信息安全系统设计基础第期中学习总结
第一部分——Linux命令
1、 man命令
· 在 Linux 环境中,如果你遇到困难,可以使用man 命令,它是Manual page的缩写。要查看相应区段的内容,就在 man 后面加上相应区段的数字即可
· man命令通常与管道命令结合使用
man -k k1 | grep k2 | grep 2
· man -k 填空:Linux中显示文件(file )属性(status)的命令是( stat )
数据结构中有线性查找算法,C标准库中没有这个功能的函数,但Linux中有,这个函数是(lfind或lsearch)
2、grep命令
· 用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,
或是所给予的文件名为“-”,则grep指令会从标准输入设备读取数据。
· -n:在显示符合范本样式的那一列之前,标示出该列的列数编号。
-r:为递归查找
· grep 填空:
~/test 文件夹下有很多c源文件,查找main函数在哪个文件中的命令( grep main .c )
Linux Bash中,使用grep查找当前目录下.c中main函数在那个文件中的命令是( grep main *.c )
查找宏 STDIN_FILENO 的值的命令是(grep -nr XXX /usr/include)
3、cheat命令
· cheat是非常好用的“打小抄”搜索工具,能够方便的告诉你你想要的内容。
· 填空:
To list the content of /path/to/foo.tgz archive using tar ( tar -jtvf /path/to/foo.tgz )
使用du命令对当前目录下的目录或文件按大小排序 的命令是( du -sk *| sort -rn )
一、文件管理类命令:
1 cat命令
· 使用方式:cat [-AbeEnstTuv] [--help] [--version] fileName 说明:把档案串连接后传到基本输出
· 参数:
-n 由 1 开始对所有输出的行数编号
-b 和 -n 相似,只不过对于空白行不编号
-s 当遇到有连续两行以上的空白行,就代换为一行的空白行
· 判断:Linux Bash中,cat -n 和 nl 命令功能等价。对
2 find命令
· 用法 : find 使用说明: 将档案系统内符合 expression 的档案列出来。你可以指要档案的名称、类别、时间、大小、权限等不同资讯的组合,只有完全相符的才会被列出来。
· 范例:
将目前目录及其子目录下所有延伸档名是 c 的档案列出来:# find . -name "*.c"
将目前目录其其下子目录中所有一般档案列出:# find . -ftype f
将目前目录及其子目录下所有最近 20 分钟内更新过的档案列出:# find . -ctime -20
· find 填空:
查找当前目录下所有目录的find命令是(find . -type d)
查找当前目录下2天前被更改过的文件 (find . -mtime +2 -type f -print)
3 locate命令:
· 使用方式: locate [-q] [-d ] [--database=]
说明:locate 让使用者可以很快速的搜寻档案系统内是否有指定的档案。其方法是先建立一个包括系统内所有档案名称及路径的数据库,之后当寻找时就只需查询这个数
据库,而不必实际深入档案系统之中了。 二、文档编辑类命令:
1 sort命令
· 将文本文件内容加以排序。可针对文本文件的内容,以行为单位来排序。
· 参数:
-m:将几个排序好的文件进行合并。
-n:依照数值的大小排序
· Linux Bash中,ls . | sort 命令的功能是( 显示当前目录内容并排序 )三、磁盘管理类命令
