MySQL 数据库双向同步复制
MySQL 复制问题的最后一篇,关于双向同步复制架构设计的一些设计要点与制约。
问题和制约
数据库的双主双写并双向同步场景,主要考虑数据完整性、一致性和避免冲突。对于同一个库,同一张表,同一个记录中的同一字段的两地变更,会引发数据一致性判断冲突,尽可能通过业务场景设计规避。双主双写并同步复制可能引发主键冲突,需避免使用数据库自增类主键方案。另外,双向同步潜在可能引发循环同步的问题,需要做回环控制。
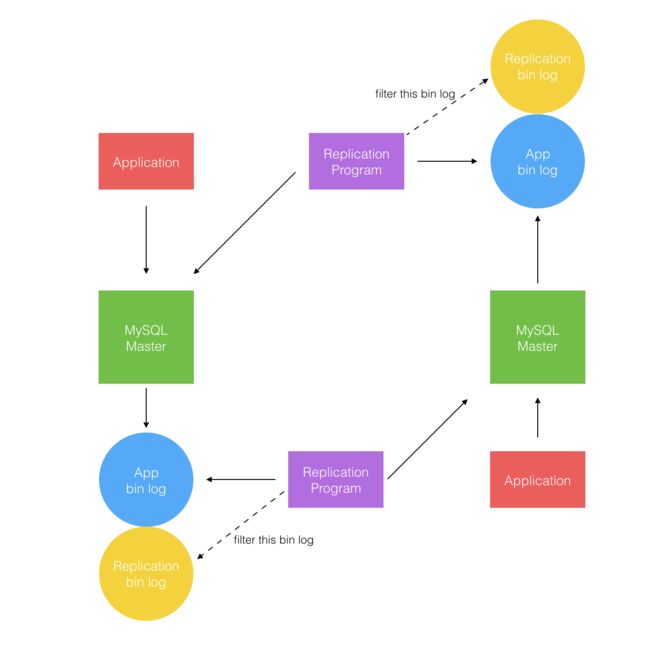
如上图所示,复制程序写入时也会产生 binlog,如何识别由复制程序产生的 binlog 并将其过滤掉是避免循环复制的关键。
原生 Dual Master 方案
MySQL 自身支持双主配置,但并没有去解决潜在的主键和双写带来的数据一致性冲突。对于双向同步潜在的循环复制问题,MySQL 在 binlog 中记录了当前 MySQL 的 server-id。一旦有了 server-id 的值之后,MySQL 就很容易判断某个变更是从哪一个 Server 最初产生的,所以就很容易避免出现循环复制的情况。而且,还可以配置不打开记录 slave 的 binlog 选项(--log-slave-update),MySQL 就不会记录复制过程中的变更到 binlog 中,就更不用担心可能会出现循环复制的情形了。
从 MySQL 自身的方案中可以找到切入点,就是如果能在 binlog 中打上标记,就有办法判断哪些 binlog 是复制产生的,并将其过滤。使用 MySQL 的方案则过于耦合 MySQL 的配置,在大规模部署的线上生产系统中容易因为 MySQL 配置错误导致问题。
自定义标记 SQL 方案
为了和 MySQL 配置解耦合,可以考虑一种通用的标记 SQL 方案。简单来说,就是在同步复制入库时插入特殊的标记 SQL 语句来标记这是来自复制程序的变更,这个标记 SQL 会进入 binlog 中。而在复制程序读取时,通过识别这个标记 SQL 来过滤判断。
binlog 中存储了对数据产生变更影响的的 SQL 语句,这些 SQL 语句组成了一段一段的事务,如下图所示:
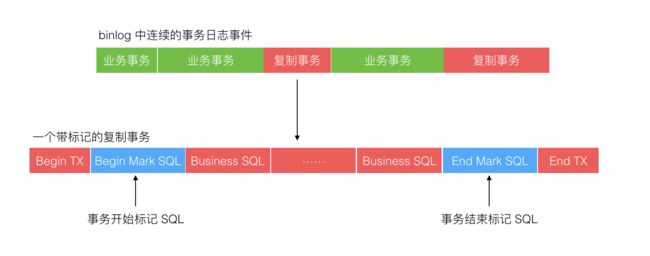
绿色区是业务运行产生的正常事务,红色区是复制程序写入产生的事务,其中蓝色块是标记 SQL。标记 SQL 分别在事务开始后与事务结束前,标记 SQL 更新一张预定义的区别于业务表的标记表。那么每次复制程序去批量读取 binlog 内容时,可能存在下面 5 种情况,如下图所示:
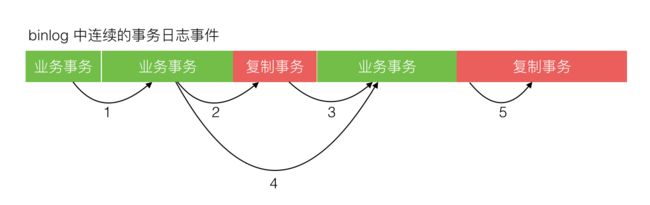
- 批量读取范围全落在绿色区内。
- 批量读取范围起点落在绿色区,终点落在红色区。
- 批量读取范围起点落在红色区,终点落在绿色区。
- 批量读取范围起点和终点都在绿色区,但中间涵盖了一段红色区。
- 批量读取范围全落在红色区。
如上只有第 5 种情况,一个事务被拆成 3 段来同步。中间一段因为没有事务头和尾的标记,复制程序读取时将无法判断,导致循环同步,需要避免。通过把复制程序的批量读取范围固定设置为至少大于或等于写入的事务长度范围,避免了第 5 种情况。复制程序批量读取 binlog 日志事件时,通过标记 SQL 来过滤,避免了循环复制,实现了回环控制。
总结
本文考虑了在 MySQL 双主写入场景下双向同步复制的一些设计要点和制约。以原生实现为参考,给出了一种自定义实现方式的设计要点分析。而对于同库同表同记录同字段的同时两地变更,则必然引发数据一致性冲突,在复制同步层面无法区分哪边的更新为准。通常会考虑以最后时间戳来恢复到一致状态,但时间戳实际也会产生误差,此类场景不多见最好还是尽可能还是在业务场景设计上来规避。
参考
[1] MySQL Internals Manual. Replication.
[2] MySQL Internals Manual. The Binary Log. [3] in355hz. 数据库 ACID 的实现.
[4] jb51. MySQL 对 binlog 的处理说明.
[5] repls. 浅析 innodb_support_xa 与 innodb_flush_log_at_trx_commit.
[6] 68idc. MySQL 5.6 之 DBA 与开发者指南.
[7] csdn. 高性能 MySQL 主从架构的复制原理及配置详解.
[8] agapple. Otter 双向回环控制.
下面是我的微信公众号 「瞬息之间」,除了写技术的文章、还有产品、行业和人生的思考,希望能和更多走在这条路上同行者交流。
