Hadoop HA 与 Federation
最近在做Hadoop上应用开发,需要和HA集成,active name node 切换不能影响应用的运行。在研究HA背景的同时,发现HA和Federation 配置中共用了nameservices 的概念,于是有了下面的整理。
一、为什么要HA 和 Federation
1. 单点故障
在Hadoop 2.0之前,也有若干技术试图解决单点故障的问题,我们在这里做个简短的总结
- Secondary NameNode。它不是HA,它只是阶段性的合并edits和fsimage,以缩短集群启动的时间。当NameNode(以下简称NN)失效的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性:如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失。
- Backup NameNode (HADOOP-4539)。它在内存中复制了NN的当前状态,算是Warm Standby,可也就仅限于此,并没有failover等。它同样是阶段性的做checkpoint,也无法保证数据完整性。
- 手动把name.dir指向NFS。这是安全的Cold Standby,可以保证元数据不丢失,但集群的恢复则完全靠手动。
- Facebook AvatarNode。Facebook有强大的运维做后盾,所以Avatarnode只是Hot Standby,并没有自动切换,当主NN失效的时候,需要管理员确认,然后手动把对外提供服务的虚拟IP映射到Standby NN,这样做的好处是确保不会发生脑裂的场景。其某些设计思想和Hadoop 2.0里的HA非常相似,从时间上来看,Hadoop 2.0应该是借鉴了Facebook的做法。
- 还有若干解决方案,基本都是依赖外部的HA机制,譬如DRBD,Linux HA,VMware的FT等等。
2. 集群容量和集群性能
单NN的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NN进程使用的内存可能会达到上百G,常用的估算公式为1G对应1百万个块,按缺省块大小计算的话,大概是64T (这个估算比例是有比较大的富裕的,其实,即使是每个文件只有一个块,所有元数据信息也不会有1KB/block)。同时,所有的元数据信息的读取和操作都需要与NN进行通信,譬如客户端的addBlock、getBlockLocations,还有DataNode的blockRecieved、sendHeartbeat、blockReport,在集群规模变大后,NN成为了性能的瓶颈。Hadoop 2.0里的HDFS Federation就是为了解决这两个问题而开发的。
二、hadoop 2 中HA的实现方式
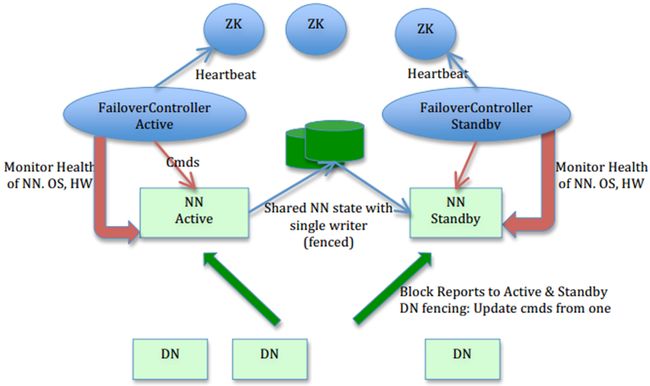
图片来源: HDFS-1623 设计文档
图片作者: Sanjay Radia, Suresh Srinivas
在这个图里,我们可以看出HA的大致架构,其设计上的考虑包括:
-
利用共享存储来在两个NN间同步edits信息。
以前的HDFS是share nothing but NN,现在NN又share storage,这样其实是转移了单点故障的位置,但中高端的存储设备内部都有各种RAID以及冗余硬件包括电源以及网卡等,比服务器的可靠性还是略有提高。通过NN内部每次元数据变动后的flush操作,加上NFS的close-to-open,数据的一致性得到了保证。社区现在也试图把元数据存储放到BookKeeper上,以去除对共享存储的依赖,Cloudera也提供了Quorum Journal Manager的实现和代码,这篇中文的blog有详尽分析:基于QJM/Qurom Journal Manager/Paxos的HDFS HA原理及代码分析 -
DataNode(以下简称DN)同时向两个NN汇报块信息。
这是让Standby NN保持集群最新状态的必需步骤,不赘述。 -
用于监视和控制NN进程的FailoverController进程
显然,我们不能在NN进程内进行心跳等信息同步,最简单的原因,一次FullGC就可以让NN挂起十几分钟,所以,必须要有一个独立的短小精悍的watchdog来专门负责监控。这也是一个松耦合的设计,便于扩展或更改,目前版本里是用ZooKeeper(以下简称ZK)来做同步锁,但用户可以方便的把这个ZooKeeper FailoverController(以下简称ZKFC)替换为其他的HA方案或leader选举方案。 -
隔离(Fencing)),防止脑裂),就是保证在任何时候只有一个主NN,包括三个方面:
- 共享存储fencing,确保只有一个NN可以写入edits。
- 客户端fencing,确保只有一个NN可以响应客户端的请求。
- DataNode fencing,确保只有一个NN可以向DN下发命令,譬如删除块,复制块,等等。
三、hadoop 2中Federation的实现方式
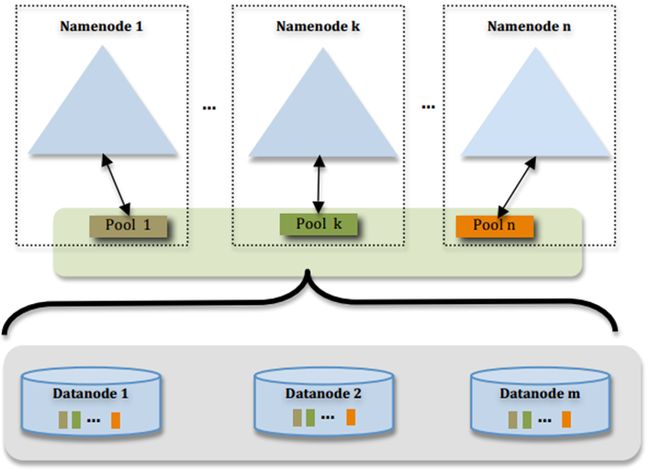
图片来源: HDFS-1052 设计文档