1 du命令
· 显示目录或文件的大小。du会显示指定的目录或文件所占用的磁盘空间。
· 参数:
-a:显示目录中个别文件的大小。
-b:显示目录或文件大小时,以byte为单位。
-c: 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
· 判断:Linux Bash中,df和 du 命令功能等价。错2 ls命令
· 显示指定工作目录下之内容(列出目前工作目录所含之档案及子目录)。
· 参数:
-a 显示所有档案及目录
-A 同 -a ,但不列出 "." (目前目录) 及 ".." (父目录)
-t 将档案依建立时间之先后次序列出
· 列出目前工作目录下所有档案及目录;目录于名称后加 "/", 可执行档于名称后加 "*" : ls -AF
· 填空:
Linux Bash中,把ls命令显示当前目录的结果存入ls.txt的命令输出重定向命令是(ls > ls.txt)3 who命令
· 使用方式 : who - [husfV] [user] 说明 : 显示系统中有那些使用者正在上面,显示的资料包含了使用者 ID,使用的终端机,从那边连上来的,上线时间,呆滞时间,CPU 使用量,动作等等。
· 参数 :
-h : 不要显示标题列
-u : 不要显示使用者的动作/工作
-s : 使用简短的格式来显示
第二部分——Linux编程基础
一、vim编辑器
1 vim的三种模式:
命令行模式:只能移动光标,删除,复制,粘贴
插入模式:编辑文字
底行模式:文件保存或退出,设置编辑环境2 操作:
· 插入:i 在当前光标处进行编辑
I 在行首插入
A 在行末插入
a 在光标后插入编辑
o 在当前行后插入一个新行
cw 替换从光标所在位置后到一个单词结尾的字符
· 保存文档:进入命令行模式,输入w回车,保存文档;输入:w 文件名可以将文档另存为其他文件名或存到其它路径下
· 退出vim:进入命令行模式,输入wq回车,保存并退出编辑3 剪切及粘贴:
· 删除:dd删除整行
· 复制:yy复制整行
· 粘贴:p4 查找:
· 快速查找
· 高级查找

二、GCC
1 GCC编译的四个步骤:
· 预处理(gcc -E)、编译(gcc -S)、汇编(gcc -c)、链接, gcc 选项可以简记为“ESc”,相应的产出文件的后缀可以简记为“iso”2 编译过程:
· 预处理:gcc –E hello.c –o hello.i; gcc –E调用cpp 生成中间文件
· 编 译:gcc –S hello.i –o hello.s; gcc –S调用ccl 翻译成汇编文件
· 汇 编:gcc –c hello.s –o hello.o; gcc -c 调用as 翻译成可重定位目标文件
· 链 接:gcc hello.o –o hello ; gcc -o 调用ld** 创建可执行目标文件3 gcc -m32 可以在64位机上生成32位的代码
gcc -S xxx.c -o xxx.s 获得汇编代码,也可以用objdump -d xxx 反汇编; 注意函数前两条和后两条汇编代码,所有函数都有,建立函数调用栈帧,应该理解、熟记。 三、GDB
1 使用GCC编译时要加“-g”参数,然后才能够用gdb调试
2 常用命令:
gdb programm(启动GDB)
l 查看所载入的文件
b 设断点
info 查看断点情况
run 开始运行程序
bt 打印函数调用堆栈
p 查看变量值
c 从当前断点继续运行到下一个断点
n 单步运行(不进入)
s 单步运行(进入)
quit 退出GDB3 四种断点(函数、行、条件、临时)
4 判断: gdb中next和step都可以单步跟踪,根据自顶向下原则应该优先选用step. 错
详细可以看书上3.11的内容四、静态库和动态库
1 静态库:
