Linux网络协议栈--IP
开场白:
IP是什么就不介绍了,不清楚的请自行百度。
这篇文章的定位
(1)说明下网络层中IPV4协议收发数据的流程
(2)不涉及太多细节
(3)一些关键数据结构
(4)一部分关于路由系统
(5)为更清晰看清楚中间的流程,可能不会去涉及分片重组,MTU发现等一些机制。
建议:
(1)一定要对着下面的参考资料中提到的一起看,不然会看的很晕
(2)为了便于理解,已经尽量少的减少细节描述,每个块中的内容都可以慢慢展开,但是感觉还是希望有个全貌后再展开会看的更清楚一些
(3)为了加深印象,大量的引用了代码,第一次看肯定会很晕,我尽量在引用前后说明代码中需要注意的字段,之后记住这个字段做什么的就可以了,代码具体内容可以跳过,毕竟不完全的代码肯定看的不明不白的
(4)我使用的资料的内核版本都不一样,所以中间肯定会有一些不同的地方,但是我可以保证,它们的思路绝对是一样的。
(5)给了一张图,里面包含的信息很多,我尽自己最大能力去挖掘里面的信息了,看后面的内容的时候不妨多返回看看这张图,可以很好的加深印象。
(6)网上也可以找到下面资料的电子版,不过我还是希望能支持下正版,毕竟作者写的不容易。
参考资料
(1)《Understand Linux Kernel Internel》
(2)《Linux内核源码剖析-TCP/IP实现》
(3)linux内核源码--我使用的版本是3.2.4
一、大蓝图
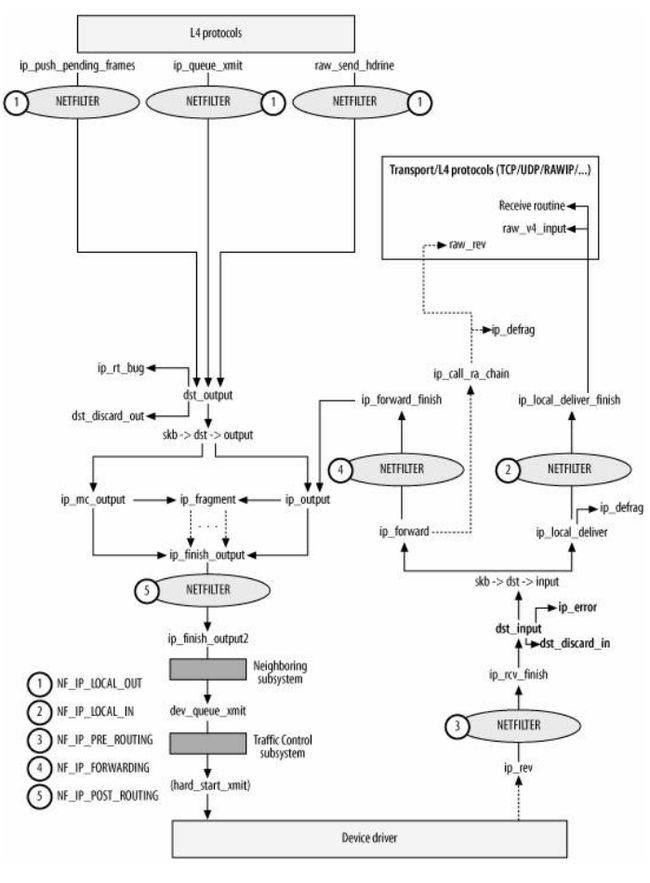
图1-1 IP协议协议栈函数流程(见《Understand Linux Kernel Internel》图18-1)
这个图包含了许多的信息,书上没有给出图的介绍,下面简要介绍,以后会慢慢详细说明
(A)记住,每个函数在进入到出口,中间可能代码会很长很长,中间其实一般只在做以下4个事情中的某几个
- 正确性检测(主要是接收和转发的数据报)
- 发送参数检测(主要是本地要发送的数据报)
- 路由选择(接收数据报,注:这里或许会让人很疑惑,后面会慢慢说明)
- 包头封装(发送和转发的数据报)
(B)注意图中5个带数字圈圈,在图中代表的就是Netfilter防火墙子系统,其中分为5种类型,图中左方给出了这5种的类型。
注:只有在开启了防火墙的情况下,数据包才会通过这5个部分的检测,否则就直接穿过了
(C)注意左下方颜色比较深的方框部分,这两个部分分别是邻居子系统和流量控制子系统,这两个部分实现都比较复杂,但是不需要太多关注。
注:流量子系统看名字就知道是什么意思。邻居子系统可以暂时把它看成ARP协议的实现(当然事实肯定不是了),这样就知道了ARP协议所在的部位了。
(D)注意图中skb->dst->input和 ip->dst->output,这两个是函数指针,数据包经过路由子系统后会把相应的函数赋值给该值。
注:输入的数据报是在ip_rcv_finish函数中经过路由子系统,输出的数据报则是在第4层经过路由子系统
注2:常用第四层数据传输协议一般为TCP和UDP,UDP协议如果没有进行connect连接,每个数据报都会经过路由子系统。UDP协议通过了connect链接和已经建立链接的TCP不需要经过路由子系统,因为路由项已经存储在套接字中。
二、一些约定:
(A)在代码中可能有些地方会看到NF_HOOK(),这个宏定义是关于防火墙的hook接口,防火墙的内容这篇文章不讨论,所以都假定关闭了防火墙。具体遇到会加以说明。
三、主要数据结构
基本上图1-1中所有函数的入口都会带有以下3个参数中的若干个,它们互相协作,辅助完成数据报在IP协议中的各种操作
注:其实这几个参数一直贯穿整个协议栈
1、struct sk_buff结构
缓存着一个用于管理一个数据包所需要的所有信息。
2、struct net_device结构
网络设备,是大部分信息的提供者
3、struct dst_entry结构
路由项,这个结构被封装在sk_buff中,知道sk_buff就可以查找到该报文的路由项(前提是,这个数据报可以找到路由,否则就为NULL)
四、接收数据包
先来看第一条支线。
ip_rcv >> ip_rcv_finish >> dst_input
一个数据报经过底层处理后会根据协议类型递交到相应的函数处理入口。如果是IPV4协议类型,其入口为ip_rcv。
注:如果是IPV6,则入口为ipv6_rcv
1、入口ip_rcv
这个函数不是太复杂,做的事情就1个---正确性检查
在函数出口时候如下调用:
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);注:这里的NF_HOOK()就是防火墙的一个hook接口,对应图1-1中的圈圈3,根据二、(A)中的约定,我们认为这里相当于直接调用ip_rcv_finish