图片作者: Sanjay Radia, Suresh Srinivas
这个图过于简明,许多设计上的考虑并不那么直观,我们稍微总结一下
- 多个NN共用一个集群里DN上的存储资源,每个NN都可以单独对外提供服务
- 每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储
- DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况
- 如果需要在客户端方便的访问若干个NN上的资源,可以使用客户端挂载表,把不同的目录映射到不同的NN,但NN上必须存在相应的目录
这样设计的好处大致有:
- 改动最小,向前兼容
- 现有的NN无需任何配置改动.
- 如果现有的客户端只连某台NN的话,代码和配置也无需改动。
- 分离命名空间管理和块存储管理
- 提供良好扩展性的同时允许其他文件系统或应用直接使用块存储池
- 统一的块存储管理保证了资源利用率
- 可以只通过防火墙配置达到一定的文件访问隔离,而无需使用复杂的Kerberos认证
- 客户端挂载表
- 通过路径自动对应NN
- 使Federation的配置改动对应用透明
四、HA和Federation的配置
为了彻底搞清HA和Federation的配置,我们一步到位,选择了如下的测试场景,结合了HA和Federation:
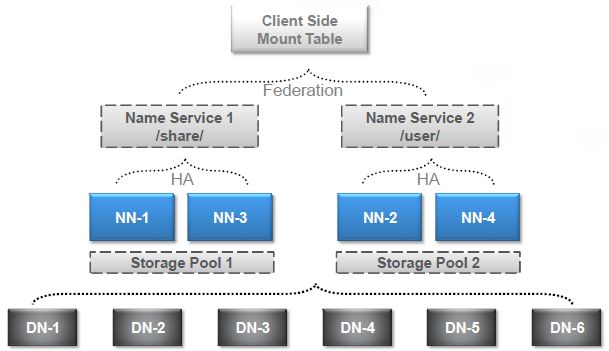
这张图里有个概念是前面没有说明的,就是NameService。Hadoop 2.0里对NN进行了一层抽象,提供服务的不再是NN本身,而是NameService(以下简称NS)。Federation是由多个NS组成的,每个NS又是由一个或两个(HA)NN组成的。在接下里的测试配置里会有更直观的例子。
图中DN-1到DN-6是六个DataNode,NN-1到NN-4是四个NameNode,分别组成两个HA的NS,再通过Federation组合对外提供服务。Storage Pool 1和Storage Pool 2分别对应这两个NS。我们在客户端进行了挂载表的映射,把/share映射到NS1,把/user映射到NS2,这个映射其实不光是要指定NS,还需要指定到其上的某个目录,稍后的配置中大家可以看到。
下面我们来看看配置文件里需要做哪些改动,为了便于理解,我们先把HA和Federation分别介绍,然后再介绍同时使用HA和Federation时的配置方式,首先我们来看HA的配置:
对于HA中的所有节点,包括NN和DN和客户端,需要做如下更改:
HA,所有节点,hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
<description>提供服务的NS逻辑名称,与core-site.xml里的对应</description>
</property>
<property>
<name>dfs.ha.namenodes.${NS_ID}</name>
<value>nn1,nn3</value>
<description>列出该逻辑名称下的NameNode逻辑名称</description>
</property>
<property>
<name>dfs.namenode.rpc-address.${NS_ID}.${NN_ID}</name>
<value>host-nn1:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<property>
<name>dfs.namenode.http-address.${NS_ID}.${NN_ID}</name>
<value>host-nn1:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
以上的示例里,我们用了${}来表示变量值,其展开后的内容大致如下:
<property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn3</value> </property>
<property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>host-nn1:9000</value> </property>
<property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>host-nn1:50070</value> </property>
<property> <name>dfs.namenode.rpc-address.ns1.nn3</name> <value>host-nn3:9000</value> </property>
<property> <name>dfs.namenode.http-address.ns1.nn3</name> <value>host-nn3:50070</value> </property>
与此同时,在HA集群的NameNode或客户端还需要做如下配置的改动:
HA,NameNode,hdfs-site.xml
