python学习笔记三之上(基础篇)
深浅copy以及赋值
对于字符串和数字而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
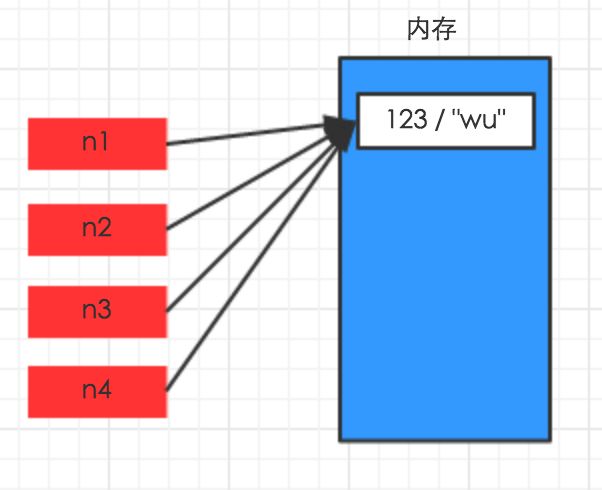
import copy n1 = 10242048 #n1 = 'hahahaha' #赋值
n2 = n1
#浅copy n3 = copy.copy(n1) #深copy
n4 = copy.deepcopy(n1)
print(id(i),id(i1)) #打印内存地址
5787536 5787536
print(id(i),id(i2))
5787536 5787536
print(id(i),id(i3))
5787536 5787536
字典,列表,元组等进行赋值,深浅copy时,它们的内存地址变化是不一样的。
在赋值操作时,仅仅只是做了一个别名而已。因为字典的存储空间比字符串和数字要大很多,当你赋值给另一个变量的时候,按原来的方式copy一份独立的数据会浪费很多资源,
效率还会很低。
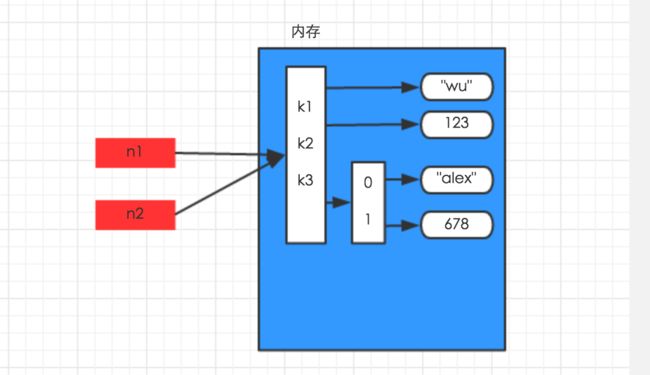
n1 = {'k1':1024,'k2':'koka','k3':['haha','xixi','hehe','houhou']}
n2 = n1
print(n2)
print(n1)
{'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k2': 'koka', 'k1': 1024}
{'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k2': 'koka', 'k1': 1024}
n1['k1']=2048
print(n2)
print(n1)
{'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k2': 'koka', 'k1': 2048}
{'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k2': 'koka', 'k1': 2048}
n1['k3'][0]='ajx'
print(n2)
print(n1)
{'k3': ['ajx', 'xixi', 'hehe', 'houhou'], 'k2': 'koka', 'k1': 2048}
{'k3': ['ajx', 'xixi', 'hehe', 'houhou'], 'k2': 'koka', 'k1': 2048}
#从结果可以发现n1和n2的值同时改变,因为他们只是两个不同的别名而已。
在浅copy操作时,只是copy了字典下的第一层数据,对于更深层次的数据还是原来的。
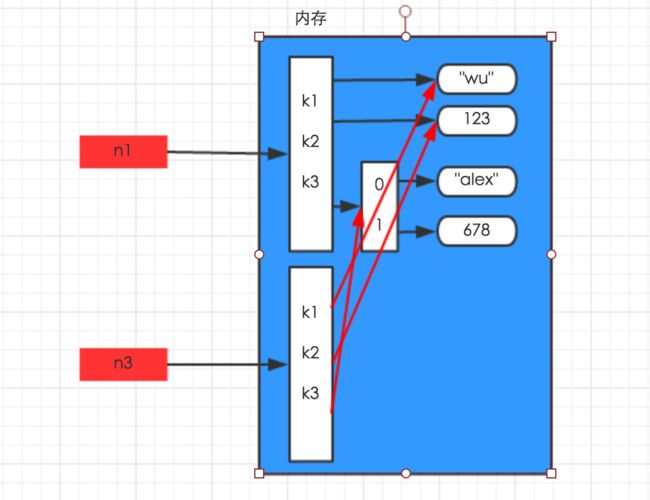
n3 =copy.copy(n1) print(n3) print(n1) {'k1': 1024, 'k2': 'koka', 'k3': ['haha', 'xixi', 'hehe', 'houhou']} {'k1': 1024, 'k2': 'koka', 'k3': ['haha', 'xixi', 'hehe', 'houhou']} n1['k2'] = 'dada' print(n3) print(n1) {'k1': 1024, 'k2': 'koka', 'k3': ['haha', 'xixi', 'hehe', 'houhou']} {'k1': 1024, 'k2': 'dada', 'k3': ['haha', 'xixi', 'hehe', 'houhou']} n1['k3'][2] = 'heihei' print(n3) print(n1) {'k1': 1024, 'k2': 'koka', 'k3': ['haha', 'xixi', 'heihei', 'houhou']} {'k1': 1024, 'k2': 'dada', 'k3': ['haha', 'xixi', 'heihei', 'houhou']}
#可以看出第一层的字符串数据改变了,而后面的列表还是同一个。
在深度copy操作时,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
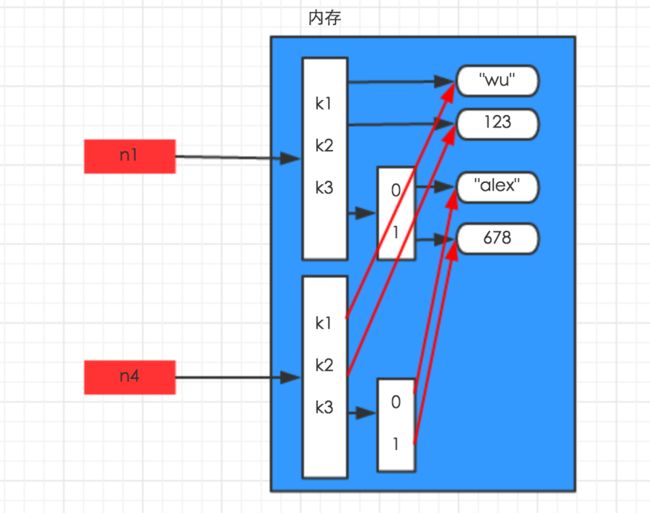
n4 = copy.deepcopy(n1)
print(n4)
print(n1)
{'k2': 'koka', 'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k1': 1024}
{'k2': 'koka', 'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k1': 1024}
n1['k1'] = 8192
n4['k2'] = 'akok'
print(n4)
print(n1)
{'k2': 'akok', 'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k1': 1024}