2、进一步处理:ip_rcv_finish
这个函数中注意的内容就一个:
static int ip_rcv_finish(struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
if (skb_dst(skb) == NULL) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr, /*!!!!!注意!!!!!*/
iph->tos, skb->dev);
在这里调用的ip_route_input_noref函数,让数据包经过路由子系统,这个函数中的操作非常复杂。完成的动作很多,先记住其中的一个动作--- 完成了skb->dst->input的赋值操作。这样就可以和后面衔接上了
最后这个函数的出口:
…… return dst_input(skb);
3、支线的出口:dst_input
ip_rcv_finish在最后调用dst_input,这个函数内容很简单:
/* Input packet from network to transport. */
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
}其实它就是简单调用了skb->dst->input,所以可以看到图中在输入输入的分支点是怎么到达的了。
上文提到skb->dst->input在ip_route_input_noref函数中完成了赋值,之后数据包就会进入相应的支线(本地递交还是转发)了。
五、发送数据包
现在先不考虑接收的数据包是如何递交或者转发的,咋们先捡好捏的柿子捏,我们先看下本地的数据包是怎么发送的。
第二条支线
dst_output >> …… >> ip_finish_output >> ip_finish_output_2 >> 邻居子系统 >> dev_queue_xmit
注:之所以选择dst_output作为开始,是因为在它上方的3个函数被哪些协议调用说起来会比较麻烦,为避免混乱,就从这里开始了。
1、入口:dst_output
先说明下进入这个入口的数据包是什么样的。
- 已经经过路由子系统选择好了路由,即skb->dst已经准备好了(包括后面的skb->dst->input指针所指向的内容)
- 已经封装好了IP首部,意味着后面的工作其实就是在想办法让这个数据包能够从正确的路径发送出去。
dst_output函数很简单:
/* Output packet to network from transport. */
static inline int dst_output(struct sk_buff *skb)
{
return skb_dst(skb)->output(skb);
}它就简单调用了skb->dst->output,在之前介绍了,在进入这个函数前就会经过路由子系统,中间会将适当的函数指针赋值给skb->dst->output。这样这里就可以实现分流了
注:针对IPV4协议,这里的skb->dst->output指针指向的函数可能是ip_output(单播报文)或者是ip_mc_output(组播报文)。
注2:如果是IPV6协议,那指针指向的就是ip6_output。
注3:IPV6协议skb->dst->output只会指向ip6_output,ip6_mc_output被包裹在ip6_output中。
2、ip_output和ip_mc_output
这个函数在图中没有被画出,不过这个函数也很简单:
int ip_output(struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
IP_UPD_PO_STATS(dev_net(dev), IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
代码仅仅只是初始化一些需要的参数而已
注:在sk_buff中就有net_device的指针
这个函数中又出现了NF_HOOK_COND(),这个也是一个防火墙的hook,对应图1-1中的圈圈5
注:会发觉这里和图1-1对不上,似乎经过防火墙的动作被提前了,我用的代码是3.2.4,出现区别很正常。这个细节先注意,不过我们暂时不细究为什么。
注2:ip_mc_output函数和ip_output函数差不多。区别就是它针对的是组播报文而已
注3:根据前面的约定,我们不讨论防火墙做了什么,这里就认为它直接穿过,进入到ip_finish_output
注4:图中ip_mc_output函数和ip_output函数会分支到ip_fragment,但是在3.2.4中不是这样的。这两个函数出口只有ip_finish_output,在ip_finish_output中才会去调用ip_fragment,但是无论那种,其实做的事情都是一样的。没必要去纠结
