Linux网络协议栈--ip_append_data函数分析
开场白:
要分析这个函数原因有两个:
一个是前几天要写《Linux网络协议栈--UDP》结果卡在这个函数这了。
另外一个就是这个函数又是UDP报文必经之路,而且对其理解对于套接口中发送队列的理解非常有帮助,所以认真去学习了下。
文章定位:
(1)尽可能撇开一些不需要的细节,重点介绍流程
(2)说明发送队列是如何组织起来的
(3)书本肯定都比我说的好,要真的看明白,还是需要看书,这里能做的就是将其结构重新组织,并且将不同的书的内容重新揉合,帮忙看的更快一些
参考书籍:
(1)《Understand Linux Kernel Internel》
(2)《Linux内核源码剖析-TCP/IP实现》
(3)linux内核源码--我使用的版本是3.2.4
注:虽然这写书都有电子版的,不过我还是希望大家能够支持正版。作者写这些书不容易。
一、cork
一开始先来说一个单词,以下内容为个人理解,仅供参考,如果有错恳请指正。
UDP相关的数据经常会存储在一个名为cork的变量中,第一次看的时候非常的让人感觉疑惑。
cork在英文中是软木塞的意思,那软木塞又和UDP有什么关系?
可以将UDP底部到IP的部分看成一个漏斗,如果从UDP下来的数据都是小数据(比如都只有几十个字节),那无疑会加重下层处理数据的负担,而且会让网络充斥各种小报文。所以cork给人的感觉就是将这个漏斗底部给堵住,等在一定时候再拔掉这个塞子,这样就可以把各种小数据汇集成一个大数据了。
不过需要注意的是,cork的标志是需要应用层来设置,所以这个塞塞子和拔塞子的动作都掌握在应用层手中,所以可以掐头去尾的看了。
二、ip_append_data在做什么
就是将上层下来的数据进行整形,如果是大数据包进行切割,变成多个小于或等于MTU的SKB。如果是小数据包,并且开启了聚合,就会将若干个数据包整合。
说的简单,但是在实现的时候做起来就复杂了,因为函数中考虑到了
(1)如何填充队列中上一个skb中未填充的部分?
(2)如何将队列中上一个skb中不能进行对齐的数据部分移动到新的skb中
(3)如何什么时候分配skb,而且skb的大小是多少
(4)如何在分配skb的时候为下层预留足够的空间
(5)需要将数据重用户空间拷贝到内核空间,那怎么拷贝效率才高
(6)如何才能减少内存的拷贝消耗
(7)……
因为考虑的事情太多,所以做起来就比较繁琐了。
三、参数
先介绍下参数,虽然参数多,但是关键参数却很少
注:该参数是3.2.4中的,可能与其他版本的不一样,不过不影响整体介绍
struct *sk :
struct flowi4 *fl4 :
struct sk_buff_head *queue :
struct inet_cork *cork : 输出数据块的地址。
int getfrag() : 将数据复制到SKB中,其为一个函数指针,会有不同的选择,在udp_sendmsg最开始的时候会进行初始化。其可能的函数如图1-1所示(见《Linux内核源码剖析-TCP/IP实现》表11-12)

图 1-1
void *from :
int length : 数据长度
int transhdrlen : 传输层首部长度,同时也是标志是否为第一个fragment的标志
struct ipcm_cookie *ipc :
struct rtable **rpt :
unsigned int flags : 处理标志,如图1-2所示(见《Linux内核源码剖析-TCP/IP实现》表23-1),在ip_append_data中只用到其中两个MSG_PROBE和MSG_MORE。其余暂时不关心


图1-2
三、几个标志
ip_append_data代码非常大,主要是它存在多个分支,不过令人高兴的是,它的分支的标志都比较清晰,所以看到如下标志就需要多注意了:
1、copy
队列中最后一个skb剩余的空间,存在3种情况,如图3-1所示(《Understand Linux Kernel Internal》章节21.1.4.9):

图3-1
注 : 不过在函数中是分为两种情况分别是:copy <= 0 和 copy > 0
2、flag & MSG_MORE
MSG_MORE在图1-2中就介绍了,在ip_append_data中这个标志也是分支的判断依据之一
3、rt->dst.dev->features&NETIF_F_SG
这个标识是判断是否开启 聚合分散 I/O的标识,也是分支的判断依据之一
下文会慢慢介绍这几个分支是怎么回事。
四、流程及代码分析
内核3.2.4中ip_append_data函数流程和以前的基本一样,区别就是将最主要的循环部分包裹到了__ip_append_data函数中。
1、ip_append_data流程图
图4-1是ip_append_data的主要流程图(见《Linux内核源码剖析-TCP/IP实现》图11-8),不过个人感觉这个图画的也不是太好,主要是下半部分画的不是太清晰,后面会用其他的流程图替换该图下半部分说明。

图4-1
(1)在3.2.4内核中将图中蓝色框中的部分包裹到了函数__ip_append_data中,不过这个部分本来就是整个函数的重点,是最主要的循环。
(2)绿色框内的部分包裹在ip_ufo_append_data中,这个函数相对比较简单,最后会给介绍。
(3)现在说明函数上半部分内容:
int ip_append_data(struct sock *sk, struct flowi4 *fl4,
int getfrag(void *from, char *to, int offset, int len,
int odd, struct sk_buff *skb),
void *from, int length, int transhdrlen,
struct ipcm_cookie *ipc, struct rtable **rtp,
unsigned int flags)
{
struct inet_sock *inet = inet_sk(sk);
int err;