{'k2': 'koka', 'k3': ['haha', 'xixi', 'hehe', 'houhou'], 'k1': 8192}
n1['k3'][0] = "lolo"
n4['k3'][1] = "lala"
print(n4)
print(n1)
{'k2': 'akok', 'k3': ['lala', 'xixi', 'hehe', 'houhou'], 'k1': 1024}
{'k2': 'koka', 'k3': ['lolo', 'xixi', 'hehe', 'houhou'], 'k1': 8192}
#真正的完全copy一份数据。
数据结构扩展
Collection系列
1、计数器(counter)
Counter是对字典类型的补充,用于追踪值的出现次数。
ps:具备字典的所有功能 + 自己的功能
c1 = collections.Counter('aabc') c2 = collections.Counter(('a','b','c','a')) print(c1) Counter({'a': 2, 'b': 1, 'c': 1}) print(c2) Counter({'a': 2, 'b': 1, 'c': 1}) #类似于c1 + c2 c1.update(c2) print(c1) Counter({'a': 4, 'b': 2, 'c': 2}) c1.subtract('a') print(c1) Counter({'a': 3, 'b': 2, 'c': 2}) #列出前几位 print(c1.most_common(2)) [('a', 3), ('b', 2)] for i in c2.elements(): #elements返回元素迭代器 print(i) b a a c
2、有序字典(orderedDict )
有序字典跟字典使用没有区别,记录key的存储顺序
o1 = collections.OrderedDict() o1['k1'] = 1 o1['k2'] = 2 o1['k3'] = 3 for i,k in o1.items(): print(i,k) k1 1 k2 2 k3 3 products = collections.OrderedDict() products = { 0:['nectarine',20], 1:['orange',15], 2:['raspberry',10], 3:['cherry',25], 4:['Apple',12], 5:['Banana',5] } format = '%-*s%*s%*s' for i,k in products.items(): print(format %(5,i,15,k[0],10,k[1])) 0 nectarine 20 1 orange 15 2 raspberry 10 3 cherry 25 4 Apple 12 5 Banana 5
3、默认字典(defaultdict)
defaultdict是对字典的类型的补充,他默认给字典的值设置了一个类型。
values = [11, 22, 33,44,55,66,77,88,99] newvalues = collections.defaultdict(list) for i in values: if i >= 6: newvalues['k1'].append(i) else: newvalues['k2'].append(i) print(newvalues)
4、可命名元组(namedtuple)
根据nametuple可以创建一个包含tuple所有功能以及其他功能的类型。
可命名元组:
1.创建类
2.使用类创建对象
3.使用对象
4.用于坐标
——————
普通元组:
1.直接使用类创建对象
2.使用对象
#old = tuple(1,2) <==> old = (1,2)
#创建一个扩展tuple的类,Mytuple
import collections
Mytuple = collections.namedtuple('Mytuple',['x','y']) new = Mytuple(1,2) print(new)
Mytuple(x=1, y=2
5、双向队列(deque)
在需要按照元素增加的顺序来移除元素时非常有用,双向队列可以通过可迭代对象来创建。
q = collections.deque(range(5)) q.append(5) q.appendleft(6) print(q) deque([6, 0, 1, 2, 3, 4, 5]) q.rotate(3) print(q) deque([2, 3, 4, 6, 0, 1]) q.rotate(-1) print(q) deque([3, 4, 6, 0, 1, 2]) q.remove(5) print(q) deque([4, 6, 0, 1, 2, 3]) ret1 = q.pop() print(ret1) 3 ret2 = q.popleft() print(ret2) 4 q.extend([7,8,9]) print(q) deque([6, 0, 1, 2, 7, 8, 9]) q.extendleft([10,11,12]) print(q) deque([12, 11, 10, 6, 0, 1, 2, 7, 8, 9])
