eclipse开发hadoop环境搭建
Hadoop2.6.0集群搭建完毕后,下面介绍一下eclipse是如何开发hadoop程序(即MapReduce程序)的。
1.jdk安装hadoop集群的搭建,不再详述,参考 http://kevin12.iteye.com/blog/2273556;
下面运行下hadoop自带的wordcount例子:
2.先将hadoop-2.6.0目录下面的README.txt和LICENSE.txt文件put到集群的/library/hadoop/data目录下面,如果目录不存在先创建;
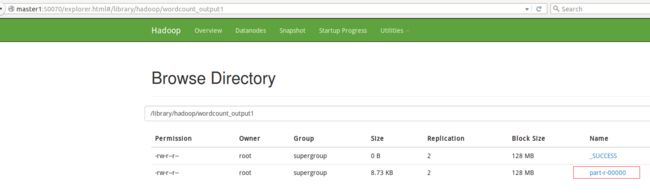
也可以通过浏览器查看文件内容,将/library/hadoop/wordcount_output1目录下面的part-r-00000文件下载打开查看即可:
3.下载eclipse liunx版64位的,直接去eclipse官网下载,不再详述;
4.将下载好的eclipse解压到/usr/local/目录下面,进入eclipse目录,执行eclipse,打开eclipse,工作空间选择默认(/root/workspace)即可。
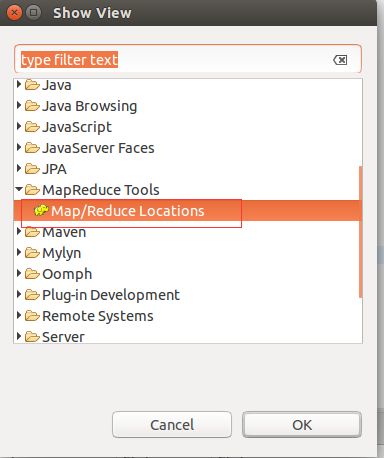
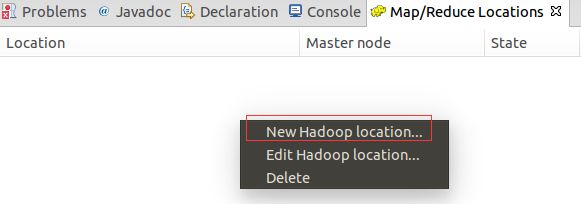
5.本地开发hadoop程序调试运行需要hadoop-eclipse-plugin-2.6.0.jar,将该jar包拷贝到/usr/local/eclipse目录下面的plugins目录下面。在eclipse中选择File->restart重启eclipse,重启打开后选择Window->Show View->Other选中MapReduceTools下面的Map/Reduce Locations并将点击OK。
