hadoop分析之四:关于hadoop namenode的双机热备份方案
参考Hadoop_HDFS系统双机热备方案.pdf,试验后有所增减
关于hadoopnamenode的双机热备份方案
1、 前言
目前hadoop-0.20.2没有提供name node的备份,只是提供了一个secondary node,尽管它在一定程度上能够保证对name node的备份,但当name node所在的机器出现故障时,secondary node不能提供实时的进行切换,并且可能出现数据丢失的可能性。
我们采用drbd + heartbeat方案实现name node的HA。
采用drbd实现共享存储,采用heartbeat实现心跳监控,所有服务器都配有双网卡,其中一个网卡专门用于建立心跳网络连接。
2、 基本配置
2.1、硬件环境
采用VMWare的虚拟机作为测试机,一共三台,其中两台分别提供2个网卡(其中一个用作网络通讯,一个为heartbeat的心跳),和一个空白的大小相同的分区(供drbd使用)。软件环境:RedHat Linux AS 5,hadoop-0.20.2, 大体情况如下图:
| 主机 |
IP地址 |
分区 |
| server1(name node) |
eth0:10.10.140.140 eth1:10.0.0.201(heartbeat心跳使用此ip) eth0:0:10.10.140.200(虚拟IP) |
/dev/drbd0 Mounted on /home/share |
| server2(data node) |
eth0:10.10.140.117 |
|
| server3(备份 name node) |
eth0:10.10.140.84 eth1:10.0.0.203(heartbeat心跳使用此ip) eth0:0:10.10.140.200(虚拟IP) |
dev/drbd0 Mounted on /home/share |
|
|
|
|
2.1、网络配置
2.2.1、修改server1和server3的hosts(相同)文件
vi /etc/hosts
10.10.140.140 server1
10.10.140.117 server2
10.10.140.84 server3
10.10.140.200 servervip
10.0.0.201 server1
10.0.0.203 server3
2.2.2、server1和server3的网络配置如下:
server1的网络配置:
[root@server1 ~]#cat /etc/sysconfig/network-scripts/ifcfg-eth0
# Advanced MicroDevices [AMD] 79c970 [PCnet32 LANCE]
DEVICE=eth0
BOOTPROTO=none
HWADDR=00:0C:29:18:65:F5
ONBOOT=yes
IPADDR=10.10.140.140
NETMASK=255.255.254.0
GATEWAY=10.10.140.1
TYPE=Ethernet
[root@server1 ~]#cat /etc/sysconfig/network-scripts/ifcfg-eth1
# Please read/usr/share/doc/initscripts-*/sysconfig.txt
# for thedocumentation of these parameters.
GATEWAY=10.0.0.1
TYPE=Ethernet
DEVICE=eth1
HWADDR=00:0c:29:18:65:ff
BOOTPROTO=none
NETMASK=255.255.255.0
IPADDR=10.0.0.201
ONBOOT=yes
USERCTL=no
IPV6INIT=no
PEERDNS=yes
Server3的网络配置:
