周末有空翻译了:http://redis.io/topics/lru-cache#maxmemory-configuration-directive
具体如下:
当用Redis作为一个LRU存储时,有些时候是比较方便的,在你增添新的数据时会自动驱逐旧的数据。这种行为在开发者论坛是非常有名的,因为这是流行的memcached系统的默认行为。
LRU实际上只是支持驱逐的方式之一。这页包含更多一般的Redis maxmemory指令的话题用于限制内存使用到一个定额,同时它也深入的涵盖了Redis所使用的LRU算法,实际上是精确LRU的近似值。
一、Maxmemory设置指令
Maxmemory设置指令用于配置Redis的数据集使用指定量的内存。可以用redis conf.file设置指令,或者可以在稍晚的时候在运行时间用config set命令。
例如,为了设置内存局限于100百万字节,下列指令可在redis.conf file内使用。设置maxmemory到零使得没有内存限制。这是64位系统的默认行为,而32位系统使用3GB内隐记忆极限。
maxmemory 100mb
当达到指定量的内存后,就可以选择不同的行为,称为策略。Redis可以返回错误的指令,导致使用更多的内存,或者为了每次增加新的数据后返回指定的内存,它可以驱逐一些旧的数据。
二、驱逐策略
当到达maxmemory极限时,使用maxmemory-策略配置指令来执行具体的Redis动作。
以下策略可以使用:
1、noeviction:达到内存限额后返回错误,客户尝试可以导致更多内存使用的命令(大部分写命令,但DEL和一些例外)
2、allkeys-lru:为了给新增加的数据腾出空间,驱逐键先试图移除一部分最近使用较少的(LRC)。
3、volatile-lru:为了给新增加的数据腾出空间,驱逐键先试图移除一部分最近使用较少的(LRC),但只限于过期设置键。
4、allkeys-random: 为了给新增加的数据腾出空间,驱逐任意键。
5、volatile-random: 为了给新增加的数据腾出空间,驱逐任意键,但只限于有过期设置的驱逐键。
6、volatile-ttl: 为了给新增加的数据腾出空间,驱逐键只有秘钥过期设置,并且首先尝试缩短存活时间的驱逐键。
如果没有秘钥去驱逐匹配先决条件,策略volatile-lru, volatile-random 和volatile-ttl行为很像noeviction。
那么根据你应用的访问模式选择正确的驱逐策略是很重要的。然而在应用运行时你可以在运行时间重新设置策略,并且监控缓存缺失的数量并为了调整你的设置点击Redis信息输出。
三、近似LRU算法
Redis的LRU算法不是准确的实现。也就是说Redis没有为逐出选择 最好的候选人 ,也就是没有选择过去最后被访问离现在最久的。反而 是去执行一个 近似LRU的算法,通过抽样少量的key,并且逐出抽样中最后被访问离现在最久的key(最老的访问时间)。
在Redis 3.0(目前的测试版),算法被改进了,使用了一个逐出最佳候选池。改进了算法的性能,使它更加近似真正LRU算法。
算法中,关于逐出检测的样品数量,你可以自己去调整。配置参数是:
maxmemory-samples 5
Redis没有使用真正实现LRU算是的原因是,因为消耗更多的内存。然而对于使用Redis的应用来说,事实上是等价的。下面是Redis的LRU算法和真正LRU算法的比较:
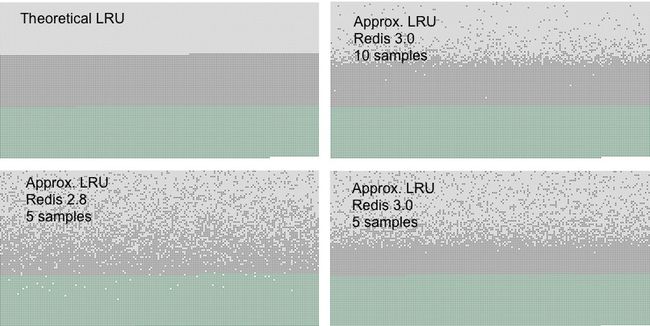
给出配置数量的key生成上面的图表。key从第一行到最后一行被访问,那么第一个key是LRU算法中最好的逐出候选者。之后有50%的key被添加,那么一半的旧key被逐出。
在上图中你可以看见3个明显的区别:
1、浅灰色带是被逐出的对象。
2、灰色带是没有被逐出的对象。
3、绿色带是被添加的对象。
LRU理论实现是在所有的旧key中前一半被逐出。Redis使用的是近似过期的key被逐出。
如你所见,3.0的工作比2.8更好,然而在2.8版本中,大多数最新访问对象的仍然保留。在3.0使用样品为10 时,性能非常接近理论上的LRU算法。
注意:LRU仅仅是一个预测模式,给出的key很可能在未来被访问。此外,如果你的数据访问模式类似于幂律(线性的),大多数key都可能被访问那么这个LRU算法的处理就是非常好的。
在实战中 ,我们发现使用幂律(线性的)的访问模式,在真正的LRU算法和Redis的LRU算法之间差异很小或者不存在差异。
你可以提升样品大小配置到10,它将接近真正的LRU算法,并且有不同错过率,但是要消耗更多的CPU。
在调试时使用不同的样品大小去调试非常简单,使用命令CONFIG SET maxmemory-samples <count> 实现。