3、ip_finish_output
这里的finish还不是真正的finish,真正的finish是在ip_finish_output2中。ip_fragment的功能就是分片。
static int ip_finish_output(struct sk_buff *skb)
{
#if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM)
/* Policy lookup after SNAT yielded a new policy */
if (skb_dst(skb)->xfrm != NULL) {
IPCB(skb)->flags |= IPSKB_REROUTED;
return dst_output(skb);
}
#endif
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb))
return ip_fragment(skb, ip_finish_output2);
else
return ip_finish_output2(skb);
}
注:这里要进入分片所需要具备的条件是同时需要具备(1)数据数据长度大于网络所能承受的MTU最大值(这个MTU值是根据路径MTU发现机制确定)(2)开启了GSO功能(可以去看看GSO和TSO的相关介绍)
这里的ip_fragment的实现很复杂,我们先不去考虑它做了什么,先看看它带入的参数,
return ip_fragment(skb, ip_finish_output2);这里知道它最后调用的函数就是ip_finish_output2就可以了。
这样ip_finish_output2所在位置就和图1-1中位置对应上了。
4、ip_finish_output2
接下来我们看看ip_finish_output2函数是怎么过度到邻居子系统的。它的代码中有如下一段
rcu_read_lock();
neigh = dst_get_neighbour(dst);
if (neigh) {
int res = neigh_output(neigh, skb);
rcu_read_unlock();
return res;
}
rcu_read_unlock();通过dst_get_neighbour获取到邻居的信息(其实就是下一跳的相关信息)。
注:邻居子系统会自动运行(在相关地址解析协议的帮助下),获取相应邻居的动作是很快的。我们这不考虑邻居子系统是怎么实现的。
注2:当然也会出现获取失败的情况
如果获取成功,就会调用neigh_output函数发送数数据报;
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb)
{
struct hh_cache *hh = &n->hh;
if ((n->nud_state & NUD_CONNECTED) && hh->hh_len)
return neigh_hh_output(hh, skb);
else
return n->output(n, skb);
}
这里的内容就和邻居子系统的实现存在一定关联了,
注:n->output会存在多个分支情况,这个和n->nud_state有关,但是属于邻居子系统的范畴,我们不要去在意
注2:虽然n->output会有多个分支,但是最后他们的出口都是dev_queue_xmit
注3:neigh_hh_output函数是对数据包的加速发送,可以从条件从可以看出来,如果邻居项中和下一跳的邻居状态是“链接CONNECTED”着的,意味着下一跳的MAC地址是非常可信的,那就可以加速发送,所以调用neigh_hh_output,我们可以来看看这个函数是怎么实现的。
static inline int neigh_hh_output(struct hh_cache *hh, struct sk_buff *skb)
{
unsigned seq;
int hh_len;
do {
int hh_alen;
seq = read_seqbegin(&hh->hh_lock);
hh_len = hh->hh_len;
hh_alen = HH_DATA_ALIGN(hh_len);
memcpy(skb->data - hh_alen, hh->hh_data, hh_alen);
} while (read_seqretry(&hh->hh_lock, seq));
skb_push(skb, hh_len);
return dev_queue_xmit(skb);
}
可以看到出口就是dev_queue_xmit。这样会不会安心一些?