[root@server3 ~]#cat /etc/sysconfig/network-scripts/ifcfg-eth0
# Advanced MicroDevices [AMD] 79c970 [PCnet32 LANCE]
DEVICE=eth0
BOOTPROTO=none
HWADDR=00:0C:29:D9:6A:53
ONBOOT=yes
IPADDR=10.10.140.84
NETMASK=255.255.254.0
GATEWAY=10.10.140.1
TYPE=Ethernet
[root@server3 ~]#cat /etc/sysconfig/network-scripts/ifcfg-eth1
# Please read/usr/share/doc/initscripts-*/sysconfig.txt
# for thedocumentation of these parameters.
GATEWAY=10.0.0.1
TYPE=Ethernet
DEVICE=eth1
HWADDR=00:0c:29:d9:6a:5d
BOOTPROTO=none
NETMASK=255.255.255.0
IPADDR=10.0.0.203
ONBOOT=yes
USERCTL=no
IPV6INIT=no
PEERDNS=yes
2.2.3、修改主机名
[root@server1 ~]#cat /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=yes
HOSTNAME=server1
[root@server3 ~]#cat /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=yes
HOSTNAME=server3
2.2.4、 关闭防火墙
[root@server1 ~]#chkconfig iptables off
[root@server3 ~]# chkconfig iptables off
3、 DRBD安装与配置
3.1、DRBD的原理
DRBD(DistributedReplicated Block Device)是基于Linux系统下的块复制分发设备。它可以实时的同步远端主机和本地主机之间的数据,类似与Raid1的功能,我们可以将它看作为网络 Raid1。在服务器上部署使用DRBD,可以用它代替共享磁盘阵列的功能,因为数据同时存在于本地和远端的服务器上,当本地服务器出现故障时,可以使用远端服务器上的数据继续工作,如果要实现无间断的服务,可以通过drbd结合另一个开源工具heartbeat,实现服务的无缝接管。DRBD的工作原理如下图:
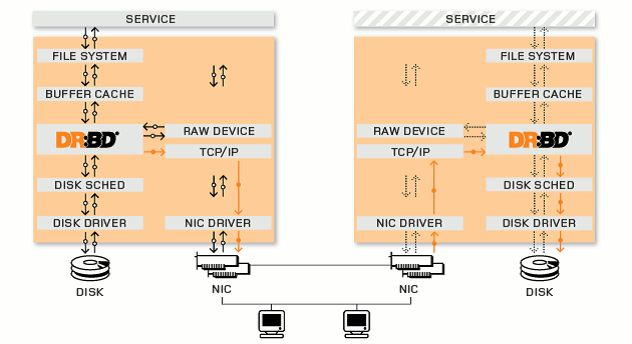
3.2、安装
下载安装包:wget http://oss.linbit.com/drbd/8.3/drbd-8.3.0.tar.gz,执行以下命令:
tar xvzf drbd-8.3.0.tar.gz
cd drbd-8.3.0
cd drbd
make clean all
cd ..
make tools
make install
make install-tools
验证安装是否正确:
# insmod drbd/drbd.ko 或者 # modprobe drbd
# lsmod | grep drbd
drbd 220056 2
显示则安装正确。主要在server1上和和server3上都要安装
3.3、配置
3.3.1、DRBD使用的硬盘分区
server1和server3分区的大小,格式必须相同。并且必须都为空白分区,可以在装系统前预留分区,如果已经安装好的系统,建议使用gparted工具进行分区。
使用方法可以参考:http://hi.baidu.com/migicq/blog/item/5e13f1c5c675ccb68226ac38.html
server1:ip地址为10.10.140.140,drbd的分区为:/dev/sda4
server3:ip地址为10.10.140.84,drbd的分区为:/dev/sda4
3.3.2、主要的配置文件
DRBD运行时,会读取一个配置文件/etc/drbd.conf。这个文件里描述了DRBD设备与硬盘分区的映射关系,和DRBD的一些配置参数。
[root@server1 ~]#vi /etc/drbd.conf
#是否参加DRBD使用者统计.默认是yes
global {
usage-count yes;
}
# 设置主备节点同步时的网络速率最大值,单位是字节
common {
syncer { rate 10M; }
# 一个DRBD设备(即:/dev/drbdX),叫做一个"资源".里面包含一个DRBD设备的主备#节点的相关信息。
resource r0 {
# 使用协议C.表示收到远程主机的写入确认后,则认为写入完成.
protocol C;
net {
# 设置主备机之间通信使用的信息算法.
cram-hmac-alg sha1;
shared-secret"FooFunFactory";
allow-two-primaries;
}
syncer {
rate 10M;
}
# 每个主机的说明以"on"开头,后面是主机名.在后面的{}中为这个主机的配置 on server1 {
device /dev/drbd0;
#使用的磁盘分区是/dev/sda4
disk /dev/sda4;
# 设置DRBD的监听端口,用于与另一台主机通信
address 10.10.140.140:7788;
flexible-meta-disk internal;
}
on server3 {
device /dev/drbd0;
disk /dev/sda4;
address 10.10.140.84:7788;
meta-disk internal;
}
}
3.3.3、将drbd.conf文件复制到备机上/etc目录下
[root@server1 ~]#scp /etc/drbd.conf root@server3:/etc/
3.4、DRBD启动
准备启动之前,需要分别在2个主机上的空白分区上创建相应的元数据保存的数据块:
常见之前现将两块空白分区彻底清除数据
分别在两个主机上执行
#dd if=/dev/zero of=/dev/sdbX bs=1M count=128
否则下一步会出现
.........