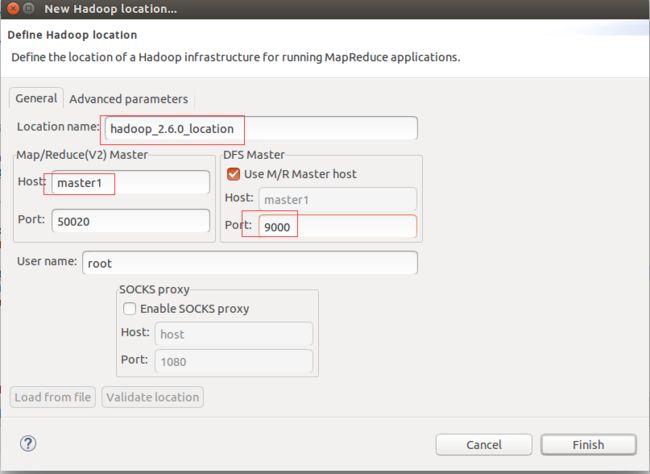
6.创建Hadoop Location,在下面的Map/Reduce Locations中新建一个Hadoop location,配置好Host和Port后保存,选择Java EE的浏览方式,在Project Explorer下面就可以看到DFS Loations,并且显示了集群的根目录文件信息。
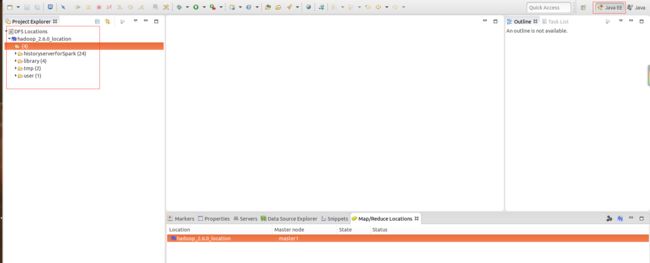
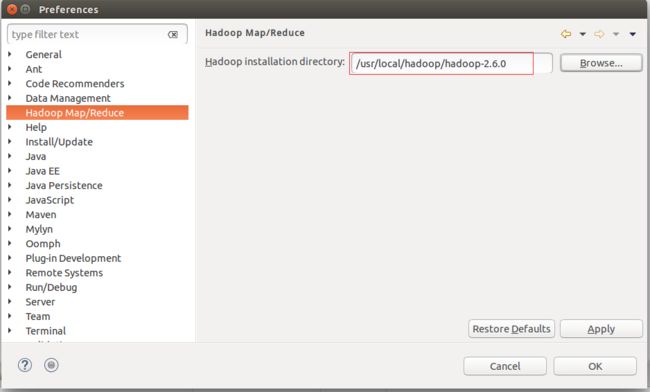
7.指定hadoop的安装目录,选择Window->Preferences->Data Management选中Hadoop Map/Reduce在右面的页签中点击“Browse..."按钮,选择hadoop的安装目录,然后点击Apply,并保存退出。
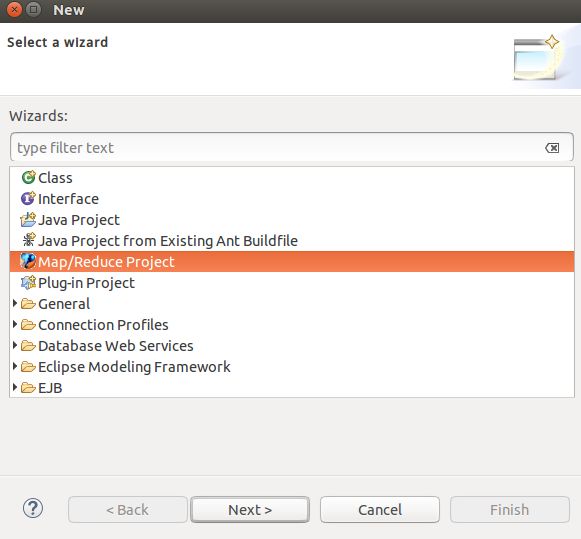
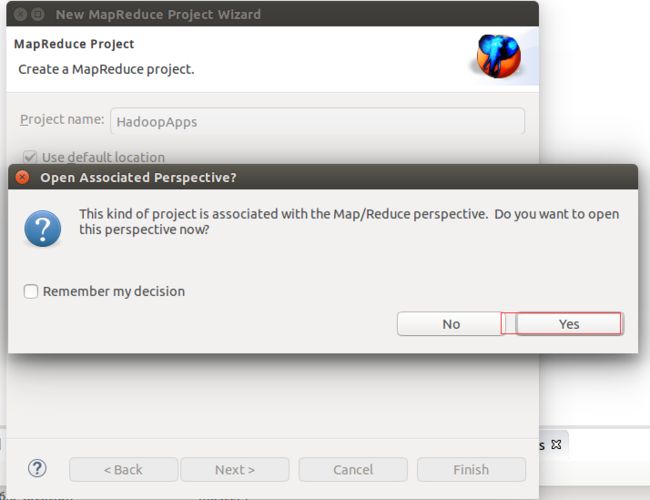
8.创建项目,点击File->New->Other,在弹出框中选择Map/Reduce Project.点击Next,填写项目名称,点击Finish,在弹出框中选择ok,eclipse自动会将hadoop安装目录下的架包引用进来,这样我们就可以开发MapReduce程序了。

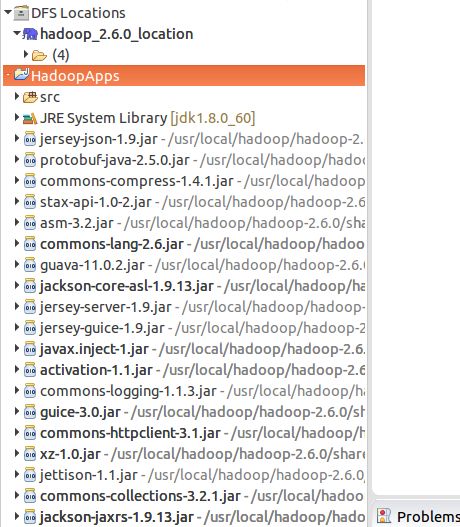
9.关联源码.
