AQL Subset Compiler:手把手教你如何写一个完整的编译器
项目地址:https://github.com/laiy/Awesome-Complier。
转载请注明出处。
前言
这是学校里编译原理课程的大作业,此Project十分适合编译原理的学习,让基本不听课的我理解了一个编译器的编写过程。
所以忍不住想分享一下。
什么是AQL?
全称: Annotation Query Language
用于Text Analytics。
可以从非结构化或半结构化的文本中提取结构化信息的语言。
语法与SQL类似。
什么是AQL Subset?
AQL语法复杂,功能强大,实现难度较高,作为学习用,我们选择实现AQL的部分语法功能达到学习编译器编写的效果。
AQL Subset具有AQL的主要特点。
主要实现以下功能:
1. 通过regex来生成一个view。
2. 通过pattern来拼接多个view或者正则表达式处理的结果。
3. 通过select来选择已有view的列生成新的view。
4. 打印view的结果。
例子:PerLoc.aql
1 create view Cap as 2 extract regex /[A-Z][a-z]*/ 3 on D.text as Cap 4 from Document D; 5 6 create view Stt as 7 extract regex /Washington|Georgia|Virginia/ 8 on D.text 9 return group 0 as Stt 10 from Document D; 11 12 create view Loc as 13 extract pattern (<C.Cap>) /,/ (<S.Stt>) 14 return group 0 as Loc 15 and group 1 as Cap 16 and group 2 as Stt 17 from Cap C, Stt S; 18 19 create view Per as 20 extract regex /[A-Z][a-z]*/ 21 on D.text 22 return group 0 as Per 23 from Document D; 24 25 create view PerLoc as 26 extract pattern (<P.Per>) <Token>{1,2} (<L.Loc>) 27 return group 0 as PerLoc 28 and group 1 as Per 29 and group 2 as Loc 30 from Per P, Loc L; 31 32 create view PerLocOnly as 33 select PL.PerLoc as PerLoc 34 from PerLoc PL; 35 36 output view Cap; 37 output view Stt; 38 output view Loc; 39 output view Per; 40 output view PerLoc; 41 output view PerLocOnly;
假设处理的文本内容是:
Carter from Plains, Georgia, Washington from Westmoreland, Virginia
那么输出结果为:
Processing ../dataset/perloc/PerLoc.input
View: Cap
+----------------------+
| Cap |
+----------------------+
| Carter:(0,6) |
| Plains:(12,18) |
| Georgia:(20,27) |
| Washington:(29,39) |
| Westmoreland:(45,57) |
| Virginia:(59,67) |
+----------------------+
6 rows in set
View: Stt
+--------------------+
| Stt |
+--------------------+
| Georgia:(20,27) |
| Washington:(29,39) |
| Virginia:(59,67) |
+--------------------+
3 rows in set
View: Loc
+--------------------------------+----------------------+--------------------+
| Loc | Cap | Stt |
+--------------------------------+----------------------+--------------------+
| Plains, Georgia:(12,27) | Plains:(12,18) | Georgia:(20,27) |
| Georgia, Washington:(20,39) | Georgia:(20,27) | Washington:(29,39) |
| Westmoreland, Virginia:(45,67) | Westmoreland:(45,57) | Virginia:(59,67) |
+--------------------------------+----------------------+--------------------+
3 rows in set
View: Per
+----------------------+
| Per |
+----------------------+
| Carter:(0,6) |
| Plains:(12,18) |
| Georgia:(20,27) |
| Washington:(29,39) |
| Westmoreland:(45,57) |
| Virginia:(59,67) |
+----------------------+
6 rows in set
View: PerLoc
+------------------------------------------------+--------------------+--------------------------------+
| PerLoc | Per | Loc |
+------------------------------------------------+--------------------+--------------------------------+
| Carter from Plains, Georgia:(0,27) | Carter:(0,6) | Plains, Georgia:(12,27) |
| Plains, Georgia, Washington:(12,39) | Plains:(12,18) | Georgia, Washington:(20,39) |