Device size would be truncated,which
would corrupt data and result in
'access beyond end of device' errors.
You need to either
* use external meta data (recommended)
* shrink that filesystem first
* zero out the device (destroy thefilesystem)
Operation refused.
..........
分别在server1和server3上面执行
3.4.1、#drbdadmcreate-md r0 创建元数据
确保成功后,接下来就可以启动drbd进程了(在server01和server02同时启用):
3.4.2 在server1和server3上分别执行
[root@server01~]# /etc/init.d/drbd start 或servicedrbd start
StartingDRBD resources: [ d(r0) s(r0) n(r0) ].
3.4.3 设置主节点
在server1执行以下命令(第一次),设置server1为主节点,以后可以用 drbdadmprimary db
#drbdsetup /dev/drbd0 primary –o
3.4.4 查看连接
在第一次启动会同步磁盘的数据。

3.4.5 对空白磁盘进行格式化并mount到文件系统中
此操作只在primary节点上执行。
[root@server1 ~]# mkfs.ext2/dev/drbd0
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
655360 inodes, 1309232 blocks
65461 blocks (5.00%) reserved forthe super user
First data block=0
Maximum filesystemblocks=1342177280
40 block groups
32768 blocks per group, 32768fragments per group
16384 inodes per group
Superblock backups stored onblocks:
32768, 98304, 163840, 229376, 294912,819200, 884736
Writing inode tables: done
Creating journal (32768 blocks):done
Writing superblocks and filesystemaccounting information: done
This filesystem will beautomatically checked every 35 mounts or
180 days, whichever comesfirst. Use tune2fs -c or -i to override.
[root@server1 ~]# mount /dev/drbd0 /home/share
3.4.6 设置drbd开机时自动启动
chkconfig--level 35 drbd on
3.5、DRBD测试
3.5.1 主备机手动切换
先卸载主机上drbd设备
[root@server1 ~]# umount /dev/drbd0
将server1降为从节点
[root@server1 ~]# drbdadm secondary r0
查询server1的状态

把server3升级为主节点
[root@server3 ~]# drbdadm primary r0
在server3上挂在到drbd设备上
[root@server3 ~]# mount /dev/drbd0 /home/share
查看server3的状态

4、 Heartbeat的安装与配置
4.1 Heartbeat的安装
在server1和server3利用yum安装heartbeat
[root@server1~]# yum install heartbeat
4.2 Heartbeat的配置
配置/etc/ha.d/ha.cf
1、使用下面的命令查找Heartbeat RPM包安装后释放的ha.cf样本配置文件:
rpm -qd heartbeat | grepha.cf
2、使用下面的命令将样本配置文件复制到适当的位置:
cp/usr/share/doc/packages/heartbeat/ha.cf /etc/ha.d/
3、编辑/etc/ha.d/ha.cf文件,取消注释符号或增加以下内容:
udpport 694
#采用ucast方式,使用网卡eth1在主服务器和备用服务器之间发送心跳消息。指定对端ip,即在server1上指定10.0.0.203,在server3上指定10.0.0.201
ucast eth1 10.0.0.203
4、同时,取消keepalive,deadtime和initdead这三行的注释符号:
keepalive 2
deadtime 30
initdead 120
initdead行指出heartbeat守护进程首次启动后应该等待120秒后再启动主服务器上的资源,keepalive行指出心跳消息之间应该间隔多少秒,deadtime行指出备用服务器在由于主服务器出故障而没有收到心跳消息时,应该等待多长时间,Heartbeat可能会发送警告消息指出你设置了不正确的值(例如:你可能设置deadtime的值非常接近keepalive的值以确保一个安全配置)。
5、将下面两行添加到/etc/ha.d/ha.cf文件的末尾:
node server1
node server3
这里填写主、备用服务器的名字(uname -n命令返回的值)
5、去掉以下注释可以查看heartbeat的运行日志,对错误分析有很大帮助