首先将hadoop-2.6.0-src.tar.gz拷贝到虚拟机中并解压到/usr/local/hadoop目录下,并用tar命令解压缩;
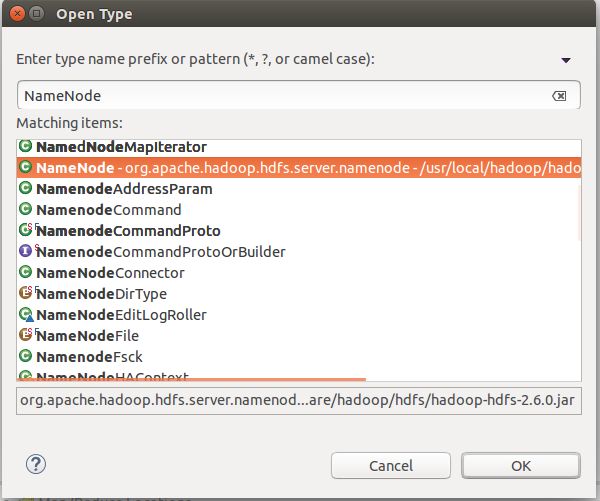
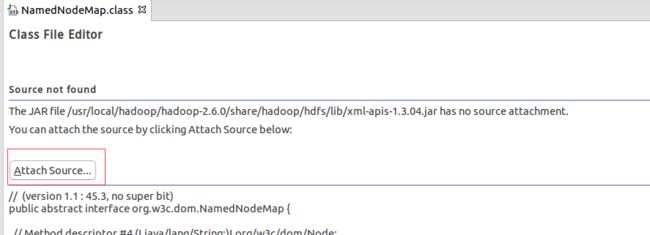
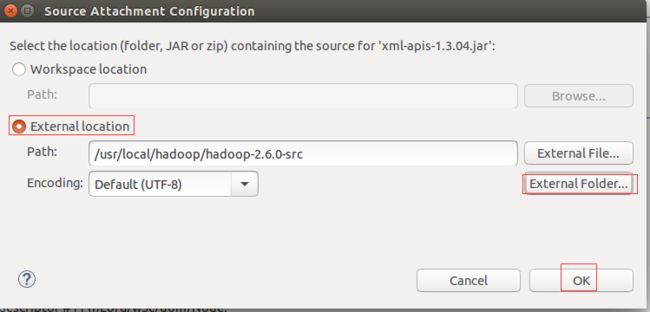
再按Shift+Ctrl+T组合键,在弹出框中输入NameNode选择Hadoop的NamedNodeMap,在class页签中点击Attach Source,在弹出的对话框中选择External location,并点击Extenal Folder按钮选择刚才解压缩的源码hadoop-2.6.0-src,点击OK就可以关联上源码了。
10.运行WordCount例子
解压缩源码,在hadoop-2.6.0-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples中找到WordCount.java文件,拷贝到HadoopApps的com.imf.hadoop包中(如果包不存在先创建);
WordCount源码如下:
然后选择WordCount右键->Run As->Run Configruations,在Java Application中选择WordCount在右面的页签中配置Arguments的Program arguments参数如下:hdfs://master1:9000/library/hadoop/data hdfs://master1:9000/library/hadoop/wordcount_output1,点击Apply,并点击Run按钮运行。

11.查看结果:在浏览器中查看会发现输出目录中会多出part-r-00000文件,这个就是我们统计的结果,也可以用命令hdfs dfs -cat /library/hadoop/wordcount_output1/part-r-00000查看。
注意,如果输出目录已经存在则运行会报错,可以更改一个目录或者删除该目录再次运行即可;

12.下面将WordCount打包成jar文件在集群中运行。
右键HadoopApps选择Export,再弹出框中选择jar文件,点击Next,然后选择jar文件输出的目录,我输出的位置是/usr/local/tools 文件名称为HadoopApps.jar,然后一路Next即可。
注意:在最后一步不指定主函数,而是在运行jar包时进行指定,因为这样做有助于测试其他项目。
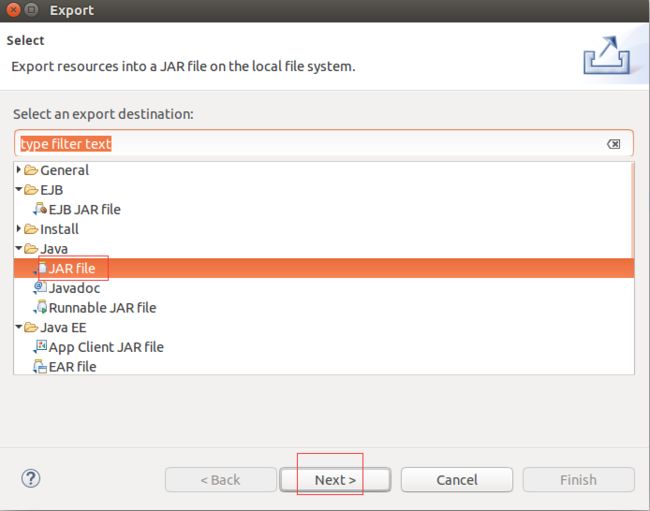

13.运行jar文件
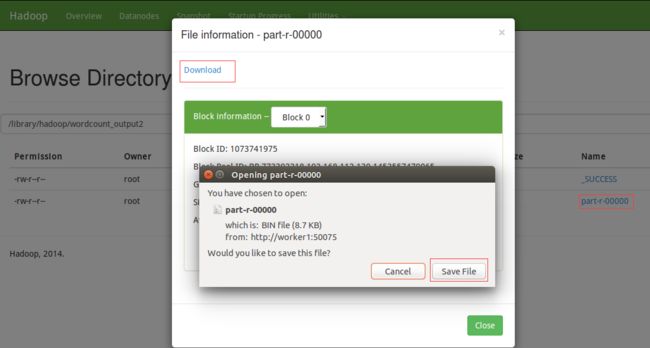
打开浏览器,点击part-r-00000下载并查看:
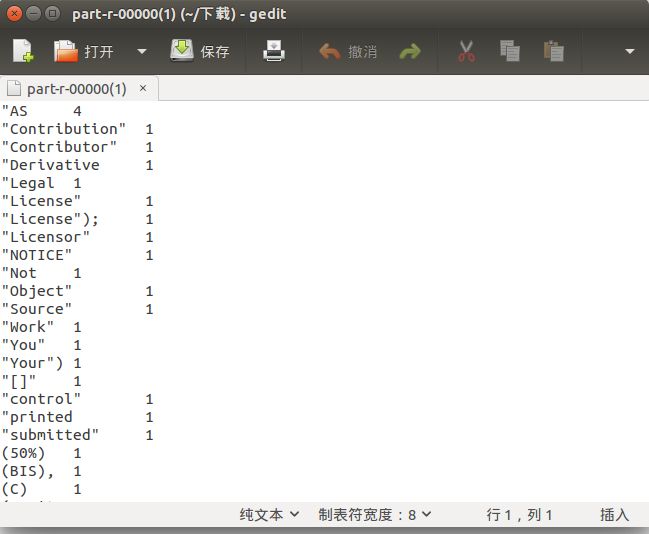
两次运行结果进行比较,结果是一样的。
王家林:中国Spark第一人,Spark亚太研究院院长和首席专家
DT大数据梦工厂
新浪微博:http://weibo.com.ilovepains/
手机:18610086859
QQ:1740415547
联系邮箱[email protected]
1.jdk安装hadoop集群的搭建,不再详述,参考 http://kevin12.iteye.com/blog/2273556;
下面运行下hadoop自带的wordcount例子:
2.先将hadoop-2.6.0目录下面的README.txt和LICENSE.txt文件put到集群的/library/hadoop/data目录下面,如果目录不存在先创建;
root@master1:/usr/local/hadoop/hadoop-2.6.0# hdfs dfs -mkdir /library/hadoop/data
root@master1:/usr/local/hadoop/hadoop-2.6.0# hdfs dfs -put ./LICENSE.txt /library/hadoop/data
root@master1:/usr/local/hadoop/hadoop-2.6.0# hdfs dfs -put ./README.txt /library/hadoop/data