· 静态库的生成:ar rcsv libxxx.a xxx.o
· 静态库的使用: gcc -o main main.c -L. -lxxx 注意-L -l 的含义
· 创建它的可执行文件
gcc -02 -c main2.c
gcc -static -o p2 main2.o ./libvector.a
· 参数:
gcc -c只编译,不连接成为可执行文件。
ar -r:在库中插入模块(替换)
-c:创建一个库
-s:写入一个目录文件索引到库中2 动态库:
· 动态库的生成:gcc -fPIC -c xxx.c
gcc -shared -o libxxx.so xxx.o
· 共享库的使用:gcc -o main main.c -L. -lxxx3 静态库和动态库的区别与联系:
· 静态函数库:.a;
利用静态函数库编译成的文件比较大,因为整个 函数库的所有数据都会被整合进目标代码中,
编译后的执行程序不需要外部的函数库支持,因为所有使用的函数都已经被编译进去了。
如果静态函数库改变了,那么你的程序必须重新编译。
· 动态函数库:.so;
动态函数库在编译的时候 并没有被编译进目标代码中,你的程序执行到相关函数时才调用该函数库里的相应函数,因此动态函数库所产生的可执行文件比较小。
由于函数库没有被整合进你的程序,而是程序运行时动态的申请并调用,所以程序的运行环境中必须提供相应的库。
动态函数库的改变并不影响你的程序,所以动态函数库的升级比较方便。 第三部分——教材内容复习整理
第一章——计算机漫游系统:
1.重要思想
·计算机系统中的所有信息都是位串表示的,所谓(信息)就是位+上下文。
·存储器层次结构的主要思想是上层存储器作为下层存储器的(高速缓存)。
·操作系统中最基本的四个抽象是(虚拟机、进程、虚拟存储器、文件)。
·查看源文件可以用od 命令 : od -tc -tx1 hello.c
·冯式结构,理解p6 CPU执行指令的操作(加载、存储、操作、跳转)
·存储系统的核心思想:缓存
第二章——信息的表示和处理:
1.重要思想
·这一章主要是一些关于计算机底层最基本的数值运算,在以前学习过的基础上又新加了一些更专业更学术的方法
字节顺序是网络编程的基础,记住小端是“高对高、低对低”,大端与之相反就可以了。
·IEEE浮点表示:标准 V=(-1)^sM2^E
符号:s 决定这个数是正数还是负数。
尾数:M 二进制小数。
阶码:E 对浮点数加权,权重是2 的E次幂。
·舍入:浮点运算只能近似的表示示数运算想要找到最接近x的值就是舍入,问题的关键在于在两个可能的值中间确定舍入方向。
a.向偶数舍入:也叫向最接近的值舍入。是默认方法。将数字向上或向下舍入使的结果的最低有效数字是偶数。其他三种方式产生实际值的确界。
·学这章还是要会各种运算,补码与反码,有符号数和无符号数,整数和浮点数
第三章——程序的机器表示:
1.重要思想
·这一章类似于之前学过的汇编,有一些机器指令
对于机器级编程来说,两种重要的抽象是(ISA,虚拟地址)
·数据传送指令:MOV:源操作数复制到目的操作数。两个操作数不能都指向寄存器
栈是一个数据结构,可以添加或删除值,遵循后进先出的原则。
push压入栈,pop删除数据。可以插入和删除元素的一端称为栈顶。栈顶元素的地址是最低的
·传送指令的三个变种:movb(传送字节)movw(传送字)movl(传送双字)
·寄存器使用:
%eax,%edx,%ecx 调用者保存寄存器(Q可覆盖,P的数据不会被破坏)
%ebx,%esi,%edi 被调用者保存寄存器(Q在覆盖这些值前必须压入栈并在返回前回复他们)
%ebp,%esp 惯例保持
%eax用来保存返回值
·栈帧指针:清楚每一句汇编语言栈帧指针都是如何变化的
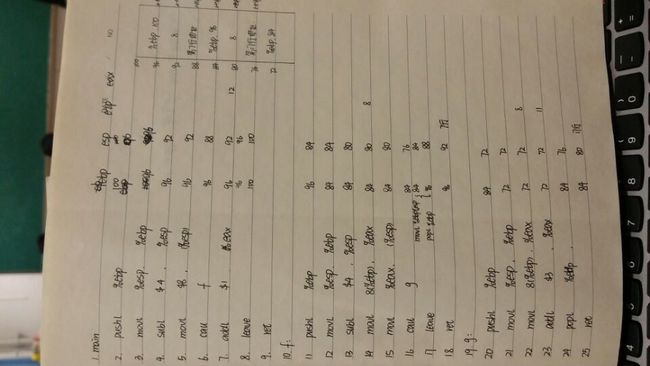
第四章——处理器体系结构:
1.重要思想