if (flags&MSG_PROBE) /*见《Linux内核源码剖析TCP/IP实现》表23-1 */
return 0;
if (skb_queue_empty(&sk->sk_write_queue)) {
err = ip_setup_cork(sk, &inet->cork.base, ipc, rtp);
if (err)
return err;
} else { /*队列不为空,则使用上次的路由,IP选项,以及分片长度 */
transhdrlen = 0;
}这里就只需要注意一个参数:MSG_PROBE,内容见图1-2的说明。
(4)然后就进入下半部的内容:
return __ip_append_data(sk, fl4, &sk->sk_write_queue, &inet->cork.base, getfrag, from, length, transhdrlen, flags); }
2、__ip_append_data流程图
图4-2本来是ip_append_data的主要循环,在3.2.4中是__ip_append_data的流程图,不伤大雅。(见《Understand Linux Kernel Internel》图21-11)
为了便于后面说明,给图中每个分支进行了编号,图中标识的(图21-X是该分支最后得到的数据结构图,这些图在《Understand Linux Kernel Internel》中可以找到)

图 4-2
2.1、分支(1)
该分支的代码部分如下:
static int __ip_append_data(struct sock *sk,
struct flowi4 *fl4,
struct sk_buff_head *queue,
struct inet_cork *cork,
int getfrag(void *from, char *to, int offset,
int len, int odd, struct sk_buff *skb),
void *from, int length, int transhdrlen,
unsigned int flags)
{
struct inet_sock *inet = inet_sk(sk);
struct sk_buff *skb;
struct ip_options *opt = cork->opt;
int hh_len;
int exthdrlen;
int mtu;
int copy;
int err;
int offset = 0;
unsigned int maxfraglen, fragheaderlen;
int csummode = CHECKSUM_NONE;
struct rtable *rt = (struct rtable *)cork->dst;
skb = skb_peek_tail(queue); /*这里skb有两种情况,如果队列为空,
则skb = NULL,否则为尾部skb的指针 */
/*这部分内容最好参考《understand linux network internal》图21-10*/
exthdrlen = !skb ? rt->dst.header_len : 0;
mtu = cork->fragsize;
hh_len = LL_RESERVED_SPACE(rt->dst.dev); /*链路层首部长度 */
fragheaderlen = sizeof(struct iphdr) + (opt ? opt->optlen : 0); /* IP首部(包括IP选项)长度 */
maxfraglen = ((mtu - fragheaderlen) & ~7) + fragheaderlen; /* 最大IP首部长度,注意对齐 */
if (cork->length + length > 0xFFFF - fragheaderlen) { /*一个IP数据包最大大小不能超过64K */
ip_local_error(sk, EMSGSIZE, fl4->daddr, inet->inet_dport,
mtu-exthdrlen);
return -EMSGSIZE;
}
/*
* transhdrlen > 0 means that this is the first fragment and we wish
* it won't be fragmented in the future.
*/
if (transhdrlen &&
length + fragheaderlen <= mtu &&
rt->dst.dev->features & NETIF_F_V4_CSUM &&
!exthdrlen)
csummode = CHECKSUM_PARTIAL; /*由硬件执行校验和计算 */
cork->length += length; /*更新数据长度 */
/* 对于UDP报文,新加的数据长度大于MTU,并且需要进行分片,则需要
* 进行分片处理
* 这里相当于《understand linux network internel》图21-11最左边的那条支线
* 注意:这里需要加入判断skb是否为NULL*/
if (((length > mtu) || (skb && skb_is_gso(skb))) &&
(sk->sk_protocol == IPPROTO_UDP) &&
(rt->dst.dev->features & NETIF_F_UFO) && !rt->dst.header_len) {
/* ufo = UDP fragmentation offload*/
err = ip_ufo_append_data(sk, queue, getfrag, from, length,
hh_len, fragheaderlen, transhdrlen,
maxfraglen, flags);
if (err)
goto error;
return 0;
}
/* So, what's going on in the loop below?