root@master1:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce# hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /library/hadoop/data /library/hadoop/wordcount_output1
16/02/12 12:49:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/02/12 12:49:07 INFO client.RMProxy: Connecting to ResourceManager at master1/192.168.112.130:8032
16/02/12 12:49:08 INFO input.FileInputFormat: Total input paths to process : 2
16/02/12 12:49:08 INFO mapreduce.JobSubmitter: number of splits:2
16/02/12 12:49:08 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1455236431298_0002
16/02/12 12:49:09 INFO impl.YarnClientImpl: Submitted application application_1455236431298_0002
16/02/12 12:49:09 INFO mapreduce.Job: The url to track the job: http://master1:8088/proxy/application_1455236431298_0002/
16/02/12 12:49:09 INFO mapreduce.Job: Running job: job_1455236431298_0002
16/02/12 12:49:20 INFO mapreduce.Job: Job job_1455236431298_0002 running in uber mode : false
16/02/12 12:49:20 INFO mapreduce.Job: map 0% reduce 0%
16/02/12 12:49:30 INFO mapreduce.Job: map 100% reduce 0%
16/02/12 12:49:42 INFO mapreduce.Job: map 100% reduce 100%
16/02/12 12:49:42 INFO mapreduce.Job: Job job_1455236431298_0002 completed successfully
16/02/12 12:49:43 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=12822
FILE: Number of bytes written=342551
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=17026
HDFS: Number of bytes written=8943
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=17371
Total time spent by all reduces in occupied slots (ms)=7667
Total time spent by all map tasks (ms)=17371
Total time spent by all reduce tasks (ms)=7667
Total vcore-seconds taken by all map tasks=17371
Total vcore-seconds taken by all reduce tasks=7667
Total megabyte-seconds taken by all map tasks=17787904
Total megabyte-seconds taken by all reduce tasks=7851008
