C++ Primer 学习笔记_28_类与数据抽象(10)--const 用法小结、static与const以及static const(const static)、分别用C和C++来实现一个链栈
一、const 用法总结
1、可以对const 的用法做个小总结:
const int n = 100; //定义常量
const Test t(10);
const int & ref = n; //const引用
int& ref = n; //Error
【const与指针】
const int* p; //const出现在*前面,表示*p是常量 (*p = 200; //Error)
int * const p2; //const出现在*后面,表示p2是常量 (p2 = &n2; //Error)
const int* const p3 = &n; //*p3是常量,p3也是常量
【类】
如果有const成员,const成员的初始化必须只能在构造函数初始化列表中进行
const修饰成员函数,表示该成员函数不能修改对象状态,也就时说它只能访问数据成员,但是不能修改数据成员
【例子】
#include <iostream>
using namespace std;
int main()
{
const int n = 100;
int n2 = 200;
int n3 = 300;
const int* p = &n;
*p = 200;
int* const p2 = &n3;
p2 = &n2;
const int* const p3 = &n;
return 0;
}运行结果:
test.cpp:11:7: 错误: 向只读位置‘* p’赋值
test.cpp:13:8: 错误: 向只读变量‘p2’赋值
2、const一些常见的问题
(1)由于const常量在定义后就不能修改,所以定义时必须初始化。
const int i, j = 0; //错误,i必须初始化
(2)全局const变量与非const变量
——在全局作用域定义非const变量时,在整个程序中都可以访问。
//file1.cpp int counter = 10;
//file2.cpp
#include <iostream>
using namespace std;
int main()
{
extern int counter;
for(int i = 0; i != counter; i++)
{
cout << i << " ";
}
cout << endl;
}
运行结果:
0 1 2 3 4 5 6 7 8 9
——在全局作用域定义const变量时是定义该对象的文件的局部变量,不能在整个程序中可以访问。需要在定义的时候在const前加上extern关键字,才可以在整个程序中访问。
//file1.cpp extern const int counter = 10; //const int counter = 10; //这样定义在file2中不能访问到
//file2.cpp
#include <iostream>
using namespace std;
int main()
{
extern const int counter;
for(int i = 0; i != counter; i++)
{
cout << i << " ";
}
cout << endl;
}
运行结果:
0 1 2 3 4 5 6 7 8 9
(3)在C++中主要是用const替代#define的功能,建议在C++中,用const取代#define。优点有很多,比较突出的优点是编译器会对const进行类型安全检查,而#define没有类型安全检查,在字符替换时可能会产生意料不到的错误。
(4)指针在不同地方的含义
——double* ptr = &value;
答:ptr是一个指向double类型的指针,ptr的值可以改变,可以通过ptr改变value的值。
——const double* ptr = &value;
答:ptr是一个指向const double类型的指针,ptr的值可以改变,不能通过ptr改变value的值。
——double* const ptr = &value;
答:ptr是一个指向double类型的const指针,ptr的值不能改变,可以通过ptr改变value的值。
——const double* const ptr = &value;
答:ptr是一个指向const double类型的const指针,ptr的值不能改变,不能通过ptr改变value的值。
【一个有趣的例子】
看下面代码:
#include <iostream>
int main()
{
char* const a[2] = {"abc", "def"};
a[0] = "ABC"; //错误
*(a+1); //正确
}
解释:a[2]是一个数组,可以当作是指针*a,然后根据上述的理解,a的值可以改变,不能通过a改变数组的值。
(5)作用区的const应用
【例子1】
下面的变量p和它所指向的字符串分别存放在()
#include <iostream>
int main()
{
char* p = "hello world";
}A、堆和常量区 B、栈和栈 C、栈和常量区 D、栈和堆
解答:C。"hello world"存放在文字常量区,变量p存放在栈上。
——现在做些修改
#include <iostream>
int main()
{
char* p = "hello world";
p[0] = 'a';
}
运行结果:
导致运行时崩溃,因为程序对文字常量区的内容试图做修改,而这是不允许的。此时可以改一下p的定义:const char* p = "hello world"; 这样编译器就会直接识别出错误。
(6)const修饰返回值
【一个例子】
猜猜下面程序的运行结果:
#include <iostream>
using namespace std;
char* getstr()
{
char p[] = "hello world";
return p;
}
int main()
{
char *str = NULL;
str = getstr();
cout << str << endl;
return 0;
}
解释:结果是乱码。p是一个数组,其内存分配在栈上,故getstr()返回的是指向“栈内存”的指针,该指针的地址不是NULL,但其原来的内容已经被清楚,新内容不可知。
——解决方案:由于栈容量小,每次作用域结束就会清除;因此可以不存在栈区,存在静态区(全局区)或者是堆区。比如下述,加上static,存到静态数据区。
#include <iostream>
using namespace std;
char* getstr()
{
static char p[] = "hello world";
return p;
}
int main()
{
char *str = NULL;
str = getstr();
cout << str << endl;
return 0;
}运行结果:
hello world
(7)const用来修饰函数参数
——【例子1】
#include <iostream>
void fun(int* i){ }
int main()
{
const int a = 1;
fun(&a);
return 0;
}运行结果:编译出错
解释:在函数中加const则可以运行,void fun(const int* i){ }
——【例子2】
#include <iostream>
void fun(int& i){ }
int main()
{
fun(1);
return 0;
}运行结果:编译出错
解释:在函数中加const则可以运行,void fun(const int& i){ }
——【例子3】
下面哪些选项能编译通过()(不定项)
int i;
char a[10];
string f();
string g(string &str);
A、if(!!I) {f();} B、g(f()); C、a = a + 1; D、g("ABC");
答案:A。
B、关键点时g++下临时变量都作为常量故f()返回值作为临时变量(常量)传递给函数g时出错,因为常量不能传递给一个非常量引用。详细如下:
#include <iostream>
#include <string>
using namespace std; //string的时候需要声明,忘了
string f() { return "a"; } //此时,只要修改为string g(const string &str) { },即在参数前加上const修饰就可以运行。
//string g(string &str) { } //不能运行
string g(const string &str) { }
int main()
{
g(f());
return 0;
}
C、a是常量,不可以进行赋值
D、同B。
3、static与const以及static const(const static)
(1)说明在C++中static、const以及static const成员变量的初始化?
解答:
在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义的外部,通常在类的实现文件中初始化,static关键字只能用于类定义内部的声明中,定义时不能标示为static。
在 C++中,const成员变量也不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。const数据成员只在某个对象生存期是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类的声明中初始化const数据成员,因为类的对象没被创建时,编译器不知道const数据成员的值时什么。(好像在C++11中可以在定义处初始化)
const数据成员的初始化只能在类的构造函数的初始化列表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现,或者static const。详细如下:
class Test
{
public:
Test(): a(0) { }
enum { size1 = 100, size2 = 200};
private:
const int a;
static int b;
const static int c; //与static const int c;相同,考虑c为整型时,有三种情况:第一,可在此处声明,但仍需在类定义体外进行定义初始化,因为const必须初始化。第二,直接在此处进行定义初始化,就不能在类定义体外进行赋值,const不能重复赋值。第三,绝对不允许在构造函数的初始化列表进行初始化。注意:c为非整型时,不能在此处初始化,整型包括char、short、long、int、float、double(但是string不行)
};
int Test::b = 0;
const int Test::c = 0;
【例子】
下面的()中可以用哪些选项填充,运行结果是:0 20 1 20?
