(二) kafka-jstorm集群实时日志分析 之 ---------jstorm集成spring
后面为了引入Dubbo RPC框架(用spring配置),先把spring 引入jstorm中,请先了解一下jsorm多线程方面的文档:http://storm.apache.org/documentation/Understanding-the-parallelism-of-a-Storm-topology.html .
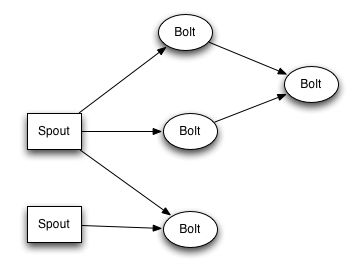
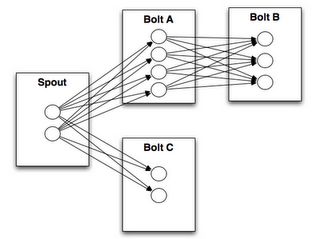


A worker process executes a subset of a topology. A worker process belongs to a specific topology and may run one or more executors for one or more components (spouts or bolts) of this topology. A running topology consists of many such processes running on many machines within a Storm cluster.
An executor is a thread that is spawned by a worker process. It may run one or more tasks for the same component (spout or bolt).
A task performs the actual data processing — each spout or bolt that you implement in your code executes as many tasks across the cluster. The number of tasks for a component is always the same throughout the lifetime of a topology, but the number of executors (threads) for a component can change over time. This means that the following condition holds true: #threads ≤ #tasks. By default, the number of tasks is set to be the same as the number of executors, i.e. Storm will run one task per thread.
多线程环境下每个bolt的每个实例都可能被不同机器执行.每个bolt所需要的服务可能不同,这就需要在每个Bolt类中加载spring,即初始化.比如
<span style="font-size:18px;">public static class WordCounterBoltCh03 extends BaseRichBolt {
private static final Logger log = LoggerFactory.getLogger(WordCounterBoltCh03.class);
private static final long serialVersionUID = 1L;
private Map<String, Integer> countMap;
private OutputCollector collector;
private String name;
private int id;
private static final ApplicationContext applicationContext;
private static final LogManager logManager;
static{
applicationContext = SpringUtil.of("learningJstormConfig/spring-kafkabolt-context.xml");//spring初始化
logManager = applicationContext.getBean(LogManager.class);
log.info("--------------ApplicationContext initialized from learningJstormConfig/spring-kafkabolt-context.xml ");
}
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.countMap = new HashMap<>();
this.collector = collector;
this.name = context.getThisComponentId();
this.id = context.getThisTaskId();
log.info("-----------------WordCounterBoltCh03 prepare");
}
@Override
public void execute(Tuple input) {
String word = null;
try {
word = input.getStringByField("word");
} catch (Throwable e) {
}
if (null != word) {
if (!countMap.containsKey(word)) {
countMap.put(word, 1);
} else {
Integer count = countMap.get(word);
count++;
countMap.put(word, count);
logManager.write(word + ":" + countMap.get(word));
}
} else {
if ("signals.".equals(input.getSourceStreamId()) && "refreshCache".equals(input.getStringByField("action"))) {
cleanup();
countMap.clear();
}
}
this.collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
log.info("{cleanup................}");
countMap.forEach((k, v) -> {
log.info("{clean up.................}");
log.info("k : {} , v : {}", k, v);
});
}
}</span>
spring配置文件如下:
<span style="font-size:18px;"><?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://code.alibabatech.com/schema/dubbo
http://code.alibabatech.com/schema/dubbo/dubbo.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task.xsd">
<import resource="classpath:/learningJstormConfig/dubbo-provider.xml"/>
<context:component-scan base-package="com.doctor.kafkajstrom.log.manager.imp" />
<context:component-scan base-package="com.doctor.kafkajstrom.log.service.imp" />
<context:component-scan base-package="com.doctor.kafkajstrom.component" />
</beans></span>
最好,每个Spout,每个Bolt都定制Spring配置文件.即每个Spout,每个Bolt都加载并初始化Spring环境.