],由此选出了n=1时可能出现的词,之后n++ 直到n=4为止。
- Complex模式:
匹配所有以Cn为首的三个词的词组(chunk),如“研究生命起源”,假设n=1,则可能出现(依赖词典)的结果:[研究生命起源] => [研_究_生],[研究_生_命],[研_究生_命]
从前面的结果可以看到,经过匹配算法,有可能出现若干以Cn为首的词,这种现象称之为分割性歧义(segmentation ambiguities)。到底应该选择哪一个呢,这需要借助歧义消除规则完成歧义消除。
3.2 歧义消除规则
MMSEG歧义消除规则有四个,其中Simple模式使用规则一(R1)就可以完成歧义消除任务。
- R1 最大匹配(Maximum matching):
Simple模式:
选择长度最大的词,比如:[南京市长] => [南京, 南京市, 南京市长],则选择长度为4的[南京市长]。
Complex模式:
选择词组长度最大的chunk,比如:[研究生命起源] => [研_究_生],[研究_生_命],[研_究生_命],则选择长度为4的 [研究_生_命] 和 [研_究生_命] 。
经过R1,Simple模式已经完成了C1[南]的词匹配,但Complex模式还有两个结果,所以还需要借助 R2 完成歧义消除。
- R2 最大平均语句长度(Largest average word length):
经过R1如果剩余的chunk超过一个,则选择平均语句长度最大的词,其中,
平均词长=词组总字数/词语数量,比如:
chunk1: [生活_水_平] = 4 / 3 = 1.33
chunk2: [生活_水平_] = 4 / 2 = 2 (二元组)
这时,chunk2将会被选出。
- R3 最小语句长度变化率(Smallest variance of word lengths)
经过R1,R2过滤后,可能还存在多个歧义结果,比如:
chunk1: 研究_生命_起源
chunk2: 研究生_命_起源
这时会选择 chunk1 中的“研究”, 这是基于语言长度均匀分布(evenly distributed)规律推测出来的,计算如下(标准差):
chunk1 = sqrt(((2-2)^2 + (2-2)^2 + (2-2)^2)/3) = 0
chunk2 = sqrt(((3-2)^2 + (1-2)^2 + (2-2)^2)/3) = 0.816
- R4 最大单字语素自由度之和(Largest sum of degree of morphemic freedom of one-character words)
如果经过R3还有多个结果,则需要R4规则完成歧义消除了。比如:
chunk1. 设施_和服_务
chunk2. 设施_和_服务
以上两个chunk拥有相同的chunk长度(R1),相同的平均语句长度(R2)以及变化率(R3), 如何分辨哪个才是正确的呢?
我们注意到这里都存在着单个字的组,而在中文用语中,不同的单字应用频率是不一样的。比如:[和]和[莪],显然单字带[和]的成词概率更大。语素自由度可由数学表达式log(frequency)计算,表示该词(one-character words)的词频对数, 自由度之和最大的则被选出: 如上例,
假设chunk1中[务]的频率 fq=5, chunk2中[和]的频率 fq=10,
则 sum_degree(chunk1)=log(5) < sum_degree(chunk2)=log(10), 所以选择chunk2。
More: mmseg4j已经提供了一个单字词频统计文件 chars.dic。
4. mmseg4j与solr集成
mmseg4j是基于MMSEG分词算法的Java实现,可以从以下地址获得:https://github.com/chenlb/mmseg4j-solr。
Note : 我这里的mmseg4j版本是 2.3.0,solr版本是 5.3.0。
安装步骤:
1. 将mmseg4j-core-1.10.0.jar,mmseg4j-solr-2.3.0.jar放到solr目录server\solr-webapp\webapp\WEB-INF\lib 下。
2. 修改schema.xml,添加mmseg支持
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/> </analyzer> </fieldtype>
重启solr服务就可以使用mmseg分词了:
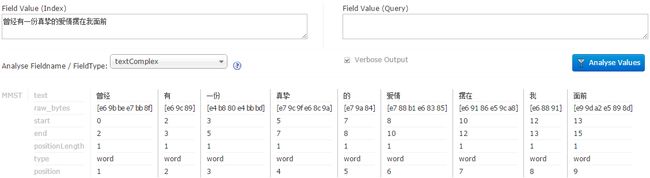
5. 参阅文档
mmseg作者: http://technology.chtsai.org/mmseg
A-Not-A Question:https ://en.wikipedia.org/wiki/A-not-A_question
http://www.360doc.com/content/13/0217/15/11619026_266141425.shtml