Map-Reduce Framework
Map input records=320
Map output records=2336
Map output bytes=24790
Map output materialized bytes=12828
Input split bytes=231
Combine input records=2336
Combine output records=886
Reduce input groups=838
Reduce shuffle bytes=12828
Reduce input records=886
Reduce output records=838
Spilled Records=1772
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=526
CPU time spent (ms)=2190
Physical memory (bytes) snapshot=476704768
Virtual memory (bytes) snapshot=5660733440
Total committed heap usage (bytes)=260173824
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=16795
File Output Format Counters
Bytes Written=8943
#查看结果,这里只截取一部分内容:
root@master1:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce# hdfs dfs -cat /library/hadoop/wordcount_output1/part-r-00000
16/02/12 12:51:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
"AS 4
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE" 1
"Not 1
"Object" 1
"Source" 1
"Work" 1
"You" 1
"Your") 1
"[]" 1
"control" 1
"printed 1
"submitted" 1
也可以通过浏览器查看文件内容,将/library/hadoop/wordcount_output1目录下面的part-r-00000文件下载打开查看即可:
3.下载eclipse liunx版64位的,直接去eclipse官网下载,不再详述;
4.将下载好的eclipse解压到/usr/local/目录下面,进入eclipse目录,执行eclipse,打开eclipse,工作空间选择默认(/root/workspace)即可。
5.本地开发hadoop程序调试运行需要hadoop-eclipse-plugin-2.6.0.jar,将该jar包拷贝到/usr/local/eclipse目录下面的plugins目录下面。在eclipse中选择File->restart重启eclipse,重启打开后选择Window->Show View->Other选中MapReduceTools下面的Map/Reduce Locations并将点击OK。
6.创建Hadoop Location,在下面的Map/Reduce Locations中新建一个Hadoop location,配置好Host和Port后保存,选择Java EE的浏览方式,在Project Explorer下面就可以看到DFS Loations,并且显示了集群的根目录文件信息。
7.指定hadoop的安装目录,选择Window->Preferences->Data Management选中Hadoop Map/Reduce在右面的页签中点击“Browse..."按钮,选择hadoop的安装目录,然后点击Apply,并保存退出。
8.创建项目,点击File->New->Other,在弹出框中选择Map/Reduce Project.点击Next,填写项目名称,点击Finish,在弹出框中选择ok,eclipse自动会将hadoop安装目录下的架包引用进来,这样我们就可以开发MapReduce程序了。
9.关联源码.