debugfile /var/log/ha-debug
logfile /var/log/ha-log
配置 /etc/ha.d/authkeys
1、使用下面的命令定位样本authkeys文件,并将其复制到适当的位置: rpm -qd heartbeat | grep authkeys
cp/usr/share/doc/packages/heartbeat/authkeys /etc/ha.d
2、编辑/etc/ha.d/authkeys文件,取消下面两行内容前的注释符号:
auth1
1 crc
3、确保authkeys文件只能由root读取:
chmod 600/etc/ha.d/authkeys
4.3 在备用服务器上安装Heartbeat
把配置文件拷贝到备用服务器上
[root@server1 ~]# scp -r/etc/ha.d root@server3:/etc/ha.d
4.4 启动Heartbeat
1 在主服务器和备用服务器上把heartbeat配置为开机自动启动
chkconfig --level 35 heartbeat on
2 手工启停方法
/etc/init.d/heartbeat start
或者
service heartbeat start
/etc/init.d/heartbeat stop
或者
service heartbeat stop
5、 Hadoop主要配置文件的配置
提示:在启动heartbeat前,应该先formatnamenode在drbd分区中产生元数据。
masters
servervipslaves
server2
core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/home/share/hadoopdata/</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://servervip:9000</value>
<description>The name of the default file system. A URI whose
schemeand authority determine the FileSystem implementation. The
uri'sscheme determines the config property (fs.SCHEME.impl) naming
theFileSystem implementation class. Theuri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property
<property>
<name>fs.checkpoint.dir</name>
<value>${hadoop.tmp.dir}/dfs/namesecondary</value>
<description>Determines where on the local filesystem the DFSsecondary
namenode should store the temporary images to merge.
Ifthis is a comma-delimited list of directories then the image is
replicated in all of the directories for redundancy.
</description>
</property
<property>
<name>fs.checkpoint.edits.dir</name>
<value>${fs.checkpoint.dir}</value>
<description>Determines where on the local filesystem the DFSsecondary
namenode should store the temporary edits to merge.
Ifthis is a comma-delimited list of directoires then teh edits is
replicated in all of the directoires for redundancy.
Default value is same as fs.checkpoint.dir
</description>
</property>
hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>${hadoop.tmp.dir}/dfs/name</value>
<description>Determines where on the local filesystem the DFS
namenode should store the name table(fsimage). If this is a
comma-delimitedlist of directories then the name table is
replicated in all of the directories, for
redundancy.</description>
</property>
<property>
<name>dfs.name.edits.dir</name>
<value>${dfs.name.dir}</value>
<description>Determines where on the local filesystem the DFS
namenode should store the transaction (edits) file. If this is
acomma-delimited list of directories then the transaction file
isreplicated in all of the directories, for redundancy.
