oracle物化视图
原文URL:
oracle 10g物化视图简介
2012-05-09 17:33:55| 分类: ORACLE性能 | 标签:oracle 物化视图 |举报|字号 订阅


环境oracle 10g 10.2.0.4 linux 64
要大而专业的看oracle自己的文档-sql参考。
说实话,oracle需要学习的内容太多,每个都看过去,实在太费事。
所以如果能够对物化视图有个概览,那最方便不过。
主要涉及内容
物化视图日志,用于快速刷新所必须的
物化视图
权限,通常不是个难题,因为编译的时候会给你足够的权限提示,没有的话找dba.为了练习,尽可以在测试环境中赋予dba的权限。
什么是物化视图?(物化视图的简单定义)
简而言之,就是具有实体表的视图,而且这个视图还可以根据多种需求和策略进行刷新。此外还有一个非常重要的功能-查询重写(query rewrite) .查询重写能够在某些时候提高你的查询速度。
所谓查询重写,简而言之,就是oracle 的查询优化器发现有个物化视图的语法和你的SQL差不多,那么就会直接访问物化视图,而不是你原来查询中有关的源表。
物化视图能干什么?
或者说,你能拿物化视图做什么用。
前文简单说了下,此处列出一些重要而想详细的功能:
1)能够提高查询速度,这主要是因为物化视图存储了实际的数据,其次具有查询重写功能。最后,物化视图具有实体表,你也可以在上面建立索引,总之大体上当作一个表用就可以了。
2) 简化了开发任务,意思是开发的人员有的时候,无需直接关注部分sql的性能,而通过dba的努力,使用查询重写来完成性能的提升。
3)减少了工作量,因为物化视图可以定义两种刷新方式:立即刷新,按需刷新。所谓按需刷新就是你自己手动刷新,或者是定时刷新;所谓立即刷新,即视图主表发生变化的时候,视图立即刷新内容。 你可以根据自己的设备情况,应用情况和需求来控制刷新的方式。
4)刷新量的灵活限制,你可以快速是刷新(只刷新变化的),也可以全刷新。看你的需要。
物化视图的语法?
略,这个内容太多,还是去看oracle官方的sql参考吧!
物化视图有关的参数
主要是优化参数(查询重写的)
SQL> show parameters query
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
query_rewrite_enabled string TRUE
query_rewrite_integrity string enforced
第一个参数是表示是否支持查询重写,默认是可以
第二个参数是查询重写的支持方式:
STALE_TOLERATED:表示即使细目表中的数据已经发生了变化,也仍然使用物化视图。
TRUSTED :表示物化视图未失效时才使用该视图。但是,查询改写可以使用信任关系,如那些由维度对象或尚未生效的约束所声明的关系。
ENFORCED(缺省):表示当物化视图保证能给出与使用细目表相同的结果时才使用它。使用这一参数意味着查询改写将不使用失效的物化视图或信任关系。
正确的设置决定于应用程序的数据需求。使用失效物化视图的查询改写可能会产生与没有使用查询改写时不同的结果。然而,如果使用细目数据,可能会因为响应查询需要处理的大量数据而使性能恶化。在一个数据仓库中,通常使用TRUSTED完整级别,因为这样才可以保证你只使用那些具有最新数据的物化视图;然而,被声明为正确(可信任)的关系也可用于查询改写。在大多数数据仓库中,这些关系已经在提取、转换和加载(ETL)过程得到了验证,因此不再需要进行验证。
物化视图有关的工具
主要是dbms_mview包。
对于初学者,主要关心两个过程:
explain_mview,看有关sql是否支持物化视图的有关功能。
Explain_Rewrite,看有关查询sql是否支持查询重写。
explain_mview需要有个表:mv_capabilities_table
SQL> desc mv_capabilities_table
Name Type Nullable Default Comments
--------------- -------------- -------- ------- --------
STATEMENT_ID VARCHAR2(30) Y
MVOWNER VARCHAR2(30) Y
MVNAME VARCHAR2(30) Y
CAPABILITY_NAME VARCHAR2(30) Y
POSSIBLE CHAR(1) Y
RELATED_TEXT VARCHAR2(2000) Y
RELATED_NUM NUMBER Y
MSGNO INTEGER Y
MSGTXT VARCHAR2(2000) Y
SEQ NUMBER Y
这可以在$ORACLE_HOME/rdbms/admin/utlxmv.sql找到脚本
explain_rewrite需要表格:rewrite_Table
脚本同样在 $ORACLE_HOME/rdbms/admin/utlxrw.sql中。
除了这些,还有许多的过程,例如:
select * from dba_procedures where PROCEDURE_NAME LIKE '%MVIEW%'
select * from dba_procedures where OBJECT_NAME='DBMS_SNAPSHOT'
(DBMS_ MVIEW是DBMS_SNAPSHOT同义词)select * from dba_synonyms where synonym_name like '%DBMS_MVIEW%'
(这意思是10g以后大家不要再叫物化视图为快照了).