*
* We use calculated fragment length to generate chained skb,
* each of segments is IP fragment ready for sending to network after
* adding appropriate IP header.
*/
if (!skb)
goto alloc_new_skb;(1)通过skb_peek_tail得到发送队列中最后一个skb,如果队列为空,则该函数返回NULL
(2)代码最后2行就是分支的判断语句
(3)中间的是很多初始化操作,这里很有必要提一点的就是skb_peek_tail语句后面的几行代码,这里涉及到了8字节对齐的内容,见图4-3(见《Understand Linux Kernel Internel》图21-10)

图 4-3
注:代码中的变量对应图中看就基本能看懂了。
(4)在最后分支语句上的一个分支语句需要返回图4-1看绿色框部分的内容
2.2、分支(2)
/* 这个循环最好参照《understand linux network internel》图21-11
* 主要可以分为4条支线,copy <= 0和copy > 0两种与是否设置NETIF_F_SG
* 标志两种的组合。
* 这几种组合可以结合《understand linux network internel》图21-3~图21-6
* 来看。*/
while (length > 0) {
/* Check if the remaining data fits into current packet. */
copy = mtu - skb->len;
/* copy > 0 : 最后一个skb还有一些空余空间
* copy = 0 : 最后一个skb已经被填满
* copy < 0 : 有些数据必须从当前IP片段中删除移动到新的片段*/
if (copy < length)
copy = maxfraglen - skb->len; /*获取一次可以拷贝的份额 */(1)while (lengh > 0)就是分支2的内容
2.3、分支(3) -> yes
分支(3)的依据是copy的值,在图4-2中已经标明,这里先看分支(3) -> yes部分内容:
if (copy <= 0) {
char *data;
unsigned int datalen;
unsigned int fraglen;
unsigned int fraggap;
unsigned int alloclen;
struct sk_buff *skb_prev;
alloc_new_skb:
skb_prev = skb;
if (skb_prev) /*需要计算从上一个skb中复制到新的新的skb中的数据长度 */
fraggap = skb_prev->len - maxfraglen; /*明显就是copy取反 */
else
fraggap = 0;
/*
* If remaining data exceeds the mtu,
* we know we need more fragment(s).
*/
datalen = length + fraggap;
if (datalen > mtu - fragheaderlen)
datalen = maxfraglen - fragheaderlen;
fraglen = datalen + fragheaderlen;
/* 对应图21-11中MSG_MORE?的分支*/
if ((flags & MSG_MORE) &&
!(rt->dst.dev->features&NETIF_F_SG))
alloclen = mtu; /*最大尺寸分配缓冲区,参考图21-3 */
else
alloclen = fraglen; /*确切尺寸分配,参考图21-4
注:fraglen = datalen + fragheaderlen*/(1)这部分代码已经项图4-2中虚线框部分的内容全部包括进去了(即包含了分支(5)和分支(7))
(2)需要注意的是,这里仅仅只是确定(而且还只是初步确定)了之后需要分配的skb缓存大小
(3)alloc_new_skb是分支(1) -> yes的跳转后的入口
(4)fraggap的内容请参考图4-3
之后的代码就是进一步确定分配空间,然后分配,最后将成功分配的skb插入到发送队列中,代码不难读懂:
alloclen += exthdrlen; /*扩展长度支持 */
/* The last fragment gets additional space at tail.
* Note, with MSG_MORE we overallocate on fragments,
* because we have no idea what fragment will be
* the last.
*/
if (datalen == length + fraggap)
alloclen += rt->dst.trailer_len;
/* 分配SKB的空间*/
if (transhdrlen) {
skb = sock_alloc_send_skb(sk,
alloclen + hh_len + 15,
(flags & MSG_DONTWAIT), &err);
} else {
skb = NULL;
if (atomic_read(&sk->sk_wmem_alloc) <=
2 * sk->sk_sndbuf)
skb = sock_wmalloc(sk,
alloclen + hh_len + 15, 1,
sk->sk_allocation);
if (unlikely(skb == NULL))
err = -ENOBUFS;
else
/* only the initial fragment is
time stamped */
cork->tx_flags = 0;
}
if (skb == NULL)
goto error;
/*
* Fill in the control structures
*/
skb->ip_summed = csummode;
skb->csum = 0;
skb_reserve(skb, hh_len);
skb_shinfo(skb)->tx_flags = cork->tx_flags;
/*
* Find where to start putting bytes.