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>file:///nfs/ha-edits</value>
<description>指定用于HA存放edits的共享存储,通常是NFS挂载点</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>host-zk1:2181,host-zk2:2181,host-zk3:2181,</value>
<description>指定用于HA的ZooKeeper集群机器列表</description>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>5000</value>
<description>指定ZooKeeper超时间隔,单位毫秒</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>指定HA做隔离的方法,缺省是ssh,可设为shell,稍后详述</description>
</property>
HA,客户端,hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>或者false</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.${NS_ID}</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>指定客户端用于HA切换的代理类,不同的NS可以用不同的代理类
以上示例为Hadoop 2.0自带的缺省代理类</description>
</property>
最后,为了方便使用相对路径,而不是每次都使用hdfs://ns1作为文件路径的前缀,我们还需要在各角色节点上修改core-site.xml:
HA,所有节点,core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
<description>缺省文件服务的协议和NS逻辑名称,和hdfs-site里的对应
此配置替代了1.0里的fs.default.name</description>
</property>
接下来我们看一下如果单独使用Federation,应该如何配置,这里我们假设没有使用HA,而是直接使用nn1和nn2组成了Federation集群,他们对应的NS的逻辑名称分别是ns1和ns2。为了便于理解,我们从客户端使用的core-site.xml和挂载表入手:
Federation,所有节点,core-site.xml
<xi:include href=“cmt.xml"/>
<property>
<name>fs.defaultFS</name>
<value>viewfs://nsX</value>
<description>整个Federation集群对外提供服务的NS逻辑名称,
注意,这里的协议不再是hdfs,而是新引入的viewfs
这个逻辑名称会在下面的挂载表中用到</description>
</property>
我们在上面的core-site中包含了一个cmt.xml文件,也就是Client Mount Table,客户端挂载表,其内容就是虚拟路径到具体某个NS及其物理子目录的映射关系,譬如/share映射到ns1的/real_share,/user映射到ns2的/real_user,示例如下:
Federation,所有节点,cmt.xml
<configuration>
<property>
<name>fs.viewfs.mounttable.nsX.link./share</name>
<value>hdfs://ns1/real_share</value>
</property>
<property>
<name>fs.viewfs.mounttable.nsX.link./user</name>
<value>hdfs://ns2/real_user</value>
</property>
</configuration>
注意,这里面的nsX与core-site.xml中的nsX对应。而且对每个NS,你都可以建立多个虚拟路径,映射到不同的物理路径。与此同时,hdfs-site.xml中需要给出每个NS的具体信息:
Federation,所有节点,hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
<description>提供服务的NS逻辑名称,与core-site.xml或cmt.xml里的对应</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>host-nn1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>host-nn1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>host-nn2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>host-nn2:50070</value>
