2亿QQ用户大调度背后的架构设计和高效运营(上)
作者介绍

周小军
腾讯高级运维工程师,目前在腾讯社交负责社交业务海量NoSQL集群运维和团队管理。曾在天涯社区任运维副总监。对互联网网站架构、数据中心、云计算及自动化运维等领域有深入研究和理解,积累了十多年的IT运维管理经验。希望穷尽一生来深入钻研运维领域。
全网大调度
8月12日23点30分,天津市滨海新区货柜码头发生集装箱连串爆炸。
占地8万平方米,服务器超过20万台的腾讯天津数据中心是腾讯在亚洲最大的数据中心,危险品仓库爆炸时,数据中心距离爆炸点仅仅1.5公里。
情况十分危急!数据中心随时有可能被迫停止运营!
事件发生后,第一时间排查了损伤,发现损伤包括冷机系统宕机,冷冻水管爆管,地下水发生严重水浸等问题,加之爆炸之后各种信息不明朗…
2亿QQ用户可能深受影响!这甚至影响很多公司的业务,因为QQ早已不是简单的聊天工具,而是商务洽谈之必备!
天津数据中心内含腾讯社交核心业务,包括QQ、空间、相册及音乐等业务。社交核心业务主要按深圳、天津和上海三地来分布部署,各支撑中国三大区域的用户访问。
其中天津数据中心是核心机房之一,承载我国北方所有用户流量,高峰期在线用户超过1亿。如果天津数据中心停运,将有30%以上的QQ用户服务受到影响。
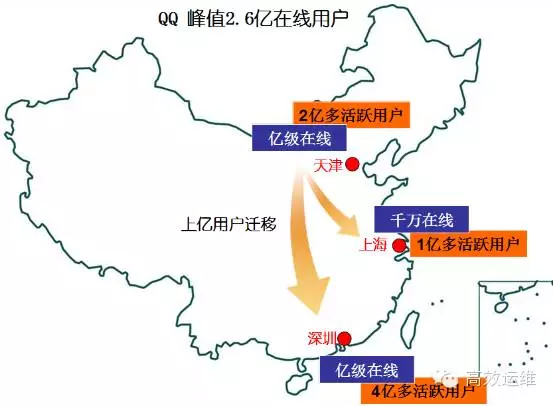
所幸的事,类似于谷歌拥有的全球业务调配能力,腾讯社交网络经过长期的建设积累,具备了数据和业务在全国范围的云数据中心中转换迁移的能力。
经过24小时的技术应急大调度,QQ用户服务最终无感知地在线迁移到深圳和上海,完成中国互联网史上最大规模的用户调度。
在如此严峻的情况下,QQ运营继续保持全年4个9的可持续服务能力。
下面先简单介绍一下调度过程。
1、启动
社交核心业务的三地部署各具有一定的容量冗余,能保证一地灾难性故障时其他二地能支撑所有用户。
事件发生后,社交运营团队立即启动重大故障处理流程,成立突发事件应急团队,启用调度应急预案,做好天津用户调度回深圳和上海的准备:
应急团队按业务分配主、备负责人配合业务线来跟进实施,接入、逻辑和数据三个架构层各安排主备负责人协调。
由故障值班工程师负责在应急团队中协调和沟通。
最上层由大事件经理将汇总信息和实施过程实时同步给总监、业务、运维和QA等工作群组。
2、调度
13日团队开始以每千万为粒度将在线用户调度回深圳。
晚上22时是QQ在线用户峰值时间段,深圳一些服务模块的容量上涨到80%的水位,应急团队利用资源池里的服务器资源,边调度边扩容模块容量,把水位下调到可控范围之内。
对于没有资源扩容的模块,团队采用服务柔性的方式顺利过渡。如QQ采取的柔性为取消一些非关键服务:
如不加载联系人备注,不读取QQ漫游消息等。
通过在线扩容、服务柔性等策略,在线高峰期间用户访问核心服务顺畅,顺利地度过了流量洪峰,用户无感知。
下图为手机QQ天津地区在线用户曲线图:

上图可以观察到从13号晚上到14号凌晨,天津在线用户降到0的曲线下降趋势;以及14号下午回迁60%天津用户后的曲线上升。
整个过程不是仅仅从天津迁出到回迁这么简单,具体是这样的:
14日凌晨1时30分,天津所有用户全部调度、迁出完毕。
调度成功结束,此时天津数据中心在线用户数已为零。
14日上午,天津数据中心运维团队知会天津数据中心暂时可以稳定运营。
应急团队于是主动将深圳的1千万在线用户调度回天津,以缓解深圳数据中心的内网传输压力,并关闭之前开启的服务柔性开关,恢复全功能服务。
14日中午,天津数据中心预警解除,现场可控。
应急团队将大部分在线用户调度回天津,使得天津在线用户恢复到4千万的容量。
20日,天津爆炸现场解控,数据中心几处受损得到全部修复,基础设施恢复正常,警报解除。
应急团队将北方用户全部调度回天津,天津恢复回812之前的流量水平。
调度的几点挑战
QQ 2亿多在线峰值用户要实时全网调度,所面临的挑战是非常大的,主要有:
用户如何在体验无损的情况下调度到异地?
数据中心三地分布,用户在三地之间以秒间调度,必须保证不掉线、不丢数据,用户完全感知不到异地切换。因此必须要保证状态、消息、数据等做到三地的一致。
用户的状态数据、消息如何保证不丢失?
用户有各类状态,如在线、隐身、忙碌等,必须要实时同步到三地数据中心;用户消息包括C2C消息、群消息、离线消息等,要解决用户切换时消息不丢失的挑战。
用户的数据如何做到几地的全量一致性同步?
这里要解决以下问题,包括如何保证同步的可靠性、实时性;如何支撑大流量高效分发和灵活伸缩;如何应对频发网络抖动和异地专线延时;如何支持多地区互联和区域自治。
异地的服务容量(包括服务器容量、模块容量、业务容量和IDC容量等)能否支撑大量用户请求的涌入,异地容量不能支撑时如何处理用户请求?
容量峰值后如何快速缩容?
调度能做到多快,分钟级、小时级还是天级?
调度速度越快就越能具备快速反应能力,而目前QQ已经做到秒级的调度能力。
运营是否具备自动化的调度能力?
调度必须是一键式全自动化,一个工程师就能轻易实现全局的调度能力。
以上任何一个挑战解决不了的话,都必将影响调度的实现。
在下篇将讲述,我们是如何应对这些挑战的。本次亿级用户迁移背后的技术架构和运营,其中用到的核心技术是SET,本文先和大家做个预热。
关于 SET
SET,就像标准化的集装箱,是一个标准化的服务模块集群。它把原错综复杂的服务器内连接关系和功能耦合模糊掉,变成运营层面看到的一个个业务部署模块。
腾讯社交业务以SET的方式部署服务,每个SET集合了一个或一组服务模块,通过接口对外提供调用服务。SET对外输出二种容量:
一个从业务层面来看到的量,即一组服务器的处理能力,处理能力有两个量来描述,PCU容量(万人/在线)和存储容量(GB);
另一个层面则直接来自于成本层面,即这一组服务器有多少台服务器和外/内网带宽。
SET间是无状态的,通过SET可以实现横向扩容能力。也就是说这些业务都支持部署最小化,当有需要时,可以不断增加SET数量来支持业务的流量,且SET之间无差异。
欲知后续如何,且听下文分解~~