物化视图日志简介
物化视图的作用就是为了支持快速刷新
总体上语法比较简单,可以简化为如下:
create materilized view log on xxxx with ? [including|excluding] new values
其中including之后的new values可以不要。
log的重点是with和new values两个句子
with字句是告诉oracle当主表数据变化的时候是否需要记录主键、行号、对象ID,或者是这些标识的组合信息,大略的语法图如下:
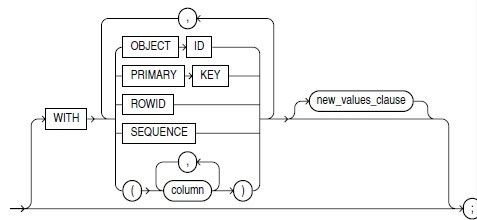
object id: 是系统生成或者用户定义的对象标识符,如果源表行有变化,那么就记录对象的ID。当然只有源表是对象表,你才能这么设置。
primary key: 行变化的时候,存储的是主键.。
rowid:变化时候,存储行号.
sequence: 指示哪些额外的排序信息需要存储起来。序列指对于一些一些更新场景的快速刷新有用。
column: 指示哪些列的指需要存储起来(到日志中)。通常这些列是过滤用或者是连接列。
with语句的限制:
1)每个物化视图日志只能设置一个primary key,rowid,object id,sequcen,以及列列表,或者说with 语句后这些关键字只能更上一次,不能这些 with primary key ,primary key
2)主键列已经是隐式存储在日志中,因此,主键列就不能包含在 column语句中了。
new values 语句
new values语句指示oracle在带更新的DML操作中保存旧数据和新数据到日志中。默认情况,是不记录新新的值。
示例:
create materialized view log on customers with primary key,rowid; --支持rowid物化视图和join物化视图。
create materialized view log on sales with rowid, sequence(amount_sold,time_id,prod_id) including new values; 支持带统计的物化视图(amount_sold是被sum的列,time_id,prod_id是用于过滤的列)。
例如视图: CREATE MATERIALIZED VIEW products_mv
REFRESH FAST ON COMMIT
AS SELECT SUM(list_price - min_price), category_id
FROM product_information
GROUP BY category_id;
物化视图例子:
这里给出了一个能够快速及时更新的物化视图例子,比较简单。
例子1:提交的快速刷新物化视图
create table test_1(id int,name varchar2(20),
constraint pk_test_1 primary key(id)
)
create table test_2(id int,score int,
constraint pk_test_2 primary key(id)
)
drop materialized view log on test_1
drop materialized view log on test_2
create materialized view log on test_1 with rowid
create materialized view log on test_2 with rowid
create materialized view mv_fastrefresh
refresh fast on commit with rowid
enable query rewrite
as
select a.id,b.name,a.score,a.rowid ra,b.rowid rb
from test_2 a, test_1 b where b.id=a.id
例子二:快速刷新的统计物化视图
create table test_s1(id int,name varchar2(20),
constraint pk_test_s1 primary key(id)
)
create table test_s2(id int,mon int, salary number,
constraint pk_test_s2 primary key(id,mon)
)
drop materialized view log on test_s1;
drop materialized view log on test_s2;
create materialized view log on test_s1 with rowid ,sequence(id,name) including new values;
create materialized view log on test_s2 with rowid ,sequence(id,salary) including new values;
create materialized view mv_fastrefresh_sum
refresh fast with primary key
enable query rewrite
as
select a.id,b.name,sum(a.salary) totalIncome
from test_s2 a, test_s1 b where b.id=a.id
group by a.id,b.name
补充
2012/05/21
start with or next 不能和on demand ,on commit共存
-------------------------------------------------------
2013、04、18
由于工作需要,经常要编写这样的脚本,故保留下:
--先检查,然后有必要就删除
declare
vs_jobname varchar2(30):='REFRESH_DMART_JYR';
VN_COUNT PLS_INTEGER;
begin
/*
创建的时候刷新一次,以后每年12月前后一周的每天晚上23:53进行刷新'
*/
SELECT COUNT(*) INTO VN_COUNT
FROM USER_SCHEDULER_JOBS
WHERE JOB_NAME=VS_JOBNAME;
IF VN_COUNT>0 THEN
DBMS_SCHEDULER.DROP_JOB(VS_JOBNAME,TRUE);
END IF;
DBMS_SCHEDULER.create_job(job_name =>VS_JOBNAME
,job_type => 'PLSQL_BLOCK'
,job_action => 'BEGIN DBMS_MVIEW.REFRESH(''MV_DISTINCT_JYR'',''c'');END;'
,start_date => SYSTIMESTAMP
,repeat_interval => 'FREQ=YEARLY; BYDATE=1231^SPAN:1W;BYHOUR=23;BYMINUTE=53'
,enabled => TRUE
,auto_drop => FALSE
,comments => '刷新系统交易日'
);
DBMS_SCHEDULER.run_job(vs_jobname);
end;