基于BP神经网络的简单字符识别算法自小结(C语言版)
本文均属自己阅读源码的点滴总结,转账请注明出处谢谢。
欢迎和大家交流。qq:1037701636 email:[email protected]
写在前面的闲话:
自我感觉自己应该不是一个很擅长学习算法的人,过去的一个月时间里因为需要去接触了BP神经网络。在此之前一直都认为算法界的神经网络、蚁群算法、鲁棒控制什么的都是特别高大上的东西,自己也就听听好了,未曾去触碰与了解过。这次和BP神经网络的邂逅,让我初步掌握到,理解透彻算法的基本原理与公式,转为计算机所能识别的代码流,这应该就是所谓的数学和计算机的完美结合吧,难道这过程也就是所谓的ACM吗?
1.BP神经网络的基本概念和原理
看了网络上很多关于神经网络相关的资料,了解到BP神经网络是最为简单和通用的,刚好所需完成的工作也主要是简单的字符识别过程。
BP神经网络的概念:
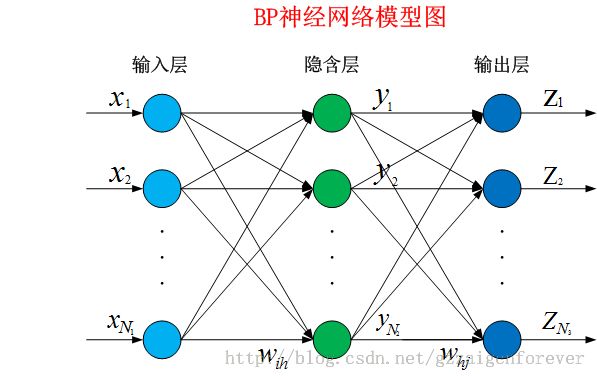
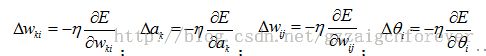
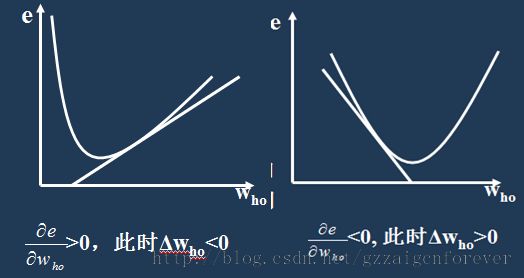






3.BP神经网络算法用C语言的实现
3.1.初始的准备工作,建立三个层的数据结构体:分别表示样本信息、输入层的信息、隐藏层的信息以及输出层的信息,最终归于到一个BP核心算法的结构体bp_alg_core_params;
typedef struct {
unsigned int img_sample_num; //待训练的图像字符、数字样本个数
unsigned int img_width;
unsigned int img_height;
unsigned char *img_buffer;
}img_smaple_params;
typedef img_smaple_params* hd_sample_params;
typedef struct {
unsigned int in_num; //输入层节点数目
double *in_buf; //输入层输出数据缓存
double **weight; //权重,当前输入层一个节点对应到多个隐层
unsigned int weight_size;
double **pri_deltas; //记录先前权重的变化值,用于附加动量
double *deltas; //当前计算的隐层反馈回来的权重矫正
}bp_input_layer_params;
typedef bp_input_layer_params* hd_input_layer_params;
typedef struct {
unsigned int hid_num; //隐层节点数目
double *hid_buf; //隐层输出数据缓存
double **weight; //权重,当前隐层一个节点对应到多个输出层
unsigned int weight_size;
double **pri_deltas; //记录先前权重的变化值,用于附加动量
double *deltas; //当前计算的输出反馈回来的权重矫正值
}bp_hidden_layer_params;
typedef bp_hidden_layer_params* hd_hidden_layer_params;
typedef struct {
unsigned int out_num;//输出层节点数目
double *out_buf; //输出层输出数据缓存
double *out_target;
}bp_out_layer_params;
typedef bp_out_layer_params* hd_out_layer_params;
typedef struct {
unsigned int size; //结构体大小
unsigned int train_ite_num; //训练迭代次数
unsigned int sample_num; //待训练的样本个数
double momentum; //BP阈值调整动量
double eta; //训练步进值,学习效率
double err2_thresh; //最小均方误差
hd_sample_params p_sample; //样本集合参数
hd_input_layer_params p_inlayer; //输入层参数
hd_hidden_layer_params p_hidlayer;//隐藏层参数
hd_out_layer_params p_outlayer;//输出层参数
}bp_alg_core_params;
3.2.参数的初始化,主要包括对计算缓存区的分配。
假设这里分别有M,N,K表示输入、隐藏、输出的节点数目;
那么一个输入缓存区大小:分配大小M+1个;同理隐藏层和输出分别分配:N+1,P+1个;数据量大小默认双精度的double类型。
权值的缓冲区大小:一个根据BP网络的算法,一个节点到下一层的节点分别需要具备一一对应,故这是一个二维数组的形式存在,我们分配输入层权值空间大小为(M+1)(N+1)的大小,隐藏权值空间大小为(N+1)(P+1);
当然对于权值的矫正量,其是一个依据节点的输出值向后反馈的一个变量,实际就是多对1的反馈,而通过公式可以看到我们可以只采用一维数组来表示每一个节点的反馈矫正值(不基于输入节点的数据,即如下的变量:
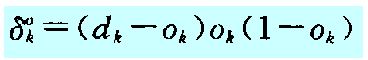
同理最终隐藏层到输出层的反馈矫正、输出层和隐藏层的反馈矫正都以一个一位变量的形式存在,只是在计算权值时要结合节点的输入数据来进行2维矫正。
完成二维数组的动态分配过程函数如下所示:
double** alloc_2d_double_buf(unsigned int m, unsigned int n)
{
unsigned int i;
double **buf = NULL;
double *head;
/*分配一个数组指针空间+ 2维数据缓存空间*/
buf = (double **)malloc(sizeof(double *)*m + m*n*sizeof(double));
if(buf == NULL)
{
ERR("malloc error!");
exit(1);
}
head = (double *)(buf + m);
memset((void *)head, 0x00, sizeof(double)*m*n);//clear 2d buf
for(i = 0; i < m; i++)
{
buf[i] = head + i*n;
DEG("alloc_2d_double_buf, addr = 0x%x", buf[i] );