| Washington from Westmoreland, Virginia:(29,67) | Washington:(29,39) | Westmoreland, Virginia:(45,67) |
+------------------------------------------------+--------------------+--------------------------------+
3 rows in set
View: PerLocOnly
+------------------------------------------------+
| PerLoc |
+------------------------------------------------+
| Carter from Plains, Georgia:(0,27) |
| Plains, Georgia, Washington:(12,39) |
| Washington from Westmoreland, Virginia:(29,67) |
+------------------------------------------------+
3 rows in set
很容易看懂,Cap这个view提取了大写字母开头的英文单词,Stt提取了美国洲名的单词,Loc对Cap和Stt进行拼接,按照中间只隔了一个逗号,且后一个单词为州名为一个地名的规则得到地名。
其中group 0指的是匹配的结果,group 1, 2, 3...指的是匹配规则中括号的内容。
然后Per人名假设和Cap一样,那么PerLoc则是拼接了Per和Loc,指定中间间隔1到2个Token(以字母或者数字组成的无符号分隔的字符串,或者单纯的特殊符号,不包含空白符。)。
最后PerLocOnly则是从view PerLoc中select了一个列出来。
其中配个匹配后面的(x, y)指的是匹配的字符在原文中的位置,左闭右开。
然后output view xxx就是把提取出的view打印出来得到了以上的结果。
Language
aql_stmt → create_stmt ; | output_stmt ;
create_stmt → create view ID as view_stmt
view_stmt → select_stmt | extract_stmt
output_stmt → output view ID alias
alias → as ID | ε
elect_stmt → select select_list from from_list
select_list → select_item | select_list , select_item
select_item → ID . ID alias
from_list → from_item | from_list , from_item
from_item → ID ID
extract_stmt → extract extract_spec from from_list
extract_spec → regex_spec | pattern_spec
regex_spec → regex REG on column name_spec
column → ID . ID
name_spec → as ID | return group_spec
group_spec → single_group | group_spec and single_group
single_group → group NUM as ID
pattern_spec → pattern pattern_expr name_spec
pattern_expr → pattern_pkg | pattern_expr pattern_pkg
pattern_pkg → atom | atom { NUM , NUM } | pattern_group
atom→ < column > | < Token > | REG
pattern_group → ( pattern_expr )
以上为AQL Subset的文法,这是语法分析生成抽象语法树的规则。
从文法可以看出,所有文法左边的为非终结符,而其他的关键词为终结符(语法数的叶子节点)。
编译器结构

词法分析器(Lexer)
首先要把AQL语言源文件输入到词法分析器中,词法分析器的职责就是从一个字符串中提取出AQL语言的非终结符序列,然后这个非终结符序列作为输入提供给语法分析器解析生成抽象语法树。
那Lexer要做的事情就很清晰了,首先定义一个token(非终结符)的数据结构如下:
1 struct token { 2 std::string value; 3 Type type; 4 bool is_grouped; 5 token(std::string value, Type type) { 6 this->value = value; 7 this->type = type; 8 this->is_grouped = false; 9 } 10 bool operator==(const token &t) const { 11 return this->value == t.value && this->type == t.type; 12 } 13 };
value是匹配到的字符串,Type为token的类型,is_grouped是之后语法分析的时候匹配group用的,暂时不管。
然后根据AQL Subset的文法(上面的Language),可以得出非终结符的类型有如下:
typedef enum { CREATE, VIEW, AS, OUTPUT, SELECT, FROM, EXTRACT, REGEX, ON, RETURN, GROUP, AND, TOKEN, PATTERN, ID, DOT, REG, NUM, LESSTHAN, GREATERTHAN, LEFTBRACKET, RIGHTBRACKET, CURLYLEFTBRACKET, CURLYRIGHTBRACKET, SEMICOLON, COMMA, END, EMPTY } Type;
最后两个END和EMPTY也是方便语法分析用的,并不是一个真实的token类型。
然后定义一个Lexer类:
1 class Lexer { 2 public: 3 Lexer(char *file_path); 4 std::vector<token> get_tokens(); 5 private: 6 std::vector<token> tokens; 7 };
Lexer在构造函数的时候就把AQL源文件进行处理得到一组token存放在tokens这个vector里,然后提供get_tokens方便语法分析器调用获得到tokens。
具体实现细节我不会在这里讲述,感兴趣的可以回到顶部进入项目代码地址查看源代码。
语法分析器(Parser)
语法分析器做的就是利用词法分析出来的token序列,构建出一个抽象语法树(AST),然后传递给编译器后端执行(Lexer + Parser我们通常称为编译器的前端)。
