冒泡排序深入具体解释
冒泡排序的基本思想
冒泡排序(Bubble Sort)是一种交换排序,它的基本思想是:两两比較相邻记录的keyword,假设凡需则交换。直到没有凡需的记录位置。
一、冒泡排序简单实现(0基础版)
#include "stdafx.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int Status;
#define MAXSIZE 10000 /* 用于要排序数组个数最大值。可依据须要改动 */
typedef struct
{
int r[MAXSIZE+1]; /* 用于存储要排序数组,r[0]用作哨兵或暂时变量 */
int length; /* 用于记录顺序表的长度 */
}SqList;
void print(SqList L)
{
int i;
for(i=1;i<L.length;i++)
printf("%d,",L.r[i]);
printf("%d",L.r[i]);
printf("\n");
}
/* 交换L中数组r的下标为i和j的值 */
void swap(SqList *L,int i,int j)
{
int temp=L->r[i];
L->r[i]=L->r[j];
L->r[j]=temp;
}
/* 对顺序表L作交换排序(冒泡排序0基础版) */
void BubbleSort0(SqList *L)
{
int i,j;
for(i=1;i<L->length;i++)
{
for(j=i+1;j<=L->length;j++)
{
if(L->r[i]>L->r[j])
{
swap(L,i,j);/* 交换L->r[i]与L->r[j]的值 */
}
}
}
}
#define N 9
int _tmain(int argc, _TCHAR* argv[])
{
int d[N]={9,1,5,8,3,7,4,6,2};
SqList L0;
int i;
for(i=0;i<N;i++)
L0.r[i+1]=d[i];
L0.length=N;
printf("排序前:\n");
print(L0);
BubbleSort0(&L0);
printf("排序后:\n");
print(L0);
getchar();
return 0;
}执行结果:
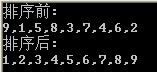
排序思想:依次实现前一个和后一个的比較,每次仅仅将最小的移至最高,其他元素位置差点儿不变。
缺点:能够看出,在排好1和2的位置后,其余keyword的排序没有帮助(数字3反而还被换到了最后一位)。也就是说这个算法的效率是很低的。
二:正宗的冒泡排序/* 对顺序表L作冒泡排序 */
void BubbleSort(SqList *L)
{
int i,j;
for(i=1;i<L->length;i++)
{
for(j=L->length-1;j>=i;j--) /* 注意j是从后往前循环 */
{
if(L->r[j]>L->r[j+1]) /* 若前者大于后者(注意这里与上一算法的差异)*/
{
swap(L,j,j+1);/* 交换L->r[j]与L->r[j+1]的值 */
}
}
}
}

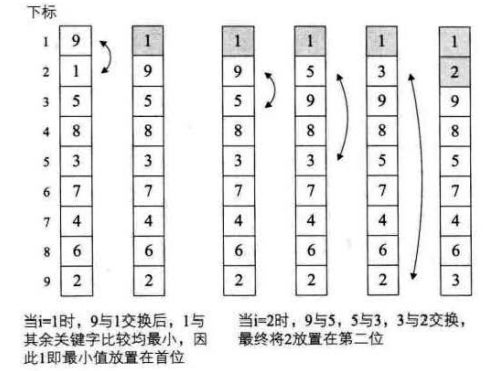
代码分析:在不断循环的过程中,除了将keyword1放到第一的位置,我们还将keyword2从第九位置提到了第三的位置,显然这一算法比前面的要有进步,在上十万条数据的排序过程中,这样的差异会体现出来。
图中较小的数字如同气泡般慢慢浮到上面。因此就将此算法命名为冒泡算法。
长处总结:1)将最小keyword1提至最高; 2)将第一次比較过的keyword2放在合适的位置附近。
三:冒泡排序升级版/* 对顺序表L作改进冒泡算法 */
void BubbleSort2(SqList *L)
{
int i,j;
Status flag=TRUE; /* flag用来作为标记 */
for(i=1;i<L->length && flag;i++) /* 若flag为true说明有过数据交换,否则停止循环 */
{
flag=FALSE; /* 初始为False */
for(j=L->length-1;j>=i;j--)
{
if(L->r[j]>L->r[j+1])
{
swap(L,j,j+1); /* 交换L->r[j]与L->r[j+1]的值 */
flag=TRUE; /* 假设有数据交换。则flag为true */
}
}
}
}
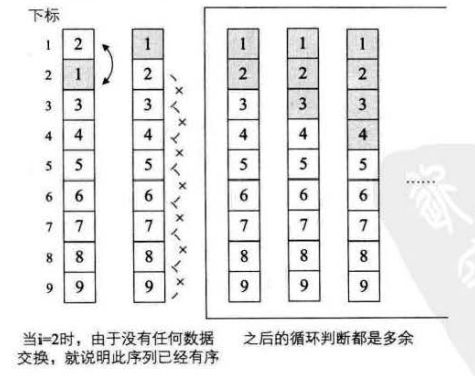
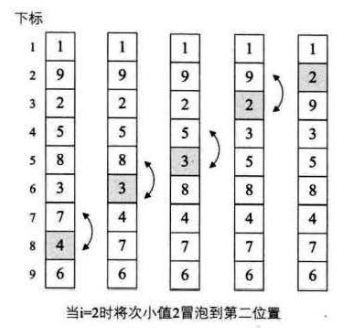
除了第一和第二的keyword须要交换外。别的都已经是正常的顺序。当i=1时。交换了2和1,此时序列已经有序。可是算法仍然不依不饶地将i=2到9以及每一个循环中的循环都运行了一遍。虽然并没有交换数据,可是之后的大量比較还是大大地多余了。
长处:减去在排序k次后,表已经有序时,兴许的无需比較。
4、冒泡排序复杂度分析
分析它的时间复杂度。当最好的情况,也就是要排序的表本身就是有序的,依据最后改进的代码。进行n-1次的比較,间复杂度为o(n)。当最坏的情况,待排序表是逆序,此时须要比較总的次数为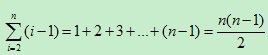 ,并作等数级的记录移动。因此。总的时间复杂度为o(n2)。
,并作等数级的记录移动。因此。总的时间复杂度为o(n2)。