</property>
可以看到,在只有Federation且没有HA的情况下,配置的name里只需要直接给出${NS_ID},然后value就是实际的机器名和端口号,不需要再.${NN_ID}。
这里有一个情况,就是NN本身的配置。从上面的内容里大家可以知道,NN上是需要事先建立好客户端挂载表映射的目标物理路径,譬如/real_share,之后才能通过以上的映射进行访问,可是,如果不指定全路径,而是通过映射+相对路径的话,客户端只能在挂载点的虚拟目录之下进行操作,从而无法创建映射目录本身的物理目录。所以,为了在NN上建立挂载点映射目录,我们就必须在命令行里使用hdfs协议和绝对路径:
hdfs dfs -mkdir hdfs://ns1/real_share
上面这个问题,我在EasyHadoop的聚会上没有讲清楚,只是简单的说在NN上不要使用viewfs://来配置,而是使用hdfs://,那样是可以解决问题,但是是并不是最好的方案,也没有把问题的根本说清楚。
最后,我们来组合HA和Federation,真正搭建出和本节开始处的测试环境示意图一样的实例。通过前面的描述,有经验的朋友应该已经猜到了,其实HA+Federation配置的关键,就是组合hdfs-site.xml里的dfs.nameservices以及dfs.ha.namenodes.${NS_ID},然后按照${NS_ID}和${NN_ID}来组合name,列出所有NN的信息即可。其余配置一样。
HA + Federation,所有节点,hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>ns1, ns2</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn3</value>
</property>
<property>
<name>dfs.ha.namenodes.ns2</name>
<value>nn2,nn4</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>host-nn1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>host-nn1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn3</name>
<value>host-nn3:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn3</name>
<value>host-nn3:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2.nn2</name>
<value>host-nn2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2.nn2</name>
<value>host-nn2:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2.nn4</name>
<value>host-nn4:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2.nn4</name>
<value>host-nn4:50070</value>
</property>
对于没有.${NS_ID},也就是未区分NS的项目,需要在每台NN上分别使用不同的值单独配置,尤其是NFS位置(dfs.namenode.shared.edits.dir),因为不同NS必定要使用不同的NFS目录来做各自内部的HA (除非mount到本地是相同的,只是在NFS服务器端是不同的,但这样是非常不好的实践);而像ZK位置和隔离方式等其实大可使用一样的配置。
除了配置以外,集群的初始化也有一些额外的步骤,譬如,创建HA环境的时候,需要先格式化一台NN,然后同步其name.dir下面的数据到第二台,然后再启动集群 (我们没有测试从单台升级为HA的情况,但道理应该一样)。在创建Federation环境的时候,需要注意保持${CLUSTER_ID}的值,以确保所有NN能共享同一个集群的存储资源,具体做法是在格式化第一台NN之后,取得其${CLUSTER_ID}的值,然后用如下命令格式化其他NN:
hadoop namenode -format -clusterid ${CLUSTER_ID}
当然,你也可以从第一台开始就使用自己定义的${CLUSTER_ID}值。
如果是HA + Federation的场景,则需要用Federation的格式化方式初始化两台,每个HA环境一台,保证${CLUSTER_ID}一致,然后分别同步name.dir下的元数据到HA环境里的另一台上,再启动集群。
材料来自:http://www.infoq.com/cn/articles/hadoop-2-0-namenode-ha-federation-practice-zh/