Default value is same as dfs.name.dir</description>
</property>
mapred-site.xml
<property> <name>mapred.job.tracker</name> <value>servervip:9001</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-processas a single map andreduce task. </description> </property>
6、 通过haresource配置自动切换
如果不使用heartbeat的情况下,DRBD只能手工切换主从关系,现在修改heartbeat的配置文件,使DRBD可以通过heartbeat自动切换。
6.1 创建资源脚本
1、新建脚本hadoop-hdfs,用于启停hdfs文件系统,同理也可以建脚本hadoop-all,hadoop-jobtracker等资源文件,以hdfs为例内容如下:
[root@server1 conf]# cat/etc/ha.d/resource.d/hadoop-hdfs
cd /etc/ha.d/resource.d vi hadoop-hdfs #!/bin/sh case "$1" in start) # Start commands go here cd /home/hadoop-0.20.2/bin msg=`su - root -c "sh/home/hadoop-0.20.2/bin/start-dfs.sh"` logger $msg ;; stop) # Stop commands go here cd /home/hadoop-0.20.2/bin msg=`su - root -c "sh/home/hadoop-0.20.2/bin/stop-dfs.sh"` logger $msg ;; status) # Status commands go here ;;
2、修改权限
[root@server1 conf]# chmod755 /etc/ha.d/resource.d/hadoop-hdfs
3、 把脚本拷贝到备份机并同样修改权限
[root@server1 conf]# scp/etc/ha.d/resource.d/hadoop-hdfs server3: /etc/ha.d/resource.d/
6.2 配置haresources
[root@server1 conf]# cat /etc/ha.d/haresources
server1 IPaddr::10.10.140.200 drbddisk::r0 Filesystem::/dev/drbd0::/home/share::ext2hadoop-hdfs
注释:
Server1 主服务器名
10.10.140.200 对外服务IP别名
drbddisk::r0 资源drbddisk,参数为r0
Filesystem::/dev/drbd0::/home/share::ext2资源Filesystem,mount设备/dev/drbd0到/home/share目录,类型为ext2
Hadoop-hdfs文件系统资源
7、 DRBD、heartbeat、hadoop联调
7.1创建文件和目录
1、在server1(主节点)上drbd和heartbeat运行着。由于heartbeat启动后,虚拟地址10.10.140.200被分配到主节点上。用命令查看:
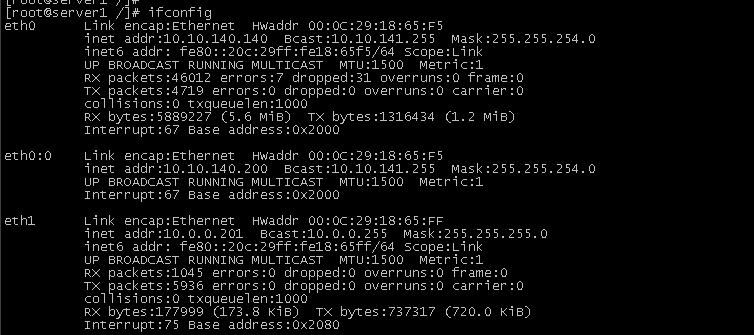
用命令cat /proc/drbd查看server1和server3是否通信正常,可以看到server1和server3分别为主从节点。


查看drbd分区是否挂载

2、查看hadoop dfs是否启动,打开:http://10.10.140.200:50070/dfshealth.jsp
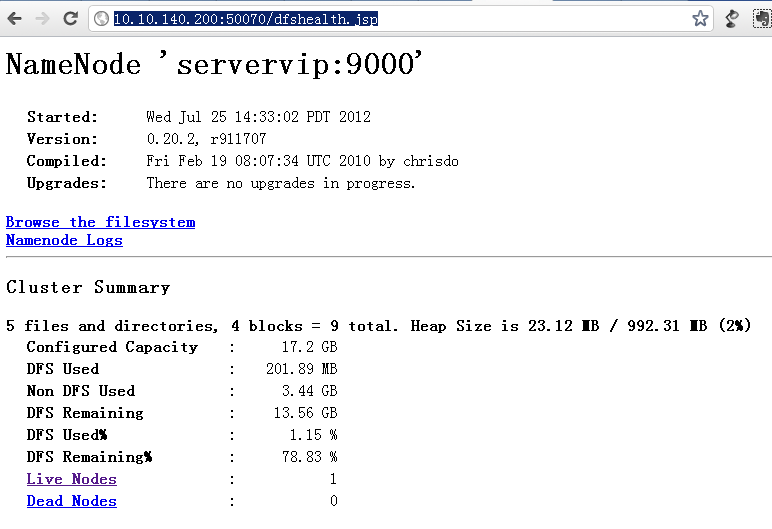
3、向hadoop上传文件
创建一个目录并上传一个测试文件,
[root@server1hadoop-0.20.2]# bin/hadoop dfs -mkdir testdir
[root@server1 hadoop-0.20.2]# bin/hadoop dfs-copyFromLocal /home/share/temp2 testdir
查看文件:
![]()
7.2 主备机切换
1、在server1上停止heartbeat
[root@server1 /]# service heartbeat stop
Stopping High-Availabilityservices:
[ OK ]
2、可以查看虚拟IP已经切换到server3上了
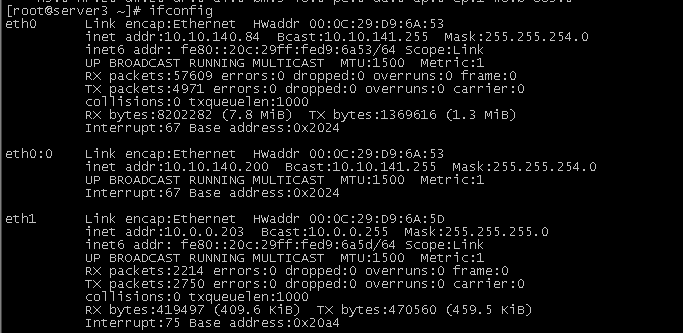
3、验证server3上查看hadoop文件系统
![]()
7.3 主备机再次切换
1、在server1上启动heartbeat
[root@server1 /]# service heartbeatstart
Starting High-Availability services:
2012/07/25_15:03:31 INFO: Resource is stopped
[ OK ]
2、查看虚拟IP已经切换到server1上。
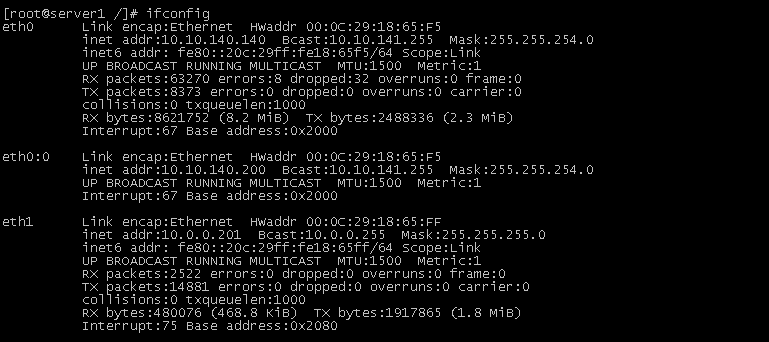
3、验证server1上查看hadoop文件系统
![]()
8、 其他问题
8.1 split brain问题处理
split brain实际上是指在某种情况下,造成drbd的两个节点断开了连接,都以primary的身份来运行。当drbd某primary节点连接对方节点准备发送信息的时候如果发现对方也是primary状态,那么会会立刻自行断开连接,并认定当前已经发生split brain了,这时候他会在系统日志中记录以下信息:“Split-Brain detected,droppingconnection!”当发生split brain之后,如果查看连接状态,其中至少会有一个是StandAlone状态,另外一个可能也是StandAlone(如果是同时发现split brain状态),也有可能是WFConnection的状态。
1 节点重新启动时,在dmesg中出现错误提示:
drbd0: Split-Brain detected, dropping connection!
drbd0: self055F46EA3829909E:899EC0EBD8690AFD:FEA4014923297FC8:3435CD2BACCECFCB
drbd0: peer 7E18F3FEEA113778:899EC0EBD8690AFC:FEA4014923297FC8:3435CD2BACCECFCB
drbd0: helper command: /sbin/drbdadm split-brain minor-0
drbd0: meta connection shut down by peer.