首先将hadoop-2.6.0-src.tar.gz拷贝到虚拟机中并解压到/usr/local/hadoop目录下,并用tar命令解压缩;
再按Shift+Ctrl+T组合键,在弹出框中输入NameNode选择Hadoop的NamedNodeMap,在class页签中点击Attach Source,在弹出的对话框中选择External location,并点击Extenal Folder按钮选择刚才解压缩的源码hadoop-2.6.0-src,点击OK就可以关联上源码了。
10.运行WordCount例子
解压缩源码,在hadoop-2.6.0-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples中找到WordCount.java文件,拷贝到HadoopApps的com.imf.hadoop包中(如果包不存在先创建);
WordCount源码如下:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.imf.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
然后选择WordCount右键->Run As->Run Configruations,在Java Application中选择WordCount在右面的页签中配置Arguments的Program arguments参数如下:hdfs://master1:9000/library/hadoop/data hdfs://master1:9000/library/hadoop/wordcount_output1,点击Apply,并点击Run按钮运行。
11.查看结果:在浏览器中查看会发现输出目录中会多出part-r-00000文件,这个就是我们统计的结果,也可以用命令hdfs dfs -cat /library/hadoop/wordcount_output1/part-r-00000查看。
注意,如果输出目录已经存在则运行会报错,可以更改一个目录或者删除该目录再次运行即可;
12.下面将WordCount打包成jar文件在集群中运行。
右键HadoopApps选择Export,再弹出框中选择jar文件,点击Next,然后选择jar文件输出的目录,我输出的位置是/usr/local/tools 文件名称为HadoopApps.jar,然后一路Next即可。
注意:在最后一步不指定主函数,而是在运行jar包时进行指定,因为这样做有助于测试其他项目。
13.运行jar文件
root@master1:/usr/local/tools# hadoop jar HadoopApps.jar com.imf.hadoop.WordCount hdfs://master1:9000/library/hadoop/data/ hdfs://master1:9000/library/hadoop/wordcount_output2
16/02/13 14:36:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/02/13 14:36:59 INFO client.RMProxy: Connecting to ResourceManager at master1/192.168.112.130:8032
16/02/13 14:37:00 INFO input.FileInputFormat: Total input paths to process : 2
16/02/13 14:37:00 INFO mapreduce.JobSubmitter: number of splits:2
16/02/13 14:37:01 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1455315784285_0004
16/02/13 14:37:01 INFO impl.YarnClientImpl: Submitted application application_1455315784285_0004
16/02/13 14:37:01 INFO mapreduce.Job: The url to track the job: http://master1:8088/proxy/application_1455315784285_0004/
16/02/13 14:37:01 INFO mapreduce.Job: Running job: job_1455315784285_0004
16/02/13 14:37:08 INFO mapreduce.Job: Job job_1455315784285_0004 running in uber mode : false
16/02/13 14:37:08 INFO mapreduce.Job: map 0% reduce 0%
16/02/13 14:37:19 INFO mapreduce.Job: map 100% reduce 0%
16/02/13 14:37:26 INFO mapreduce.Job: map 100% reduce 100%
16/02/13 14:37:27 INFO mapreduce.Job: Job job_1455315784285_0004 completed successfully
16/02/13 14:37:28 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=12822
FILE: Number of bytes written=342443
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=17026
HDFS: Number of bytes written=8943
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=17479
Total time spent by all reduces in occupied slots (ms)=4161
Total time spent by all map tasks (ms)=17479
Total time spent by all reduce tasks (ms)=4161
Total vcore-seconds taken by all map tasks=17479
Total vcore-seconds taken by all reduce tasks=4161
Total megabyte-seconds taken by all map tasks=17898496
Total megabyte-seconds taken by all reduce tasks=4260864
Map-Reduce Framework
Map input records=320
Map output records=2336
Map output bytes=24790
Map output materialized bytes=12828
Input split bytes=231
Combine input records=2336
Combine output records=886
Reduce input groups=838
Reduce shuffle bytes=12828
Reduce input records=886
Reduce output records=838
Spilled Records=1772
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=387
CPU time spent (ms)=2030
Physical memory (bytes) snapshot=483635200
Virtual memory (bytes) snapshot=5660704768
Total committed heap usage (bytes)=259067904
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=16795
File Output Format Counters
Bytes Written=8943
打开浏览器,点击part-r-00000下载并查看:
两次运行结果进行比较,结果是一样的。
王家林:中国Spark第一人,Spark亚太研究院院长和首席专家
DT大数据梦工厂
新浪微博:http://weibo.com.ilovepains/
手机:18610086859
QQ:1740415547
联系邮箱[email protected]