·Y86指令集体系结构
能掌握指令编码和字节序列之间的转换
·确定字节编码的方法:
•汇编码表示的第一个字节前端的字节编码
• 寄存器指示符字节
• 4字节常数反序
·Y86中,指令执行分为六个阶段(取指、译码、执行、访存、写回、更新PC)
第六章——存储器层次结构:
1.RAM运存:
·静态(SRAM):
用来作为高速缓存存储器。将每个位存储在一个双稳态的存储器单元里。
并无限期的保持在两个状态或配置之一。其他任何状态都是不稳定的。
在有干扰的情况下,当干扰消除电路恢复稳定。
·动态(DRAM):用来作为主存以及图形系统的帧缓冲区。将每个位存储为对一个电容的充电。
对干扰十分敏感,当电容电压被扰乱之后就不会恢复了。
静态与动态的区别:
· 只要有供电SRAM就会保持不变,与DRAM不同不需要刷新
· SRAM的存取比DRAM快
· SRAM对抗干扰能力比DRAM强,而功耗更大·要掌握有关磁盘的运算
·局部性
局部性又分为时间局部性和空间局部性,一个程序的好坏就看他的局部性是否良好
· 时间局部性:被引用过的存储器的位置在将来可能被多次引用 (同一存储器)
· 空间局部性:被引用过的存储器的位置在将来可能引用附近一个存储器的位置 (不同存储器)
· 对于取指令来说,循环良好的时间和空间局部性,循环体越小,迭代次数越多,局部性越好。
· 顺序引用模式:步长为1的引用模式。随着步长的增加,空间局部性下降
2.
·存储器层次结构
· 中心思想:位于k层的更小更快的存储设备作为位于k+1层更大更慢的存储设备的缓存
数据总是以块大小为传送单元在上下层之间来回拷贝。离CPU越远,使用的块越大。
·缓存命中:
当程序需要第k+1层的某个数据对象d时,首先在当前存储在第k层的一个块中查找d,如果d刚好缓存在第k层中,就称为缓存命中。
该程序直接从第k层读取d,比从第k+1层中读取d更快。
·缓存不命中:
即第k层中没有缓存数据对象d。这时第k层缓存会从第k+1层缓存中取出包含d的那个块。如果第k层缓存已满,就可能会覆盖现存的一个块
替换策略:随机替换策略-随机牺牲一个块,最近最少被使用替换策略LRU-牺牲最后被访问的时间距离现在最远的块。
·缓存不命中的种类
· 强制性不命中/冷不命中:第k层的缓存是空的(称为冷缓存),对任何数据对象的访问都不会命中。
· 冲突不命中:由于一个放置策略:将第k+1层的某个块限制放置在第k层块的一个小的子集中,这就会导致缓存没有满,但是那个对应的块满了。
· 容量不命中:当工作集的大小超过缓存的大小时,缓存会经历容量不命中,就是说缓存太小了,不能处理这个工作集。
·高速缓存的:组相连,行匹配,字选择
四、体会与不足
学了大半学期的计算机系统,刚开始被超级多的任务吓到了有点措手不及不知道从哪下手,觉得这些都是艰涩难懂的知识,但是经过一段时间的学习会发现,这个跟以前学过的很多课都是相通的,比如汇编,和c语言。经过几周下来找到了适合自己学习的方法,每周都会用一段特定的时间来认真读这本书,因为我学知识消化吸收比较慢,如果中间有漏掉一部分内容会导致我后面的内容很难理解所以会用去很长的时间看书做笔记,让自己理解的更透彻一点,这本书应该是我做笔记最多的一本书了哈哈。
自己的不足之处在于不会用这些知识,就比如每章的家庭作业,虽然捋清了知识点但是不能灵活的运用,还有就是抓不住每章的重点。另外之前要在实验楼里完成的几个实验我觉得自己做的不好,离开教程也就不知道该怎么做了。
老师在博客园里答疑的帖子好多都是精华,大家遇到的问题我也会遇到,经常看这些提问与解答也会帮助我解决问题。参考资料
常用命令:http://itlab.idcquan.com/linux/special/linuxcom/
以前发过的博客和别人的优秀博客
每周测验的解析老师总结的每周的重点导读:http://group.cnblogs.com/topic/73069.html