注4:之后dev_queue_xmit函数会根据配置情况选择发送数据包的排队规则,也就是进入流量控制子系统。这个系统也比较复杂,完全不用管,之后就是下层的事情了。
六、本地递交
第三条支线
ip_local_deliver >> 防火墙 >> ip_local_deliver_finish
这条支线主要完成两个功能
(1)确定是否需要完成分配组装
(2)确定递交给的上层的函数
注:这部分我没怎么看,就说的简单些了。
1、重组分片
这个功能在ip_local_deliver中完成
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}其中ip_is_fragment完成的就是重组分片的功能。
2、递交
(还没看,过几天补上)
七、转发过程
这个过程相对比较简单
1、ip_foward
这里的一些检测暂时先不管,这里我们关注这么一段语句:
if (!xfrm4_route_forward(skb)) goto drop; rt = skb_rtable(skb);这里要做的事情就是进行路由查找。
最后ip_forward的出口是
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev, rt->dst.dev, ip_forward_finish);注:这里的防火墙对应图1-1中的圈圈4,当然我们还是不考虑它做了什么,只知道它的出口是ip_forward_finish就可以了。
2、ip_forward_finish
该函数很简单,定义如下
static int ip_forward_finish(struct sk_buff *skb)
{
struct ip_options * opt = &(IPCB(skb)->opt);
IP_INC_STATS_BH(dev_net(skb_dst(skb)->dev), IPSTATS_MIB_OUTFORWDATAGRAMS);
if (unlikely(opt->optlen))
ip_forward_options(skb);
return dst_output(skb);
}根据五、1中的内容我就很容易看懂dst_output是什么意思了。之后的内容就是进入五中的内容了。
八、数据包发送2
这条直线主要就是ip_push_pending_frames , ip_queue_xmit , raw_send_hdrine,其中
UDP发送数据的时候使用的是ip_push_pending_frames;
TCP发送数据的时候使用的是ip_queue_xmit;
注:其实调用这几个函数的时机会很多
这里需要注意的就是,IP层的数据包头部就是在这些函数中封装的,其他的就没什么需要注意的了。
现在选取ip_push_pending_frames来介绍,其他的类似就不介绍了
int ip_push_pending_frames(struct sock *sk, struct flowi4 *fl4)
{
struct sk_buff *skb;
skb = ip_finish_skb(sk, fl4);
if (!skb)
return 0;
/* Netfilter gets whole the not fragmented skb. */
return ip_send_skb(skb);
}首先会在ip_finish_skb中进行头部的封装
注:其实这里的函数引用是这样的ip_finish_skb >> ip_make_skb >> __ip_make_skb
在 __ip_make_skb中有如下语句,这些语句就是在封装IP层头部
iph = (struct iphdr *)skb->data;
iph->version = 4;
iph->ihl = 5;
iph->tos = inet->tos;
iph->frag_off = df;
ip_select_ident(iph, &rt->dst, sk);
iph->ttl = ttl;
iph->protocol = sk->sk_protocol;
iph->saddr = fl4->saddr;
iph->daddr = fl4->daddr;
if (opt) {
iph->ihl += opt->optlen>>2;
ip_options_build(skb, opt, cork->addr, rt, 0);
}
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
/*
* Steal rt from cork.dst to avoid a pair of atomic_inc/atomic_dec
* on dst refcount
*/
cork->dst = NULL;
skb_dst_set(skb, &rt->dst);
if (iph->protocol == IPPROTO_ICMP)
icmp_out_count(net, ((struct icmphdr *)
skb_transport_header(skb))->type);
然后会调用ip_send_skb将数据包传递给下一个操作函数。
int ip_send_skb(struct sk_buff *skb)
{
struct net *net = sock_net(skb->sk);
int err;
err = ip_local_out(skb);
if (err) {
if (err > 0)
err = net_xmit_errno(err);
if (err)
IP_INC_STATS(net, IPSTATS_MIB_OUTDISCARDS);
}
return err;
}
注:这里就是简单的包裹,递交工作又是有ip_local_out函数完成,
int ip_local_out(struct sk_buff *skb)
{
int err;
err = __ip_local_out(skb);
if (likely(err == 1))
err = dst_output(skb);
return err;
}
注:这里看到dst_output,就与五中的内容衔接上了。
注2:去跟踪ip_queue_xmit函数可以找到ip_local_out这个函数。
结束语:
在这里我们基本上把整个发送和接收的过程给理顺了。而且在这里主要是关注数据报的流动方向,对于很多细节没有进行任何讨论。存在以下不足
(1)三中的数据结构没有展开说明,因为数据结构太大,讲多了看着累,但是后面的内容又不需要懂那么深
(2)将一些很重要的机制给漏过不提了,例如分片重组,GSO,MTU发现机制等
(3)没有讲到IP如何与一些其他的子系统是如何交互的,例如路由子系统,邻居子系统