set 集合
a = set([1,2,3,4]) b = set([3,4,5,6,7]) a.update(b) print(a) a.add(9) print(a) #a.clear() c = a.copy() print(c) #并集 | result1 = a.union(b) result2 = a | b print(result1,result2) #交集 & result = a.intersection(b) print(result) result = a & b print(result) #子集 >= c = set([2,3]) result = c.issubset(a) print(result) #父集 <= result = a.issuperset(c) print(result) #取差集 - result1 = a.difference(b) result2 = a - b print(result1,result2) #异或差集 & result1 = a ^ b result2 = a.symmetric_difference(b) print(result1,result2) #删除 # remove(If the element is not a member, raise a KeyError.) # discard (If the element is not a member, do nothing.) #pop (Remove and return an arbitrary set element.Raises KeyError if the set is empty.) a.remove(1) print(a) #a.discard() print(a) a.pop() print(a)
集合练习:
找出下面字典中不同的键,同样的更新,现在没有的删除,现在有的更新
old_dict = {
"#1":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
"#2":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
"#3":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 }
}
new_dict = {
"#1":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 800 },
"#3":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
"#4":{ 'hostname':'c2', 'cpu_count': 2, 'mem_capicity': 80 }
}
old_set =set(old_dict.keys()) new_set = set(new_dict.keys()) update_set = old_set.intersection(new_set) del_list = list(old_set.difference(update_set)) add_list = list(new_set.difference(update_set)) print(list(update_set),add_list,del_list)
堆(heap)
它是一种优先队列。它能够以任意顺序增加对象,并且能在任何时间(可能在增加对象的同时)找到(也可能是移除)最小的元素,它比列表的min方法更有效率。
相关函数:
heappush(x) 将X入堆
heappop(heap) 将堆中最小的元素弹出
heapify(heap) 将堆中属性强制应用到任意一个列表,如果没有使用haeppush创建堆,可以使用heapif(heap)
heapreplace(heap,x) 将堆中最小元素弹出,同时将x入堆
nlargest(n,iter) 返回iter中第n大的元素
nsmallest(n,iter) 返回iter中第n小的元素
from heapq import * from random import shuffle seq = [11,22,33,44,55] shuffle(seq) heap = [] for i in seq: heappush(heap,i) print(heap) [11, 22, 44, 55, 33] heappush(heap,10) print(heap) [10, 22, 11, 55, 33, 44]
元素的顺序并不像看起来那么随意,算法:位于i位置上的元素总比1//2位置处的元素大(反过来说就是i位置的元素总比2*以及2*i+1位置处的元素小)
print(heappop(heap)) 10 print(heappop(heap)) 11 print(heappop(heap)) 22
一般来说都是在索引0处的元素,并且会确保剩余元素中最小的那个占据这个位置
li = [1,2,5,4,67,27,2] heapify(li) print(li) heapreplace(li,0.5) print(li)