*/
data = skb_put(skb, fraglen + exthdrlen); /*预留L2,L3首部空间 */
skb_set_network_header(skb, exthdrlen); /*设置L3层的指针 */
skb->transport_header = (skb->network_header +
fragheaderlen);
data += fragheaderlen + exthdrlen;
if (fraggap) { /*填充原来的skb尾部的空间 */
skb->csum = skb_copy_and_csum_bits(
skb_prev, maxfraglen,
data + transhdrlen, fraggap, 0);
skb_prev->csum = csum_sub(skb_prev->csum,
skb->csum);
data += fraggap;
pskb_trim_unique(skb_prev, maxfraglen);
}
copy = datalen - transhdrlen - fraggap;
if (copy > 0 && getfrag(from, data + transhdrlen, offset, copy, fraggap, skb) < 0) {
err = -EFAULT;
kfree_skb(skb);
goto error;
}
/* 计算下次需要复制的数据长度*/
offset += copy;
length -= datalen - fraggap;
transhdrlen = 0; /*注意 */
exthdrlen = 0; /*注意 */
csummode = CHECKSUM_NONE;
/*
* Put the packet on the pending queue.
*/
__skb_queue_tail(queue, skb); /*将skb添加的尾部 */
continue;
}
(1)这里第一个需要注意的就是fraggap的内容,还是参照图4-3来看
(2)最后需要计算下次需要复制的数据的长度。
可能只看代码会比较让人头晕,所以下面给出这些内存分配后数据组织的情况:
注:在代码中这些部分内容都揉在一起,也不是不能拆,只是觉得拆了以后代码太零散,看的更让人头晕。
(a)分支(5) -> yes (见《Understand Linux Kernel Internel》图21-5)
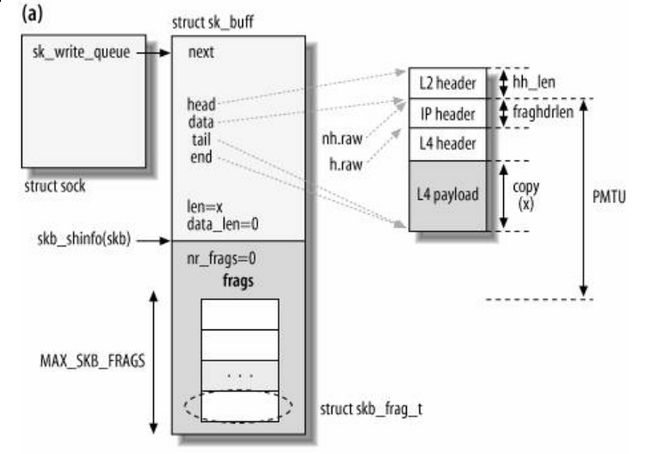
图 4-4
这里需要注意PMTU大小和skb缓存实际大小。
(b)分支(7) -> no (见《Understand Linux Kernel Internel》图21-3)

图 4-5
注:这里需要注意一些参数之间的关系:
(c) 分支(7)-> yes (见《Understand Linux Kernel Internel》图21-4)
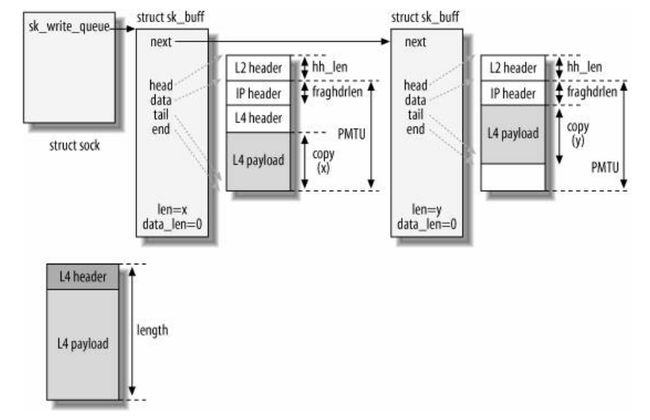
图 4-6
注:这里注意skb缓存大小的分配。
2.4 分支(3)-> no
该分支对应copy > 0的情况,根据分支4中的情况会分为两条支线。
2.4.1 分支(4) -> no
if (copy > length)
copy = length;
if (!(rt->dst.dev->features&NETIF_F_SG)) { /*不支持分散聚合,《understand
linux netowrk internel》图21-11
中的分支,直接填充缓存*/
unsigned int off;
off = skb->len;
if (getfrag(from, skb_put(skb, copy),
offset, copy, off, skb) < 0) {
__skb_trim(skb, off);
err = -EFAULT;
goto error;
}copy > 0 说明有足够的空间,如果不开启分散聚合 I/O,就直接拷贝,之后的数据结构如下图(见
《Understand Linux Kernel Internel》图21-6(b))