编译器后端做的主要是根据语法树的结构,完成具体的执行逻辑。
这里需要注意!很多同学混淆不清的一个问题:这里所说的构建抽象语法树并不是在数据结构上去构建一颗树出来,这里的树的意思体现在函数的调用逻辑,举个例子,一个简单的DFS搜索,递归实现,这个搜索经常会呈现出一个树的逻辑结构。
然后根据文法(Language),我们可以定义一个Parser类:
1 class Parser { 2 public: 3 Parser(Lexer lexer, Tokenizer tokenizer, const char *output_file, const char *processing); 4 ~Parser(); 5 token scan(); 6 void match(std::string); 7 void error(std::string str); 8 void output_view(view v, token alias_name); 9 void program(); 10 void aql_stmt(); 11 void create_stmt(); 12 std::vector<col> view_stmt(); 13 void output_stmt(); 14 token alias(); 15 std::vector<col> select_stmt(); 16 std::vector<token> select_list(); 17 std::vector<token> select_item(); 18 std::vector<token> from_list(); 19 std::vector<token> from_item(); 20 std::vector<col> extract_stmt(); 21 std::vector<token> extract_spec(); 22 std::vector<token> regex_spec(); 23 std::vector<token> column(); 24 std::vector<token> name_spec(); 25 std::vector<token> group_spec(); 26 std::vector<token> single_group(); 27 std::vector<token> pattern_spec(); 28 std::vector<token> pattern_expr(); 29 std::vector<token> pattern_pkg(); 30 std::vector<token> atom(); 31 std::vector<token> pattern_group(); 32 inline col get_col(view v, std::string col_name); 33 inline view get_view(std::string view_name); 34 inline void print_line(view &v); 35 inline void print_col(view &v); 36 inline void print_span(view &v); 37 private: 38 std::vector<token> lexer_tokens; 39 int lexer_parser_pos; 40 token look; 41 std::vector<document_token> document_tokens; 42 std::vector<view> views; 43 FILE *output_file; 44 };
需要注意的是构造函数里的tokenizer并不是词法分析器,只是AQL需要处理的文本的分词器,作用和Lexer类似,因为在pattern匹配的时候需要用到<Token>的表示。
然后从树的根节点program()开始,不断的根据文法规则和look(预读的token,通过look我们可以唯一的定位到在一个非终结符节点下一步的函数调用)调用,然后利用函数的返回值传递必要的执行参数(我这里主要是以token的vector形式实现)。
这样描述可能有点抽象,看个具体的例子。
来看我们之前例子的第一个create语句:
create view Cap as extract regex /[A-Z][a-z]*/ on D.text as Cap from Document D;
我们根据向前看规则,可以得到如下抽象语法树:
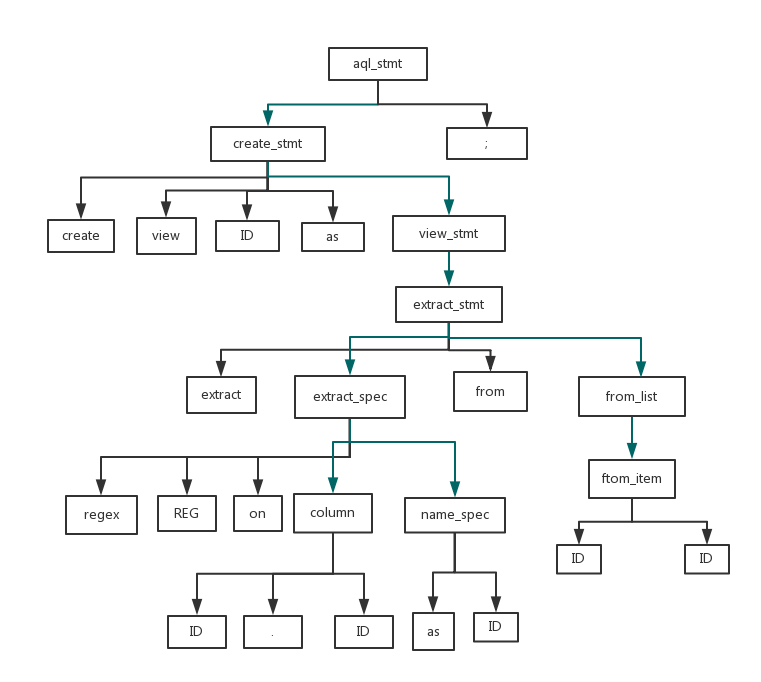
绿色的线表示函数调用,黑色表示终结符匹配。
来看预读的token是怎么帮助我们找到正确的函数调用的,以非终结符节点aql_stmt为例:
aql_stmt → create_stmt ; | output_stmt ;
aql_stmt可以推导出create_stmt+;或者output_stmt+;。
然后此时如果look.Type是CREATE的话其实就意味着应该调用create_stmt,如果是output_stmt的话此时预读的token类型应该是OUTPUT。
整体思路就是这样,我们分别把每个非终结符按照文法规则利用预读的look即可完成一个抽象语法树的结构(非终结符的节点箭头指向表示的是函数调用)。
编译器后端
我们在抽象语法树构造的过程中,在必要的节点返回程序执行需要的数据,然后后端做的事情就是利用抽象语法树提取出来的关键数据去执行AQL语言需要实现的逻辑。
而AQL Subset的后端逻辑其实只有4个:
1. 利用正则表达式创建一个view。
2. 利用pattern匹配创建一个view。
3. 利用select提取创建一个view。
4. 打印view。
按理说还应该抽象出一个执行类,提供方法,让Parser直接调用去执行的,由于这里后端逻辑挺简单的我就直接写在抽象语法树构造过程函数的内部了。
对应分别是:
1. extract_stmt的条件分支(Parser.cpp 213-229行)实现正则提取文本。
2. extract_stmt的条件分支(Parser.cpp 234-320行)实现pattern匹配提取文本。
3. select_stmt尾部实现select逻辑。
4. output_view函数实现打印逻辑。
5. view的创建逻辑实现在create_stmt尾部。
具体实现没什么好说的了,coding就是了。
完成之后可以自己玩各种有趣的文本处理,比如我从HTML文本中提取出所有meta的内容,又比如可以提取出HTML中所有的class, id等等....(结果可以参考dataset/html/*.output,提取的aql源文件为dataset/html.aql)。
一些体会
一个编译器的编写完全体现了自顶向下,逐步求精的分而治之的架构思想,其实具体coding对于大三的学生来说已经完全不是什么难事了,重要的是怎么把一个大的问题不断分治到能够被轻易解决的小的问题上来。
谢谢。
