我们先来回顾下,一个基本的搜索流程是怎么完成的
1,得到一个索引目录Directory(可能基于内存的或者磁盘的)。
2,得到一个DirectoryReader。
3,实例化查询组件IndexSearcher。
4,检索得到TopDoc查询结果集
5,遍历ScoresDocs处理结果
我们看下这个检索的流程,大概可以分这5步,前1,2,3算是准备工作,后面的2步是我们经常需要进行数据处理的地方,那么我们Collector到底工作在哪一步呢?,其实Collector真正的起作用是在3-4步之间的。
那么Collector的作用是干什么的?为什么需要使用Collector?
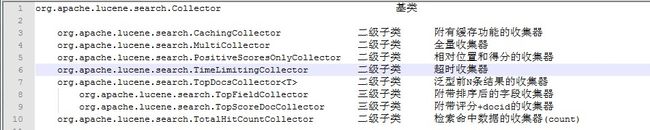
在这之前先分析下TopDocs这个类,这个类的工作原理,其实在后台使用的也是一个收集器,收收集我们检索的结果,通过TopDocsCollector这个基类下面的2个子类收集器,来收集一次我们检索的命中数据。
所以collector的作用就是收集某些我们需要定制化的结果集,某些情况下使用collector可以可以极大的提升我们程序的性能,通过collector可以让我们对每一个匹配上的文档做一些特有的定制化操作,当然前提是在我们需要使用的情况下。
下面我们来看下collector基类的几个方法
| 方法 | 说明 |
| collect() | 检索时,每匹配上一个文档,都会调用此方法 |
| acceptsDocsOutOfOrder() | 测试本collector是否能处理无序到达的docid |
| setScorer(Scorer scorer) | 处理检索结果的评分 |
| setNextReader(AtomicReaderContext context) | 检索时,在多个索引段结构之间切换的方法 |
下面我们来看下自定义的一个collector来实现ScoreDoc类的功能,代码如下.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
package
com.piaoxuexianjing;
import
java.io.IOException;
import
java.util.ArrayList;
import
java.util.List;
import
org.apache.lucene.index.AtomicReaderContext;
import
org.apache.lucene.search.Collector;
import
org.apache.lucene.search.ScoreDoc;
import
org.apache.lucene.search.Scorer;
/**
* @author
* @version 1.0
*
* 自定义收集器
* 实现评分收集
* **/
public
class
MyScoreCollector
extends
Collector {
//private HashMap<String, String> documents=new HashMap<String, String>();
List<ScoreDoc> docs=
new
ArrayList<ScoreDoc>();
private
Scorer scorer;
//scorer类
private
int
docBase;
//全局相对段基数
@Override
public
boolean
acceptsDocsOutOfOrder() {
// TODO Auto-generated method stub
//返回true是允许无次序的ID
//返回false必须是有次序的
return
true
;
}
@Override
public
void
collect(
int
arg0)
throws
IOException {
/**
* 匹配上一个文档
* 就记录其docid与打分情况
*
* */
docs.add(
new
ScoreDoc(arg0+docBase,scorer.score()));
//
}
// BinaryDocValues names;//字符类型的内置存储
// BinaryDocValues bookNames;//字符类型的内置存储
// BinaryDocValues ids;//字符类型的内置存储
// BinaryDocValues prices;//字符类型的内置存储
// FieldCache.Doubles d ; //数值类型的内置存储
// FieldCache.Ints ints;//数值类型的内置存储
@Override
public
void
setNextReader(AtomicReaderContext arg0)
throws
IOException {
this
.docBase=arg0.docBase;
//记录每个索引段结构的相对位置
}
@Override
public
void
setScorer(Scorer arg0)
throws
IOException {
// TODO Auto-generated method stub
this
.scorer=arg0;
//记录改匹配的打分情况
}
}
|
测试类的核心代码
|
1
2
3
4
5
6
7
8
9
10
11
|
//自定义收集器
MyScoreCollector scoreCollector=
new
MyScoreCollector();
searcher.search(
new
MatchAllDocsQuery(), scoreCollector);
/**
* 自定义的收集类,实现效果===>ScoreDocs类
*
**/
List<ScoreDoc> s=scoreCollector.docs;
for
(ScoreDoc sc:s){
System.out.println(sc.doc+
"===="
+sc.score);
}
|
输出结果如下
|
1
2
3
4
5
6
7
8
|
0
====
1.0
1
====
1.0
2
====
1.0
3
====
1.0
4
====
1.0
5
====
1.0
6
====
1.0
7
====
1.0
|
至此,我们就利用自定义的collector完成了一个简单的收集评分功能,当然我们可以根据自己的业务,来实现各种各样的collector,灵活运用!
http://my.oschina.net/MrMichael/blog/220946