2在203查看cat/proc/drbd,203运行为StandAlone状态
version: 8.3.0 (api:88/proto:86-89)
GIT-hash: 9ba8b93e24d842f0dd3fb1f9b90e8348ddb95829build by root@ost3, 2008-12-30 17:16:32
0: cs:StandAlone ro:Secondary/Unknownds:UpToDate/DUnknown r---
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0ua:0 ap:0 ep:1 wo:b oos:664
3在202查看cat /proc/drbd,202运行为StandAlone状态
version: 8.3.0 (api:88/proto:86-89)
GIT-hash:9ba8b93e24d842f0dd3fb1f9b90e8348ddb95829 build by root@ost2, 2008-12-3017:23:44
0: cs:StandAlone ro:Primary/Unknownds:UpToDate/DUnknown r---
ns:0 nr:0 dw:4 dr:21 al:1 bm:0 lo:0pe:0 ua:0 ap:0 ep:1 wo:b oos:68
4 原因分析
由于节点重启导致数据不一致,而配置文件中没有配置自动修复错误的内容,因而导致握手失败,数据无法同步。
split brain有两种解决办法:手动处理和自动处理。
手动处理
1 在203上停止heartbeat
Heartbeat会锁定资源,只有停止后才能释放
/etc/init.d/heartbeat stop
2 在作为secondary的节点上放弃该资源的数据
在ost3上
/sbin/drbdadm -- --discard-my-dataconnect r0
3在作为primary的节点重新连接secondary
在ost2上
/sbin/drbdadm disconnect r0
/sbin/drbdadm connect r0
把ost2设置为主节点
/sbin/drbdadm primary r0
4在203上重新启动heartbeat
/etc/init.d/heartbeat start
5 查看202状态 cat /proc/drbd,显示为Connected,已经恢复了正常。
version: 8.3.0 (api:88/proto:86-89)
GIT-hash: 9ba8b93e24d842f0dd3fb1f9b90e8348ddb95829 build byroot@ost2, 2008-12-30 17:23:44
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r---
ns:768 nr:0 dw:800 dr:905 al:11 bm:10 lo:0 pe:0 ua:0 ap:0 ep:1wo:b oos:0
6查看203状态 cat/proc/drbd,显示为Connected,已经恢复了正常。
version: 8.3.0 (api:88/proto:86-89)
GIT-hash:9ba8b93e24d842f0dd3fb1f9b90e8348ddb95829 build by root@ost3, 2008-12-3017:16:32
0: cs:Connected ro:Secondary/Primaryds:UpToDate/UpToDate C r---
ns:0 nr:768 dw:768 dr:0 al:0 bm:10 lo:0pe:0 ua:0 ap:0 ep:1 wo:b oos:0
自动处理
通过/etc/drbd.conf配置中设置自动处理策略,在发生数据不一致时自动处理。自动处理策略定义如下:
1 after-sb-0pri.
当两个节点的状态都是secondary时,可以通过after-sb-0pri策略自动恢复。
1)disconnect
默认策略,没有自动恢复,简单的断开连接。
2)discard-younger-primary
在split brain发生前从主节点自动同步。
3)discard-older-primary
在split brain发生时从变成primary的节点同步数据。
4)discard-least-changes
在split brain发生时从块最多的节点同步数据。
5)discard-node-NODENAME
自动同步到名字节点
2 after-sb-1pri
当两个节点的状态只有一个是primary时,可以通过after-sb-1pri策略自动恢复。
1)disconnect
默认策略,没有自动恢复,简单的断开连接。
2)consensus
丢弃secondary或者简单的断开连接。
3)discard-secondary
丢弃secondary数据。
4)call-pri-lost-after-sb
按照after-sb-0pri的策略执行。
3 after-sb-2pri
当两个节点的状态都是primary时,可以通过after-sb-2pri策略自动恢复。
1)disconnect
默认策略,没有自动恢复,简单的断开连接。
2)violently-as0p
按照after-sb-0pri的策略执行。
3)call-pri-lost-after-sb
按照after-sb-0pri的策略执行,并丢弃其他节点。
4 配置自动恢复
编辑/etc/drbd.conf,找到resource r0部分,配置策略如下,所有节点完全一致。
#after-sb-0pri disconnect;
after-sb-0pri discard-younger-primary;
#after-sb-1pri disconnect;
after-sb-1pri discard-secondary;
#after-sb-2pri disconnect;
after-sb-2pri call-pri-lost-after-sb;
相
参考资料:Hadoop_HDFS系统双机热备方案.pdf
DRBD安装配置(主从模式)--详细步骤图文并茂.doc