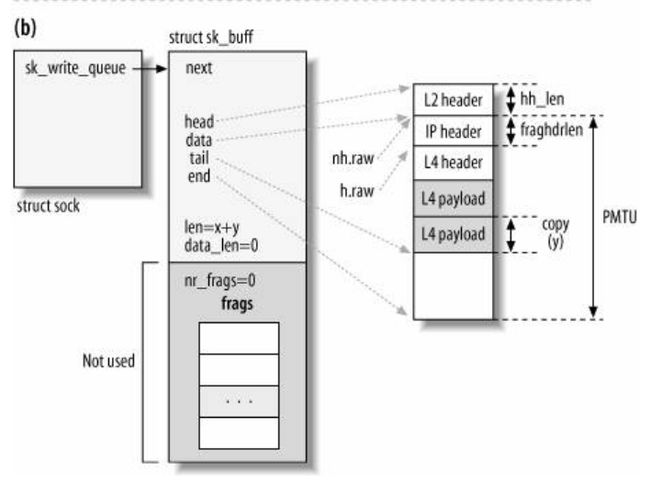
2.4.2 、分支(4) -> yes
} else {
int i = skb_shinfo(skb)->nr_frags;
skb_frag_t *frag = &skb_shinfo(skb)->frags[i-1];
struct page *page = cork->page;
int off = cork->off;
unsigned int left;
if (page && (left = PAGE_SIZE - off) > 0) { /*已经分配了页面 */
if (copy >= left)
copy = left;
if (page != skb_frag_page(frag)) {
if (i == MAX_SKB_FRAGS) {
err = -EMSGSIZE;
goto error;
}
skb_fill_page_desc(skb, i, page, off, 0);
skb_frag_ref(skb, i);
frag = &skb_shinfo(skb)->frags[i];
}
} else if (i < MAX_SKB_FRAGS) {
/* 注: MAC_SKB_FRAGS是最大片段数量,即skb->frags数组的最大下标
* 注2: 由此可以推断一个IP封包最大不能超过64K + MTU
* 注3: IP封包大小不是IP报文大小,IP报文大小根据MTU的值规定*/
if (copy > PAGE_SIZE)
copy = PAGE_SIZE;
page = alloc_pages(sk->sk_allocation, 0); /*分配一个页面 */
if (page == NULL) {
err = -ENOMEM;
goto error;
}
cork->page = page;
cork->off = 0;
skb_fill_page_desc(skb, i, page, 0, 0);
frag = &skb_shinfo(skb)->frags[i];
} else {
err = -EMSGSIZE;
goto error;
}
if (getfrag(from, skb_frag_address(frag)+skb_frag_size(frag), /*将数据拷贝到页面内 */
offset, copy, skb->len, skb) < 0) {
err = -EFAULT;
goto error;
}
cork->off += copy;
skb_frag_size_add(frag, copy);
skb->len += copy;
skb->data_len += copy;
skb->truesize += copy;
atomic_add(copy, &sk->sk_wmem_alloc);
}
offset += copy;
length -= copy;
}
return 0;注:上述代码已经包含了页面分配的内容
见《Understand Linux Kernel Internel》图21-7

图 4-8
注:这里注意下MAX_SKB_FRAGS,源代码定义是16,一个page是4K,所以一个IP封包最大的大小是64K.
2.5 扫尾。
return 0; error: cork->length -= length; IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTDISCARDS); return err; }
结束:
关于ip_ufo_append_data函数,如果弄懂上面的过程,那个看起来就很简单了。ip_append_data函数涉及的参数很多,但是涉及的知识面却是很少的,主要都是在缓存分配和数据结构组织上。所有的内容去其实都在《understand linux network internal》图21-2~图21-8中。对照源码以及《Linux内核源码剖析-TCP/IP实现》中的说明,看起来应该还是比较简单的。
另外还有ip_append_page函数,我没去看,感觉应该和这个差不多。