}
return buf;
}
3.3 BP神经网络训练过程和不断的权值矫正
依次经过forward向前刺激,权值矫正值计算,权值调整,样本均分误差计算。以一次样本数所有样本节点计算完后做均方误差,误差满足一定的阈值就说明BP神经网络训练可以基本结束(一般定义可接受的误差在0.001左右):
int bp_train(bp_alg_core_params *core_params)
{
unsigned int i, j, k;
unsigned int train_num, sample_num;
double err2;//均分误差
DEG("Enter bp_train Function");
if(core_params == NULL)
{
ERR("Null point Entry");
return -1;
}
train_num = core_params->train_ite_num;//迭代训练次数
sample_num = core_params->sample_num;//样本数
hd_sample_params p_sample = core_params->p_sample; //样本集合参数
hd_input_layer_params p_inlayer = core_params->p_inlayer; //输入层参数
hd_hidden_layer_params p_hidlayer = core_params->p_hidlayer; //隐藏层参数
hd_out_layer_params p_outlayer = core_params->p_outlayer; //输出层参数
DEG("The max train_num = %d", train_num);
/*依次按照训练样本数目进行迭代训练*/
for(i = 0; i < train_num; i++)
{
err2 = 0.0;
DEG("current train_num = %d", i);
for(j = 0 ; j < sample_num; j++)
{
DEG("current sample id = %d", j);
memcpy((unsigned char*)(p_inlayer->in_buf+1), (unsigned char*)sample[j], p_inlayer->in_num*sizeof(double));
memcpy((unsigned char*)(p_outlayer->out_target+1), (unsigned char*)out_target[j%10], p_outlayer->out_num*sizeof(double));
/*输入层到隐藏层的向前传递输出*/
bp_layerforward(p_inlayer->in_buf, p_hidlayer->hid_buf, p_inlayer->in_num, p_hidlayer->hid_num, p_inlayer->weight);
/*隐藏层到输出层的向前传递输出*/
bp_layerforward(p_hidlayer->hid_buf, p_outlayer->out_buf, p_hidlayer->hid_num, p_outlayer->out_num, p_hidlayer->weight);
/*输出层向前反馈错误到隐藏层,即权值矫正值*/
bp_outlayer_deltas(p_outlayer->out_buf, p_outlayer->out_target, p_outlayer->out_num, p_hidlayer->deltas);
/*隐藏层向前反馈错误到输入层,权值矫正值依赖于上一层的调整值*/
bp_hidlayer_deltas(p_hidlayer->hid_buf, p_hidlayer->hid_num, p_outlayer->out_num, p_hidlayer->weight, p_hidlayer->deltas, p_inlayer->deltas);
/*调整隐藏层到输出层的权值*/
adjust_layer_weight(p_hidlayer->hid_buf, p_hidlayer->weight, p_hidlayer->pri_deltas, p_hidlayer->deltas, p_hidlayer->hid_num,
p_outlayer->out_num, core_params->eta, core_params->momentum);
/*调整隐藏层到输出层的权值*/
adjust_layer_weight(p_inlayer->in_buf, p_inlayer->weight, p_inlayer->pri_deltas, p_inlayer->deltas, p_inlayer->in_num,
p_hidlayer->hid_num, core_params->eta, core_params->momentum);
err2 += calculate_err2(p_outlayer->out_buf, p_outlayer->out_target, p_outlayer->out_num);//统计所有样本遍历一次后的均分误差
}
/*一次样本处理后的均分误差统计*/
err2 = err2/(double)(p_outlayer->out_num*sample_num);
INFO("err2 =%08f\n",err2 );
if(err2 < core_params->err2_thresh)
{
INFO("BP Train Success by costs vaild iter nums: %d\n", i);
return 1;
}
}
INFO("BP Train %d Num Failured! need to modfiy core params\n", i);
return 0;
}
4.总结
BP神经网络在理解完算法的核心思想后,用代码的形式去实现往往会变得事半功倍,而如果一股脑儿直接拿到code去分析的做法不推荐。因为不了解核心思想的基础下,无法对算法的参数进行部分的修改以及优化,盲目修改往往会造成实验的失败。
本算法应该满足了BP神经网络的基本训练过程。至于无论是识别,预测还是其他,都可以在获取理想样本源和目标源的基础上对BP神经网络进行训练与学习,使得其具备了一定的通用性。后期要做的是将上述浮点的处理过程竟可能的转为定点化的DSP来处理,将其应用到嵌入式设备中去。
注:
由于很多人向我咨询code,所以上传了基于BP神经网络的简单字符识别算法自小结(C语言版) 。本人已不再研究,谢谢。