#include <iostream>
using namespace std;
class Test
{
public:
() int a;
() int b;
public:
Test(int _a, int _b) : a(_a)
{
b = _b;
}
};
int Test::b;
int main()
{
Test t1(0, 0), t2(1, 1);
t1.b = 10;
t2.b = 20;
cout << t1.a <<" " << t1.b << " " << t2.a << " " << t2.b << endl;
}
A、statc/const B、const/static C、-/static D、const static/static E、None of the above
答案:BC。发现t1与t2的b是相同的,仿佛“只有一份”,所以是静态的。相反,a肯定是非静态的。所以,a只是在初始化列表中初始化,const和非const都满足,因此答案是BC。
二、从一个实例看数据抽象与封装(分别用C和C++来实现一个链栈)
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
struct Link //栈内部用链表来实现
{
int data;
struct Link* next;
};
struct Stack
{
struct Link* head; //指向链表头结点的指针
int size; //栈的大小
};
void StackInit(struct Stack* stack) //栈的初始化
{
stack->head = NULL;
stack->size = 0;
}
void StackPush(struct Stack* stack, const int data) //往栈当中加入一个数据data
{
struct Link* node; //产生一个新的节点,并分配内存
node = (struct Link*)malloc(sizeof(struct Link));
assert(node != NULL);
node->data = data; //新产生节点的数据域等于data
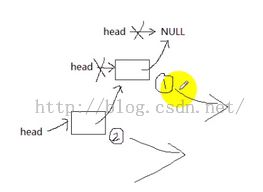
node->next = stack->head; //根据图可以实现,实际就是链表头插入法
stack->head = node;
++stack->size;
}
int StackEmpty(struct Stack* stack)
{
return (stack->size == 0);
}
int StackPop(struct Stack* stack, int* data) //将头结点出栈,并写到data中
{
if (StackEmpty(stack))
{
return 0;
}
struct Link* tmp = stack->head; //为了释放头结点,应先保存
*data = stack->head->data;
stack->head = stack->head->next;
free(tmp);
--stack->size;
return 1;
}
void StackCleanup(struct Stack* stack)
{
struct Link* tmp;
while (stack->head)
{
tmp = stack->head;
stack->head = stack->head->next;
free(tmp);
}
stack->size = 0;
}
int main(void)
{
struct Stack stack;
StackInit(&stack);
int i;
for (i = 0; i < 5; i++)
{
StackPush(&stack, i);
}
while (!StackEmpty(&stack))
{
StackPop(&stack, &i);
printf("%d ", i);
}
printf("\n");
return 0;
}
2、用C++数据抽象的方式实现栈
#include <iostream>
using namespace std;
class Stack
{
private:
struct Link
{
int data_;
Link* next_;
Link(int data, Link* next) : data_(data), next_(next) { }
};
public:
Stack() : head_(0), size_(0) { }
~Stack() //将StackCleanup放到析构函数中实现
{
Link *tmp;
while (head_)
{
tmp = head_;
head_ = head_->next_;
delete tmp;
}
}
void Push(const int data)
{
Link* node = new Link(data, head_); //通过构造函数修改数据域和指针域
head_ = node;
++size_;
}
bool Empty()
{
return (size_ == 0);
}
bool Pop(int &data)
{
if (Empty())
{
return false;
}
Link *tmp = head_;
data = head_->data_;
head_ = head_->next_;
delete tmp;
--size_;
return true;
}
private:
Link *head_;
int size_;
};
// 避免名称冲突
// 类型的扩充
// 数据封装、能够保护内部的数据结构不遭受外界破坏
int main(void)
{
Stack stack; // 抽象数据类型 类类型
int i;
for (i = 0; i < 5; i++)
{
stack.Push(i); // this = &stack
}
while (!stack.Empty())
{
stack.Pop(i);
cout << i << " ";
}
cout << endl;
return 0;
}
3、相对比C语言,C++的实现由一些不同之处:
(1)栈的初始化放到构造函数实现,栈的释放使用析构函数实现
(2)每个函数的调用都少了一个参数,不需要再传递stack的地址;实际上在C++中,this = &stack。
(3)避免名称冲突,数据封装、能够保护内部的数据结构不遭受外界破坏
参考:
C++ primer 第四版